| |
|
  |
 Эффективный широкий pipelined mux Эффективный широкий pipelined mux, как альтеровский LPM_MUX, но для Xilinx |
|
|
|
|
 Jun 26 2018, 11:42 Jun 26 2018, 11:42
|
Частый гость

Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149

|
Ещё в процессе экспериментов выяснилось, что не всегда синтезатор оптимально размещает муксы используя специальные внутренние примитивы (MUXF8, MUXF9). Не знаю, можно ли вставлять сразу картинки большего качества, пока получилось через ссылки и в аттаче.Начнём с семейства Zynq7000. Как уже писалось выше 1 слайс (поправка именно Slice; в CLB два Slice, но сути это не меняет) используя все 4xLUT6, 2xMUXF и 1xMUXF8 можно превратить в mux 16:1 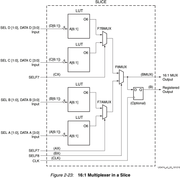 Когда из кода общего вида делаю синтез для mux с 16 входами, то как раз получается такой «канонический» результат: 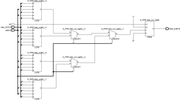 Однако когда делаем синтез для 32 входов, картина меняется. Почему-то MUXF8 не задействованы, а лишь MUXF7 (хотя ничто не мешает просто продублировать как было в mux_16_1 два раза и объединить через LUT). 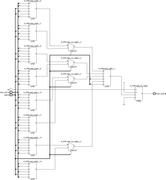 Что ещё более интересно, для 64 входов (mux_64_1) вновь синтезируется корректно, задействует MUX8 (т.е. повторяем четыре раза mux_16_1 и объединяем через LUT):  И кстати вот ещё картинка, где показано, как для mux_64_1 работает атрибут retiming_backward и «задвигает» добавочные регистры пайплана на промежуточную стадию (до входа на конечный LUT): 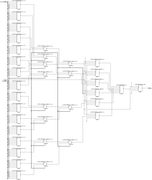 Для муксов большего размера ситуация повторяется - каждые дополнительные 32 входа MUXF8 то используется, то нет. -------------------------------------------------------------------------------------------------------------------------------------------- В семействе Zynq UltraScale+ ситуация немного другая, чуть хуже. Начнём с того, что тут другая архитектура CLB – два слайса объединены в один и поэтому можно на базе одного CLB делать mux 32:1 (используя примитив MUXF9): 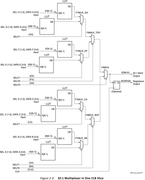 Однако, какого бы размера муксы не пытался синтезировать, ни в одном случае не удавалось задействовать MUXF9. Для примера вот так синтезируется mux_32_1 (нет ни MUXF8, ни MUXF9): 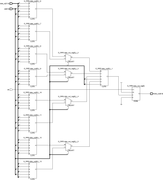 В муксах большего размера ситуация похожая как в семейтсве Zynq7000 (т.е. MUXF8 то используется, то нет). Но MUXF9 увидеть ни разу не удалось. Перепробовал все стратегии синтеза – не помогло. Даже в одном случае для стратегии AlternateRoutability вместо всех MUXF[5-8] использовались LUT (что и соответствует заданной стратегии). Вроде бы должна помочь стратегия AreaOptimized_high, в описании которой присутствует фраза “area optimized mux optimization” - но результаты не менялись. Начал смотреть в документации, как можно заставить использовать эти самые MUXF[7-9]. Вроде нашёл подходящую опцию. В ug901, Глава 3 “Using Block Synthesis Strategies” имеется перечень поддерживаемых Вивадо опций стратегии блочного синтеза. Среди них есть опция: Код MUXF_MAPPING
INTEGER 0/1
• 0 – Disable MUXF7/F8/F9 inference
• 1 – Enable MUXF7/F8/F9 inference Попробовал использовать – не помогло (убедился, что xdc файл с этой опцией действительно читается и парсится синтезатором). Прогонялось в Vivado 2017.4 Вопрос: может есть идеи, как ещё можно попытаться задействовать эти самые MUXF[8-9] там, где им положено бы быть, не запихивая их туда вручную из кода? Возможно в более новых версиях Вивадо ситуация может быть другая, но пока проверить это имею возможности. По идее есть смысл спросить на форуме Xilinx, но что-то тамошние ответы или отсутствуют, или не шибко-то помогают… P.S.: в аттаче pdf файлы генерируемых схематик, которые легче масштабировать.
Сообщение отредактировал Vengin - Jun 26 2018, 11:51
|
|
|
|
|
|
|
|
Jun 26 2018, 12:36
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 26 2018, 14:42)  ...
Вопрос: может есть идеи, как ещё можно попытаться задействовать эти самые MUXF[8-9] там, где им положено бы быть, не запихивая их туда вручную из кода? Возможно в более новых версиях Вивадо ситуация может быть другая, но пока проверить это имею возможности. По идее есть смысл спросить на форуме Xilinx, но что-то тамошние ответы или отсутствуют, или не шибко-то помогают… В 2018.2 все также  - Все синтезаторы с которыми мне приходилось работать почти никогда не делают "красивую картинку" при синтезе. Главное для них обеспечить описанную функциональность. При этом могут быть свои внутренние (и как показывают Ваши изыскания весьма загадочные  ) приоритеты при реализации тех или иных функций. И атрибуты синтеза это не сколько приказ а больше Ваши пожелания синтезатору. Поэтому если нужна гарантированная структура после синтеза - будь добр - лепи примитивы в RTL для ограничения творческого своеволия. При этом часто не обязательно лепить все включая LUT примитивы, для mux например достаточно просто rtl блоков 4:1 и затем дерево с MUXF7/8/9. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 26 2018, 12:53
|
Гуру
Группа: Свой
Сообщений: 3 106
Регистрация: 18-04-05
Пользователь №: 4 261
|
Попробовал сделать на LUT6 4-дерево из MUX 4:1 для MUX 150:1 и однобитных входных данных (через generate). Получилось: LUT = 52 FF = 210 Соответственно, если делать MUX 150:1 для 32-х битных данных, обе цифры нужно умножить на 32. Worst Pulse Width Slack = 4.5 ns (это для клока 100 MHz и XC7A200-3). ИМХО, вполне.. PS. Входные данные для MUX 150:1 с регистров, поэтому из 210 FF'ов 158 FF'ов это просто входные регистры.
|
|
|
|
|
|
|
|
Jun 26 2018, 13:09
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(blackfin @ Jun 26 2018, 15:53) Попробовал сделать на LUT6 бинарное дерево из 4:1 для MUX 150:1 и однобитных входных данных (через generate)...
Worst Pulse Width Slack = 4.5 ns (это для клока 100 MHz и XC7A200-3). Т.е., это вообще без всех MUXF[7-8], чисто на LUT-ах? Возможно действительно на данном этапе погоня за "совершенством" и не имеет особого смысла. А уж если прижмёт, начинать дёргаться. Хотя в большущем проекте это всегда сложнее отследить и проконтролировать. Вот и попытался ещё на начальном этапе соптимизировать, пока есть свободное время.
|
|
|
|
|
|
|
|
Jun 26 2018, 13:50
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(blackfin @ Jun 26 2018, 15:53) Попробовал сделать на LUT6 бинарное дерево из 4:1 для MUX 150:1 и однобитных входных данных (через generate).
...
Worst Pulse Width Slack = 4.5 ns (это для клока 100 MHz и XC7A200-3).
ИМХО, вполне..
PS. Входные данные для MUX 150:1 с регистров, поэтому из 210 FF'ов 150 FF'ов это просто входные регистры. Увы эта радужная картина покрывается ржавыми пятнами если заполнение кристалла велико. Тогда задержки роутинга начинают доминировать над задержками в логике. Особенно для сильно-связанного проекта. Тут уж без художеств во florplane не обойтись. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 27 2018, 09:57
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Цитата(Vengin @ Jun 26 2018, 14:42) Однако когда делаем синтез для 32 входов, картина меняется. Почему-то MUXF8 не задействованы, а лишь MUXF7 (хотя ничто не мешает просто продублировать как было в mux_16_1 два раза и объединить через LUT).
..
Что ещё более интересно, для 64 входов (mux_64_1) вновь синтезируется корректно, задействует MUX8 (т.е. повторяем четыре раза mux_16_1 и объединяем через LUT): Синтезатор не глуп и придерживается принципа "бритвы оккама". В том случае, в котором Вы сетуете на отсутствие MUX8 всё равно без ЛУТа не обойтись, а значит эти муксы - лишние сущности. Цитата(Vengin @ Jun 26 2018, 14:42) В муксах большего размера ситуация похожая как в семейтсве Zynq7000 (т.е. MUXF8 то используется, то нет). Но MUXF9 увидеть ни разу не удалось. Здесь может быть всё, что угодно - от синтезатора, который просто "не знает" про MUXF9 или немного не корректно по каким-либо причинам обсчитывает через него времянки, до хардварных с ними проблем, о которых предпочитают не говорить, но дали указание "низя". Может как-нибудь проверю симплифаем, да сейчас лень.. Да и вообще, сознательное использование специфических элементов, типа этих муксов, carry логики или линий связи между дсп накладывает кучу ограничений на описание. Главное из которых, ИМХО, это выносить описание этих элементов в отдельные модули и жёстко контролировать оптимизацию на всех уровнях, чтобы какой-нибудь ресинтез не уничтожил все Ваши труды. К тому же такое низкоуровневое описание имеет смысл в действительно больших и быстрых проектах, а так же с чётким осознанием цели их применения.
|
|
|
|
|
|
|
|
Jun 28 2018, 07:07
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(TRILLER @ Jun 27 2018, 12:57) Синтезатор не глуп и придерживается принципа "бритвы оккама". В том случае, в котором Вы сетуете на отсутствие MUX8 всё равно без ЛУТа не обойтись, а значит эти муксы - лишние сущности. В этом есть смысл, хотя опять-таки всплывают нюансы. Вот, например, как для mux_32_1 при использовании только MUXF7 происходит добавление pipeline регистров атрибутом retiming_backward: 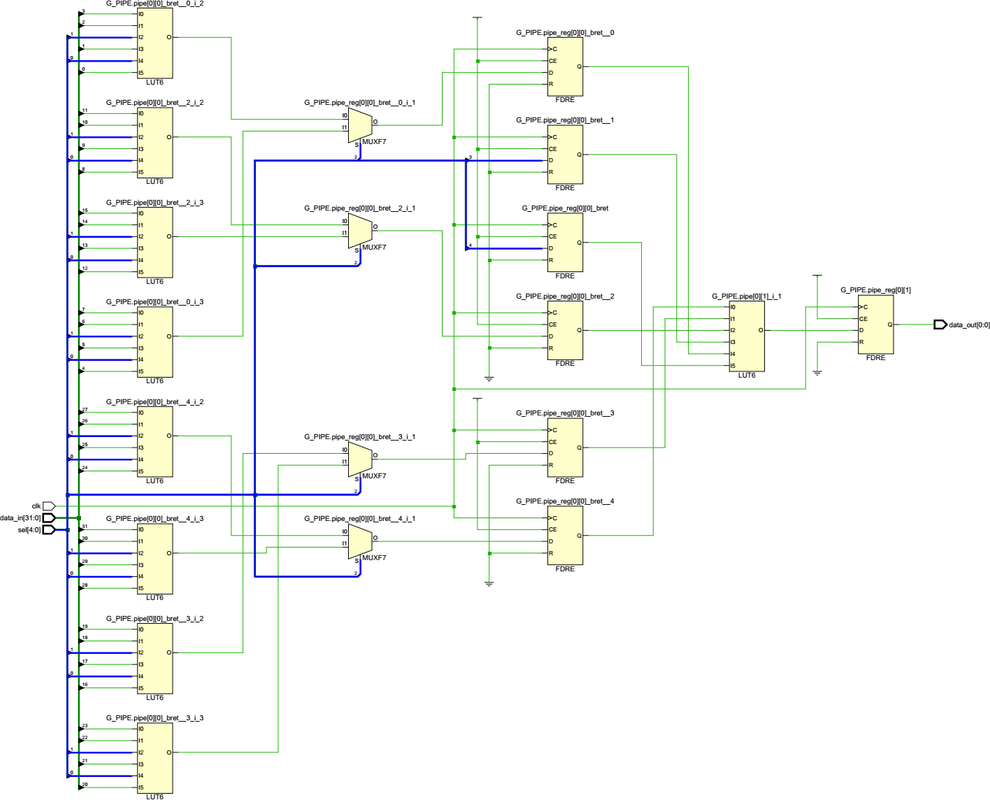 Как видно, на промежуточной стадии добавляется аж 6 регистров – 4 для сигналов данных и 2 для «задержки» сигнала выбора sel (которые синтезатор вставляет по собственной инициативе, в коде их нет). Если бы первый каскад заканчивался не на четырёх MUXF7, а на двух MUXF8, то промежуточных регистров было бы по идее только 3 (2 для сигнала данных, 1 для sel). Короче чем дальше в лес…
|
|
|
|
|
|
|
|
Jun 28 2018, 07:45
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 28 2018, 10:07) В этом есть смысл, хотя опять-таки всплывают нюансы. Вот, например, как для mux_32_1 при использовании только MUXF7 происходит добавление pipeline регистров атрибутом retiming_backward:
Как видно, на промежуточной стадии добавляется аж 6 регистров – 4 для сигналов данных и 2 для «задержки» сигнала выбора sel (которые синтезатор вставляет по собственной инициативе, в коде их нет). Если бы первый каскад заканчивался не на четырёх MUXF7, а на двух MUXF8, то промежуточных регистров было бы по идее только 3 (2 для сигнала данных, 1 для sel).
Короче чем дальше в лес… Экономить на регистрах тут смысла нет - так как критично по ресурсам будет число LUT. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 28 2018, 07:48
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Цитата(Vengin @ Jun 28 2018, 10:07) Как видно, на промежуточной стадии добавляется аж 6 регистров – 4 для сигналов данных и 2 для «задержки» сигнала выбора sel (которые синтезатор вставляет по собственной инициативе, в коде их нет). Если бы первый каскад заканчивался не на четырёх MUXF7, а на двух MUXF8, то промежуточных регистров было бы по идее только 3 (2 для сигнала данных, 1 для sel). Скорее всего атрибут применяется уже после получения схемы, отсюда и такой результат. И совет Вам: не пытайтесь скрещивать бульдога с носорогом. Атрибуты, подобные retiming_backward и низкоуровневый rtl не совместимы. ИМХО.
|
|
|
|
|
|
|
|
Jun 28 2018, 07:56
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(RobFPGA @ Jun 28 2018, 10:45) Приветствую!
Экономить на регистрах тут смысла нет - так как критично по ресурсам будет число LUT. Тут вроде не совсем в экономии дело, а в том, что чем больше регистров (и вооще ресурсов), тем больше скажем этот мукс размазывается по кристаллу (разным CLB и слайсам) и в итоге расходует больше ресурсов, хуже времянка и т.п. Цитата(TRILLER @ Jun 28 2018, 10:48) Скорее всего атрибут применяется уже после получения схемы, отсюда и такой результат. Это более чем логично, что retiming_backward применяется позже или имеет более низкий приоритет. Просто пытаюсь указать на всякие не совсем предвиденные вещи. Цитата(TRILLER @ Jun 28 2018, 10:48) И совет Вам: не пытайтесь скрещивать бульдога с носорогом. Атрибуты, подобные retiming_backward и низкоуровневый rtl не совместимы. ИМХО. Так а в данном случае опция retiming_backward применяется к коду общего вида (в этом и весь смысл), а не низкоуровневому описанию. Т.е. итоговая "композиция" - результат синтеза кода "общего вида". Естественно, если вручную компоновать примитивы, то можно сделать по другому. Но вот даже исходя из этого относительно простого примера, может возникнуть масса нюансов, которые не так то легко учесть.
|
|
|
|
|
|
|
|
Jun 28 2018, 08:57
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 28 2018, 10:56) Тут вроде не совсем в экономии дело, а в том, что чем больше регистров (и вооще ресурсов), тем больше скажем этот мукс размазывается по кристаллу (разным CLB и слайсам) и в итоге расходует больше ресурсов, хуже времянка и т.п. Для структуры SLICE в Xilinx для элементарных mux 4:1, 8:1 16:1 что есть регистр на выходе что нет - число занятых SLICE не меняется. Бывают правда ситуации когда при P&R регистр выносится из SLICE где стоить LUT который кормит этот регистр Это может быть если есть запас времянки на входе в LUT а с выхода от регистра на следующий каскад его нет. Тогда регистр выносится в SLICE поближе к получателю. Что касается размазывания тоже не все так однозначно - вариант на каскадах 4:1 требует больше ресурсов НО при R&R элементарные модули можно гибче распределять по площади чем жесткие блоки 16:1. Опять же - это все относительно и начинает играет роль при заполненном кристалле для сильно-связанного проекта. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 28 2018, 11:43
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(blackfin @ Jun 28 2018, 11:09) На мой взгляд, что-то не так в консерватории..  Наверняка, изменив архитектуру всего проекта, можно уменьшить число этих мультиплексоров на порядок.. Ломать не строить... К хэшированию/криптованию проект отношения не имеет. Муксы в основном используются для обеспечения доступа к чему-то похожему на многопортовую память. Т.е. есть порядка 40-150 входных/выходных шин (32/64 бита каждая) потоковых данных, между которыми нужно организовать обмен с временным хранением. Данные хоть и потоковые, но не постоянные (не каждый клок активные), скорее нерегулярные, слегка блочные. Всё это хоть и важная, но далеко не единственная (а в плане ресурсов не самая большая, ) часть проекта. И, между прочим, где-то лет 5 назад была схожая задача, где нужно было реализовать своеобразный «коммутатор» - взаимоисключающе соединить N потоковых входов на N выходов. Тогда N доходило до 320 (правда шины были 1-битные), т.е. каждый мукс был 320 в 1, и их надо было 320 штук. Да, с одной стороны можно сказать, что архитектура своеобразная, может даже «хромает». Но FPGA как раз и созданы такие проблемы решать. И повторюсь, пока очевидных путей её оптимизации/изменения не видно. Тем более что проекту уже больше 2-ух лет, и так просто взять все, да и поменять – ну сами понимаете.
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|


























