| |
|
  |
 Параллельная шина внутри ПЛИС Параллельная шина внутри ПЛИС, можно ли упростить? |
|
|
|
|
 Jul 25 2016, 08:59 Jul 25 2016, 08:59
|

Универсальный солдатик

Группа: Модераторы
Сообщений: 8 634
Регистрация: 1-11-05
Из: Минск
Пользователь №: 10 362

|
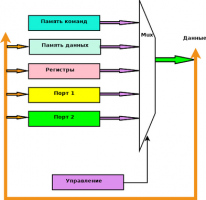
Есть внешняя шина, подключенная к микроконтроллеру. Внутри ПЛИС к шине подключено несколько устройств. В ПЛИС они объединяются по "или", не смотря, что сигналы описаны с z-состоянием. Потому что внутри ПЛИС таких буферов нет (экзотику обсуждать не предлагаю). Представим 8 16-битовых устройств, и все по "или" объединить. Много логики отъедается. Кстати, я хочу так и описать эту шину, как она реально создается. Если проще не станет, так хотя бы, понятнее. Нет ли иного способа прочитать устройства? Например, медленные читать последовательно? Точно, сковать всех одной цепью!  И по SPI выбросить. А еще как...?
|
|
|
|
|
|
|
|
Jul 25 2016, 09:05
|
Гуру
Группа: Модераторы
Сообщений: 4 011
Регистрация: 8-09-05
Из: спб
Пользователь №: 8 369
|
Цитата(ViKo @ Jul 25 2016, 11:59)  Есть внешняя шина, подключенная к микроконтроллеру. Внутри ПЛИС к шине подключено несколько устройств. В ПЛИС они объединяются по "или", не смотря, что сигналы описаны с z-состоянием. Потому что внутри ПЛИС таких буферов нет (экзотику обсуждать не предлагаю). Представим 8 16-битовых устройств, и все по "или" объединить. Много логики отъедается. Кстати, я хочу так и описать эту шину, как она реально создается. Если проще не станет, так хотя бы, понятнее. Нет ли иного способа прочитать устройства? Например, медленные читать последовательно? Точно, сковать всех одной цепью! И по SPI выбросить. А еще как...? Да, шина в ПЛИС разделится на две. Одна - шина на запись пройдет ко всем абонентам в ПЛИС параллельно. А от этих абонентов соберется куча шин и пройдет через мультиплексор и далее на выход через трехстабильные буфера... Но, поскольку клоки в ПЛИС на порядок быстрее, то дело можно упростить... Сначала надо написать за сколько времени происходит обмен по шине "снаружи" ПЛИС и какова тактовая внутри ПЛИС? Возможно удастся сделать на "входе" в ПЛИС преобразователь из паралл. в послед (например хотя бы в тетрады или в байты). и внутри далее разрядность шины уменьшить... И, кстати, при чтении из ПЛИС надо давать 1 такт задержки на открытие шинников из ПЛИС, иначе они греются сильно...
--------------------
www.iosifk.narod.ru
|
|
|
|
|
|
|
|
Jul 25 2016, 13:23
|
Гуру
Группа: Модераторы
Сообщений: 4 011
Регистрация: 8-09-05
Из: спб
Пользователь №: 8 369
|
Цитата(_pv @ Jul 25 2016, 14:52) daisy chain конечно здорово, но вот если устройств сильно много, частота работы не упрётся во время прохождения через всех подряд?
точнее вопрос даже: как именно это обычно делается в каких-нибудь процессорах когда есть куча memory maped регистров на шине памяти и без z состояния. В ПЛИС для этой цели есть "регистровый файл", который делается из "памяти"... Берем память с раздельными шинами на чтение и запись или двухпортовку, со стороны логики пишем (читаем), со стороны процессора - читаем (пишем)... Дешифрация памяти - встроенная, объем довольно большой... Или скажем берем "двухпортовку", по одной стороне используем небольшую часть как регистры, по другой - используем как остальную память... Или вот так... У Ксайлинкса есть блоки памяти 16х1 из одной ячейки SRL... 16 таких блочков дадут поле 16х16... У более новых - это 64х1... Думаю что 16 регистров - вполне хватит для начала... И это всего 16 логических ячеек... И к ним FSM, который из "регистров модулей" переносит информацию в "регистровый файл". Возможно что при записи потребуется несколько тактов. Но уж зато чтение - быстрое... PS... Просто в этом случае "голову" надо перестроить с ASIC на FPGA... В ASIC там в одном блоке и обработка и регистры... И шин накрутить не проблема...
--------------------
www.iosifk.narod.ru
|
|
|
|
|
|
|
|
Jul 25 2016, 13:58
|
Универсальный солдатик
Группа: Модераторы
Сообщений: 8 634
Регистрация: 1-11-05
Из: Минск
Пользователь №: 10 362
|
Цитата(iosifk @ Jul 25 2016, 16:46) Вопрос в том, что либо быстро в память пишем и быстро читаем, либо медленно в память пишем, но быстро читаем... А оно надо писать быстро?
И что, неужели внешний процессор пишет по шине на 120 МГц? LVTTL или LVCMOS? Нет, за 11 тактов. По несколько тактов выдать адрес, сигнал защелки адреса, данные, запись / чтение. Я выбрал времена с гарантией, что не потеряю ничего. Мне не время экономить надо, хотя его тоже терять не желательно. Не хочу тратить логику на мультиплексор данных при чтении. Чисто теоретически. Всякие RAM и не на такой частоте молотят.
|
|
|
|
|
|
|
|
Jul 25 2016, 14:31
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(ViKo @ Jul 25 2016, 16:58) Мне не время экономить надо, хотя его тоже терять не желательно. Не хочу тратить логику на мультиплексор данных при чтении. Чисто теоретически. Чисто теоретически (а также и практически) все равно придется терять ее родимую - в смысле логику. Так как при любой схеме придется выводит N выходов регистов на 1 выход. Как не крути. Можно только оптимизировать сам мультиплексор - по простоте написания RTL, по универсальности подключения кучи модулей, по времянке и простоте разводки в кристалле. Если у Вас 16-64 регистров - то тут и заморачивается не стоит. Вот если 200 - 1000. то тогда можно начинать экономить. Удачи! Rob.
|
|
|
|
|
|
|
|
Jul 25 2016, 14:47
|
Гуру
Группа: Свой
Сообщений: 2 563
Регистрация: 8-04-05
Из: Nsk
Пользователь №: 3 954
|
Цитата(iosifk @ Jul 25 2016, 20:23) В ПЛИС для этой цели есть "регистровый файл", который делается из "памяти"... Берем память с раздельными шинами на чтение и запись или двухпортовку, со стороны логики пишем (читаем), со стороны процессора - читаем (пишем)... Дешифрация памяти - встроенная, объем довольно большой...
Или скажем берем "двухпортовку", по одной стороне используем небольшую часть как регистры, по другой - используем как остальную память...
Или вот так...
У Ксайлинкса есть блоки памяти 16х1 из одной ячейки SRL... 16 таких блочков дадут поле 16х16... У более новых - это 64х1... Думаю что 16 регистров - вполне хватит для начала... И это всего 16 логических ячеек... я про, например, регистры различной периферии, которой может быть довольно много, килобайты, то есть наружу оно должно торчать как регистры, а процессору - как область памяти на общей шине с остальной нормальной памятью. как тут поможет двух портовая память? не будут же например два различных порта IO, или какой-нибудь уарт чтобы данные из своего регистра прочитать/записать драться за доступ к второму порту шине памяти которая к ним смотрит.
|
|
|
|
|
|
|
|
Jul 25 2016, 16:35
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(ViKo @ Jul 25 2016, 19:00) В FLEX10 были цепи Cascade, позволяющие объединять по И / ИЛИ сигналы после LUT. А в Cyclone III нет подобного.  Ну с это и надо начинать - с того чего нет  Древовидный mux прост в написании и минимален в latency но при большом количестве входов возникают проблемы с трассировкой. Цепочечный mux больше размером, имеет большой latency но просто трассируется особенно на большом кристалле. Универсального решения нет. Я у себя оптимизирую регистры на чтение так - если возможно без потери функциональности то в FPGA регистры параметров/ управления WriteOnly + soft зеркало в CPU. Если программист капризничает и не хочет (а говорит что не может) возится с зеркалами а хочет читать текущее значение из FPGA то ставлю память для ReadBаck + регистр. То есть пишу и в память и в регистр а читаю только из памяти. Естественно это работает когда нет изменений состояния регистра из логики FPGA. Ну и комбинация этих способов с обычными регистрами. Гемор с переносом состояния регистров в память выгоден в очень редких случаях. Опят же все это для Xilinx где локальная память для LUT просто прелесть какая для такого использования. Цитата(iosifk) Вот кусок софт-процессора... Это как раз шина данных "внутри"... Спасибо! теперь я буду знать как выглядит шина данных  Удачи! Rob.
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|