| |
|
  |
 Bus Master DMA для PCIe Bus Master DMA для PCIe |
|
|
|
|
 Oct 8 2015, 19:17 Oct 8 2015, 19:17
|
Профессионал

Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539

|
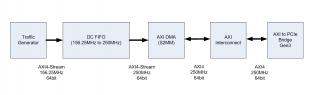
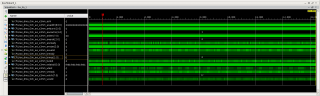
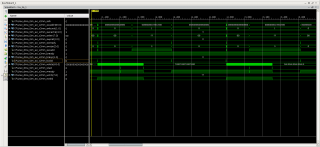
Приветствую. Собрал систему (см. рисунок) для передачи данных по PCIe. Ядро AXI Bridge for PCIe сконфигурировано в режиме x4, 64 bit, 250MHz, должно позволить прокачивать поток 16 Гбит/с. В качестве DMA используется ядро AXI DMA v7.1 в режиме Scatter-Gather. Кольцо дескрипторов и буферы данных выделяются в памяти ядра Linux. Ранее было сделано так, пропускная способность канала составляла ~6 Гбит/с. Тут опять упёрся в 6 Гбит/с, думал, что софт ограничивает производительность канала. Потом убрал вмешательство системы в работу DMA - инициализирую кольцо дескрипторов, запускаю DMA. DMA бросает данные пока не закончатся дескрипторы. Оценивая время обработки кольца дескрипторов и переданный объём данных, получаю чуть больше 6 Гбит/с. Вытянул сигналы AXI4-Stream между FIFO и DMA на ILA, вижу - FIFO держит TVALID всегда в 1, а DMA периодически (очень часто) сбрасывает TREADY в 0. Получается DMA является виновником ограничения скорости потока. В доке вычитал, что в тестах получали пропускную способность до ~70%, но это ~11,2 Гбит/с, меня бы устроило. Вопрос - как поднять производительность DMA? Как понимаю, AXI Interconnect и PCIe мост могут тормозить DMA?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 8 2015, 19:44
|
Местный
Группа: Свой
Сообщений: 372
Регистрация: 14-02-06
Пользователь №: 14 339
|
Цитата(doom13 @ Oct 8 2015, 22:17)  Кольцо дескрипторов ... выделяется в памяти ядра Linux. Может в этом причина ? Посмотрите анализатором очередность транзакций на шине axi.
|
|
|
|
|
|
|
|
Oct 9 2015, 13:23
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
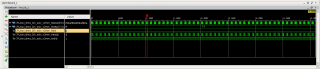
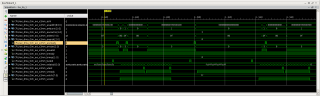
На AXI4 между DMA и AXI Interconnect вот такая штука (тут даже не пойму на какой из сигналов настроить триггер): PS: Триггер настроен на TLAST для AXI4-Stream (FIFO->DMA). PSPS: Тут, как понимаю, Slave (AXI Interconnect) выставил WREADY, а Master (DMA) ещё очень долго тупит. Получается, что все проблемы из-за DMA? Или надо ещё смотреть и на BVALID?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 10 2015, 10:34
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
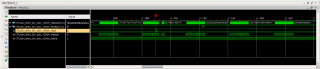
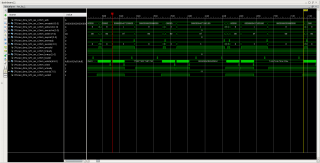
Засинхронизировал триггер по начальному адресу буфера (0х0000_0004_0720_0000) на который ссылается первый дескриптор в кольце. На рисунке сечение DMA-AXI Interconnect, для AXI Interconnect-PCIe Bridge диаграмма такая же. Нужна помощь в анализе, что тут работает неправильно (медленно) и получится ли ускорить? Если всё правильно понимаю, то WVALID ждёт подтверждения записи BVALID для второго burst-a и только потом устанавливается в 1. Как-то можно повлиять на более быстрое появления BVALID и, как следствие, на WVALID?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 10 2015, 14:13
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
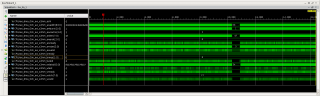
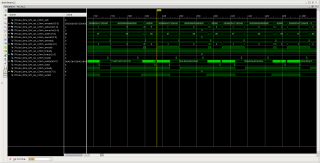
Увеличил burst size для DMA до максимального 256, а вместе с этим увеличилось время от WLAST до BVALID. Что за ерунда? Где тут увеличение производительности? Время от WLAST до BVALID должно было остаться таким же, как и при значении burst 16??? Если нет, за счёт чего тут можно было получить увеличение производительности DMA??? Спасибо.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 10 2015, 21:23
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(toshas @ Oct 10 2015, 23:34) Мне кажется pcie-mm всегда позиционировалось как удобное решение для микропроцессорной системы, не более того, при этом максимальной скорости он него никто и не требовал. А я думал это ядро и есть самое то, что Xilinx предлагает для работы с PCIe, а оно вот как оказывается  Цитата(toshas @ Oct 10 2015, 23:34) Однако для получения максимальных скоростей очень вероятно придется самому с нуля писать dma для голого ядра pcie.
Или посмотреть на работу dsmv. Вот с нуля делать и не хотелось. Разбираться с DS_DMA показалось очень сложным, решил на готовых ядрах собрать систему, счас надо думать, куда двигать дальше. Цитата(toshas @ Oct 10 2015, 23:34) Или дождаться что же xilinx предложит как альтернативу (xdma). Стоимость может оказаться невысокой или вообще бесплатной. Почти дождался - вчера слил, установил, посмотрел. Остался вопрос с мануалом на это чудо-ядро XDMA. Мне его давать не хотят, так что если кто помог бы с описанием ядра, был бы очень благодарен. Цитата(toshas @ Oct 10 2015, 23:34) В чем точно происходит затык в вашем случае было бы интересно выяснить. А может ли как-то система (драйвер) влиять на такую длительность появления BVALID? В ядре есть много способов выделения памяти, может я использую неправильный (пользуюсь kmalloc)? Мне пока нужно выжать с системы 10 Гбит/с. Можно наверное настроить мост на работу с PCIe Gen 3, пропускная способность должна будет возрасти. Тут только придётся подбирать более навороченную систему для работы с платой, мой рабочий ПК подойдёт, а вот тот, что будем использовать в проекте???
|
|
|
|
|
|
|
|
Oct 11 2015, 20:19
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
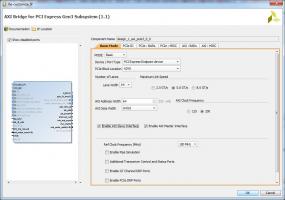
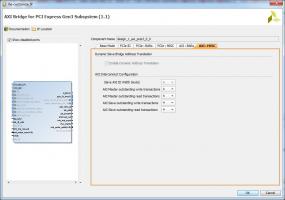
Цитата(RobFPGA @ Oct 11 2015, 15:20) Для начала неплохо бы убедится что PCIe действительно работает в x4 Gen2, каков размер payload. Настройки для моста стоят именно такие (см. рисунок). По поводу payload не понял, что это, такой опции там нет. Есть ещё вкладка (второй рисунок) с опциями для моста (можно выбирать 2/4/8), но с ней не разбирался, надо глянуть, за что оно отвечает. Цитата(RobFPGA @ Oct 11 2015, 15:20) А правильнее было бы на модели в симуляторе посмотреть что и как работает, какова скорость передачи и что и как тормозит передачу. И уж если на модели скорость будет ОК то только тогда разбирается на рабочей системе сравнивая с моделью что не так. Не совсем представляю, как это всё проверять в симуляторе. Завтра думаю проверить как быстро DMA будет бросать данные в память FPGA, но тут наверное всё будет работать быстрее.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|