| |
 Учет уровня шума при мягких демодуляции/декодировании Учет уровня шума при мягких демодуляции/декодировании |
|
|
|
|
 Apr 14 2015, 16:02 Apr 14 2015, 16:02
|
Группа: Участник
Сообщений: 11
Регистрация: 14-04-15
Пользователь №: 86 230

|
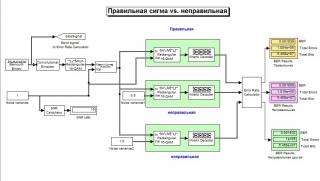
Здравствуйте! Меня интересует проблема учета уровня шума при мягких демодуляции/декодировании. Прилагаю скриншот с симулинковской моделью, на которой отображены так же результаты моделирования. Можно видеть, что принятие неверной сигмы 1.5 при формировнии решений демодулятора дает лучший результат, чем принятие истинной сигмы 1.0. Результат для меня неожиданный и непонятный. Различе небольшое, но статистически значимое, поскольку выборка большая, и моделирование проводилось неоднократно с разными начальными условиями генератора случайных чисел. Результат один. Помимо этого видно, что учет разных сигм дает вообще не очень-то различный результат. Я ожидал другого. Можно вообще использовать приближенные LLR вместо точных, где сигма вообще не участвует. Результат опять таки будет мало отличаться. Зачем же тогда вообще нужен учет шума, если толку мало? Модель изготовлена из матлаб-симулинковского демо "LLR vs. Hard Decision Demodulation". Все параметры модуляции, кодирования и т.д. такие же как в демке. Их можно крутить, но по сути ничего не меняется. Используются неквантованные решения демодулятора. Расчитываю на помощь экспертов. Спасибо!
|
|
|
|
|
|
|
|
Apr 14 2015, 16:47
|
Знающий

Группа: Свой
Сообщений: 565
Регистрация: 22-02-13
Пользователь №: 75 748
|
При небольших рассогласованиях в оценке мощности шума существенных ухудшений BER не будет. Если же вы вместо 1 будете использовать оценку, скажем, равную 7, то увидите, что BER резко ухудшится. Если в том примере из MATLAB вы будете работать с неверной оценкой в схеме с квантованием, то уже при малых рассогласованиях оценки шума будет плохой BER, поскольку уровни квантователя расситываются заранее на определенную мощность шума. Как сказал выше des00, для LDPC и турбокодов для некоторых алгоритмов неверная оценка шума очень критична. Цитата Можно видеть, что принятие неверной сигмы 1.5 при формировнии решений демодулятора дает лучший результат, чем принятие истинной сигмы 1.0. Результат для меня неожиданный и непонятный. Как вы определили, что именно этот результат лучший? С помощью функции berconfint можете посчитать доверительные интервалы. На скриншоте виден объективный разброс в статистике.
Сообщение отредактировал Grizzzly - Apr 14 2015, 16:57
|
|
|
|
|
|
|
|
Apr 14 2015, 16:58
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(AEG @ Apr 14 2015, 19:02)  Помимо этого видно, что учет разных сигм дает вообще не очень-то различный результат. Я ожидал другого. Можно вообще использовать приближенные LLR вместо точных, где сигма вообще не участвует. Результат опять таки будет мало отличаться. Зачем же тогда вообще нужен учет шума, если толку мало?
Модель изготовлена из матлаб-симулинковского демо "LLR vs. Hard Decision Demodulation". Все параметры модуляции, кодирования и т.д. такие же как в демке. Их можно крутить, но по сути ничего не меняется. Используются неквантованные решения демодулятора.
Расчитываю на помощь экспертов.
Спасибо! Могу посоветовать повторить моделирование на ОСШ пониже. На 10 раличия в способах формирования мягких решений не сильно влияют. Также, я думаю, что для 6..7 значащей цифры в BER маловато статистики. Статистики было бы достаточно, чтобы сказать, что BER лучше, чем 10^-7, если бы не было зафиксировано ошибок. Но для сравнения, которое Вы проводите, мне кажется, что передано недостаточно бит. Вы ж врядли даже все возможные кодовые слова сверточного кода по разу передали.
Сообщение отредактировал andyp - Apr 14 2015, 16:58
|
|
|
|
|
|
|
|
Apr 15 2015, 07:43
|
Знающий
Группа: Участник
Сообщений: 527
Регистрация: 4-06-14
Из: Санкт-Петербург
Пользователь №: 81 866
|
Почему если выбрать approximate log-likelihood ratio вместо обычного log-likelihood ratio результат не зависит от сигма шума? Прикладываю модельку с экспериментом. При этом если выбрать log-likelihood ratio то при значительной ошибке сигма и низком snr получем большой ber. В моем понимание approximate метод позволяет перейти от логарифма суммы экспонент к max/min функциям, при этом сигма выносится за скобки, но не уходит из конечного выражения. Какая-то особенность реализации матлабовского approximate log-likelihood ratio? что-то вроде автоматической нормировки сигмы к 1, на подобии той что делают на практике?  llr_test.zip
llr_test.zip ( 11.51 килобайт )
Кол-во скачиваний: 45Еще вот статейку почитал по soft decision для OFDM, мб будет интересно:  HPL_2001_246.pdf
HPL_2001_246.pdf ( 243.03 килобайт )
Кол-во скачиваний: 227Они сигму нормируют к 1, считая шум постоянным на каждой поднесущей, но учитывают мощность канальных весов для корректировки значений метрик. Насколько это реально улучшит OFDM систему в условиях частотно-селективных замираний? Интуитивно мне это понятно, т.к. чем меньше i-й канальный вес, тем больше подавление на данной поднесущей и больше "раздувание" шума после выравнивания, следовательно меньше достоверность бит переданных в данном символе, но интересно как это на практике будет - есть смысл так делать или нет.
|
|
|
|
|
|
|
|
Apr 15 2015, 08:43
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(serjj @ Apr 15 2015, 10:43) Почему если выбрать approximate log-likelihood ratio вместо обычного log-likelihood ratio результат не зависит от сигма шума? Прикладываю модельку с экспериментом. При этом если выбрать log-likelihood ratio то при значительной ошибке сигма и низком snr получем большой ber. В моем понимание approximate метод позволяет перейти от логарифма суммы экспонент к max/min функциям, при этом сигма выносится за скобки, но не уходит из конечного выражения. Какая-то особенность реализации матлабовского approximate log-likelihood ratio? что-то вроде автоматической нормировки сигмы к 1, на подобии той что делают на практике? Это особенность алгоритма витерби - вынесенная за скобки сигма не влияет на результат декодирования.
|
|
|
|
|
|
|
|
Apr 15 2015, 08:46
|
Гуру
Группа: Свой
Сообщений: 2 220
Регистрация: 21-10-04
Из: Balakhna
Пользователь №: 937
|
Цитата(serjj @ Apr 15 2015, 10:43) Интуитивно мне это понятно, т.к. чем меньше i-й канальный вес, тем больше подавление на данной поднесущей и больше "раздувание" шума после выравнивания, следовательно меньше достоверность бит переданных в данном символе, но интересно как это на практике будет - есть смысл так делать или нет. Вообще интуитивно понятно, что в OFDM возможности мяких кодов как бы недоиспользуются, грубо, канал нам известен из оценки, в задавленных поднесущих инфы нет, в поднесущих, где сложение лучей в фазе произошло, наоборот сигна/шум очень хороший, т. е. ошибки ближе к жёстким, как бы в такой ситуации БЧХ с исправлением стираний не сильно хуже оказался. Более того каналы с замираниями могут быть и справлены без избыточного кодирования вообще!
|
|
|
|
|
|
|
|
Apr 15 2015, 08:52
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(petrov @ Apr 15 2015, 11:46) Более того каналы с замираниями могут быть и справлены без избыточного кодирования вообще! Для OFDM этот тезис неверен именно потому, что в каждом кодовом блоке теряются биты, попадающие на спектральные нули. Для того, чтобы их восстановить, нужна небольшая избыточность. OFDMа без избыточности не бывает, так как именно избыточность кода позволяет реализовать частотное разнесение.
|
|
|
|
|
|
|
|
Apr 15 2015, 08:55
|
Знающий
Группа: Участник
Сообщений: 527
Регистрация: 4-06-14
Из: Санкт-Петербург
Пользователь №: 81 866
|
Цитата Посмотрел справку и последнюю редакцию Communications System Toolbox User's Guide для 2015a. Там в формуле с аппроксимацией есть деление на сигма в квадрате пед скобкой. При этом они ссылаются на статью Витерби ”An Intuitive Justification and a Simplified Implementation of the MAP Decoder for Convolutional Codes”, в которой нет упоминаний про уровень шума. Ага, вот здесь у них даётся мат описание алгоритмов LLR и ALLR: справка. Хотелось бы задать вопрос гуру итертивного декодирования (и мягкого декодирования вообще): Если в рассчёте метрик по методу approximate log-likelihood ratio мы вводим масштабирование на 1/sigma^2, то при меньшем snr входная достоверность каждого бита уменьшается. Логично вроде бы. Но мы полагаем, что действие шума усредненно по всем битам, тогда все метрики взвешиваются на 1/sigma^2 и при увеличении мощности шума достоверность всех бит на входе декодера уменьшается пропорционально. В процессе итераций декодера он просто скомпенсирует это уменьшение достоверности. Другое дело, если метрики взвешиваются различными коэффициентами как в приведенной выше статье с OFDM и частотно-селективными замираниями. Мое понимание, что важно не абсолютная достоверность метрик на входе декодера, а их соотношение между собой. Правильно ли я думаю?
|
|
|
|
|
|
|
|
Apr 15 2015, 09:01
|
Гуру
Группа: Свой
Сообщений: 2 220
Регистрация: 21-10-04
Из: Balakhna
Пользователь №: 937
|
Цитата(andyp @ Apr 15 2015, 11:52) Для OFDM этот тезис неверен именно потому, что в каждом кодовом блоке теряются биты, попадающие на спектральные нули. Для того, чтобы их восстановить, нужна небольшая избыточность. OFDMа без избыточности не бывает, так как именно избыточность кода позволяет реализовать частотное разнесение. Избыточность не нужна! Разнесение можно реализовать без избыточности. Цитата(serjj @ Apr 15 2015, 11:55) Правильно ли я думаю? Да.
|
|
|
|
|
|
|
|
Apr 15 2015, 10:22
|
Знающий
Группа: Участник
Сообщений: 527
Регистрация: 4-06-14
Из: Санкт-Петербург
Пользователь №: 81 866
|
Немного оффтопа. Цитата Для OFDM этот тезис неверен именно потому, что в каждом кодовом блоке теряются биты, попадающие на спектральные нули. Для того, чтобы их восстановить, нужна небольшая избыточность. OFDMа без избыточности не бывает, так как именно избыточность кода позволяет реализовать частотное разнесение. Я знаю три вида избыточности в OFDM (на уровне OFDM символов данных): избыточность FEC, избыточность CP/ZP, избыточность пилот-тонов. При этом на декодирование символов, попавших в спектральные нули, влияет только первая избыточность, которая никак не связана с OFDM. Про какую избыточность вы говорите? Цитата Более того каналы с замираниями могут быть и справлены без избыточного кодирования вообще! Согласен с andyp, то что попало в спектральные нули, может быть вытянуто только FEC'ом.
|
|
|
|
|
|
|
|
Apr 15 2015, 10:57
|
Гуру
Группа: Свой
Сообщений: 2 220
Регистрация: 21-10-04
Из: Balakhna
Пользователь №: 937
|
Цитата(serjj @ Apr 15 2015, 13:22) Согласен с andyp, то что попало в спектральные нули, может быть вытянуто только FEC'ом. Это не так, разнос битов между поднесущими может быть осуществлён без избыточности, это должно быть очевидно из возможности приёма single carrier в канале со спектральными нулями без какого-либо избыточно кодирования, single carrier можно представить в виде OFDM с прекодером.
itjul98s.pdf ( 658.31 килобайт )
Кол-во скачиваний: 144Цитата(des00 @ Apr 15 2015, 13:54) немного потроллю, а вы их (биты) адамаром размажьте каждый бит по всему спектру, а потом соберите  В точку!
|
|
|
|
|
|
|
|
Apr 15 2015, 12:50
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(des00 @ Apr 15 2015, 13:54) немного потроллю, а вы их (биты) адамаром размажьте каждый бит по всему спектру, а потом соберите Только после того, как будет открыт способ собрать На текущий момент коды адамара декодируются при помощи преобразования адамара и избыточность там есть. Цитата(petrov @ Apr 15 2015, 13:57) Это не так, разнос битов между поднесущими может быть осуществлён без избыточности, это должно быть очевидно из возможности приёма single carrier в канале со спектральными нулями без какого-либо избыточно кодирования, single carrier можно представить в виде OFDM с прекодером.
itjul98s.pdf ( 658.31 килобайт )
Кол-во скачиваний: 144Ну я вообще-то каноническую OFDM имел в виду, когда мультиплексируются поднесущие, каждая из которых модулируется. Но если Вы про это... Ну надеюсь авторы за последние >15 лет нашли способ преодолеть те "мелкие" трудности, которые стояли на пути практической реализации этой идеи.
Сообщение отредактировал andyp - Apr 15 2015, 12:50
|
|
|
|
|
|
2 чел. читают эту тему (гостей: 2, скрытых пользователей: 0)
Пользователей: 0

|
|
|