| |
|
  |
 Коды БЧХ Коды БЧХ, Вопросы по алгоритмам декодирования |
|
|
|
|
 Sep 5 2012, 17:06 Sep 5 2012, 17:06
|
Участник

Группа: Участник
Сообщений: 17
Регистрация: 22-03-12
Пользователь №: 70 951

|
На 200-400 бит вполне пойдет код Рида-Соломона...
Этот код достаточно прост в реализации до (255, на сколько нибудь там) так как единица с которой прийдется оперерировать при декодировании равна 8 битам тоесть одному байту что значительно упощает програмную реализацию. Если хотите брать блоки большей длинны то уже будет не байта 9 бит 10 и.т.д. ... максимально возможная длинна блока при разрядности n определяется как 2 в степени n минус 1.
Пример:
вот как раз если рассматривать единицу кодирования-декодирования как байт(8 бит) получается 2^8 - 1 = 255
Число на сколько нибудь выбирается в зависимости от того сколько информации хотите передать и сколько ошибок в блоке хотите исправить
Пример:
В начале выбиаем размер блока допустим 200
Затем Кол-во ошибок которое хотим исправить допустим 10
Теперь прикидываем для того чтобы нам исправить 10 ошибок нам над добавить 20 дополнительных символов к информационным
(Напоминаю что мы говорим про единицу 1 байт что означает если 10 ошибок значит 10 байт = 80 бит)
в итоге получается что информационных символов у нас остается 200 - 20 = 180 получаем код (200,180)
Спрашивается если код такой хороший почему бы его не пнррименять вместо турбокодов и LDPC? Я уже говорил что алгоритм декодирования кда единица кодирования равна 1 байту достаточно быстр но с 9 битами уже сложнее и далее если будем увеличивать алгоритм будет замедляться и избыточная информация рости (никто же не будет при коде 10000 исправлять в нем только 10 ошибок это малавато будет)
Алгоритм декодирования тубокодов намного быстрее потому и применяют ....
|
|
|
|
|
|
|
|
Nov 15 2013, 11:16
|

Частый гость
Группа: Свой
Сообщений: 163
Регистрация: 3-09-04
Пользователь №: 586
|
Цитата(Mikhalych @ Sep 28 2010, 16:26)  Недавно сам занимался аппаратной реализацией такого декодера - вообщемто всё удачно получилось.
Вот что я тогда нашёл по этой тематике:
h__p://depositfiles.com/files/zmz0ppjzi Уважаемый Михалыч, не могли бы Вы перезалить вашу подборку, а то на депозите ее уже нет. Заранее спасибо
|
|
|
|
|
|
|
|
Jan 11 2016, 07:57
|
Частый гость
Группа: Участник
Сообщений: 100
Регистрация: 4-04-07
Пользователь №: 26 768
|
Всем привет! Недавно приступил к изучению кодов БЧХ. После изучения нескольких статей появились вопросы, касающиеся вычисления синдромов. В стандартном варианте достаточно пропустить принятое кодовое слово через сумматор и умножитель на элементы поля Галуа первых степеней. Например, синдром с индексом 1 получается равным элементу с индексом, соответствующим номеру позиции ошибки, если ошибка одна. Если их несколько, результат синдрома будет равен элементу, полученному в результате сложения элементов поля Галуа с индексами, соответствующих позициям ошибочных бит в кодовом слове. Но в одной из статей предлагается вычислять синдромы с помощью деления входного кодового слова на порождающий полином. Т.е. входное кодовое слово пропускают через сдвиговый регистр, структура которого определяется порождающим полиномом. А потом из полученного значения умудряются каким то образом получить величину синдрома. Написал программку, чтобы посмотреть, что за значения получаются. Как оказалось результат деления равен значению элемента синдрома. Но как уверяется в статье (прикрепил к сообщению) это еще не есть значение синдрома. Вообще для дальнейших операций декодирования нужно ведь знать индексы элементов? Они определяются с помощью ROM, содержащих элементы поля Галуа?
Сообщение отредактировал Neznaika - Jan 11 2016, 08:00
|
|
|
|
|
|
|
|
Jan 25 2016, 13:39
|
Частый гость
Группа: Участник
Сообщений: 100
Регистрация: 4-04-07
Пользователь №: 26 768
|
Появились определенные успехи в изучении БЧХ-кодов. Наткнулся на хорошую статью, где приведен пример умножения 2-х элементов поля Галуа через представление их в композитном поле. Все здорово и прекрасно, вроде как стало понятно. Взял даже другие элементы поля из примера и перемножил, все получилось верно. Но стоило попробовать повторить эту процедуру в поле со степенью 14, разложив его на 2 и 7, и ничего не получилось. Кто-нибудь возился с композитными полями и может легко посчитать матрицу перехода?
Прикрепленные файлы
 OLA_28.pdf
OLA_28.pdf ( 294.98 килобайт )
Кол-во скачиваний: 82
|
|
|
|
|
|
|
|
Jan 26 2016, 11:46
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(Neznaika @ Jan 11 2016, 10:57) ...Но в одной из статей предлагается вычислять синдромы с помощью деления входного кодового слова на порождающий полином. Т.е. входное кодовое слово пропускают через сдвиговый регистр, структура которого определяется порождающим полиномом. А потом из полученного значения умудряются каким то образом получить величину синдрома. Написал программку, чтобы посмотреть, что за значения получаются. Как оказалось результат деления равен значению элемента синдрома. Но как уверяется в статье (прикрепил к сообщению) это еще не есть значение синдрома. Пусть синдромный полином s(x) является остатком от деления принятого полинома r(x) на генерирующий полином кода g(x): r(x) = quotient(x) * g(x) + s(x); Значения синдромов вычисляются как r(a_i), a_i - корни генерирующего полинома в поле-расширении, т.е. g(a_i) = 0 - это свойство кода БЧХ; Поэтому r(a_i) = quotient(a_i) * 0 + s(a_i); r(a_i) = s(a_i); Т.е. синдромы можно считать как значения синдромного полинома-остатка. Достоинство в том, что степень синдромного полинома меньше степени принятого.
|
|
|
|
|
|
|
|
Jan 27 2016, 07:53
|
Частый гость
Группа: Участник
Сообщений: 100
Регистрация: 4-04-07
Пользователь №: 26 768
|
Так то оно так.. но как я понимаю, мы получаем путем деления r(x), а не r(a_i). Хотя по полученному результату очень похоже на r(a_i)=s(a_i). А значения s(a_i^2), s(a_i^4)... они как получаются? Там нарисовано волшебное облако. Кроме как поставить там умножители s(a_i)* s(a_i) и s(a_i)* s(a_i)*s(a_i)* s(a_i)... у меня идей нету. Но по ресурсам это не оправдано, можно же просто вычислять s(a_i), s(a_i^2) по отдельности с помощью одного умножителя, регистра и сумматора. Хотя... может и оправдано. Получится, что нам не потребуются на a_i^2, a_i^4.. регистры и сумматоры, но появится задержка в вычислении. В статье говориться про какую то магическую матрицу - не понимаю как она может помочь делу.
Сообщение отредактировал Neznaika - Jan 27 2016, 08:00
|
|
|
|
|
|
|
|
Jan 27 2016, 11:56
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(Neznaika @ Jan 27 2016, 10:53) ...А значения s(a_i^2), s(a_i^4)... они как получаются? Там нарисовано волшебное облако. Кроме как поставить там умножители s(a_i)* s(a_i) и s(a_i)* s(a_i)*s(a_i)* s(a_i)... у меня идей нету. Но по ресурсам это не оправдано, можно же просто вычислять s(a_i), s(a_i^2) по отдельности с помощью одного умножителя, регистра и сумматора. Хотя... может и оправдано. Получится, что нам не потребуются на a_i^2, a_i^4.. регистры и сумматоры, но появится задержка в вычислении. В статье говориться про какую то магическую матрицу - не понимаю как она может помочь делу. В статье все сделано "в лоб": 1. сначала считают остатки от деления принятого полинома на 13 минимальных. В результате получается по 16 коэффициентов полинома-остатка. Коэффициенты из GF(2). Это регистровая логика. 2. затем для каждого a_i, для которого требуется подсчитать синдром, из таблицы элементов поля по степеням i выбирают a_i, (a_i)^2, (a_i)^3 и т.п полученные значения суммируют (xor - ят) друг с дружкой, если коэффициент при этой степени с полиноме-остатке, полученном на предыдущем шаге, ненулевой. Это у них облачко с комбинаторной логикой. Значения степеней, записанные по столбцам - это у них матрица В. Т.к. в зависимости от i элемент поля a_i попадает в тот или иной циклотомический класс, то в зависимости от класса берут тот или иной минимальный полином на первом шаге. Какие элементы соответствуют какому полиному, показано на картинке.
|
|
|
|
|
|
|
|
Jan 29 2016, 11:58
|
Частый гость
Группа: Участник
Сообщений: 100
Регистрация: 4-04-07
Пользователь №: 26 768
|
Я понял.. это ВЫ маг и волшебник) А я всего лишь плохо учюсь..
Попробуем меня пробить по примеру.
Допустим мы имеем 2 ошибки в 40 и 57 битах.
Остаток деления от первого полинома будет регистровое число равное значению элемента поля с индексом 40+57=97.
Нужно вычислить синдромы s1(a_1), s2(a_2), s3(a_3), s_4(a_4).. По остатку от первого полинома можно вычислить s1(a_1), s2(a_2), s4(a_4) и т.д...
Для вычисления s1(a_1) берем из поля Галуа значение (пусть 16 бит) 0100 0000 0000 0000, начиная с младшего. Для a_1 выбираем из таблицы поля Галуа элементы с индексами а_(1*2), а_(1*3), а_(1*4)... а_(1*16). Затем XORим те значения индексы которых соответствуют не нулевым битам результата деления. Т.е. если мы получили в регистре полинома регистровое значение 1001 0010 0000 0000, то XORим значения a_1 xor a_4 xor a_7=s1(a_1). Так?
А для s2(a_2)= a_2 xor a_8 xor a_14. Угу?
Матрица B - просто список степеней относящихся к каждому а_i. Т.е. имеем 16 матриц. Матрица для а_1 содержит адреса степеней. По 0-му адресу этой матрицы - просто 1-ца, по 1-му - 2, по 2-му - 4... по 15 - 1*16=16. И так для каждого а_i?
Получается по реализации структуры с умножителем на a_i, регистром и сумматор значительно меньше кушают ресурсов, чем вычисление полинома-остатка и использование матрицы B?
Поправьте меня, пожалуйста, где я заблуждаюсь. Спасибо)
|
|
|
|
|
|
|
|
Jan 29 2016, 16:42
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(Neznaika @ Jan 29 2016, 14:58) Поправьте меня, пожалуйста, где я заблуждаюсь. Спасибо) Давайте так: я задам один вопрос, если ответ вам ясен, то дальше разбираться смысла нет (Вы все поняли). Если ответ не ясен, я тогда еще пояснить попробую. Вопрос: На картинке с облачками в статье на ножке S1 облачка нет. Почему? А то писать много и матлабить не очень хочется.
Сообщение отредактировал andyp - Jan 29 2016, 16:44
|
|
|
|
|
|
|
|
Feb 1 2016, 13:38
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(Neznaika @ Feb 1 2016, 10:56) Как я понимаю, результат деления на первый полином является значением синдрома s1(a_1). А те облака - это матрица B, по которой определяем индексы (a_1)^2, (a_1)^4, (a^1)^8 и (а^1)^16 и в зависимости от ненулевых бит s1(a_1) ХОRим значения элементов этих квадратных индексов из поля Галуа. Матрица В нужна нам для получения индексов степеней, относящихся к квадратам. Угу? Да, все так и есть. Вы молодец. Вот пример кода на октаве, рассчитывающий полиномы-остатки и собственно значения синдромов Код %Вычисление синдромов
%Устанавливаем нужный нам примитивный полином поля - он соответствует минимальному полиному для a^1
p = zeros(1,17); p([16,5,3,2,0]+1) = 1;
%по матлабовским соглашениям самый левый коэффициент - старший
p_dec = bi2de(p); p = fliplr(p);
%Предполагаем нулевое кодовое слово и 2 ошибки: в 40 и 57 бите,
%Будем рассматривать скажем 256-битные слова (укороченный код), чтобы упростить себе жизнь
r = zeros(1, 256);
r(41) = 1;
r(58) = 1;
r = fliplr(r);
%получаем принятый полином с коэффициентами из GF(2)
r = gf(r,1);
%используем минимальный полином для нахождения остатка :
m = gf(p,1);
%остаток:
[ans,s] = deconv(r,m);
%избавляемся от нулевых коэффициентов в старших степенях
s = fliplr(fliplr(s)(1:length(m)-1));
%выводим полученный остаток (старшая степень слева!!!)
printf('Syndrom polynomial: ')
printf('%i', s);
printf('\n');
%посчитаем S1.
S1 = gf(bi2de(fliplr(s.x)),16,p_dec);
printf('S1: %i = alpha^%i\n', S1.x, log(S1));
%вектор из length(m)-1 примитивных элементов поля
alphas = gf(2*ones(1,length(m)-1),16,p_dec);
%посчитаем для примера какой-нибудь синдром из певого циклотомического косета,
%использующий тот же минимальный полином и, соответственно, остаток
%матрица B (как в статье) содержит (a^synd_num)^1... (a^synd_num)^16
synd_num = 4;
B = alphas.^([15:-1:1 0]*synd_num);
Synd = gf(0,16,p_dec);
%собственно вычисление значения синдромного полинома
for ii = 1:length(s)
if s(ii) == gf(1,1)
Synd = Synd + B(ii);
end
end
printf('S%i: %i = alpha^%i\n', synd_num, Synd.x, log(Synd)); И результат выполнения: >> synd_test Syndrom polynomial: 0000101110011011 S1: 2971 = alpha^824 S4: 39678 = alpha^3296 Надеюсь, что нигде не накосячил.
|
|
|
|
|
|
|
|
Feb 2 2016, 07:02
|
Частый гость
Группа: Участник
Сообщений: 100
Регистрация: 4-04-07
Пользователь №: 26 768
|
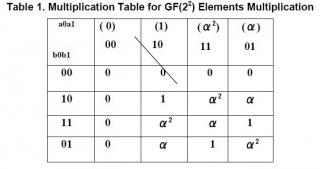
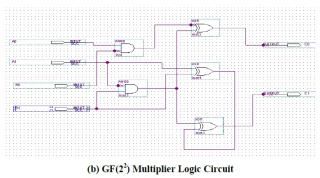
Спасибо, большое) Вы сделали все возможное и невозможное для разрешения моего вопроса. Стал замахиваться на реализацию умножителя в композитном поле Галуа на базе умножителей в базовом поле GF(2^2). Нашел любопытную статью с более-менее внятным описанием того, как это делается.. но первое же вычисление вызвало недоумение. Они взяли два элемента из GF(2^2) и перемножили их в параметрическом виде, т.е.: C=c0+c1*alpha=(a0+a1*alpha)*(b0+b1*alpha)=a0b0+a1b1+(a1+b1+a1b1)*alpha Эту формулу они и реализовали на логике и ссылаются на таблицу в которой приведены результаты перемножения. Эта статья, кусочек вычисления и сама схема прикреплена к сообщению. Но почему то результаты умножения из таблицы никак не согласованы с их вычислениями и схемой. После моего перемножения получается немного другой результат и на его основе можно получить значения из таблицы: С=a0b0+a1b1+(a1b0+a0b1+a1b1)*alpha Может я чего то не понимаю и там подключены более высокие материи?
Эскизы прикрепленных изображений
Прикрепленные файлы
25.pdf ( 384.84 килобайт )
Кол-во скачиваний: 13
|
|
|
|
|
|
|
|
2 чел. читают эту тему (гостей: 2, скрытых пользователей: 0)
Пользователей: 0

|
|
|