Цитата(ASN @ Feb 21 2015, 00:11)

Arlleex
Для копирования ЦП блока данных необходимо (считаем, что система команд содержит автоинкремент/декремент):
1. Считать команду "чтение источника";
2. Считать слово (адресуемую единицу) источника в регистр;
3. Считать команду "запись приёмника";
4. Записать слово из регистра в приёмник;
5. Проверить на условие окончания цикла;
А ПДП делает это аппаратно за такт.
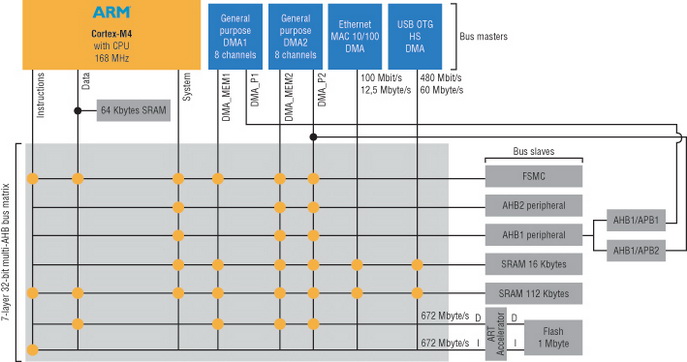
И для какого это CPU Вы привели? Для AVR?
Даже в обычном Cortex-M имеются prefetch-буфера, тогда никаких "считать команду" не будет и вообще это может идти по другой шине. И копирования массивов могут выполняться по неск. слов за проход.
А ещё можно вспомнить про DSP, который всё описанное выполнит за такт. И даже неск. слов может скопировать за такт.



















 Feb 20 2015, 16:26
Feb 20 2015, 16:26