| |
 Как уменьшить время распространения сигнала (route)? Как уменьшить время распространения сигнала (route)?, Virtex6, xc6vlx240, Ise14.7, LDPC DVBS2 |
|
|
|
|
 Jan 22 2018, 11:26 Jan 22 2018, 11:26
|
Местный

Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243

|
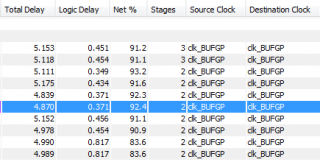
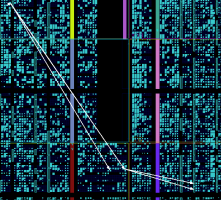
Доброго времени суток. Есть дизайн c LDPC DVBS2 (около 25-30 % процентов ПЛИС), с тактовой частотой 200 МГц. В проекте много однотипных юнитов. После P/R с помощью PlanAhead вижу следующую таблицу. Из неё видно, что значительная часть времянок уходит на route. Как это время можно уменьшить, не используя loc, rloc, area_group и т. п. ручные механизмы? А если это не уменьшить, то как грамотно использовать ручные механизмы? Всем откликнувшимся - спасибо! 
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Jan 22 2018, 12:09
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(svedach @ Jan 22 2018, 14:56)  Может организовать дополнительные регистры на входах и выходах модулей... ISE из-за этого будет модули компактнее делать? Здесь route внутри модуля огромный, из-за "хаотичного" расположения компонента по кристаллу 
|
|
|
|
|
|
|
|
Jan 22 2018, 12:37
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(bogaev_roman @ Jan 22 2018, 15:28) У Вас временные ограничения не выполняются? Или Вам просто не нравится процентное соотношение задержек? Что за пути - может там по одному регистру на входе/выходе и сигнал тянется через весь кристалл? Не выполняются. Не нравится. Тянется примерно через четверть кристалла. По Триггер->lut->триггер ->lut, fanout 1..4, иногда 2 триггера. Я бы хоть как-то понял если бы они не выполнялись в такой связке, но даже не пути триггер-триггер не выполняется. 4 строчка в репорте. Увеличение количества триггеров приведет к резкому увеличению используемых ресурсов.
|
|
|
|
|
|
|
|
Jan 22 2018, 13:09
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(alexadmin @ Jan 22 2018, 15:55) Если не поможет - фиксировать модули по определенным местам в кристалле через AREA_GROUP. Сейчас нахожусь на этой стадии. Цитата(alexadmin @ Jan 22 2018, 15:55) Ну и для начала попробовать ответить на вопрос - какую задачу решает плэйсер распихивая соседние элементы по разным углам... Тут все зависит от первоначального размещения базовых элементов (?), расположение которых зависит практически от погоды на марсе и магической константы cosе table , если я правильно понял. А остальную мелочь он размещает после размещения базовых элементов. В проекте много памяти и он раскидал её равномерно по всей окружности. Остальное начинает плясать от этого. Где-то адрес не дотягивается с fanout 8 ибо память к которой адрес идет по половине кристалла раскидана, хотя можно было рядом положить. Где-то данные. Пробовал память группировать с помощью rloc стало только хуже. Пробовал наложить AREA_GROUP, стало только хуже. Надо какой-то системный подход, а какой я по понять не могу....
|
|
|
|
|
|
|
|
Jan 22 2018, 13:14
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Основная проблема раскладки проекта в ISE, на мой взгляд, это шины. Т.е. если у Вас сигналы образуют шину, то они будут распиханы по 4 штуки(по умолчанию) в SLICE. Ещё хуже то обстоятельство, что однобитные сигналы одинаковых модулей("empty" для фифо, например), описанных через генерейт(т.е. копи) будут объединены в шину. В итоге у вас большие массивы BRAM в разных углах кристалла будут стоять, а управляющие сигналы к ним будут в одном "месте"  Как с этим бороться в уже готовом описании я даже не представляю. В любом случае, советую уделить этой особенности работы маппера особое внимание.
|
|
|
|
|
|
|
|
Jan 22 2018, 13:20
|
Профессионал
Группа: Свой
Сообщений: 1 088
Регистрация: 20-10-09
Из: Химки
Пользователь №: 53 082
|
Цитата(Tpeck @ Jan 22 2018, 15:37) Я бы хоть как-то понял если бы они не выполнялись в такой связке, но даже не пути триггер-триггер не выполняется. 4 строчка в репорте. Для начала - возьмите один длинный путь от триггера до триггера и проанализируйте кол-во fan-out на выходном триггере этого пути, а также наиболее длинный путь до входного триггера, возможно у Вас дикое кол-во fan-out. Цитата В итоге у вас большие массивы BRAM в разных углах кристалла будут стоять, а управляющие сигналы к ним будут в одном "месте" biggrin.gif
Как с этим бороться в уже готовом описании я даже не представляю. Дублировать логику, можно для этих сигналов ограничить fan-out - тогда компилятор сам все продублирует.
|
|
|
|
|
|
|
|
Jan 22 2018, 13:22
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(TRILLER @ Jan 22 2018, 16:14) Основная проблема раскладки проекта в ISE, на мой взгляд, это шины. Т.е. если у Вас сигналы образуют шину, то они будут распиханы по 4 штуки(по умолчанию) в SLICE. Ещё хуже то обстоятельство, что однобитные сигналы одинаковых модулей("empty" для фифо, например), описанных через генерейт(т.е. копи) будут объединены в шину. В итоге у вас большие массивы BRAM в разных углах кристалла будут стоять, а управляющие сигналы к ним будут в одном "месте" Управляющие сигнала древовидно разветвляются в две стадии, образуя относительно небольшой fanout. Вопрос в другом, почему ISE, при исользовании четверти памяти, ставит их в разные углы плисины? Цитата(bogaev_roman @ Jan 22 2018, 16:20) Для начала - возьмите один длинный путь от триггера до триггера и проанализируйте кол-во fan-out на выходном триггере этого пути, а также наиболее длинный путь до входного триггера, возможно у Вас дикое кол-во fan-out. fan-out = 2.
|
|
|
|
|
|
|
|
Jan 22 2018, 13:29
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Цитата(Tpeck @ Jan 22 2018, 16:22) Вопрос в другом, почему ISE, при исользовании четверти памяти, ставит их в разные углы плисины? Лично я считаю хорошим тоном приколотить ВСЮ блочную память гвоздями. Несколько сотен штук - не так и много. Зато экономит кучу времени в дальнейшем. И САПРине сильно легчает.
|
|
|
|
|
|
|
|
Jan 22 2018, 13:36
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(bogaev_roman @ Jan 22 2018, 16:27) Это для выхода? Проанализируйте длину этих путей. Думаю, что тут без скриншота не обойтись. Да. Длина - длинная Тут системная проблема и длинный путь - это следствие. Цитата(TRILLER @ Jan 22 2018, 16:29) Лично я считаю хорошим тоном приколотить ВСЮ блочную память гвоздями. Несколько сотен штук - не так и много. Зато экономит кучу времени в дальнейшем. И САПРине сильно легчает. А по-какому принципу ее приколачивать? LOC, Rloc, AREA_GROUP? Или еще какие-нибудь? И главное, как её расположить так, чтобы хуже не стало?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Jan 22 2018, 13:41
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Цитата(Tpeck @ Jan 22 2018, 16:36) А по-какому принципу ее приколачивать? Как вариант: INST "*/u_layer_a/u_layer_b/gen_layer_c.0.u_layer_c/u_fifo/u_bram" AREA_GROUP = "pb_0_bram_0"; AREA_GROUP "pb_0_bram_0" RANGE=RAMB36_X7Y60:RAMB36_X7Y61; INST "*/u_layer_a/u_layer_b/gen_layer_c.1.u_layer_c/u_fifo/u_bram" AREA_GROUP = "pb_0_bram_1"; AREA_GROUP "pb_0_bram_1" RANGE=RAMB36_X7Y62:RAMB36_X7Y63; u_bram - собственно описание памяти. П.С.: хотя я всё равно считаю, что проблема в шинах..
|
|
|
|
|
|
|
|
Jan 22 2018, 13:53
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(TRILLER @ Jan 22 2018, 16:41) Как вариант:
INST "*/u_layer_a/u_layer_b/gen_layer_c.0.u_layer_c/u_fifo/u_bram" AREA_GROUP = "pb_0_bram_0";
AREA_GROUP "pb_0_bram_0" RANGE=RAMB36_X7Y60:RAMB36_X7Y61;
INST "*/u_layer_a/u_layer_b/gen_layer_c.1.u_layer_c/u_fifo/u_bram" AREA_GROUP = "pb_0_bram_1";
AREA_GROUP "pb_0_bram_1" RANGE=RAMB36_X7Y62:RAMB36_X7Y63;
u_bram - собственно описание памяти. Значит каждый юнит отдельно... Цитата(TRILLER @ Jan 22 2018, 16:41) П.С.: хотя я всё равно считаю, что проблема в шинах.. В шинах управления?
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|