Дожив до седых волос, понял, что не вполне понимаю как правильно обконстрейнить чтение по асинхронной шине. Не люблю асинхронные схемы, но "жизнь вынуждает написать бестселлер", поэтому нужно восполнить некоторый пробел.
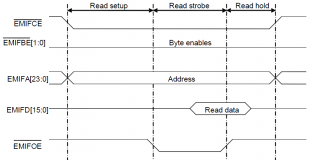
Дано: DSP имени TI и FPGA имени Xilinx, соединённые шиной EMIF. EMIF асинхронный. Временные диаграммы чтения в приаттаченном рисунке.
В FPGA имееется много регистров, формируемых в общем случае на разных клоках. Их надо читать процессором. То есть получается такой большой многоразрядный мультиплексор:
Код
process (EMIFA, D0, D1, D2)
begin
-- для простоты тут регистра только три, реально их много больше
case EMIFA is
when A0 => D <= D0;
when A1 => D <= D1;
when A2 => D <= D2;
when others => D <= (others => '0');
end case;
EMIFD <= D when (EMIFCE = '0' and EMIFOE = '0') else (others => 'Z');
end;
Вопрос в том, как всё это правильно обконстрейнить. Пока я обхожусь только указанием максимальной задержки от каждого из регистров до ножек микросхемы:
Код
# DSP read strobe: setup: 2 * 6 ns, strobe: 4 * 6 ns, hold: 2 * 6 ns
TIMEGRP DSP_EMIFD_GRP = PADS(EMIFD(*));
NET U00/D0(*) TPSYNC = UU0_D0;
TIMESPEC TS_UU0_D0 = FROM UU0_D0 TO DSP_EMIFD_GRP 30 ns;
# 30 нс -- это меньше чем setup+hold=36 нс.
Но видимо, этого недостаточно. Наверное, надо как-то учесть и EMIFA, и EMIFCE, и EMIFOE.

















 Dec 12 2014, 06:37
Dec 12 2014, 06:37