| |
|
  |
 Bus Master DMA для PCIe Bus Master DMA для PCIe |
|
|
|
|
 Oct 8 2015, 19:17 Oct 8 2015, 19:17
|
Профессионал

Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539

|
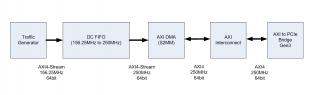
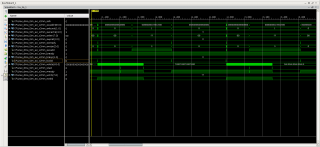
Приветствую. Собрал систему (см. рисунок) для передачи данных по PCIe. Ядро AXI Bridge for PCIe сконфигурировано в режиме x4, 64 bit, 250MHz, должно позволить прокачивать поток 16 Гбит/с. В качестве DMA используется ядро AXI DMA v7.1 в режиме Scatter-Gather. Кольцо дескрипторов и буферы данных выделяются в памяти ядра Linux. Ранее было сделано так, пропускная способность канала составляла ~6 Гбит/с. Тут опять упёрся в 6 Гбит/с, думал, что софт ограничивает производительность канала. Потом убрал вмешательство системы в работу DMA - инициализирую кольцо дескрипторов, запускаю DMA. DMA бросает данные пока не закончатся дескрипторы. Оценивая время обработки кольца дескрипторов и переданный объём данных, получаю чуть больше 6 Гбит/с. Вытянул сигналы AXI4-Stream между FIFO и DMA на ILA, вижу - FIFO держит TVALID всегда в 1, а DMA периодически (очень часто) сбрасывает TREADY в 0. Получается DMA является виновником ограничения скорости потока. В доке вычитал, что в тестах получали пропускную способность до ~70%, но это ~11,2 Гбит/с, меня бы устроило. Вопрос - как поднять производительность DMA? Как понимаю, AXI Interconnect и PCIe мост могут тормозить DMA?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 8 2015, 19:44
|
Местный
Группа: Свой
Сообщений: 372
Регистрация: 14-02-06
Пользователь №: 14 339
|
Цитата(doom13 @ Oct 8 2015, 22:17)  Кольцо дескрипторов ... выделяется в памяти ядра Linux. Может в этом причина ? Посмотрите анализатором очередность транзакций на шине axi.
|
|
|
|
|
|
|
|
Oct 9 2015, 13:23
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
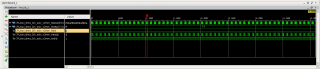
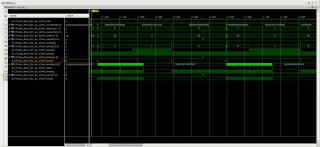
На AXI4 между DMA и AXI Interconnect вот такая штука (тут даже не пойму на какой из сигналов настроить триггер): PS: Триггер настроен на TLAST для AXI4-Stream (FIFO->DMA). PSPS: Тут, как понимаю, Slave (AXI Interconnect) выставил WREADY, а Master (DMA) ещё очень долго тупит. Получается, что все проблемы из-за DMA? Или надо ещё смотреть и на BVALID?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 10 2015, 10:34
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
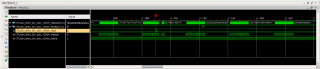
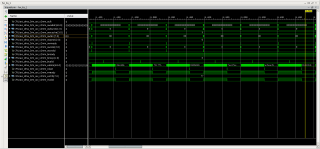
Засинхронизировал триггер по начальному адресу буфера (0х0000_0004_0720_0000) на который ссылается первый дескриптор в кольце. На рисунке сечение DMA-AXI Interconnect, для AXI Interconnect-PCIe Bridge диаграмма такая же. Нужна помощь в анализе, что тут работает неправильно (медленно) и получится ли ускорить? Если всё правильно понимаю, то WVALID ждёт подтверждения записи BVALID для второго burst-a и только потом устанавливается в 1. Как-то можно повлиять на более быстрое появления BVALID и, как следствие, на WVALID?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 10 2015, 14:13
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
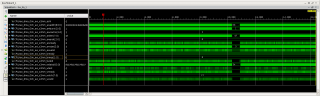
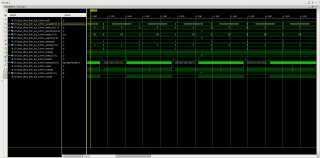
Увеличил burst size для DMA до максимального 256, а вместе с этим увеличилось время от WLAST до BVALID. Что за ерунда? Где тут увеличение производительности? Время от WLAST до BVALID должно было остаться таким же, как и при значении burst 16??? Если нет, за счёт чего тут можно было получить увеличение производительности DMA??? Спасибо.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 10 2015, 21:23
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(toshas @ Oct 10 2015, 23:34) Мне кажется pcie-mm всегда позиционировалось как удобное решение для микропроцессорной системы, не более того, при этом максимальной скорости он него никто и не требовал. А я думал это ядро и есть самое то, что Xilinx предлагает для работы с PCIe, а оно вот как оказывается  Цитата(toshas @ Oct 10 2015, 23:34) Однако для получения максимальных скоростей очень вероятно придется самому с нуля писать dma для голого ядра pcie.
Или посмотреть на работу dsmv. Вот с нуля делать и не хотелось. Разбираться с DS_DMA показалось очень сложным, решил на готовых ядрах собрать систему, счас надо думать, куда двигать дальше. Цитата(toshas @ Oct 10 2015, 23:34) Или дождаться что же xilinx предложит как альтернативу (xdma). Стоимость может оказаться невысокой или вообще бесплатной. Почти дождался - вчера слил, установил, посмотрел. Остался вопрос с мануалом на это чудо-ядро XDMA. Мне его давать не хотят, так что если кто помог бы с описанием ядра, был бы очень благодарен. Цитата(toshas @ Oct 10 2015, 23:34) В чем точно происходит затык в вашем случае было бы интересно выяснить. А может ли как-то система (драйвер) влиять на такую длительность появления BVALID? В ядре есть много способов выделения памяти, может я использую неправильный (пользуюсь kmalloc)? Мне пока нужно выжать с системы 10 Гбит/с. Можно наверное настроить мост на работу с PCIe Gen 3, пропускная способность должна будет возрасти. Тут только придётся подбирать более навороченную систему для работы с платой, мой рабочий ПК подойдёт, а вот тот, что будем использовать в проекте???
|
|
|
|
|
|
|
|
Oct 11 2015, 20:19
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
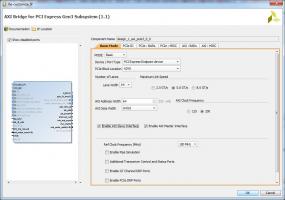
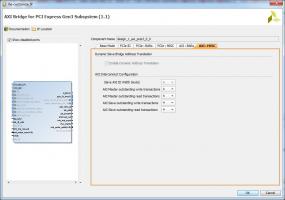
Цитата(RobFPGA @ Oct 11 2015, 15:20) Для начала неплохо бы убедится что PCIe действительно работает в x4 Gen2, каков размер payload. Настройки для моста стоят именно такие (см. рисунок). По поводу payload не понял, что это, такой опции там нет. Есть ещё вкладка (второй рисунок) с опциями для моста (можно выбирать 2/4/8), но с ней не разбирался, надо глянуть, за что оно отвечает. Цитата(RobFPGA @ Oct 11 2015, 15:20) А правильнее было бы на модели в симуляторе посмотреть что и как работает, какова скорость передачи и что и как тормозит передачу. И уж если на модели скорость будет ОК то только тогда разбирается на рабочей системе сравнивая с моделью что не так. Не совсем представляю, как это всё проверять в симуляторе. Завтра думаю проверить как быстро DMA будет бросать данные в память FPGA, но тут наверное всё будет работать быстрее.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 12 2015, 10:41
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(toshas @ Oct 12 2015, 12:43) Под линуксом выполните "lspci -vv" и посмотрите с какими параметрами ядро сконфигурировано, а с какими система разрешила работать. Слот в котором стоит плата поддерживает Gen 3, ядро настроено на Gen 2, почему Gen 2 должен не установиться? Нашёл, надо было вводить команду с правами суперпользователя, получил следующее: Цитата 07:00.0 Multimedia controller: Xilinx Corporation Device 7024
Subsystem: Xilinx Corporation Device 0007
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR+ FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 32 bytes
Interrupt: pin A routed to IRQ 31
Region 0: Memory at f7100000 (64-bit, non-prefetchable) [size=128K]
Capabilities: [80] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [90] MSI: Enable+ Count=1/1 Maskable- 64bit+
Address: 00000000feeff00c Data: 4182
Capabilities: [c0] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us
ExtTag- AttnBtn- AttnInd- PwrInd- RBE+ FLReset-
DevCtl: Report errors: Correctable- Non-Fatal- Fatal- Unsupported-
RlxdOrd- ExtTag- PhantFunc- AuxPwr- NoSnoop+
MaxPayload 128 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- UncorrErr- FatalErr- UnsuppReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 5GT/s, Width x4, ASPM not supported, Exit Latency L0s unlimited, L1 unlimited
ClockPM- Surprise- LLActRep- BwNot-
LnkCtl: ASPM Disabled; RCB 64 bytes Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 2.5GT/s, Width x4, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range B, TimeoutDis+, LTR-, OBFF Not Supported
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis-, LTR-, OBFF Disabled
LnkCtl2: Target Link Speed: 5GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance De-emphasis: -6dB
LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete-, EqualizationPhase1-
EqualizationPhase2-, EqualizationPhase3-, LinkEqualizationRequest-
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+
AERCap: First Error Pointer: 00, GenCap- CGenEn- ChkCap- ChkEn-
Kernel driver in use: htg_v7_g3 Получается что работает как Gen 1? PS: Как его загнать в 5 GT/s?
|
|
|
|
|
|
|
|
Oct 12 2015, 12:01
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(toshas @ Oct 12 2015, 14:06) Попробуйте воткнуть плату в слот ближайший к процессору. Спасибо, сейчас попробую. Цитата(gosu-art @ Oct 12 2015, 14:09) 2. попробовать воткнуть непосредственно в слот видюхи Это и будет ближайший слот к процессору. Цитата(gosu-art @ Oct 12 2015, 14:09) 1. посмотреть в биосе материнки настройки PCIe
У меня,например, на линк х4 слота определяется слотом видеокарты. Т.е. на каком линке заработала видюха на таком все остальное будет работать Видюха Quadro 600 работает почему-то на 2.5 GT/s x16, может с этим как-то связано? Ещё вопрос: при старте системы прошивки в FPGA нету, заливаю прошивку в RAM, перезагружаю систему, может проблема быть в этом? Может необходимо, чтоб FPGA запускалась с флэша при старте системы за определённое (небольшое) время?
|
|
|
|
|
|
|
|
Oct 12 2015, 12:58
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(KPiter @ Oct 12 2015, 15:33) Нет ли в биосе Initialization at Gen1\Gen2\Gen3? Что-то похожее есть только для слота видеокарты, но стоит настройка авто, попытка изменить не дала результата (видеокарта продолжила работу в Gen 1). Цитата(KPiter @ Oct 12 2015, 15:33) свежий ли биос? Тот, что был с компом при покупке. Наверное старый.
|
|
|
|
|
|
|
|
Oct 12 2015, 13:40
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(toshas @ Oct 12 2015, 14:06) Попробуйте воткнуть плату в слот ближайший к процессору. Цитата(gosu-art @ Oct 12 2015, 14:09) 2. попробовать воткнуть непосредственно в слот видюхи Цитата(KPiter @ Oct 12 2015, 16:19) Не понял был ли испробован вариант: поставить Xilinx в слот видюхи. смысл оставить только xilinx на pcie шине Поменял местами видеокарту и плату с FPGA. Теперь система вообще не видит плату (нет в списке PCI устройств). Ранее с настройкой AXI to PCIe моста для Gen 1 работало при таком расположении устройств.
|
|
|
|
|
|
|
|
Oct 12 2015, 14:08
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(toshas @ Oct 12 2015, 16:57) Есть ли в биосе настройка pcie spread spectrum clock (ssc)? Попробуйте ее изменить. Проверю. Цитата(toshas @ Oct 12 2015, 16:57) Что у вас за платформа ? Проц: i7-3770K Материнка: GA-Z77P-D3 Видео: Quadro 600 Ещё стоит сетевая карта в слоте PCIe x1
|
|
|
|
|
|
|
|
Oct 12 2015, 14:33
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(doom13 @ Oct 12 2015, 13:41) Слот в котором стоит плата поддерживает Gen 3, ядро настроено на Gen 2, почему Gen 2 должен не установиться?
....
Получается что работает как Gen 1?
PS: Как его загнать в 5 GT/s? Хи-xи - так бы еще долго "разгоняли" DMA  А плата у Вас покупная или самопальная ? Удачи! Rob.
|
|
|
|
|
|
|
|
Oct 12 2015, 15:36
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Oct 12 2015, 17:33) Хи-xи - так бы еще долго "разгоняли" DMA Мне тоже смешно стало, а главное - осталось настроить/поменять комп и система ОБЯЗАНА заработать, а то думал скоро линчевать начнут Цитата(gosu-art @ Oct 12 2015, 17:15) Может пока отложить видеокарту и подключится к встроенной графике? UPD: Сетевуху тоже можно пока выкинуть  скорее всего она тоже на х1. Если это все подключено к свичу то он может поставить линки на х1 (ориентируясь на самое медленное устройство). Я уже на cPCI serial с этой фигней сталкивался)) Встроенной нету, есть выход HDMI, но я под него моник не найду. Сейчас выкину и сетевуху. Самое интересное - у двух товарищей такая же система, видюха работает на 5 GT/s. Уже сравнили версию биоса - один в один. Цитата(RobFPGA @ Oct 12 2015, 17:33) А плата у Вас покупная или самопальная ? Покупная, вот такая (X690T)
|
|
|
|
|
|
|
|
Oct 16 2015, 14:33
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(doom13 @ Oct 16 2015, 14:33) Если можно расскажите тут подробнее, что это (pipe) и как работает? Что можно почитать по данной теме?
xapp1184 достаточно будет? Нее - в PIPE лезть не нужно - это интерфейс к MGT - toshas наверное имел ввиду шины s_axis_rq_* s_axis_rc_* на самой pcie корке которая внутри bridge Через эти шины TLP идут request/completion от bridge логики к pcie корке. Цепляете туда ChipScope - а еще лучше логер который будет Вам скидывать TLP header-ы и смотрите что куда тормозит. Конечно это сначало проще было бы на симе сделать. Тут либо сам bridge не заточен на макс thruput, ну или DMA например не успевает подкачивать дескрипторы. Можно попробовать разместить дескрипторы в памяти FPGA или выделить один большой непрерывный кусок физ памяти (>1MB) и все дескрипторы залинковать на него. И посмотреть изменится ли скорость или нет. Если не изменится - то тогда или пробовать на дугой мамке, или скорее всего bridge не заточен на макс thruput, ну или универсальная причина №3 - ХЗ . Успехов! Rob.
|
|
|
|
|
|
|
|
Oct 16 2015, 17:55
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(toshas @ Oct 16 2015, 20:14) Нет я как раз предлагал посмотреть трафик в системе (какие пакеты проходят mgt).
Но в принципе не важно с какой стороны начинать разбираться.
По факту надо отследить всю цепочку:
MGT -1.(txdata/rxdata)- PCIE -2.(ll/s_axi) - MMcore -3.(axi)- DMA -4.(axi)- source
Так можно найти, кто причина простоя, но может оказаться, что это просто следствие накладных расходов цепочки такой длины. Ой - разбирается на уровне PIPE это труба дело . DLP layer, K-коды, AK-и NAK-и постоянно туда сюда снуют. ужас!  Проще сначала на TLP layer посмотреть. Так как операция WRITE на PCIE не требует completion то тут или в bridge для PCIe настройки буферов зажаты или потери времени на чтение/update дескрипторов велики. Все же CDMA разрабатывался для внутреннего употребления а не для PCIe. Я вот свою железку симулирую - так latency на чтение дескриптора из памяти ~500 нс (x8 gen2) и это при PIPE симуляции и без задержек на стороне модели RC. Успехов! Rob.
|
|
|
|
|
|
|
|
Oct 16 2015, 19:45
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Oct 16 2015, 17:33) ... ну или DMA например не успевает подкачивать дескрипторы.
Можно попробовать разместить дескрипторы в памяти FPGA или выделить один большой непрерывный кусок физ памяти (>1MB) и все дескрипторы залинковать на него. И посмотреть изменится ли скорость или нет.
Если не изменится - то тогда или пробовать на дугой мамке ... Цитата(RobFPGA @ Oct 16 2015, 20:55) ... или потери времени на чтение/update дескрипторов велики. Все же CDMA разрабатывался для внутреннего употребления а не для PCIe. Судя по диаграммам, которые приводил выше (затык после каждого второго burst-a и длительность пропорциональна размеру burst-a), проблема не в размещении дескрипторов в Kernel space memory. Пока использую 32 дескриптора, память под них выделяется в непрерывном куске физической памяти с помощью kmalloc. Цитата(toshas @ Oct 16 2015, 20:14) Нет я как раз предлагал посмотреть трафик в системе (какие пакеты проходят mgt).
Но в принципе не важно с какой стороны начинать разбираться.
По факту надо отследить всю цепочку:
MGT -1.(txdata/rxdata)- PCIE -2.(ll/s_axi) - MMcore -3.(axi)- DMA -4.(axi)- source
Так можно найти, кто причина простоя, но может оказаться, что это просто следствие накладных расходов цепочки такой длины. Сегодня пытался проследить, кто является источником BVALID, но один из модулей зашифрован и связь теряется. Дальше куча линий с другими названиями и куда смотреть пока не разобрался.
|
|
|
|
|
|
|
|
Oct 18 2015, 20:21
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Как говорится "Даренному коню в зубы .." а надо заглядывать даже в зад Прогнали бы на симуляции все сразу стало бы понятно. По умолчанию CDMA настроен на глубину очереди запросов адреса=4 (при этом реально выдается 4+2=6 запросов) ну а а потом CDMA шлангует пока не получит ответ/подтверждение. Поменять это безобразие в красивой формочке при конфигурировании CDMA нельзя Только через зад коня - ручками Код set_property CONFIG.C_WRITE_ADDR_PIPE_DEPTH 8 [get_bd_cells i_axi_cdma]
set_property CONFIG.C_READ_ADDR_PIPE_DEPTH 8 [get_bd_cells i_axi_cdma] Но один конь карету не помчит - также надо во всех crossbar-ах по пути следования кареты выставить постовых - значение READ_ACCEPTANCE, WRITE_ACCEPTANCE на >=8 (а то по умолчанию там стоит 2 - даже не лошадь - дохлая кляча получается ). Ну и бубенцы на хомут - значения больше 8 ставить смысла нет так как bridge больше 8 запросов в очередь не принимает, а вроде бы соответствующие параметры c_s_axi_num_read/c_s_axi_num_write расположенны слишком глубоко в зад.. read_only Успехов! Rob. P.S. Ни одно животное не пострадало. Все эксперименты проводились на виртуальной лошади с "заездами" на идеальной трассе (PIPE sim. , BFM RC без задержек); 
|
|
|
|
|
|
|
|
Oct 19 2015, 06:42
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
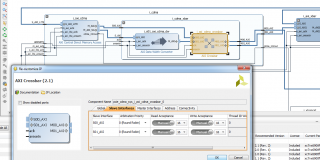
Цитата(RobFPGA @ Oct 18 2015, 23:21) А что если у меня используется DMA v7.1 в режиме S2MM (CDMA был в начале)? Цитата(RobFPGA @ Oct 18 2015, 23:21) ... также надо во всех crossbar-ах по пути следования кареты выставить постовых - значение READ_ACCEPTANCE, WRITE_ACCEPTANCE на >=8 (а то по умолчанию там стоит 2 ... Если на рисунке тот параметр, о котором шла речь, то там 8.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 19 2015, 07:45
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(doom13 @ Oct 19 2015, 09:42) А что если у меня используется DMA v7.1 в режиме S2MM (CDMA был в начале)? Думаю что тоже самое - так как CDMA это AXI DMA сконфигурированный в позе 69 через loop-back fifo. И так и есть - правда тут придется резать бедную лошадь и ковыряется в потрохах - исходниках Код axi_dma.vhd
...
-- DataMover outstanding address request fifo depth
constant DM_ADDR_PIPE_DEPTH : integer := 4;
... Цитата(doom13 @ Oct 19 2015, 09:42) Если на рисунке тот параметр, о котором шла речь, то там 8. Нет это как раз и есть "бубенцы" а я имел ввиду - axi_interconect/axi_crosbar которые стоят МЕЖДУ DMA и PCIe. Вы же как то объединяете шины DMA M_AXI и M_AXI_SG для подключения к одой шине S_AXI в PCIe bidge? Успехов! Rob.
|
|
|
|
|
|
|
|
Oct 19 2015, 08:53
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Oct 19 2015, 10:45) Код axi_dma.vhd
...
-- DataMover outstanding address request fifo depth
constant DM_ADDR_PIPE_DEPTH : integer := 4;
... Такой параметр нахожу, он у меня почему-то 1, попробую задать 8. Цитата(RobFPGA @ Oct 18 2015, 23:21) ... вроде бы соответствующие параметры c_s_axi_num_read/c_s_axi_num_write расположенны слишком глубоко ... Такие параметры поиском могу найти только в папках с файлами для PCIe моста (xml - файл задаёт параметры для gui ядра) и они там 8.
|
|
|
|
|
|
|
|
Oct 19 2015, 09:01
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(doom13 @ Oct 19 2015, 11:53) Такой параметр нахожу, он у меня почему-то 1, попробую задать 8.
Такие параметры поиском могу найти только в папках с файлами для PCIe моста (xml - файл задаёт параметры для gui ядра) и они там 8. Не трогайте пока PCIe bridge - настройте DMA и axi_interconect-ы Успехов! Rob.
|
|
|
|
|
|
|
|
Oct 19 2015, 10:10
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Для AXI Interconnect эти параметры надо править: Код parameter [C_NUM_SLAVE_SLOTS*32-1:0] C_S_AXI_WRITE_ACCEPTANCE = 32'H00000002,
// Maximum number of active write transactions that each SI
// slot can accept. (Valid only for SAMD)
// Format: C_NUM_SLAVE_SLOTS{Bit32};
// Range: 1-32.
parameter [C_NUM_SLAVE_SLOTS*32-1:0] C_S_AXI_READ_ACCEPTANCE = 32'H00000002,
// Maximum number of active read transactions that each SI
// slot can accept. (Valid only for SAMD)
// Format: C_NUM_SLAVE_SLOTS{Bit32};
// Range: 1-32. ???
|
|
|
|
|
|
|
|
Oct 19 2015, 11:07
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Увы это издержки "удобств" когда за Вас работает неизвестный индийский Раджа. В форме кофигурирования interconecta таких параметров нет - но можно раскрыть блок interconecta ПОСЛЕ diagram validation найти там axi_crossbar и в нем уже - поставив ручной режим - изменить нужные параметры. Ну или сразу нарисовать правильный xbar из примитивов axi_crossbar, axi_dwidth_converter, axi_clock_converter, ... не надеясь на телепатические способности Раджи. Успехов! Rob.
|
|
|
|
|
|
|
|
Oct 19 2015, 13:42
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
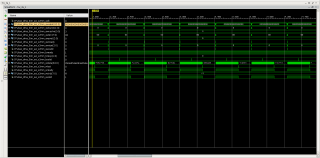
Сделал всё, как Вы советовали. Должно было увеличить скорость передачи, но почему-то осталось по-прежнему. Рисунок первый, то как работало ранее, использую burst 256. По рисунку видно, что период двух burst-ов примерно 1400 тактов. Рисунок второй, то как работает сейчас (с параметром constant DM_ADDR_PIPE_DEPTH : integer := 8; и crossbar-om c Read/Write Acceptance 8) Тут два burst-a передаются за 800 тактов. На осцил вывожу сигнал прерывания по обработке дескриптора, его период в обоих случаях одинаковый??? По данным ILA производительность возрасла, на деле осталась прежней, как так???
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Oct 20 2015, 12:37
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Oct 20 2015, 12:34) По картинкам видно что тормозит именно DMА такое впечатление что на входе у него не хватает данных.
Задержек со стороны PCIe тут не видно. Да, спасибо, вот я ... . Можете смеяться, генератор трафика работает на 156.25 MHz (моделирует приём 10G Ethernet, далее фифо с переходом на 250 MHz, DMA забирает данные из FIFO), для него 9.3 Gbit/s почти потолок. Когда была проблема с работой ядра в Gen1 я его проверял, чтоб там ничего не тормозило, а тут что-то позабыл.
|
|
|
|
|
|
|
|
Oct 20 2015, 14:40
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Oct 20 2015, 15:42) Запустил генератор трафика на 250 MHz, с Вашими советами показало 13.56 Gbit/s. Спасибо, помогли. Если оставить AXI Interconnect в режиме auto и параметр DM_ADDR_PIPE_DEPTH для DMA со стандартным значением 1, получаю примерно тех же 9.3 Gbit/s. Руками набросать свой interconnect - это ещё нормально, но вот вручную править файлы, которые нагенерил IP Integrator, чтоб оно заработало нормально, - "ваще опа".
|
|
|
|
|
|
|
|
Oct 29 2015, 08:03
|
Участник
Группа: Участник
Сообщений: 64
Регистрация: 10-01-06
Пользователь №: 13 025
|
Цитата(RobFPGA @ Oct 19 2015, 14:07) Приветствую! Увы это издержки "удобств" когда за Вас работает неизвестный индийский Раджа. В форме кофигурирования interconecta таких параметров нет - но можно раскрыть блок interconecta ПОСЛЕ diagram validation найти там axi_crossbar и в нем уже - поставив ручной режим - изменить нужные параметры. Ну или сразу нарисовать правильный xbar из примитивов axi_crossbar, axi_dwidth_converter, axi_clock_converter, ... не надеясь на телепатические способности Раджи. Успехов! Rob.
Почему у меня отсутствует кнопка ОК? Могу отредактировать но не могу применить? И куда Вы добавляете set_property? В xdc или в свойства корки. В свойства корки есть только удалить, а добавить нет. Версия 2015.1 и 2015.3.
|
|
|
|
|
|
|
|
Oct 29 2015, 08:03
|
Участник
Группа: Участник
Сообщений: 64
Регистрация: 10-01-06
Пользователь №: 13 025
|
Цитата(RobFPGA @ Oct 19 2015, 14:07) Приветствую! Увы это издержки "удобств" когда за Вас работает неизвестный индийский Раджа. В форме кофигурирования interconecta таких параметров нет - но можно раскрыть блок interconecta ПОСЛЕ diagram validation найти там axi_crossbar и в нем уже - поставив ручной режим - изменить нужные параметры. Ну или сразу нарисовать правильный xbar из примитивов axi_crossbar, axi_dwidth_converter, axi_clock_converter, ... не надеясь на телепатические способности Раджи. Успехов! Rob.
Почему у меня отсутствует кнопка ОК? Могу отредактировать но не могу применить? И куда Вы добавляете set_property? В xdc или в свойства корки. В свойства корки есть только удалить, а добавить нет. Версия 2015.1 и 2015.3.
|
|
|
|
|
|
|
|
Nov 30 2015, 12:03
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
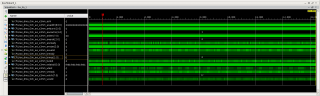
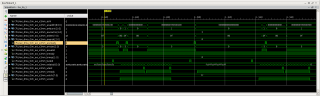
Приветствую. Новый вопрос по DMA. Сейчас делаю передачу данных ПК -> FPGA (параметры для DMA и AXI Interconnect-a, как советовали выше). На базе генератора трафика сделал loopback для DMA (MM2S -> S2MM). Получаю скорость передачи примерно в два раза меньше (около 7.5 Гбит/с) чем мог выдать DMA в режиме S2MM. Для возможности подключения разных источников трафика на интерфейс DMA S_AXIS_S2MM сделал мультиплексор AXI-Stream (могу включать loopback для DMA или передавать данные от генератора трафика). Получаю низкую скорости передачи при использовании режима loopback для DMA - MM2S канал тормозит передачу. Вопрос, как это устранить? Рисунок 1 - режим loopback для DMA, данные передаются ПК -> FPGA -> ПК. Рисунок 2 - данные передаются только в направлении ПК.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Dec 1 2015, 11:06
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
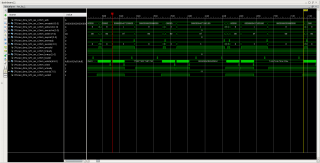
Цитата(RobFPGA @ Oct 16 2015, 20:55) Так как операция WRITE на PCIE не требует completion... Можно ли объяснить снижение скорости при чтении тем, что READ на PCIe требует completion? Если да, то во сколько раз они могут отличаться? Получаю скорость записи (FPGA -> PC) примерно в 1.8 раза больше чем скорость чтения (PC -> FPGA). Ниже рисунки: 1 - DMA перебрасывает данные из ПК в FPGA (+ они же обратно FPGA -> PC, интерфейс DMA S2MM не показан); 2 - DMA перебрасывает данные из FPGA в ПК (однонаправленная передача FPGA -> PC).
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Dec 1 2015, 14:16
|
Профессионал
Группа: Свой
Сообщений: 1 404
Регистрация: 11-03-11
Из: Минск, Беларусь
Пользователь №: 63 539
|
Цитата(RobFPGA @ Dec 1 2015, 16:45) Дело не в том что для READ требуются completion а в глубине очереди на запросы чтения.
Если глубина маленькая то возникают паузы на ожидания окончания предыдущих запросов перед посылкой следующего запроса.
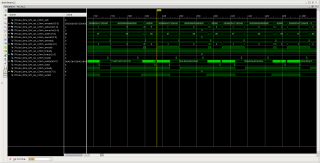
Надо иметь еще ввиду что AXI интерконнект может "блокировать" запросы на чтение/запись если они идут в одно периферийное устройство - тое-есть исполнятся они будут в порядке прихода а не полностью параллельно. Спасибо, счас это всё обдумаю, пока хочу ещё спросить: для рисунка 1 (сообщение #63) , где идёт передача PC -> FPGA данные передаются ещё и в обратном направленни FPGA -> PC (на диаграмму их не добавил). Т.е. получается на S_AXIS_RQ_* в данном случае поступает больше транзакций (от MM2S и от S2MM, на чтение и на запись) чем когда однонаправленная передача данных от генератора трафика (рисунок 2, сообщение #63). Стоит ли искать проблему в этом? Цитата(RobFPGA @ Dec 1 2015, 16:45) Надо иметь еще ввиду что AXI интерконнект может "блокировать" запросы на чтение/запись если они идут в одно периферийное устройство - тое-есть исполнятся они будут в порядке прихода а не полностью параллельно. Об этом не подумал, цепочка DMA -> Interconnect -> AXI_PCIe на рисунке, т.е. если включаю loopback (см рисунок), то ещё и DMA M_AXI_MM2S и M_AXI_S2MM (+ M_AXI_SG) будут делить время доступа к PCIe??! Похоже, надо сделать заглушку для M_AXIS_MM2S, чтобы отдельно проверить скорость для DMA M_AXI_MM2S?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|