| |
|
  |
 100 Ватт - модуль на Kintex UltraScale KU115 100 Ватт - модуль на Kintex UltraScale KU115, Хочу похвастаться |
|
|
|
|
 May 27 2018, 16:21 May 27 2018, 16:21
|
Местный

Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284

|
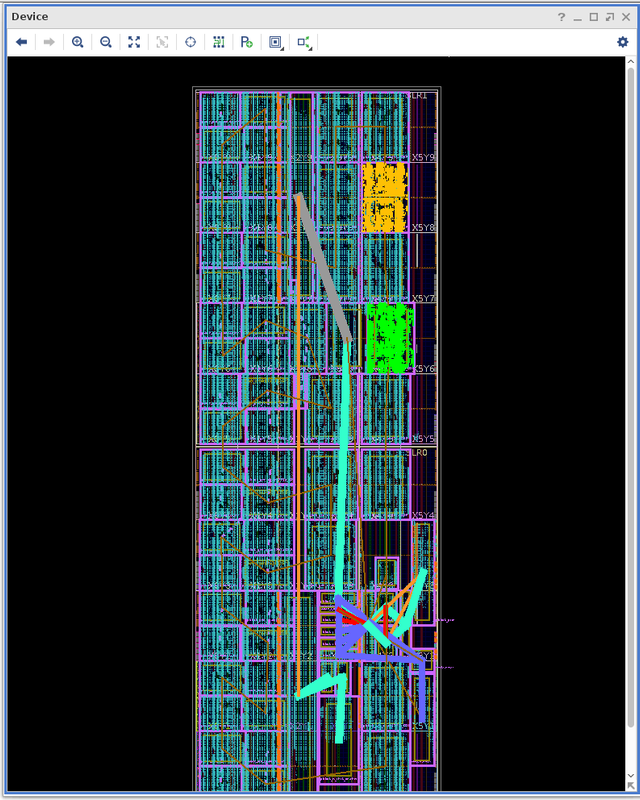
Про БПФ пишет Александр Капитанов. Вот например картинка как ложатся БПФ и ОБПФ размером 64К в ПЛИС Virtex 7 VX1140. В этой ПЛИС 3360 DSP, т.е. она меньше чем KU115 в которой 5560 DSP. Но масштабы сравнимые. А вот теперь увеличиваем размер БПФ и ОБПФ до 256К. Это уже займёт больше половины ПЛИС. Это при том, что мы используем собственный формат с плавающей точкой размером 23 бита. Если FFT от Xilinx с плавающей точкой 32 бита, то скорее всего вообще не поместиться. Здесь используется классические алгоритмы БПФ и ОБПФ с прореживанием по частоте и по времени. А также совершенно классическое представление числа с плавающей точкой. Вот только размеры мантиссы и экспоненты подобраны так, что они оптимально ложились на архитектуру DSP блока Xilinx. Подробнее - на Хабрахабр: Реализация узла БПФ с плавающей точкой на ПЛИСCustom floating point format on FPGA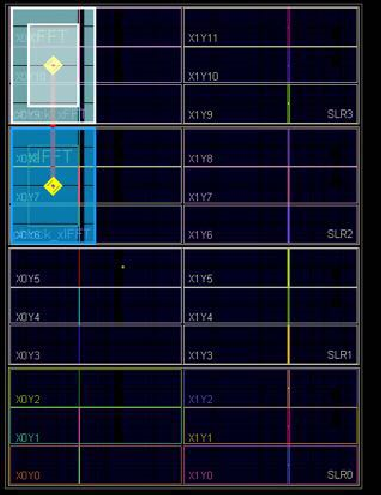
|
|
|
|
|
|
|
|
May 27 2018, 16:42
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(blackfin @ May 27 2018, 19:35)  У Xilinx'а есть две реализации FFT - burst_io и pipliled streaming. У вас какая из них реализована?
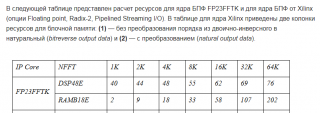
И с точки зрения реализации FFT на ПЛИС интереснее расход BRAM, а не умножителей. У вас БПФ на 64К сколько съедает блочной памяти? У нас - pipelined Для БПФ 64К используется 202 BRAM. у Xilinx - 478. В статье Капитанова приведена таблица с потребляемыми ресурсами для разных размеров БПФ. Реализация узла БПФ с плавающей точкой на ПЛИС
|
|
|
|
|
|
|
|
May 27 2018, 18:54
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(Volkov @ May 27 2018, 21:00) Круто. А тепло как отводите? У нас в блоке на 100 Вт ПЛИС-ов, никак не могу добиться от конструкторов эффективного отвода тепла. А тут 100 с одного кристалла. На модуле мощная система охлаждения. Модуль занимает два слота, установлен мощный вентилятор, обдувается также субмодуль. Интересно наблюдать что происходит при выключении DSP блоков, температура очень быстро падает от +78 до +50. И хочу отметить, 105 Вт это со всего модуля. На ПЛИС наверное приходится 85 Вт. Ещё есть куда расти.  Вот вид с другой стороны. 
|
|
|
|
|
|
|
|
May 27 2018, 20:59
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(rloc @ May 27 2018, 23:50) По картинке не очень понятно, какой объем. В оптимальном случае, для R4 увеличение вычислительных ресурсов составит log4(256k)/log4(64k)=9/8 = 12.5 % (по умножениям), по памяти соответственно в 4 раза. Но данных по памяти нет, выводов по ресурсам сделать нельзя. Это не для режима pipeline. В этом режиме нарастание идёт практически линейное. Посмотрите таблицу в разделе "Общий объём ресурсов" https://habr.com/post/322728/Используется Radix-2
|
|
|
|
|
|
|
|
May 27 2018, 21:44
|
Узкополосный широкополосник
Группа: Свой
Сообщений: 2 316
Регистрация: 13-12-04
Из: Moscow
Пользователь №: 1 462
|
Цитата(dsmv @ May 27 2018, 23:59) Это не для режима pipeline. В этом режиме нарастание идёт практически линейное. Для pipeline приводил. R2 по ресурсам DSP48 растет конечно быстрее R4, но не настолько.
Приведу еще раз ресурсы VX1140T: DSP48 = 3360, BRAM18 = 3760 Экстраполируя данные по таблице, получаем для 256K: DSP48 ~ 93, BRAM18 ~ 800 Как и ожидалось, память закончится раньше, а с оптимизированным алгоритмом R4 или R22 DSP48 потребуется еще меньше. Пока не вижу смысла использовать ПЛИС с большим кол-вом DSP48.
|
|
|
|
|
|
|
|
May 27 2018, 22:09
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(rloc @ May 28 2018, 00:44) ...
Как и ожидалось, память закончится раньше, а с оптимизированным алгоритмом R4 или R22 DSP48 потребуется еще меньше. Пока не вижу смысла использовать ПЛИС с большим кол-вом DSP48. FFT/IFFT это не предел сложности DSP обработки - у меня были системы в которых 70% ресурсов кристалла были заняты обработкой того что входило и выходило из/на них. И если б в то время у меня были такие чипы то можно было б еще немножко усложнил обработку - процентиков на 300-400.  . А не мудохатся с несколькими чипами. Успехов! Rob.
|
|
|
|
|
|
|
|
May 27 2018, 22:27
|
Узкополосный широкополосник
Группа: Свой
Сообщений: 2 316
Регистрация: 13-12-04
Из: Moscow
Пользователь №: 1 462
|
Цитата(RobFPGA @ May 28 2018, 01:09) у меня были системы в которых 70% ресурсов кристалла были заняты обработкой того что входило и выходило из/на них. Если не сложно, то по порядку: 1. Постановка задачи. 2. Решение. 3. Результаты в цифрах.
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|