| |
 Буфер для PCI Express Буфер для PCI Express |
|
|
|
|
 Sep 2 2015, 05:59 Sep 2 2015, 05:59
|
Профессионал

Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539

|
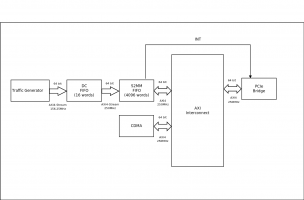
Приветствую. Собираю систему для передачи данных от 10G Ethernet по PCIe в ПК (см. рисунок). Приёмник MAC-уровня для 10G Ethernet пока моделирую Traffic Generator-ом. Прерывание от S2MM FIFO заводится в ПК и обрабатывается драйвером. Использовал DC FIFO (для перехода между clock domains, Ethernet тактируется 156.25 МГц, PCIe - 250 МГц) и S2MM FIFO (для преобразования AXI4-Stream в AXI4). S2MM FIFO генерирует прерывание либо по достижению определённого уровня заполнения, либо по приёму очередного пакета данных. Traffic Generator управляется MicroBlaze (пока, для отладки) и может генерировать пакет 1024*64bit в цикле или постоянно. Если использую прерывание по заполнению уровня (1024 позиции фифо), то приходится ставить большую задержку между запусками Traffic Generator-а, чтобы CDMA успевал выгребать данные до накопления новых 1024 позиций, иначе передача фифо забивается и прерывание больше не срабатывает. Тогда попробовал использовать прерывание по приёму пакета и забирать максимальное число данных кратное 1024 позициям фифо. Тут Traffic Generator может работать в непрерывном режиме (CDMA постоянно забирает данные), но есть ощущение, что при заполнении фифо Traffic Generator может некоторое время ожидать следующей передачи. Вопросы: 1) Правильно ли реализую сам буфер, возможно есть более удобное решение? 2) Как выбрать размер FIFO и размер разовой передачи CDMA с учётом разных скоростей работы FIFO на запись/чтение и времени, требуемого для обработки прерывания и запуска CDMA драйвером?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Sep 2 2015, 06:07
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
тупое S2MM fifo вам на 10G не поможет. скорости не те. посмотрите хотя бы как сделана интеловская сетевушка: http://www.intel.com/content/dam/www/publi...r-datasheet.pdfтам и идеология алгоритма для драйвера есть.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Sep 2 2015, 06:19
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(krux @ Sep 2 2015, 09:07)  посмотрите хотя бы как сделана интеловская сетевушка: http://www.intel.com/content/dam/www/publi...r-datasheet.pdfтам и идеология алгоритма для драйвера есть. Спасибо, посмотрю. Цитата(krux @ Sep 2 2015, 09:07) тупое S2MM fifo вам на 10G не поможет. скорости не те. А что не так с FIFO? Генератор данных заполняет его на 156.25 МГц, CDMA забирает данные на 250 МГц, шина данных 64 бита на запись/чтение. Основную проблему вижу в затратах времени на обработку прерывания длайвером и перезапуск CDMA (использую Simple DMA mode для CDMA, возможно, лучше применить Scatter Gather mode).
|
|
|
|
|
|
|
|
Sep 2 2015, 08:52
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
Цитата А что не так с FIFO? формально, с FIFO всё нормально =) прерывание-то от него сформируется как положено, однако перезарядка отработавшего DMA со стороны проца - процесс недетерминированный. поэтому к тому моменту как проц презарядит DMA, у вас во входном буфере подропается приличное количество пакетов, а если не отслеживать старт-стопы пакетов, то будет ещё нарезка кусков пакетов.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Sep 2 2015, 09:28
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(krux @ Sep 2 2015, 11:52) формально, с FIFO всё нормально =)
прерывание-то от него сформируется как положено, однако перезарядка отработавшего DMA со стороны проца - процесс недетерминированный. Вот в этом и вижу основную проблему, нельзя ли отыграть это за счёт вместимости FIFO, вычитка данных происходит со скоростью на 60 % больше чем запись? Возможно тут понадобится очень большой буфер, но как это просчитать? Думал ещё сделать ping pong memory-buffer, но получу то же, что и с ФИФО, за счёт непредсказуемости прерывания отыграться если и можно, то только за счёт размера буфера. Цитата(krux @ Sep 2 2015, 11:52) поэтому к тому моменту как проц презарядит DMA, у вас во входном буфере подропается приличное количество пакетов, а если не отслеживать старт-стопы пакетов, то будет ещё нарезка кусков пакетов. Тут получается, что на AXI4-Stream приёмник тормозит передатчик. Данные не портятся, просто происходит остановка передачи Traffic Generator-ом. PS. Мануал на Intel 82599 10 GbE Controller просмотрел, но вот информации по реализации FIFO не нашёл, там больше о буферизации на уровне драйвера.
|
|
|
|
|
|
|
|
Sep 2 2015, 16:51
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
Цитата Мануал на Intel 82599 10 GbE Controller просмотрел, но вот информации по реализации FIFO не нашёл, если коротко, то там используются: 1) 512 кбайт буферного озу 2) SGDMA 3) DMA для чтения таблиц дескрипторов 4) 16 записей для указателей (видных через BAR) 5) 16 таблиц для дескрипторов для SGDMA проц формирует в озу пк таблицы дескрипторов-указателей на буферы под хранение данных. проц заполняет записи 4) -- слейвом (ака запись в target) -- самая медленная операция после чего DMA 3) вычитывает из оперативки таблицы дескрипторов и складирует их себе в 5) сетевка готова к приему. по приему пакета SGDMA 2) берёт очередную запись из 5) и пишет данные из буфера 2) в озу пк по адресу, указанному в дескрипторе. посылает MSI. при расходовании целых таблиц из 5) посылаются прерывания на пополнение таблицы дескрипторов. проц снова формирует таблицу дескрипторов, пишет в 4) адрес где он эту табличку положил, и DMA 3) её вычитывает Цитата вычитка данных происходит со скоростью на 60 % больше чем запись вы не можете контролировать процесс формирования готовности со стороны PCIe Root Complex, поэтому в любой момент DMA-передача по PCIe может застрять на очередном отправляемом куске TLB в 128 байт. соотношение максимальных пропускных способностей AXI и FIFO здесь погоды не делают. Цитата просто происходит остановка передачи Traffic Generator в реальной жизни, в отличие от Traffic Generator-а остановить прилетающий поток невозможно.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Sep 3 2015, 06:46
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(krux @ Sep 2 2015, 19:51) в реальной жизни, в отличие от Traffic Generator-а остановить прилетающий поток невозможно. тут имелл ввиду, что поток генератора трафика тормозится сигналом ready от слейва AXI4-Stream. Цитата(krux @ Sep 2 2015, 19:51) если коротко, то там используются:
1) 512 кбайт буферного озу
2) SGDMA
3) DMA для чтения таблиц дескрипторов
4) 16 записей для указателей (видных через BAR)
5) 16 таблиц для дескрипторов для SGDMA
проц формирует в озу пк таблицы дескрипторов-указателей на буферы под хранение данных.
проц заполняет записи 4) -- слейвом (ака запись в target) -- самая медленная операция
после чего DMA 3) вычитывает из оперативки таблицы дескрипторов и складирует их себе в 5)
сетевка готова к приему.
по приему пакета SGDMA 2) берёт очередную запись из 5) и пишет данные из буфера 2) в озу пк по адресу, указанному в дескрипторе. посылает MSI.
при расходовании целых таблиц из 5) посылаются прерывания на пополнение таблицы дескрипторов.
проц снова формирует таблицу дескрипторов, пишет в 4) адрес где он эту табличку положил, и DMA 3) её вычитывает В доке Intel есть упоминание о Rx FIFO, в которое данные (пакет) поступают после прохождения фильтра. Как понимаю, его я и пытаюсь реализовать. Всё остальное - это работа драйвера, который ваделяет буферы в ПК, перезапускает DMA. Тут я не совсем понимаю, как происходит передача данных без потери. Ведь на обработку прерывания и перезапуск DMA опять же требуется время и достаточно много. Даже если работает SgDMA, ему также нужно обновлять цепочку дескрипторов. Что если вместо MM ядра CDMA попытаться использовать ядро DMA (v7.1) в режиме SgDMA S2MM и зациклить ему цепочку дескрипторов? Т.е. выбрасываем из системы (см. рисунок) S2MM FIFO и CDMA, ставим DMA, и DMA будет принимать поток AXI4-Stream и сразу складывать в буферы в ПК выделяемые драйвером устройства. Потеря данных будет только если user space application не успевает вычитывать данные из буферов драйвера, т.е. если все буферы заполнены идёт перезапись. Подойдёт ли такой вариант?
|
|
|
|
|
|
|
|
Sep 3 2015, 08:32
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
1 таблица дескрипторов - это 128 буферов, на 128 SGDMA операций. таблиц 16. т.е. в самом худшем случае, если перезарядок со стороны проца не будет некоторое время - SGDMA сможет запуститься 1024 раза, передав по 4 кбайта на каждом запуске. Цитата зациклить ему цепочку дескрипторов зациклить - не советую, поскольку если проц не успеет их обработать - то DMA их может затереть записав следующие данные поверх.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Sep 28 2015, 12:23
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(doom13 @ Sep 3 2015, 09:46) Что если вместо MM ядра CDMA попытаться использовать ядро Зачи(v7.1) в режиме SgDMA S2MM и зациклить ему цепочку дескрипторов?
Т.е. выбрасываем из системы (см. рисунок) S2MM FIFO и CDMA, ставим DMA, и DMA будет принимать поток AXI4-Stream и сразу складывать в буферы в ПК выделяемые драйвером устройства. Потеря данных будет только если user space application не успевает вычитывать данные из буферов драйвера, т.е. если все буферы заполнены идёт перезапись. Подойдёт ли такой вариант? Для Ethernet это как раз более правильное решение чем CDMA. Проще структура пересылок данных. К тому же можно взять за основу его драйвер. Однако на входе DMA нужно FIFO для буферизации коротких затыков на PCIe шине. Дескрипторы проще размещать в системной памяти. Опят же со стороны драйвера проще и быстрее их (дескрипторы ) обрабатывать. Смотрите доки на DMA - как работать с кольцом дескрипторов. Там все продуманно - затирки данных не будет в худшем случае просто потеря новых данных. Успехов! Rob.
|
|
|
|
|
|
|
|
Sep 28 2015, 13:00
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Sep 28 2015, 15:23) Для Ethernet это как раз более правильное решение чем CDMA. Проще структура пересылок данных. К тому же можно взять за основу его драйвер. Однако на входе DMA нужно FIFO для буферизации коротких затыков на PCIe шине. Спасибо, долго тупил на этом вопросе, но вот уже начал разбираться с работой DMA S2MM. А как рассчитать размер этого FIFO? Цитата(RobFPGA @ Sep 28 2015, 15:23) Дескрипторы проще размещать в системной памяти. Опят же со стороны драйвера проще и быстрее их (дескрипторы ) обрабатывать. А не возникнет ли тут проблем по доступу к дескрипторам со стороны DMA (ему-то проще получать доступ к памяти в FPGA), как найти тут "золотую середину"? Цитата(RobFPGA @ Sep 28 2015, 15:23) Смотрите доки на DMA - как работать с кольцом дескрипторов. Там все продуманно - затирки данных не будет в худшем случае просто потеря новых данных. Может быть посоветуете что-то конкретное? Спасибо. Пока есть такие вот варианты c применением DMA S2MM, не знаю какой выбрать: 1) Создаём N таблиц по M дескрипторов. По завершению таблицы DMA генерирует прерывание. В прерывании драйвер перенастраивает DMA на следующую таблицу и перезапускает его. Далее система начинает обрабатывать данные соответствующие отработанной таблице дескрипторов. Тут вопрос с FIFO, на прерывание (перезапуск DMA) потратится какое-то время, а поток данных идёт и хотелось бы их сохранить. 2) Второй вариант - кольцо дескрипторов (если всё правильно понял). Создаём кольцо дескрипторов и запускаем DMA S2MM, при обработке дескриптора DMA генерит прерывание, а сам переходит к следующему дескриптору. По прерыванию система обрабатывает полученные данные и возвращает дескриптор в цепочку. Тут будет тормозить если система не успевает возвращать обработанные дескрипторы в цепочку. Т.е. получим, что система будет тормозить работу DMA, только каким образом - обрабатывать и возвращать в кольцо по одному дескриптору или обработает и вернёт все накопленные дескрипторы? В приведённой выше доке на 10G карту используется несколько таблиц дескрипторов, но не понял для чего. Если софт обновляет (возвращает) дескрипторы в кольцо, то зачем нужна другая (16 шт., если правильно понял) таблица. Возможно, если DMA обрабатывает все дескрипторы из таблицы, чтобы софт долго не тормозил DMA, идёт прерывание и переключение на следующую таблицу?
|
|
|
|
|
|
|
|
Sep 28 2015, 14:23
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Для начала почитайте LogiCORE IP AXI DMA v6.00.a Product Guide (pg021_axi_dma.pdf) В более новых доках отсутствуют понятные картинки про ring buffer.  Я обычно ставлю FIFO как минимум на пару пакетов максимального размера. Конкретно это сильно зависит от конфигурации системы - соотношения средней полосы PCIe r к полосе траффика 10G, другой активности через этот же сегмент PCIe шины, и.т.д. и.т.п. Ну и также Ваших хотелок по допустимым потерям пакетов. DMA в режиме SG "кеширует" в локальном FIFO 3 дескриптора, сглаживая latecy при чтении дескрипторов. Однако это может быть недостаточно если предполагается трафик с большим количеством малых пакетов и при этом еще и желательно разбивка этих пакетов на отдельные буфера в системной памяти В этом случае можно дескрипторы располагать и в памяти FPGA . Но при этом существенно усложняется драйвер (для гарантированного получения пиковых характеристик). Есть еще куча промежуточных вариантов, но это уже все экзотика - Опят же тут надо четко представлять себе требования к системе в целом. Вариант N2 - Вы можете и миллион дескрипторов закольцевать - лишь бы памяти хватило - настроить iterrupt coalesing в DMA и потом не спеша перебирать эти "четки" выискивая в пришедших горах мусо... ..данных крупицы истины. Но опят же ничто не даром под луной - latecy обработки пакетов в этом случае будет большой. Сложная структура дескрипторов в сетевых картах позволяет разгрузить софт от рутинных дел - например разгребать траффик от разных источников и переслать напрямую его на выделенный проц. в многопроцессорных системах, приоритеты пересылки для разного типа пакетов, и кучу других приятных плюшек. Никто не мешает Вам сделать все тоже самое если нужно и даже больше - главное тут понять - а оно нам нужно?  Начните с малого/простого - запустите 10G Ethernet  Успехов! Rob.
|
|
|
|
|
|
|
|
Sep 28 2015, 15:07
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Sep 28 2015, 17:23) Для начала почитайте LogiCORE IP AXI DMA v6.00.a Product Guide (pg021_axi_dma.pdf) В более новых доках отсутствуют понятные картинки про ring buffer. Спасибо, смотрю, есть картинки, которых у меня не было. Цитата(RobFPGA @ Sep 28 2015, 17:23) Я обычно ставлю FIFO как минимум на пару пакетов максимального размера. Конкретно это сильно зависит от конфигурации системы - соотношения средней полосы PCIe r к полосе траффика 10G, другой активности через этот же сегмент PCIe шины, и.т.д. и.т.п. Ну и также Ваших хотелок по допустимым потерям пакетов.
DMA в режиме SG "кеширует" в локальном FIFO 3 дескриптора, сглаживая latecy при чтении дескрипторов. Однако это может быть недостаточно если предполагается трафик с большим количеством малых пакетов и при этом еще и желательно разбивка этих пакетов на отдельные буфера в системной памяти В этом случае можно дескрипторы располагать и в памяти FPGA . Но при этом существенно усложняется драйвер (для гарантированного получения пиковых характеристик).
Есть еще куча промежуточных вариантов, но это уже все экзотика - Опят же тут надо четко представлять себе требования к системе в целом.
Вариант N2 - Вы можете и миллион дескрипторов закольцевать - лишь бы памяти хватило - настроить iterrupt coalesing в DMA и потом не спеша перебирать эти "четки" выискивая в пришедших горах мусо... ..данных крупицы истины. Но опят же ничто не даром под луной - latecy обработки пакетов в этом случае будет большой. Система будет состоять из приёма 10G Ethernet трафика и передачи его по PCIe в ПК. По 10G Ethernet принимается непрерывный поток данных от плат АЦП. Соединение "точка-точка" - мусор отсутствует, только полезные данные. Цитата(RobFPGA @ Sep 28 2015, 17:23) Начните с малого/простого - запустите 10G Ethernet Это уже готово (возможно, понадобится усложнить систему, но данные с платы на плату погонял).
|
|
|
|
|
|
|
|
Sep 28 2015, 15:47
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(doom13 @ Sep 28 2015, 18:07) Система будет состоять из приёма 10G Ethernet трафика и передачи его по PCIe в ПК. По 10G Ethernet принимается непрерывный поток данных от плат АЦП. Соединение "точка-точка" - мусор отсутствует, только полезные данные. Увы - пока я Вашего слона представляю как нечто похожее на веревку  Плат АЦП у Вас несколько? Каков траффик средний/пиковый? Будет ли lose-less режим 10G MAC? каков протокол передачи данных/управления платами? Нужен ли контроль целостности/непрервыности данных? необходима ли заливка потока данных каждого АЦП в независимый буфер? Нужена ли преобработка/статистика данных? Режимы работы? ................... Ну а если по простому гнать пакеты в одну сторону то 800-900 MB/s можно получить без проблем. Естетсвенно если у Ваc слон хотябы о 4 ногах и желателно в версии 2 Успехов! Rob.
|
|
|
|
|
|
|
|
Sep 28 2015, 16:08
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Sep 28 2015, 18:47) Что-то мы ушли от темы. Считаем, что есть генератор трафика (просто пакеты данных) с максимальным потоком данных 10Gbit/s, шина данных 64 бита, тактовая частота 156.25 MHz и надо всё это запихнуть в ПК по PCIe. Пока сделал, как на рисунке выше, но вижу, что это неправильно, и начинаю попытки запустить DMA S2MM. А тут есть вопросы, как правильно идет формирование и работа с дескрипторами.
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|