| |
 FEC на ПЛИС FEC на ПЛИС, пиарю красоту SV |
|
|
|
|
 Jun 19 2011, 09:57 Jun 19 2011, 09:57
|
Вечный ламер

Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453

|
сделал отдельную тему для проекта с началом здесь сообщения из кросс тем переместил. продолжаем пиарить красоту SV. итак новый релиз проекта БЧХ : 1. переписана работа с математикой в полях галуа. Теперь ква собирает декодер много быстрее, почти не задумываясь и не требует кучу памяти %) 2. переписан статически конфигурируемый БЧХ кодер/декодер, удалены лишние модули, ясность выше код чище 3. добавлен статический конфигурируемый RS кодер/декодер, стиль унифицирован с БЧХ кодером. Внимание : в сорцах есть реализация BM алгоритма, требующая на декодирование всего check тактов (!!! именно тактов а не шагов). 4. модифицированы random constraints тестбенчи, ясность выше, код чище. 5. Все как и прежде, не требует каких либо генераторов, скриптов и т.д. Вычисляется и синтезируется по месту. Расчет генераторного полинома БЧХ по прежнему не сделан %( Динамически конфигурируемые кодеры/декодеры выкладывать не буду, это уж как нить сами  UPD. Естественно осталась возможность использовать несколько инстансов кодеров с разными параметрами в одном проекте %)
--------------------
|
|
|
|
|
|
|
|
Mar 16 2012, 06:34
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
1. Причесал описание, для БЧХ добавил полиномов, кое что поправил в тестбенче 2. Добавил статически конфигурируемый декодер РС со стираниями, по алгоритму ribm, правда реализации только самая быстрая и самая медленная. 3. Различные алгоритмы декодирования РС со стираниями в идеалках (BM, IBM, rIBM, RIBM) ЗЫ. точнее не самая быстрая, можно посчитать также за check тактов, если полином локаторов стираний, рассчитать заранее используя блок rs_eras_syndrome_count_poly для вычисления синдрома и полинома локаторов стираний 
--------------------
|
|
|
|
|
|
|
|
Mar 16 2012, 09:07
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Цитата для БЧХ добавил полиномов Не нашел. Функция generate_pol_coeficients таже.
Сообщение отредактировал Denisnovel - Mar 16 2012, 09:09
|
|
|
|
|
|
|
|
Mar 16 2012, 09:29
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Я думал что добавили функцию расчета полиномов. Проблема в том, что нужно считать больше 511. Ну да ладно. Кстати, нашел еще одну реализацию БМ, можно ли при этом уменьшить обьем на 40%?
|
|
|
|
|
|
|
|
Mar 16 2012, 09:39
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Mar 16 2012, 03:29)  Я думал что добавили функцию расчета полиномов. Проблема в том, что нужно считать больше 511. Ну да ладно. все никак время не найду разобраться что там к чему и сделать. Цитата Кстати, нашел еще одну реализацию БМ, можно ли при этом уменьшить обьем на 40%? надо глянуть на досуге Цитата(des00 @ Mar 16 2012, 03:33) надо глянуть на досуге хмм, смотрю алгоритм на странице 773, судя по алгоритму должно быть 2*t умножителей GF(2^m), смотрю выложенный код Код data_t tetta [0 : t2+1];
logic tetta_clear [0 : t2+2];
data_t gamma [0 : t2+2]; те же t2 умножителей %) (t2+1) это константа, а если еще учесть что у них в алгоритме Код For r = 0 step 1 until 2t-1 do , а в выложенном коде Код for (int r = 0; r <= t-1; r += 1) я немного смущен %)
--------------------
|
|
|
|
|
|
|
|
Mar 16 2012, 17:59
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 16 2012, 10:34) 1. Причесал описание, для БЧХ добавил полиномов, кое что поправил в тестбенче 2. Добавил статически конфигурируемый декодер РС со стираниями, по алгоритму ribm, правда реализации только самая быстрая и самая медленная. 3. Различные алгоритмы декодирования РС со стираниями в идеалках (BM, IMB, rIBM, RIBM) ЗЫ. точнее не самая быстрая, можно посчитать также за check тактов, если полином локаторов стираний, рассчитать заранее используя блок rs_eras_syndrome_count_poly для вычисления синдрома и полинома локаторов стираний Для кода БЧХ GF(2^11) исправляющего 8 ошибок, какую тактовую частоту может обеспечить ваш декодер?
|
|
|
|
|
|
|
|
Mar 17 2012, 05:33
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 17 2012, 06:30) полином дайте проверю. Из того что делал, декодер с t = 23 в поле GF(2^8), свободно, не особо напрягаясь, работает на 200МГц на третьем сыклоне. Для GF(2^11) проверить надо, но думаю что 150 на том же чипе даст точно. у меня дает 135 на третьем циклоне, а надо 155. Какими способами можно увеличить частоту?
|
|
|
|
|
|
|
|
Mar 17 2012, 15:10
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Gold777 @ Mar 17 2012, 00:33) у меня дает 135 на третьем циклоне, а надо 155. полином дайте, проверю сколько получиться. Вот для примера кодер {8191, 8152, 3/7} работа в поле GF(2^13), чип EP3C25...C8, используется TQ, все по дефолту, порты виртуальные результаты LE/REG/Fmax bch_enc 45/44/402.09MHz bch_dec в режиме ribm_t_by_t 823/447/180.6MHz и это при математике в поле GF(2^13), 5-6 слоев логики. При этом TQ показывает пару возможных оптимизаций для разгона, но если учесть что на декодирование уходит 22 такта, а пакет длинной 8191 такт, то можно сделать BM по мультициклу и задрать тактовую/битовую потока под 250-300 МГц %) Цитата Какими способами можно увеличить частоту? Единственный способ : оптимизация логических функций и грамотная конвейеризация под целевую ПЛИС. Научиться этому в двух словах не возможно, все приходит с опытом.
--------------------
|
|
|
|
|
|
|
|
Mar 17 2012, 18:07
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 17 2012, 19:10) полином дайте, проверю сколько получиться.
Вот для примера кодер {8191, 8152, 3/7} работа в поле GF(2^13), чип EP3C25...C8, используется TQ, все по дефолту, порты виртуальные полином 2053(x^11+x^2+1), код (2040, 1952) поле GF(2^11) 8 ошибок чип EP3C25...C8
|
|
|
|
|
|
|
|
Mar 18 2012, 15:28
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(des00 @ Mar 18 2012, 09:20) а где генераторный полином? примитивный полином мне не нужен %) без генераторного полинома, bch_enc не собрать, а результаты по декодеру LE/REG/Fmax bch_dec в режиме ribm_t_by_t 1127/790/213,04MHz 4 слоя логики. Если учесть что для этого результата решение BM занимает 129 тактов, а пакет весит 2040, то можно посадить BM для работы на половинном клоке, поставить мультицикл и выжать 250-300 МГц. Но и в базе 200 мегабит в секунду обрабатывает не особо напрягаясь %) если не сложно сообщите генераторный полином для этого кода для коллекции, можно в личку. ну не умею я пока их самостоятельно рассчитывать %( А ковыряние в гугле мне не помогло %( Всем кто решиться использовать этот декодер при низких Eb/N0, надо помнить что в этом декодере, перебор ченя и коррекция ошибок происходят одновременно. Поэтому в случае отказа от декодирования, который определиться в конце ченя, декодер размножает ошибки. Что бы это побороть, нужно немного модифицировать ченя, выплюнуть сырые данные в фифошку/память вместе с коррекцией ошибок ну и потом считать с коррекцией или без %) но это не сложно и делается минут за 10-20 %)
--------------------
|
|
|
|
|
|
|
|
Mar 18 2012, 15:59
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 18 2012, 19:28) без генераторного полинома, bch_enc не собрать, а результаты по декодеру LE/REG/Fmax
bch_dec в режиме ribm_t_by_t 1127/790/213,04MHz
4 слоя логики. Если учесть что для этого результата решение BM занимает 129 тактов, а пакет весит 2040, то можно посадить BM для работы на половинном клоке, поставить мультицикл и выжать 250-300 МГц. Но и в базе 200 мегабит в секунду обрабатывает не особо напрягаясь %)
если не сложно сообщите генераторный полином для этого кода для коллекции, можно в личку. ну не умею я пока их самостоятельно рассчитывать %( А ковыряние в гугле мне не помогло %(
Всем кто решиться использовать этот декодер при низких Eb/N0, надо помнить что в этом декодере, перебор ченя и коррекция ошибок происходят одновременно. Поэтому в случае отказа от декодирования, который определиться в конце ченя, декодер размножает ошибки. Что бы это побороть, нужно немного модифицировать ченя, выплюнуть сырые данные в фифошку/память вместе с коррекцией ошибок ну и потом считать с коррекцией или без %) но это не сложно и делается минут за 10-20 %) Да, интересный у вас результаты получились. Меня интересует именно декодер. Вроде для него генераторный полином я не использовал, но посмотрю. Точно сейчас посмотреть не могу, но приблизительно sibm/5000 LE/700-800 Reg/135 Fmin Mhz (требуется 155), но результат за 16 тактов. На решение не более 32 тактов, иначе не успею. Интересно какие при таком условии будет характеристики вашего декодера. Можете объяснить как посадить BM для работы на половинном клоке и что значит поставить мультицикл и выжать 250-300 МГц, вообще как-то не очень понятно что вы имеете ввиду. Если можно, объясните поподробнее.
Сообщение отредактировал Gold777 - Mar 18 2012, 17:49
|
|
|
|
|
|
|
|
Mar 19 2012, 03:52
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Gold777 @ Mar 18 2012, 10:59) Точно сейчас посмотреть не могу, но приблизительно sibm/5000 LE/700-800 Reg/135 Fmin Mhz (требуется 155), но результат за 16 тактов. На решение не более 32 тактов, иначе не успею. Интересно какие при таком условии будет характеристики вашего декодера. bch_dec(ribm_1t) BM выполняется за t+1 = 9 тактов, 3209/732/170.85MHz, судя по TQ упирается в разводку, если сделать register dublication + кое что подпилить в BM думаю что выйдет на 200МГц. bch_dec(ribm_2t) BM выполняется за 2*t+1 = 17 тактов, 2472/776/184.95MHz, тут сложнее, надо бороть "лишний" мультиплексор в BM Цитата Можете объяснить как посадить BM для работы на половинном клоке и что значит поставить мультицикл и выжать 250-300 МГц, вообще как-то не очень понятно что вы имеете ввиду. Если можно, объясните поподробнее. Хмм, вам лучше почитать мои публикации о TQ, временных ограничениях, одноцикловых цепях и мультицикловых. Если на пальцах, то подаете на clockena меандр и говорите временному анализатору что задержки считать не для периода T, а для периода 2*T. Естественно что производительность именно этого блока упадет, но если ее достаточно для выполнения задачи, то.... %)
--------------------
|
|
|
|
|
|
|
|
Mar 19 2012, 09:33
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 19 2012, 09:30) Кстати, вы же тестируетесь с каким то кодером. Генераторный полином можно получить, подав "дельта импульс". последовательность со всеми нулевыми битами, кроме одного %) Вы имеете ввиду подать на вход кодера дельта импульс? Еще было бы интересно посмотреть результаты для sibm алгоритма, чтобы сравнить.
Сообщение отредактировал Gold777 - Mar 19 2012, 09:34
|
|
|
|
|
|
|
|
Mar 19 2012, 13:27
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Gold777 @ Mar 19 2012, 04:33) Вы имеете ввиду подать на вход кодера дельта импульс? да. нашел стандарт 975.1 там указаны функции циклотомических классов для получение генераторных полиномов GF(2^11), на досуге получу полином %) Цитата Еще было бы интересно посмотреть результаты для sibm алгоритма, чтобы сравнить. а смысл? он гарантировано проиграет, для этого достаточно посмотреть как рассчитывается delta %) bch_dec(ibm_2t) выполняется за 2t+1 = 17 тактов, 2816/957/145.69MHz bch_dec(ibm_4t) выполняется за 4t+1 = 33 такта, 2212/959/188.08MHz bch_dec(ibm_2t_by_t) выполняется за 2t + 2(t+1)^2+1 = 179 такта, 1805/1057/238.04MHz. Но этот в свое время конвейризировался по самое нехочу
--------------------
|
|
|
|
|
|
|
|
Mar 19 2012, 14:30
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 19 2012, 17:27) да. нашел стандарт 975.1 там указаны функции циклотомических классов для получение генераторных полиномов GF(2^11), на досуге получу полином %)
а смысл? он гарантировано проиграет, для этого достаточно посмотреть как рассчитывается delta %)
bch_dec(ibm_2t) выполняется за 2t+1 = 17 тактов, 2816/957/145.69MHz
bch_dec(ibm_4t) выполняется за 4t+1 = 33 такта, 2212/959/188.08MHz
bch_dec(ibm_2t_by_t) выполняется за 2t + 2(t+1)^2+1 = 179 такта, 1805/1057/238.04MHz. Но этот в свое время конвейризировался по самое нехочу Для этого кода (2040,1952) t= 8 G1(x) = x11 + x2 + 1, G3(x) = x11 + x5 + x3 + x2 + 1, G5(x) = x11 + x6 + x5 + x + 1, G7(x) = x11 + x7 + x3 + x2 + 1, G9(x) = x11 + x8 + x5 + x2 + 1, G11(x) = x11 + x8 + x6 + x5 + x4 + x + 1, G13(x) = x11 + x10 + x3 + x2 + 1, G15(x) = x11 + x10 + x9 + x8 + x3 + x + 1. g(x)=G1(x)*G3(x)*G5(x)*G7(x)*G9(x)*G11(x)*G13(x)*G15(x)
|
|
|
|
|
|
|
|
Mar 19 2012, 19:26
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Mar 19 2012, 20:03) спасибо !!! А так не проще: Если надо просто построить код, то набрать в матлабе строчку: >> [genpoly,errorcorr] = BCHGENPOLY(2047,2047 - 11*8)
|
|
|
|
|
|
|
|
Mar 20 2012, 03:42
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(SKov @ Mar 19 2012, 14:26) А так не проще: Если надо просто построить код, то набрать в матлабе строчку: проще, но в матлабе что у меня на машине написано Цитата LimitationsThe maximum allowable value of n is 511. у вас какая версия матлаба ?
--------------------
|
|
|
|
|
|
|
|
Mar 20 2012, 04:15
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Для генерации длинных кодов я использовал следующий файл.
Прикрепленные файлы
 bch.zip
bch.zip ( 1.18 килобайт )
Кол-во скачиваний: 128
|
|
|
|
|
|
|
|
Mar 20 2012, 06:20
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Mar 20 2012, 07:42) проще, но в матлабе что у меня на машине написано
у вас какая версия матлаба ? R2010a. Ограничение на степень двойки при генерации БЧХ - не более 16. Так что до длин 65535 все должно работать. Сейчас на рутрекере есть более поздняя версия матлаба.Может быть там еще лучше.
|
|
|
|
|
|
|
|
Mar 22 2012, 17:01
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 18 2012, 19:28) Всем кто решиться использовать этот декодер при низких Eb/N0, надо помнить что в этом декодере, перебор ченя и коррекция ошибок происходят одновременно. Поэтому в случае отказа от декодирования, который определиться в конце ченя, декодер размножает ошибки. Что бы это побороть, нужно немного модифицировать ченя, выплюнуть сырые данные в фифошку/память вместе с коррекцией ошибок ну и потом считать с коррекцией или без %) но это не сложно и делается минут за 10-20 %) Почему вы решили сделать процедуру Ченя и исправление ошибок одновременно?
Сообщение отредактировал Gold777 - Mar 22 2012, 17:02
|
|
|
|
|
|
|
|
Mar 25 2012, 13:37
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Правильно ли я понял, что для плис оптимизация поиска Ченя не актуальна? Clock enable применен для энергосбережения? Если в какой-то момент декодер мне не нужен, то я должен отключить clock enable. Перед включением сбросить ресетом(для инициализации) и подать clock enable?
|
|
|
|
|
|
|
|
Mar 25 2012, 15:13
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Mar 25 2012, 17:37) Правильно ли я понял, что для плис оптимизация поиска Ченя не актуальна? Пробовал оптимизировать процедуру Ченя, конкретнее оптимизировал умножители на константу, как представлено в статье. В итоге выигрыша никакого не получил. Но делал по циклон 3, возможно под другое железо что-то и получится.
Сообщение отредактировал Gold777 - Mar 25 2012, 15:14
|
|
|
|
|
|
|
|
Mar 25 2012, 16:04
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Mar 25 2012, 07:37) Clock enable применен для энергосбережения?
Если в какой-то момент декодер мне не нужен, то я должен отключить clock enable. Перед включением сбросить ресетом(для инициализации) и подать clock enable? clkena можно использовать по разному, в том числе и для энергосбережения. пока декодер не получит блок, он работать не будет. это видно из логики его работы. в случае энергосбережения, можно его не сбрасывать, но, в зависимости от того, в какой момент времени вы остановили декодер, на выходе может быть мусор после старта. Поэтому использовать сброс или нет зависит от вас %) Цитата(Gold777 @ Mar 25 2012, 09:13) В итоге выигрыша никакого не получил. я вам сразу про это сказал %)
--------------------
|
|
|
|
|
|
|
|
Mar 25 2012, 16:15
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Mar 25 2012, 20:04) я вам сразу про это сказал %) Да я помню. Хотел посмотреть ради интереса что изменится. Действительно вы были правы.
|
|
|
|
|
|
|
|
Mar 25 2012, 19:46
|
Профессионал
Группа: Свой
Сообщений: 1 284
Регистрация: 9-04-06
Пользователь №: 15 968
|
Цитата(des00 @ Mar 23 2012, 09:57) Также есть версии декодера с динамически изменяемым {n, check}, но смысла выкладывать не вижу. Выложенные сорцы заточены под простую реализацию динамического изменения, кому надо тот сделает %) А {n,check} - в Вашей версии любые можно поставить на ходу или заранее определенный набор (набор определяется до синтеза) ? Модифицировал Ваш код для декодирования 12 кодов, каждый со своим {n,check}, длина до 16384. Декодер занимает около 5000 LE. С ростом количества кодов растет и декодер, примерно линейно. В основном это умножители в галуа на константы. Если бы были умножители числа на число, то от количества кодов декодер бы не так сильно рос. Только вот не знаю на сколько такое решение реально. Просто в моей задаче скорость не нужна (50 мгц за глаза), а вот количество кодов надо 36... В Вашей версии динамически изменяемых {n,check} умножители в галуа также на константы или умножители динамического числа на динамическое число?  То что спрашивал у Вас по таймквесту, все вроде получилось в моделсиме, огромное спасибо! Надо дождаться железа и испытать в реале...
|
|
|
|
|
|
|
|
Mar 26 2012, 09:54
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(alexPec @ Mar 25 2012, 13:46) А {n,check} - в Вашей версии любые можно поставить на ходу или заранее определенный набор (набор определяется до синтеза) ? Для работы мне нужны были с динамическим укорочением и с предопределенном набором check. Цитата Только вот не знаю на сколько такое решение реально. Просто в моей задаче скорость не нужна (50 мгц за глаза), а вот количество кодов надо 36...
В Вашей версии динамически изменяемых {n,check} умножители в галуа также на константы или умножители динамического числа на динамическое число? Строго говоря сорцы что выложены, были оптимизированы (по логике и конвейеру) под конкретную реализацию статического декодера. Для динамического декодера нужно делать немного по другому : 1. genstart == 0, это позволит очень просто считать синдромы по максимальному check (не нужна коррекция позиций синдромов) цена : дополнительный умножитель при расчете значений ошибок 2. везде считать на максимальный check 3. уйти с RIBM на rIBM алгоритм (не нужна коррекция позиций готового полинома локаторов). цена : несколько больший ресурс при последовательном вычислении. 4. ченя делать в обратном порядке в отдельном проходе (не нужна начальная коррекция при укорочении кода). ну собственно все, в итоге ресурс декодера у вас будет чуть больше, чем статического декодера кода с максимальным check Цитата То что спрашивал у Вас по таймквесту, все вроде получилось в моделсиме, огромное спасибо! Надо дождаться железа и испытать в реале... рад что вы разобрались в вопросе %) И еще про динамическую конфигурацию. Если кол-во генераторных полиномов больше 4-х, то выгоднее поставить кодер с умножителями на число, иначе мультиплексор + 4 кодера %) (для полей GF(2^8)
--------------------
|
|
|
|
|
|
|
|
Mar 28 2012, 19:50
|
Группа: Новичок
Сообщений: 2
Регистрация: 27-03-12
Пользователь №: 71 038
|
Доброго времени суток!прочитал представленные исходники!и никак не могу разобраться, как все-таки поступать, в процедуре Ченя, с укороченными кодами?у меня получаются позиции ошибок но соответственно со смещением на длину укорочения кода!пытался задерживать FIFO на эту задержку но получается расхождение!может кто нибудь подскажет как правильно быть? заранее спасибо!
|
|
|
|
|
|
|
|
Mar 29 2012, 16:34
|
Группа: Новичок
Сообщений: 2
Регистрация: 27-03-12
Пользователь №: 71 038
|
Вопрос разрешился!))))
|
|
|
|
|
|
|
|
Mar 29 2012, 20:21
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Mar 29 2012, 21:48) Делаю параллельный БЧХ. При этом он получается в несколько раз больше Рид-Соломона при той же пропускной способности. Так должно быть и почему? Я так понимаю все зависит от параметров ваших кодов.
|
|
|
|
|
|
|
|
Apr 20 2012, 07:02
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Я сделал так Код osyndrome <= ieop? osyndrome_comb[n%dec_width]: osyndrome_comb[dec_width]; Где osyndrome_comb[n%dec_width] как раз синдром без учета последних бит. Но в этом случае критический путь получился очень длинным
|
|
|
|
|
|
|
|
Apr 23 2012, 16:33
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Apr 1 2012, 19:07) если имелось в виду по 8 бит за 1 такт, то чему удивляться то? ручками распишите получаемую логику на уровне функций и это станет очевидно.
ЗЫ. если вам нужна производительсность бчх 8 бит за 1 такт (что, если брать например сыклон 3, соответствует ~200 мегабайт в секунду), то как вариант поставить 8 декодеров, с одним блоком BM. Если нужна производительность 8 бит за такт для кода длиной 2040, получается, что блок синдромов получит результат за 255 тактов. Т.е. за один так для первого синдрома вычисляется (alfa^1,alfa^2,alfa^3,..,alfa^8). Как вы предлагаете поставить 8 декодеров как-то не очень понятно? Если поставить 8 блоков подсчета синдромов параллельно, получается в первый блок идет первый бит, во второй блок 2-й бит и т.д, хотя этот второй бит нужен для подсчета в первом блоке. И еще вопрос как поступать, если нужна производительность 64 бита за такт для этого же кода? Думаю, что за 31-32 такта думаю по частоте не войдет.
|
|
|
|
|
|
|
|
Apr 24 2012, 05:16
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Может это поможет на ст 771. Если не секрет, делаете для G.975.1?
|
|
|
|
|
|
|
|
Apr 24 2012, 07:44
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Apr 24 2012, 09:16) Может это поможет на ст 771. Если не секрет, делаете для G.975.1? Получается надо обрабатывать по 8 бит или по 16, тогда возможно по частоте войдет. Да, делаю для G.975.
|
|
|
|
|
|
|
|
Apr 24 2012, 13:53
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Apr 24 2012, 14:03) Нужно сохранять синдром и поочереди подавать их в БМ.
Как я понял вы делаетет I.4. Почему выбрали этот алгоритм? Еще более не скромный вопрос: Т8 или Орион? Я делаю I.3. I.4 сделал там вроде все понятно, идет распараллеливание данных на 64 блока т.к каждый бит принадлежит отдельному кодовому слову. Если вы сделали I.3, расскажи как. Еще интересно сколько ваши декодеры заняли ресурсов. Поймите правильно, но мне бы не хотелось называть организацию в которой работаю. Цитата(des00 @ Apr 24 2012, 13:43) а если заранее, записать 8 фреймов в память перед декодированием и после декодирования ? Собственно так и собрался делать.
|
|
|
|
|
|
|
|
Apr 24 2012, 16:35
|
Профессионал
Группа: Участник
Сообщений: 1 050
Регистрация: 4-04-07
Пользователь №: 26 775
|
Цитата(des00 @ Apr 24 2012, 19:14) турбо (на основе БЧХ кодов было бы интересно порыть) есть такие практические схемы турбокодов-произведения на основе БЧХ. Цитата(des00 @ Apr 24 2012, 19:14) И сопутствующий вопрос, как тестировать вероятностные декодеры без матлаба? сгородить в верилоге модулятор/демодулятор + модель awgn ? я использую собственные программные модели (С++) модулятор/демодулятор + модель awgn.
|
|
|
|
|
|
|
|
Apr 24 2012, 16:44
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Serg76 @ Apr 24 2012, 11:35) есть такие практические схемы турбокодов-произведения на основе БЧХ. как раз от вас я о них и слышал %), не поделитесь ссылками? Цитата я использую собственные программные модели (С++) модулятор/демодулятор + модель awgn. вы же вроде как делаете как раз все для PC платформы, или вы через DPI портируете это в HDL симуляторы и тестируете HDL корки ?
--------------------
|
|
|
|
|
|
|
|
Apr 24 2012, 16:59
|
Профессионал
Группа: Участник
Сообщений: 1 050
Регистрация: 4-04-07
Пользователь №: 26 775
|
Цитата(des00 @ Apr 24 2012, 19:44) как раз от вас я о них и слышал %), не поделитесь ссылками? по-моему здесь http://www.google.com.ua/url?sa=t&rct=...c2g&cad=rjaЦитата(des00 @ Apr 24 2012, 19:44) вы же вроде как делаете как раз все для PC платформы, или вы через DPI портируете это в HDL симуляторы и тестируете HDL корки ? неа, только программное моделирование
|
|
|
|
|
|
|
|
Apr 24 2012, 17:02
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Apr 24 2012, 20:31) I.3 я сделал. Какие есть конкретные вопросы. По ресурсам сложно сказать, так как нужно еще оптимизировать кое-что. Чем не устроил I.4? Интересует реализация внутреннего декодера. Судя по документу, который скинули, у вас следующая схема: 8 блоков вычисления синдромов на входе по 8 бит, один блок решателя ключевого уравнения обрабатывающий данные с 8-ми каналов по очереди, 8 блоков Ченя по 8 бит. Записать 8 блоков данных в память перед декодированием и после декодирования (Вот этот момент особенно интересует). Вы так сделали? И еще по ресурсам было бы интересно хотя бы приблизительные результаты оценить. Можно в личку. I.4 устроил, но надо остальные FEC схемы реализовать.
|
|
|
|
|
|
|
|
Jun 25 2012, 11:39
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
To des00 Хочу сделать, чтобы IBM работал на частоте в два раза меньше. Для этого делаю multicycle как описано у вас в блоге. Причем в проекте несколько разных декодеров. Правильно ли я задал констрейты? Код set_multicycle_path -from {*bch_berlekamp:berlekamp|*} -to {*bch_berlekamp:berlekamp|*} -setup -end 2
set_multicycle_path -from {*bch_berlekamp:berlekamp|*} -to {*bch_berlekamp:berlekamp|*} -hold -end 1 Clock Enable для входа в модуле bch_berlekamp генерится следующем образом. Код iclkena <= ~iclkena;
Сообщение отредактировал Denisnovel - Jun 25 2012, 11:42
|
|
|
|
|
|
|
|
Jun 25 2012, 16:00
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Jun 25 2012, 05:39) Хочу сделать, чтобы IBM работал на частоте в два раза меньше. Для этого делаю multicycle как описано у вас в блоге. Причем в проекте несколько разных декодеров. Правильно ли я задал констрейты? Код set_multicycle_path -from {*bch_berlekamp:berlekamp|*} -to {*bch_berlekamp:berlekamp|*} -setup -end 2
set_multicycle_path -from {*bch_berlekamp:berlekamp|*} -to {*bch_berlekamp:berlekamp|*} -hold -end 1 Clock Enable для входа в модуле bch_berlekamp генерится следующем образом. Код iclkena <= ~iclkena; хммм, в таком случае вам выгодно подать именно тактовую в 2 раза ниже и сделать переходы между доменами. решение лучше со всех точек зрения. Если по мультициклам, то их накладывают на цепи между регистрами источниками сигнала и приемниками. Где в вашей команде указано что это относиться к регистрами ? )
--------------------
|
|
|
|
|
|
|
|
Jun 26 2012, 04:25
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
В моём кнстрейте описывается, что все регистры в модуле bch_berlekamp:berlekamp работают на частоте в два раза меньше. Т.е. источником и приемником является эти регистры. Или я не прав? Если я захочу сделать частоту в 2 раза меньше, то в PLL я должен выдать синхроную частоту. Как это описать?
Сообщение отредактировал Denisnovel - Jun 26 2012, 04:30
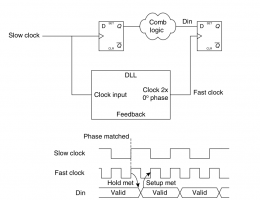
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Jun 26 2012, 04:50
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Jun 25 2012, 22:25) В моём кнстрейте описывается, что все регистры в модуле bch_berlekamp:berlekamp работают на частоте в два раза меньше. Т.е. источником и приемником является эти регистры. Или я не прав? хммм, вообще то регистры описываются через команду get_registers Цитата Если я захочу сделать частоту в 2 раза меньше, то в PLL я должен выдать синхроную частоту. Как это описать? хммм, сгененрировать PLL и посмотреть на вейвформы ее работы?
--------------------
|
|
|
|
|
|
|
|
Jun 26 2012, 09:15
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
А если написать так, то между регистрами модуля БМ будет увеличенный период? Код set_multicycle_path -from [get_registers{*bch_berlekamp:berlekamp|*}] -to [get_registers{*bch_berlekamp:berlekamp|*}] -setup -end 2
set_multicycle_path -from [get_registers{*bch_berlekamp:berlekamp|*}] -to [get_registers{*bch_berlekamp:berlekamp|*}] -hold -end 1 С PLL не поял? Допустим, я сделал синхронную частоту в два раза меньше, подал её на модуль БМ, как синхронизировать данные между этими clock domain? 
|
|
|
|
|
|
|
|
Jun 26 2012, 14:40
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Jun 26 2012, 04:15) А если написать так, то между регистрами модуля БМ будет увеличенный период? смотрите что говорит TQ, если он скажет что будет, значит будет. %) Цитата С PLL не поял? Допустим, я сделал синхронную частоту в два раза меньше, подал её на модуль БМ, как синхронизировать данные между этими clock domain? а если сделаете пусть и на одной частоте но с clkena синхронизировать не потребуется ? Повторю еще раз, прочитайте что такое PLL и ее свойства. Сгенерируйте в мегавизарде PLL и посмотрите на вейвформы выходных сигналов. Тогда сразу все поймете %)
--------------------
|
|
|
|
|
|
|
|
Jun 28 2012, 19:36
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
По PLL я имею ввиду, что одна ПЛЛ генерирует быстрый и медленный клок, то есть они синхронные, как на картинке выше . Ну да оставим PLL. У меня работает первый вариант задания контстрейтов  , TQ распознает их как мультисайкл. Самый критичный путь в этом случае от clken до регистров модуля БМ. Еще вопрос. Правильно ли я понимаю, что БЧХ может детектировать ошибки больше t, но меньше 2t, и определять их количество?
|
|
|
|
|
|
|
|
Jun 29 2012, 13:23
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Jun 28 2012, 23:36) Еще вопрос. Правильно ли я понимаю, что БЧХ может детектировать ошибки больше t, но меньше 2t, и определять их количество? БЧХ может детектировать 2t ошибок
|
|
|
|
|
|
|
|
Jun 29 2012, 13:55
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Jun 28 2012, 14:36) У меня работает первый вариант задания контстрейтов , TQ распознает их как мультисайкл. значит TQ вас понял %) Цитата(SKov @ Jun 29 2012, 08:35) Количество не может. Только сам факт наличия где-то ошибок кратности от 1 до d-1. Вот интересно, как я понял из учебников по кодированию, сам код БЧХ позволяет обнаружить большее кол-во ошибок, но не все из них. Ограничение d-1 связанно с использованием стандартных методов декодирования, через решение системы уравнений. Интересно чисто теоретически, есть ли методы позволяющие преодолеть эту границу? (ну кроме полного перебора или синдромного декодирования что почти тоже самое).
--------------------
|
|
|
|
|
|
|
|
Jun 29 2012, 14:34
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Jun 29 2012, 17:55) Вот интересно, как я понял из учебников по кодированию, сам код БЧХ позволяет обнаружить большее кол-во ошибок, но не все из них. Ограничение d-1 связанно с использованием стандартных методов декодирования, через решение системы уравнений. Интересно чисто теоретически, есть ли методы позволяющие преодолеть эту границу? (ну кроме полного перебора или синдромного декодирования что почти тоже самое). То, что я написал, не имеет отношение к БЧХ и справедливо для любого кода. Вообще, способность кода к обнаружению ошибок не имеет отношения к методу декодирования - это свойство кода, а не декодера. В принципе, код может обнаружить любую ошибку, не совпадающую с кодовым словом. Понятно, что некоторые ошибки веса d в принципе не могут быть обнаружены, если совпадают с кодовым словом. Если поделить количество кодовых слов веса d на общее количество векторов веса d, то легко посчитать, с какой вероятностью можно НЕ обнаружить ошибку веса d. Количество кодовых слов мин. веса для большинства коротких БЧХ известно точно. Для длинных кодов БЧХ известно, что их весовой спектр приближается к биномиальному распределению с ростом длины. Иногда можно пользоваться грубой оценкой необнаружения ошибки в виде 1/(2^r).
|
|
|
|
|
|
|
|
Jun 29 2012, 18:35
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(Gold777 @ Jun 29 2012, 21:51) Возник следующий вопрос. К примеру исправляющая способность кода 8 ошибок. На передающей стороне мы внесли 10 ошибок. Соответственно декодер может обнаружить 16 ошибок. Можем ли мы на этапе декодирования каким-либо образом сказать сколько конкретно ошибок у нас возникло или мы можем только гарантированно сказать что их больше восьми? Гарантированно мы не можем сказать ничего. Есть след. варианты. 1) На расстоянии D (D<9) от принятого вектора есть кодовое слово. Тогда произошло либо D ошибок либо, как минимум, d-D. 2) Ближайший кодовый вектор находится на расстоянии D (D>8). Тогда произошло не менее D ошибок. Это все, что можно сказать. В вашем конкретном случае 10 ошибок могли лечь как кодовое слово, тогда вы увидете кодовое слово на расстоянии 6 от принятого вектора. Это значит, что ошибок было либо 6, либо как минимум 16-6.
|
|
|
|
|
|
|
|
Jun 30 2012, 05:43
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(SKov @ Jun 29 2012, 09:34) То, что я написал, не имеет отношение к БЧХ и справедливо для любого кода. Спасибо за развернутый ответ, то что вы пишите понятно и сомнению не подлежит. Мой же вопрос заключался в существовании алгоритма декодирования БЧХ кодов, который обладает возможностью исправлять часть ошибок больше D (ведь по теории можно). Т.е. ИМХО классический БЧХ декодер обладает фиксированными, не вероятностными характеристиками (в не в том смысле что вероятность ошибки к нему не применима, а в том смысле что от прогона к прогону на случайном потоке он будет давать одинаковый результат), существует ли метод декодирования (итеративный алгоритм чейза не рассматриваем) позволяющий выйти за эти границы БЧХ ? ЗЫ. могу путать термины теории кодирования, прошу строго не судить %)
--------------------
|
|
|
|
|
|
|
|
Jun 30 2012, 06:07
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Jun 30 2012, 09:43) Спасибо за развернутый ответ, то что вы пишите понятно и сомнению не подлежит. Мой же вопрос заключался в существовании алгоритма декодирования БЧХ кодов, который обладает возможностью исправлять часть ошибок больше D (ведь по теории можно).
Т.е. ИМХО классический БЧХ декодер обладает фиксированными, не вероятностными характеристиками (в не в том смысле что вероятность ошибки к нему не применима, а в том смысле что от прогона к прогону на случайном потоке он будет давать одинаковый результат), существует ли метод декодирования (итеративный алгоритм чейза не рассматриваем) позволяющий выйти за эти границы БЧХ ?
ЗЫ. могу путать термины теории кодирования, прошу строго не судить %) Вы уже как-то задавали этот вопрос. Я помню, что были работы, позволяющие исправлять на одну ошибку больше, чем гарантирует граница БЧХ. Вроде, иногда можно исправить +2 ошибки. Больше я не видел.
|
|
|
|
|
|
|
|
Jul 4 2012, 13:04
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Почему размерность порта количества ошибок m? Код logic [m-1 : 0] obiterr Может лучше привязать его к количесту исправляемых ошибок Код logic [$clog2(t)-1:0] obiterr
|
|
|
|
|
|
|
|
Jul 4 2012, 17:13
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Denisnovel @ Jul 4 2012, 07:04) Почему размерность порта количества ошибок m? Код logic [m-1 : 0] obiterr Может лучше привязать его к количесту исправляемых ошибок Код logic [$clog2(t)-1:0] obiterr ваша правда, можно но смысл ? при вариации типов декодеров постоянно отслеживать разрядность этого порта? Экономия копейки, требуется введение нового типа, да и кому нужно переписать не сложно %)
--------------------
|
|
|
|
|
|
|
|
Oct 3 2012, 09:54
|
Участник
Группа: Участник
Сообщений: 33
Регистрация: 29-01-09
Пользователь №: 44 114
|
Возможно мой вопрос покажется глупым, но я пытаюсь разобраться в SystemVerilog и тестбенчах. Пример из обсуждаемого здесь проекта: Код rs_enc
#(
.n ( n ) ,
.check ( check ) ,
.m ( m ) ,
.irrpol ( irrpol ) ,
.genstart ( used_genstart )
)
uut_enc
(
.iclk ( iclk ) ,
.iclkena ( iclkena ) ,
.ireset ( ireset ) ,
//
.isop ( isop ) ,
.ieop ( ieop ) ,
.ieof ( ieof ) ,
.ival ( ival ) ,
.idat ( idat ) ,
//
.osop ( enc__osop ) ,
.oval ( enc__oval ) ,
.oeop ( enc__oeop ) ,
.odat ( enc__odat )
); Взято из файла тест бенча rs_eras_enc_dec_tb.v Что означает Код rs_enc
#(
.n ( n ) ,
.check ( check ) ,
.m ( m ) ,
.irrpol ( irrpol ) ,
.genstart ( used_genstart )
) Понятно что uut_enc - наследник или копия модуля rs_enc, но за что отвечает здесь #(...)? Цитата(nkie @ Oct 3 2012, 13:22) ... но за что отвечает здесь #(...)? все разобрался, передача параметров...
|
|
|
|
|
|
|
|
Oct 19 2012, 08:18
|
Знающий
Группа: Свой
Сообщений: 740
Регистрация: 24-07-06
Из: Minsk
Пользователь №: 19 059
|
Как оптимизировать рассчет GPOLY ? Синтезатор (использую synplify) на следующий код делает на 12 страниц RTL, содержащий ПЗУ и логику, тогда как на выходе всего лишь массив констант GPOLY CODE `include "rsParam.vh"
`include "gfFunctions.vh"
module testEnc (
output gpoly_t dataOut //%Данные выход кодера
);
//-----------------------------------------------------------
//% формирование таблиц
//-----------------------------------------------------------
gpoly_t GPOLY;
rom_t ALPHA_TO;
rom_t INDEX_OF;
always_comb
begin
ALPHA_TO = generate_gf_alpha_to_power(irrpol);
INDEX_OF = generate_gf_index_of_alpha(ALPHA_TO);
GPOLY = generate_pol_coeficients (genstart, rootspace, check, generate_gf_index_of_alpha(generate_gf_alpha_to_power(irrpol)), generate_gf_alpha_to_power(irrpol));
dataOut = GPOLY;
end
endmodule
|
|
|
|
|
|
|
|
Oct 19 2012, 11:55
|
Знающий
Группа: Свой
Сообщений: 740
Регистрация: 24-07-06
Из: Minsk
Пользователь №: 19 059
|
QUOTE (des00 @ Oct 19 2012, 10:09) Извините что не ответил сразу, да проблема именно в симплифае. По непонятным причинам он не может рассчитать генераторный полином по этой функции. Причем в режиме VHDL все ок, а вот в Verilog ну никак. Поэтому когда потребовалось запустить декодер под хилых, из моделсима прочитал полином и задал руками %) спасибо, так и делал изначально:  CODE always_comb
begin
// ALPHA_TO = generate_gf_alpha_to_power(irrpol);
// INDEX_OF = generate_gf_index_of_alpha(ALPHA_TO);
// GPOLY = generate_pol_coeficients (genstart, rootspace, check, generate_gf_index_of_alpha(generate_gf_alpha_to_power(irrpol)), generate_gf_alpha_to_power(irrpol));
//$display ("GPOLY=%p",GPOLY);
GPOLY = {1, 12'd1023, 12'd3523, 12'd1566, 12'd4068, 12'd3078, 12'd2862, 12'd2296, 12'd4030, 12'd3332, 12'd2733};
end Причем ALPHA_TO и INDEX_OF рассчитывается без проблем. С помощью атрибутов пытаюсь заставить работать и расчет GPOLY. была идея, указал даже явно ROM STYLE как logic , все равно синтезатор наделал ПЗУ-шек. Мне не жалко лишней логике, но в моем случае при m=12 синфлифай жрет всю доступную память ПК и вылетает с ошибкой. Есть еще вопрос, то ли пятница, то ли еще что, не могу разобраться, как Вы раскрыли скобки при вычислении GPOLY = (X+a)(X+a^2)(X+a^3) и т.д. в функции generate_pol_coeficients. Поясните, пожалуйста, на пальцах  P.S тогда как RTL в synplify загружен логикой и ПЗУ, technology view имеет константу. весьма любопытно . это как он аккуратно по коду идет , боится оптимизировать лишнее. P.S. нашел причинную функцию. synplify стесняется оптимизировать ПЗУ в функции gf_mul
|
|
|
|
|
|
|
|
Oct 19 2012, 15:26
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Костян @ Oct 19 2012, 06:55) Есть еще вопрос, то ли пятница, то ли еще что, не могу разобраться, как Вы раскрыли скобки при вычислении GPOLY = (X+a)(X+a^2)(X+a^3) и т.д. в функции generate_pol_coeficients. Поясните, пожалуйста, на пальцах там непосредственное перемножение полиномов. Шаг 1. берем x+a Шаг 2. умножаем на (x+a^2). получаем x^2 + x(a + a^2) + (a*a^2). Шаг 3. умножаем на (x+a^3). получаем x^3 + x^2(a + a^2 + a^3) + x(a*a^2 + a^3*(a+a^2)) + (a*a^2*a^3). и т.д. Т.е. gf_mul в этой функции это учет раскрытия скобок с умножением на следующий корень, а gf_add это накопление значения при коэффициенте. Цитата P.S. нашел причинную функцию. synplify стесняется оптимизировать ПЗУ в функции gf_mul можно переделать идеальный gf_mul на синтезируемый gf_mult_a_by_b, может тогда ему станет лучше. но мне было лень это делать %)
--------------------
|
|
|
|
|
|
|
|
Oct 30 2012, 06:21
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Koluchiy @ Jul 2 2012, 03:32) Денис, не появилось ли нового релиза с расчетом генераторного полинома БЧХ?  1. Реализована функция расчета генераторного полинома БЧХ. В качестве прототипа использовалась функция из матлаба. Сравнил с полиномами из таблицы один в один. В симуляторе все прекрасно работает. Но при синтезе ква 9.1 долго думает когда ищет циклотомические классы. Но тем не менее полином в ква 9.1 считается и ресурс энкодера после синтеза такой же что и при использовании таблиц. Из особенностей : т.к. кол-во классов и членов классов априори не известно, а ква не может использовать массивы больше чем 2^28 бит, настройка размерностей массивов в функции генерации полиномов задается в ручную через макросы (файл bch_define.v). Цитата(Костян @ Oct 19 2012, 04:30) проблема видимо в synplify 2. Заменил функции gf_add/gf_mul в генерации полинома РС на синтезируемые xor/gf_mult_a_by_b. Тест показал что все работает, ква тоже съел и не подавился. Сделал для проверки синтезируемости на сторонних синтезаторах (в частности Symplify)
--------------------
|
|
|
|
|
|
|
|
Nov 1 2012, 18:12
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Gold777 @ Oct 30 2012, 20:59) При декодировании кода Рида-Соломона (к примеру RS(255,239)) заметил такую особенность: когда ошибок в сигнале нет первый синдром практически всегда получается ненулевым, остальные S2..S16 равны нулю. Решатель ключевого уравнения показывает что кол-во ошибок равно нулю и собственно ничего не исправляется. Все таки непонятно почему первый синдром ненулевой?Ведь по теории такого быть не должно (если ошибок нет значит все синдромы должны быть равны нулю!!!). Интересно, что при внесении ошибок неправильного исправления не наблюдал. У БЧХ такой закономерности не встречал. Более подробно опишу ранее описанную проблему. При расчете синдромов первый синдром вычисляю подставляя alfa^1 т.е. S1(alfa^1 ), S2(alfa^2), S16(alfa^16) или надо первый синдром считать подставляя alfa^0 т.е. S1(alfa^0)...S16(alfa^15)? Если расчет по второму варианту делать, то если нет ошибок все синдромы равны нулю (Позиции ошибок считаются правильно, а величины). По первому варианту S16(alfa^16) получается ненулевым (при этом позиции ошибок и величины считаются верно). Вот не могу понять, где у меня ошибка и какой вариант при расчете правильный? И еще вопрос все ли 16 синдромов всегда используются при декодировании или можно не все их вычислять(по идее существует 2^128 различных вариантов комбинаций синдромов, а возможных комбинаций ошибок и величин будет меньше)?
Сообщение отредактировал Gold777 - Nov 1 2012, 19:01
|
|
|
|
|
|
|
|
Nov 2 2012, 08:43
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Gold777 @ Nov 1 2012, 12:12) Вот не могу понять, где у меня ошибка и какой вариант при расчете правильный? Все зависит от того, как именно у вас рассчитан генераторный полином. Если вы брали корни полинома как a^[0:check] то и синдромы нужно считать для корней со степенями [0:check], если a^[1:check+1] то соответственно будет сдвиг. Цитата И еще вопрос все ли 16 синдромов всегда используются при декодировании или можно не все их вычислять(по идее существует 2^128 различных вариантов комбинаций синдромов, а возможных комбинаций ошибок и величин будет меньше)? ИМХО нужно вычислять все, могу ошибаться. Думаю что гуру поправят %)
--------------------
|
|
|
|
|
|
|
|
Nov 2 2012, 09:31
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Nov 2 2012, 12:43) ИМХО нужно вычислять все, могу ошибаться. Думаю что гуру поправят %) Если у вас 2^128 разных синдромов, то ровно столько различных ошибок может исправлять код. Там могут быть и ошибки веса много больше Dмин/2. Исправить все можно, например, полным перебором кодовых слов (если много свободного времени ) Чем больше Dмин, тем дальше код от плотной упаковки и тем больше тяжелых ошибок (больше Dмин/2) он в принципе может исправлять. Вообще, не обязательно исправлять совсем все ошибки для хорошего декодера. Есть , например, такой результат: достаточно исправлять все ошибки, которые может исправить код, до веса Dвг,тогда вероятность ошибки декодирования не более чем вдвое превосходит вероятность ошибки при декодировании полным перебором. Здесь Dвг означает мин. расст. для данного кода, которое получается из границы Варшамова-Гильберта для данных кодовых параметров. Другое дело, что ваш конкретный алгоритм исправляет только часть этих ошибок. Наример, он не исправляет ошибки веса больще Dмин/2. Но если вы не будете в алгоритме испрользовать часть синдрома, то часть исправимых алгоритмом ошибок еще больше уменьшится, т.е. вы не сможете исправлять даже некоторые ошибки веса меньше Dмин/2.
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|




























 оптимальные решения они всегда в одной области находяться.
оптимальные решения они всегда в одной области находяться.