| |
 IAR ARM ассемблер IAR ARM ассемблер, Преобразовать процедуру в макрос |
|
|
|
|
 Aug 28 2017, 13:42 Aug 28 2017, 13:42
|
Частый гость

Группа: Свой
Сообщений: 168
Регистрация: 8-10-08
Из: РФ Смоленск
Пользователь №: 40 764

|
Здравствуйте. В проекте функция реализована как ассемблерная процедура. Состоит из одной инструкции и хотелось бы преобразовать её в макрос, чтобы не тратить такты на вход и выход. Реализована в *.s файле в виде Код SECTION .text:CODE:NOROOT(2)
PUBLIC MULSHIFT32
THUMB
MULSHIFT32
smull r2, r0, r1, r0
BX lr Далее используется в *.c файлах как обычная функция b2 = MULSHIFT32(*cptr++, a1 - a2) << (s1); Не зная тонкостей синтаксиса ассемблера IAR попробовал "в лоб" реализовать таким образом Код MULSHIFT32 MACRO
smull r2, r0, r1, r0
ENDM Линкер ругается на неизвестное имя MULSHIFT32. Ключевые слова PUBLIC и EXTERN вызывают ошибку. Кто подскажет, как этот макрос правильно оформить, чтобы можно было использовать его вне *.s-файла?
|
|
|
|
|
|
|
|
Aug 28 2017, 14:01
|
Местный
Группа: Свой
Сообщений: 475
Регистрация: 14-04-05
Из: Москва
Пользователь №: 4 140
|
Не занимайтесь ерундой. Умножать с нужной разрядностью - дело компилятора. Код int32_t x=1L,y=2L;
int64_t z;
z = (int64_t)x*y; Дадут вам Код // 106 int32_t x=1L,y=2L;
MOVS R0,#+1
STR R0,[SP, #+4]
MOVS R0,#+2
STR R0,[SP, #+0]
// 107 int64_t z;
// 108 z = (int64_t)x*y;
LDR R0,[SP, #+4]
LDR R1,[SP, #+0]
SMULL R0,R1,R1,R0
STRD R0,R1,[SP, #+8]
|
|
|
|
|
|
|
|
Aug 28 2017, 14:43
|
Частый гость
Группа: Свой
Сообщений: 168
Регистрация: 8-10-08
Из: РФ Смоленск
Пользователь №: 40 764
|
VladislavS, спасибо за идею. Это не совсем то, что нужно, но получилось слегка ускорить алгоритм. Создал обычный макрос Код #define MULSHIFT32(arg1, arg2) ((((long long)arg1)*((long long)arg2))>>32) Всё-равно получается избыточно, если верить листингу. Было до Код b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59ac0: 0xf8d4 0xa010 LDR.W R10, [R4, #0x10]
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59ac4: 0x1846 ADDS R6, R0, R1
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59ac6: 0x1a09 SUBS R1, R1, R0
0x59ac8: 0xf855 0x0b04 LDR.W R0, [R5], #0x4
0x59acc: 0xf7fd 0xf9ea BL MULSHIFT32 ; 0x56ea4
MULSHIFT32:
0x56ea4: 0xfb81 0x2000 SMULL R2, R0, R1, R0
0x56ea8: 0x4770 BX LR
0x59ad0: 0x4680 MOV R8, R0
0x59ad2: 0xea4f 0x0848 LSL.W R8, R8, #1 Стало после Код b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x58dee: 0xf851 0x6b04 LDR.W R6, [R1], #0x4
0x58df2: 0x17f7 ASRS R7, R6, #31
0x58df4: 0x17e5 ASRS R5, R4, #31
0x58df6: 0x17d3 ASRS R3, R2, #31
0x58df8: 0x1aa2 SUBS R2, R4, R2
0x58dfa: 0xeb65 0x0303 SBC.W R3, R5, R3
0x58dfe: 0x4634 MOV R4, R6
0x58e00: 0x463d MOV R5, R7
0x58e02: 0xfba2 0x6704 UMULL R6, R7, R2, R4
0x58e06: 0xfb02 0x7705 MLA R7, R2, R5, R7
0x58e0a: 0xfb03 0x7704 MLA R7, R3, R4, R7
0x58e0e: 0x46b8 MOV R8, R7
0x58e10: 0xea4f 0x0848 LSL.W R8, R8, #1 В моём случае объявить, как в Вашем примере 64-битную переменную и положить в неё результат 32х32 не получится.
|
|
|
|
|
|
|
|
Aug 28 2017, 15:18
|
Гуру
Группа: Свой
Сообщений: 3 020
Регистрация: 7-02-07
Пользователь №: 25 136
|
Из любопытства попробовал на GCC вот такое: Код #define MULSHIFT32(arg1, arg2) ((((long long)arg1)*((long long)arg2))>>32)
int volatile a0, a7, b7, ar[2];
void f(void)
{
int* cptr = ar;
b7 = MULSHIFT32(*cptr++, a0) << 1;
} Получилось вот что: Код 0x0800146E 4D72 LDR r5,[pc,#456]; @0x08001638
0x08001470 686B LDR r3,[r5,#0x04]
0x08001472 68E8 LDR r0,[r5,#0x0C]
0x08001474 FB830100 SMULL r0,r1,r3,r0
0x08001478 184A ADDS r2,r1,r1
0x0800147A 612A STR r2,[r5,#0x10] А если написать вот так Код b7 = MULSHIFT32(*cptr++, a0 - a7) << 1; То получается АдЪ: Код 0x0800146E 4D77 LDR r5,[pc,#476]; @0x0800164C
0x08001470 6868 LDR r0,[r5,#0x04]
0x08001472 68AE LDR r6,[r5,#0x08]
0x08001474 68EC LDR r4,[r5,#0x0C]
0x08001476 17C1 ASRS r1,r0,#31
0x08001478 1B80 SUBS r0,r0,r6
0x0800147A EB6171E6 SBC r1,r1,r6,ASR #31
0x0800147E FB04F201 MUL r2,r4,r1
0x08001482 17E3 ASRS r3,r4,#31
0x08001484 FB002303 MLA r3,r0,r3,r2
0x08001488 FBA40100 UMULL r0,r1,r4,r0
0x0800148C 185C ADDS r4,r3,r1
0x0800148E 1922 ADDS r2,r4,r4
0x08001490 616A STR r2,[r5,#0x14]
|
|
|
|
|
|
|
|
Aug 28 2017, 16:00
|
Местный
Группа: Свой
Сообщений: 475
Регистрация: 14-04-05
Из: Москва
Пользователь №: 4 140
|
Во-первых, очень некрасиво не показывать типы используемых переменных и желаемого результата. Во-вторых, разберитесь с размерностью вычислений. Написанный вами макрос делает совсем не то что вы хотите. В-третьих, ваш mulshift32, судя по всему, это банальное Код int32_t x=1L,y=2L;
int32_t z;
z = ((int64_t)x*y)>>32; Поверьте, компилятор сделает всё лучше вас, особенно с оптимизацией. Только не мешайте ему. Код // int32_t x=1L,y=2L;
MOVS R0,#+1
MOVS R1,#+2
// int32_t z;
// z = ((int64_t)x*y)>>32;
SMULL R0,R1,R1,R0 В-четвёртых, вместо x и y можете ставить что угодно, только с соблюдением типов.
|
|
|
|
|
|
|
|
Aug 28 2017, 16:14
|
Местный
Группа: Свой
Сообщений: 475
Регистрация: 14-04-05
Из: Москва
Пользователь №: 4 140
|
Дарю Код #define MULSHIFT32(arg1, arg2) (((int64_t)(int32_t)(arg1)*(int32_t)(arg2))>>32)
|
|
|
|
|
|
|
|
Aug 29 2017, 09:41
|
Гуру
Группа: Свой
Сообщений: 3 020
Регистрация: 7-02-07
Пользователь №: 25 136
|
Кстати, если в моём эксперименте с GCC сделать так Код #define MULSHIFT32(a, b) (((long long)(a) * (b)) >> 32) то код генерится вменяемый. Очевидно, в первоначальном варианте макроса не хватает скобок вокруг аргументов. На первый взгляд, в данном случае неважно, но, возможно, я что-то не заметил.
|
|
|
|
|
|
|
|
Aug 29 2017, 09:53
|
Частый гость
Группа: Свой
Сообщений: 168
Регистрация: 8-10-08
Из: РФ Смоленск
Пользователь №: 40 764
|
jcxz, всё верно, чужие библиотеки. Портирую mp3-декодер Helix. В очередной раз) Цитата(jcxz @ Aug 28 2017, 18:49)  Если Вам нужны только старшие 32 бита (как следует из этого макроса), то всё просто:
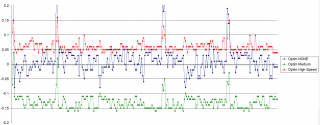
#define MULSHIFT32(x, y) __SMMUL(x, y) Спасибо. Даже забыл, что в IAR есть intrinsic-ассемблер, как всё просто оказывается. Цитата(VladislavS @ Aug 28 2017, 19:14) Дарю Код #define MULSHIFT32(arg1, arg2) (((int64_t)(int32_t)(arg1)*(int32_t)(arg2))>>32) Спасибо за подарок. Прогнал оба варианта на разных уровнях оптимизации. По оси ординат разница выполнения алгоритма в мс. Time( __SMMUL(x, y)) - Time((((int64_t)(int32_t)(arg1)*(int32_t)(arg2))>>32)). Без оптимизации паритет, на умеренной оптимизации использование интринсик-функции __SMMUL(x, y) оказывается более быстрым, в случае максимальной оптимизации по скорости выигрывает решение от VladislavS. Разница не существенная, в районе 1%.
Дизассемблер для каждой из реализаций. Алгоритм раскладывается в одни и те же инструкции, но с использованием разных РОН. Код b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59830: 0x1979 ADDS R1, R7, R5
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59832: 0x1bed SUBS R5, R5, R7
0x59834: 0xf852 0x7b04 LDR.W R7, [R2], #0x4
0x59838: 0xfb57 0xfc05 SMMUL R12, R7, R5
0x5983c: 0xea4f 0x0c4c LSL.W R12, R12, #1 Код b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59906: 0x1978 ADDS R0, R7, R5
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59908: 0xf853 0xcb04 LDR.W R12, [R3], #0x4
0x5990c: 0x1bed SUBS R5, R5, R7
0x5990e: 0xfb5c 0xfc05 SMMUL R12, R12, R5
0x59912: 0xea4f 0x0c4c LSL.W R12, R12, #1 И хотя первоначальный вопрос про синтаксис макросов остался открытым, но задача решена другими средствами. Спасибо за помощь!
|
|
|
|
|
|
|
|
Aug 29 2017, 10:29
|
Гуру
Группа: Свой
Сообщений: 3 020
Регистрация: 7-02-07
Пользователь №: 25 136
|
Цитата(Sergey_Aleksandrovi4 @ Aug 29 2017, 12:53) И хотя первоначальный вопрос про синтаксис макросов остался открытым, но задача решена другими средствами. Спасибо за помощь! Имеется в виду вот этот вопрос? Цитата(Sergey_Aleksandrovi4 @ Aug 28 2017, 16:42) Кто подскажет, как этот макрос правильно оформить, чтобы можно было использовать его вне *.s-файла? Тогда ответ такой: никак. Это макросы ассемблера, фактически текстовая подстановка в пределах ассемблерного файла. Ни разу не видел, чтобы такие вещи действовали в сишных файлах. И уж точно на уровне линкера ничего этого быть не может.
|
|
|
|
|
|
|
|
Aug 29 2017, 13:04
|
Частый гость
Группа: Свой
Сообщений: 168
Регистрация: 8-10-08
Из: РФ Смоленск
Пользователь №: 40 764
|
Цитата(scifi @ Aug 29 2017, 13:29) Это макросы ассемблера, фактически текстовая подстановка в пределах ассемблерного файла. Вот оно что. Спасибо. С ARM-ассемблером пару раз в жизни сталкивался, не знал про эти тонкости. jcxz, в двух словах - интерактивная игрушка для детей, ничего серьёзного. Кодек этот давно ещё портировал на cortex M3 (не без помощи здешних форумчан). Теперь перевожу на cortex M4, ну и решил по-максимуму из него выжать и закрыть тему навсегда.
|
|
|
|
|
|
|
|
Aug 30 2017, 08:26
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(VladislavS @ Aug 28 2017, 19:14) Дарю Код #define MULSHIFT32(arg1, arg2) (((int64_t)(int32_t)(arg1)*(int32_t)(arg2))>>32) __SMMUL() может быть чуть-чуть лучше если нужно ещё и округление результата: __SMMULR(). Правда без возможности предварительного сдвига результата влево на 1 бит, это округление редко бывает полезным.  Не знаю почему в системе команд не предусмотрена опция сдвига влево результата на 1 бит.
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|