| |
 Графический фильтр на Cortex-M7 Графический фильтр на Cortex-M7, Увеличение ровно в 2 раза |
|
|
|
|
 Jul 16 2018, 05:35 Jul 16 2018, 05:35
|

Местный

Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126

|
Бьюсь над реализацией графического фильтра HQ2X на STM32H743 (Cortex-M7). Фильтр работает, но притормаживает, когда в кадре много мелких деталей. Была предпринята оптимизация: Switch/Case из 256 значений был заменён на JumpTable. Не помогло. Исходный код фильтра (Keil ARM MDK):  HQ2x.rar
HQ2x.rar ( 8.36 килобайт )
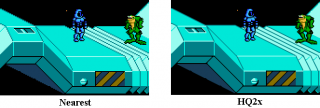
Кол-во скачиваний: 21Требуется растянуть кадр в 2 раза по обеим осям. Есть другие фильтры Scale2x, SaI2x , LQ2x - с ними проблем нет, на STM32H743 они идут довольно шустро(написанные на C, без Asm-а). Вот тут чувак заточил под NEON и DSP фильтр HQnX (что не годится для Cortex-M7): https://pyra-handheld.com/boards/threads/ru...sp.69047/page-5Существуют ли аналогичные графические фильтры (в частности HQ 2x), оптимизированные на ассемблере для ядер ARM Cortex-M7? Работа фильтра пояснена на рисунке:
Сообщение отредактировал __inline__ - Jul 16 2018, 05:37
|
|
|
|
|
|
|
|
Jul 16 2018, 06:12
|

Профессионал
Группа: Участник
Сообщений: 1 620
Регистрация: 22-06-07
Из: Санкт-Петербург, Россия
Пользователь №: 28 634
|
А попорбовать вместо ассемблерных вставок (которые обычно сбивают оптимизатор) использовть встроенные инлайны компилятора? В случае GCC, к примеру, могут оптимизатором варьироваться регистры, содержащие исходные значения/результаты... Кстати, сравнение для четырех восьмибитных чисел должно быть тоже в SIMD... скорее всего. Вы его делаете "в ручную". Код Searching for 'SSUB8'...
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core\Include\cmsis_armcc.h(803):#define __SSUB8 __ssub8
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core\Include\cmsis_armclang.h(1381):__STATIC_FORCEINLINE uint32_t __SSUB8(uint32_t op1, uint32_t op2)
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core\Include\cmsis_armclang.h(1385): __ASM volatile ("ssub8 %0, %1, %2" : "=r" (result) : "r" (op1), "r" (op2) );
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core\Include\cmsis_gcc.h(1590):__STATIC_FORCEINLINE uint32_t __SSUB8(uint32_t op1, uint32_t op2)
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core\Include\cmsis_gcc.h(1594): __ASM volatile ("ssub8 %0, %1, %2" : "=r" (result) : "r" (op1), "r" (op2) );
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core\Include\cmsis_iccarm.h(397): #define __SSUB8 __iar_builtin_SSUB8
C:\USER\SVN\CMSIS_5-5.3.0\CMSIS\Core_A\Include\cmsis_iccarm.h(310): #define __SSUB8 __iar_builtin_SSUB8
7 occurrence(s) have been found. И самый главный вопрос - DATA CACHE включен в процессоре?
Сообщение отредактировал Genadi Zawidowski - Jul 16 2018, 06:18
|
|
|
|
|
|
|
|
Jul 16 2018, 07:49
|
Местный
Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126
|
Цитата(Genadi Zawidowski @ Jul 16 2018, 07:12)  А попорбовать вместо ассемблерных вставок (которые обычно сбивают оптимизатор) использовть встроенные инлайны компилятора? В случае GCC, к примеру, могут оптимизатором варьироваться регистры, содержащие исходные значения/результаты...
Кстати, сравнение для четырех восьмибитных чисел должно быть тоже в SIMD... скорее всего. Вы его делаете "в ручную". Наскоряк не нашёл CMSIS-овский хедер, поэтому на ассемблере написал. Попробуем использовать инлайны. Цитата(Genadi Zawidowski @ Jul 16 2018, 07:12) И самый главный вопрос - DATA CACHE включен в процессоре? Да. Без него всё очень сильно медленно.
|
|
|
|
|
|
|
|
Jul 16 2018, 07:54
|
Местный
Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126
|
Цитата(ViKo @ Jul 16 2018, 08:26) Рисунок врет. Например, глаза лягушонка он размыл (округлил), а такой же черный квадрат недалеко оставил, как есть. И диагональные линии выглядят слишком красиво.
Растянуть в 2 раза - половина пикселей (по одной оси) уже есть, а половину всунуть кубической интерполяцией. Еще есть пиксели по диагонали, те нужно интерполировать побеим осям. Не врёт. Это волшебный фильтр. Не просто билинейная-бикубическая фильтрация , а смарт-фильтр, заточенный под пиксель-арт. В доказательство прикрепляю программу (под винду) вместе с исходником и мейкфайлом. Фильтр LQ2x (практически результат схож с HQ2x, но быстрее и легче для STM32):
LQ2x_WIN32.rar ( 218.86 килобайт )
Кол-во скачиваний: 16Входные данные: файл test.raw, 160x102 пикселя RGB 8:8:8 Выходные данные после отработки программы : LQ2x.raw 204x320 пикселей RGB 8:8:8 В программе фильтр делает ещё поворот на 90 градусов и работает в цветовом пространстве RGB 5:6:5 (для моих целей). RAW смотреть к примеру IrfanView, выставив длину, ширину и пиксель-формат. Ну и ниже картинка с результатами фильтров (с википедии):
Сообщение отредактировал __inline__ - Jul 16 2018, 07:57
|
|
|
|
|
|
|
|
Jul 16 2018, 08:17
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(__inline__ @ Jul 16 2018, 11:07) При -O3 -Otime switch/case заменяется на Jumptable при условии, что есть некая упорядоченность в проверяемых значениях. А в фильтре она идёт в разнобой. Максимум на что можно надеяться при таком подходе - это на поиск с бинарным разделением Ещё и не факт что подобная раскрутка циклов: Код if ((w1 != w5) && (Diff(y, RGBtoYUV[w1]))) pattern |= (1 << 0);
if ((w2 != w5) && (Diff(y, RGBtoYUV[w2]))) pattern |= (1 << 1);
if ((w3 != w5) && (Diff(y, RGBtoYUV[w3]))) pattern |= (1 << 2);
if ((w4 != w5) && (Diff(y, RGBtoYUV[w4]))) pattern |= (1 << 3);
if ((w6 != w5) && (Diff(y, RGBtoYUV[w6]))) pattern |= (1 << 4);
if ((w7 != w5) && (Diff(y, RGBtoYUV[w7]))) pattern |= (1 << 5);
if ((w8 != w5) && (Diff(y, RGBtoYUV[w8]))) pattern |= (1 << 6);
if ((w9 != w5) && (Diff(y, RGBtoYUV[w9]))) pattern |= (1 << 7); даст ускорение. Тело цикла достаточно большое, чтобы одна команда перехода в конце незначительно влияла на скорость. Зато кеша надо намного меньше.
|
|
|
|
|
|
|
|
Jul 16 2018, 08:35
|
Частый гость
Группа: Участник
Сообщений: 182
Регистрация: 16-10-15
Пользователь №: 88 894
|
Цитата(__inline__ @ Jul 16 2018, 11:35) Вот тут чувак заточил под NEON и DSP фильтр HQnX (что не годится для Cortex-M7) NEON имеет множество пробелов по сравнению с возможностями Cortex-M7. И уж точно Cortex-M7 может выполнять всё что есть в NEON. Нужно просто перелопатить код, удаляя и заменяя вставки NEON функций.
|
|
|
|
|
|
|
|
Jul 16 2018, 08:50
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Я так понимаю - Вы сами пытались оптимизировать функцию Diff() asm-вставками? И в её начале - закомментаренное си-тело? Если так, то действие: Код int c1v = (c1 & Vmask) - (c2 & Vmask);
if (Absolute(c1v) > trV) совсем не аналогично варианту на асме ниже. Подумайте, что будет если к примеру c1==0x81, c2==0 в первом и во втором случае. Если конечно в реализации изначально не заложено какое-то ограничение по количеству цветов (диапазону значений байтов). Но в любом случае: взятие модуля от числа - не аналогично операции x=-x. Да и вычитать SSUB8 c1,c2 чтобы потом находить NEG от каждого байта - это как-то бессмысленно. Почему бы тогда сразу не сделать SSUB8 c2,c1 ? PS: Так что похоже у Вас ещё и реализация кривая.... 
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|