Бьюсь над реализацией графического фильтра HQ2X на STM32H743 (Cortex-M7). Фильтр работает, но притормаживает, когда в кадре много мелких деталей.
Была предпринята оптимизация: Switch/Case из 256 значений был заменён на JumpTable. Не помогло. Исходный код фильтра (Keil ARM MDK):
 HQ2x.rar
HQ2x.rar ( 8.36 килобайт )
Кол-во скачиваний: 21Требуется растянуть кадр в 2 раза по обеим осям.
Есть другие фильтры Scale2x, SaI2x , LQ2x - с ними проблем нет, на STM32H743 они идут довольно шустро(написанные на C, без Asm-а).
Вот тут чувак заточил под NEON и DSP фильтр HQnX (что не годится для Cortex-M7):
https://pyra-handheld.com/boards/threads/ru...sp.69047/page-5Существуют ли аналогичные графические фильтры (в частности HQ 2x), оптимизированные на ассемблере для ядер ARM Cortex-M7?
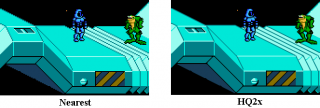
Работа фильтра пояснена на рисунке:
Сообщение отредактировал __inline__ - Jul 16 2018, 05:37


















 Jul 16 2018, 05:35
Jul 16 2018, 05:35