| |
 Я просто не верю что IAR STM8 такой тупой! Я просто не верю что IAR STM8 такой тупой!, Ведь это же всегда был один из самых качественных компиляторов |
|
|
|
|
 May 9 2017, 20:00 May 9 2017, 20:00
|

I WANT TO BELIEVE

Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751

|
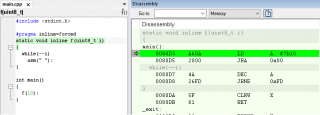
Код #pragma inline=forced
static void inline f(uint8_t i)
{
while(--i)
asm("");
}
int main()
{
f(10);
} В результате: Код 183 int main()
184 {
\ main:
\ 000000 52 01 SUB SP, #0x1
186 f(10);
\ 000002 35 0A .... MOV S:?b0, #0xa
\ 000006 20 00 JRA L:??main_0
\ ??main_1:
\ ??main_0:
\ 000008 B6 .. LD A, S:?b0
\ 00000A 4A DEC A
\ 00000B B7 .. LD S:?b0, A
\ 00000D 26 F9 JRNE L:??main_1 ЗАЧЕМ? Зачем он делает всё это???? Настройки компилятора по полной программе: Multi-file compilation, High, Speed +No size constraints P.S. Cosmic же на много толковее справился, хотя я конечно по прежнему не понимаю почему нельзя просто с регистром A работать.... Зачем в стек то? Код 60 .text: section .text,new
61 0000 _main:
63 0000 88 push a
64 00000001 OFST: set 1
67 ; 10 f(12);
70 0001 a60c ld a,#12
71 0003 6b01 ld (OFST+0,sp),a
74 0005 L72:
75 ; 5 _asm("");
79 ; 4 while(--i)
81 0005 0a01 dec (OFST+0,sp)
83 0007 26fc jrne L72
///////////////////////////////////////////////
84 0009 L73:
86 0009 20fe jra L73
99 xdef _main
118 end
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 10 2017, 06:51
|

фанат дивана
Группа: Свой
Сообщений: 3 387
Регистрация: 9-08-07
Из: Уфа
Пользователь №: 29 684
|
Посмотрите, что из вашего кода делает sdcc, и успокойтесь  Вот: (я только заменил asm("") на asm("nop"), для однозначности). Код ld a, #0x0a
00101$:
dec a
tnz a
jrne 00116$
ret
00116$:
nop
jra 00101$
ret Вот, если интересно, сравнение компиляторов для stm8. По нему видно, что IAR далеко не лидер в области размера кода. Зато он побеждает в тестах скорости.
--------------------
Если бы я знал, что такое электричество...
|
|
|
|
|
|
|
|
May 10 2017, 10:01
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Грустно, потому что я в другом окне смотрю, что из этого кода делает avr-gcc( вариант с asm("nop") ) Код 00000048 LDI R24,0x09 Load immediate
00000049 NOP No operation
0000004A SUBI R24,0x01 Subtract immediate
0000004B BRNE PC-0x02 Branch if not equal Алсо не очень понятно, как IAR может быть при всех этих лишних телодвижениях быстрее........ Очень жаль, что разработчики компиляторов считают СТМ8 не важной архитектурой  У меня еще есть пример как IAR весело тупит на куске С++ кода, где на этапе компиляции рекурсивно обходится список типов и вызывается функция. Так вот там аналогичным образом IAR просто делает одно и то-же: кладет в стек, грузит в А, кладет в стек, грузит в А.... В то время как GCC просто взял и прошелся одним значением по всем вызовам(ибо они реально не меняются и это известно во время компиляции). В общем печаль полнейшая с этим IAR.... Обидно, что кроме него плюсы никто не поддерживает больше. Sdcc снапшот от 9 мая sdcc -mstm8 --std-c99 --opt-code-size main.c вариант с asm(nop) функциa объявлена как static inline dly(char i); Код 000000 81 _dly:
82; main.c: 3: while(--i)
000000 7B 03 [ 1] 83 ld a, (0x03, sp)
000002 84 00101$:
000002 4A [ 1] 85 dec a
000003 4D [ 1] 86 tnz a
000004 26 01 [ 1] 87 jrne 00115$
000006 81 [ 4] 88 ret
000007 89 00115$:
90; main.c: 4: __asm__("nop");
000007 9D [ 1] 91 nop
000008 20 F8 [ 2] 92 jra 00101$
00000A 81 [ 4] 93 ret
94; main.c: 7: void main(void)
95; -----------------------------------------
96; function main
97; -----------------------------------------
00000B 98 _main:
99; main.c: 3: while(--i)
00000B A6 0A [ 1] 100 ld a, #0x0a
00000D 101 00101$:
00000D 4A [ 1] 102 dec a
00000E 4D [ 1] 103 tnz a
00000F 26 01 [ 1] 104 jrne 00116$
000011 81 [ 4] 105 ret
000012 106 00116$:
107; main.c: 4: __asm__("nop");
000012 9D [ 1] 108 nop
000013 20 F8 [ 2] 109 jra 00101$
110; main.c: 9: dly(10);
000015 81 [ 4] 111 ret ЗАИНЛАЙНИЛ БЛИН..... IAR при инлайне хоть тело функции догадывается убрать....
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 10 2017, 18:21
|
фанат дивана
Группа: Свой
Сообщений: 3 387
Регистрация: 9-08-07
Из: Уфа
Пользователь №: 29 684
|
А как, по-вашему, должен выглядеть предложенный вами кусок? Покажите, интересно. Я вот сделал пару проектов с использованием sdcc, всё поместилось, всё успелось. Посмотрел в дизассемблер, улыбнулся. Всё выглядит как gcc -O0. Неиспользуемые функции не выкидываются. Ну и ладно. Многие и с gcc так работают, и не жужжат Кстати, сейчас вроде бы появился вариант LLVM+SDCC. Теоретически, там всё может быть получше. C++ опять же... Попробуете?
--------------------
Если бы я знал, что такое электричество...
|
|
|
|
|
|
|
|
May 10 2017, 20:01
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(sigmaN @ May 10 2017, 15:13)  Просто обидно что хорошие по переферии и цене процы стм8 так и не имеют сравнимого с авр-гцц компилятора Ну и что? Кому он реально нужен на этом ядре? Реально, а не для того чтоб "проверить". Чтобы решать какую-то вычислительную задачу, требующую серьёзных вычислений на этом ядре??? Для этого следует выбирать другое ядро. Ниша STM8 - помахать ножками немножко, поуправлять не спеша простой периферией. В случае чего в редких случаях можно и асм использовать. Да и рынок пользователей STM8 очень ограничен, это далеко не экосистема ARM - вот там реально нужны хорошие оптимизаторы, и туда и следует прикладывать максимум усилий, и сообщество пользователей там несравнимо больше. И работы по оптимизатору там ещё - море. Нефиг ресурсы разработчиков понапрасну распылять. PS: А "реально нужен" следует ещё читать и как "кто готов за это заплатить деньги".
|
|
|
|
|
|
|
|
May 11 2017, 01:54
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Выглядеть этот кусок может и должен в точности как сделал авр-гцц: кладем в А число итераций-1, тело цикла, dec А далее условный переход на начало тела цикла(jrne метка). Все данные для такого преобразования у компилятора имеются, что гцц и продемонстрировал. LLVM надо конечно попробовать, но учитывая присутствие в связке sdcc...надежды мало Я конечно не готов платить и использую триал версию IAR, но просто перенести мои наработки с авра на стм8 в полном объёме не получится и это печально. Придется опять на голый си и писать все "в одну функцию" ибо оно даже заинлайнить толково не может однократно вызываемую статик функцию.... я молчу уже про плюсы, где тоже есть явные недоработки оптимизатора опять же есть с чем сравнивать, хоть меня и обвинят в холливаре. Причины наверно понятны, я конечно не могу оценить объем работ объективно, но что-то прям так и подсказывает, что ИАР просто самую малость не допилили. Вот реально чууть-чуть осталось им и всё было бы круто!
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 11 2017, 06:20
|
фанат дивана
Группа: Свой
Сообщений: 3 387
Регистрация: 9-08-07
Из: Уфа
Пользователь №: 29 684
|
Цитата(sigmaN @ May 11 2017, 06:54) Выглядеть этот кусок может и должен в точности как сделал авр-гцц: кладем в А число итераций-1, тело цикла, dec А далее условный переход на начало тела цикла(jrne метка). Дело в том, что любое непустое тело цикла почти гарантированно испортит аккумулятор. Вероятно поэтому IAR сразу располагает переменную цикла в ОЗУ. И вообще, судить об оптимизации по тому, как компилятор заоптмизировал пустой цикл - по меньшей мере странно. К тому же, надо ещё посчитать по тактам, какой вариант выгоднее. Вполне возможно, что IAR при большем числе команд выигрывает в скорости.
--------------------
Если бы я знал, что такое электричество...
|
|
|
|
|
|
|
|
May 11 2017, 08:34
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Тоже потом подумал про испорченный A. Однако же никто не отменял direct indexed sp based адресацию, с которой в один такт может работать dec и jrne тоже сработает.
В любом случае то, что делает IAR - это самый ужас, ибо там лишние действия по загрузке/выгрузке A выполняются каждую итерацию!
Да, этот пример с пустым циклом он простой и показательный, хотя не претендует на полную объективность.
Привести примеры, где происходит просто куча лишних движений не сложно.
Опять же: гцц в случае с коротким циклом ума хватает, что такой-то регистр не затирается и его можно испоьзовать. Сделать цикл по-больше и стратегия изменится. Он полезет в стек тоже, а куда денется. Но в этом случае заметно, что компилятор(и его разработчики) стараются )))
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 11 2017, 10:24
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Цитата Приведите лучше пример реализации БИХ-фильтра для разных компиляторов biggrin.gif Проверено на вполне боевой реализации void fir_mem16() из https://github.com/xiph/speex/blob/master/libspeex/filters.c из Speex Взято как средний случай обычного фильтра на Си, без особых оптимизаций там и всего прочего. Согласен, чистота эксперимента нарушена, т.к. это КИХ фильтр ))))) Но переделывать уже не охота ) Удивительно, но при раздутом размере IAR по тактам таки победил 19498 тактов у IAR 19929 Cosmic Оба последних версий, у обоих оптимизация на скорость включена по максимуму. Added:Мужики, ну я не удержался и скомпилил это на AVR-GCC 6.3.0 10708 тактов оптимизация -O3 Да-даа, я знаю что это разные архитектуры и сравнивать вот так в лоб нельзя, но я просто оставлю эти цифры здесь )))))) полный код теста: Код #include <stdint.h>
typedef int16_t spx_int16_t;
typedef uint16_t spx_uint16_t;
typedef int32_t spx_int32_t;
typedef uint32_t spx_uint32_t;
#define ABS(x) ((x) < 0 ? (-(x)) : (x)) /**< Absolute integer value. */
#define ABS16(x) ((x) < 0 ? (-(x)) : (x)) /**< Absolute 16-bit value. */
#define MIN16(a,b) ((a) < (b) ? (a) : (b)) /**< Maximum 16-bit value. */
#define MAX16(a,b) ((a) > (b) ? (a) : (b)) /**< Maximum 16-bit value. */
#define ABS32(x) ((x) < 0 ? (-(x)) : (x)) /**< Absolute 32-bit value. */
#define MIN32(a,b) ((a) < (b) ? (a) : (b)) /**< Maximum 32-bit value. */
#define MAX32(a,b) ((a) > (b) ? (a) : (b)) /**< Maximum 32-bit value. */
typedef spx_int16_t spx_word16_t;
typedef spx_int32_t spx_word32_t;
typedef spx_word32_t spx_mem_t;
typedef spx_word16_t spx_coef_t;
typedef spx_word16_t spx_lsp_t;
typedef spx_word32_t spx_sig_t;
#define Q15ONE 32767
#define LPC_SCALING 8192
#define SIG_SCALING 16384
#define LSP_SCALING 8192.
#define GAMMA_SCALING 32768.
#define GAIN_SCALING 64
#define GAIN_SCALING_1 0.015625
#define LPC_SHIFT 13
#define LSP_SHIFT 13
#define SIG_SHIFT 14
#define GAIN_SHIFT 6
#define VERY_SMALL 0
#define VERY_LARGE32 ((spx_word32_t)2147483647)
#define VERY_LARGE16 ((spx_word16_t)32767)
#define Q15_ONE ((spx_word16_t)32767)
#define QCONST16(x,bits) ((spx_word16_t)(.5+(x)*(((spx_word32_t)1)<<(bits))))
#define QCONST32(x,bits) ((spx_word32_t)(.5+(x)*(((spx_word32_t)1)<<(bits))))
#define NEG16(x) (-(x))
#define NEG32(x) (-(x))
#define EXTRACT16(x) ((spx_word16_t)(x))
#define EXTEND32(x) ((spx_word32_t)(x))
#define SHR16(a,shift) ((a) >> (shift))
#define SHL16(a,shift) ((a) << (shift))
#define SHR32(a,shift) ((a) >> (shift))
#define SHL32(a,shift) ((a) << (shift))
#define PSHR16(a,shift) (SHR16((a)+((1<<((shift))>>1)),shift))
#define PSHR32(a,shift) (SHR32((a)+((EXTEND32(1)<<((shift))>>1)),shift))
#define VSHR32(a, shift) (((shift)>0) ? SHR32(a, shift) : SHL32(a, -(shift)))
#define SATURATE16(x,a) (((x)>(a) ? (a) : (x)<-(a) ? -(a) : (x)))
#define SATURATE32(x,a) (((x)>(a) ? (a) : (x)<-(a) ? -(a) : (x)))
#define SHR(a,shift) ((a) >> (shift))
#define SHL(a,shift) ((spx_word32_t)(a) << (shift))
#define PSHR(a,shift) (SHR((a)+((EXTEND32(1)<<((shift))>>1)),shift))
#define SATURATE(x,a) (((x)>(a) ? (a) : (x)<-(a) ? -(a) : (x)))
#define ADD16(a,b) ((spx_word16_t)((spx_word16_t)(a)+(spx_word16_t)(b)))
#define SUB16(a,b) ((spx_word16_t)(a)-(spx_word16_t)(b))
#define ADD32(a,b) ((spx_word32_t)(a)+(spx_word32_t)(b))
#define SUB32(a,b) ((spx_word32_t)(a)-(spx_word32_t)(b))
/* result fits in 16 bits */
#define MULT16_16_16(a,b) ((((spx_word16_t)(a))*((spx_word16_t)(b))))
/* (spx_word32_t)(spx_word16_t) gives TI compiler a hint that it's 16x16->32 multiply */
#define MULT16_16(a,b) (((spx_word32_t)(spx_word16_t)(a))*((spx_word32_t)(spx_word16_t)(b)))
#define MAC16_16(c,a,b) (ADD32((c),MULT16_16((a),(b))))
#define MULT16_32_Q12(a,b) ADD32(MULT16_16((a),SHR((b),12)), SHR(MULT16_16((a),((b)&0x00000fff)),12))
#define MULT16_32_Q13(a,b) ADD32(MULT16_16((a),SHR((b),13)), SHR(MULT16_16((a),((b)&0x00001fff)),13))
#define MULT16_32_Q14(a,b) ADD32(MULT16_16((a),SHR((b),14)), SHR(MULT16_16((a),((b)&0x00003fff)),14))
#define MULT16_32_Q11(a,b) ADD32(MULT16_16((a),SHR((b),11)), SHR(MULT16_16((a),((b)&0x000007ff)),11))
#define MAC16_32_Q11(c,a,b) ADD32(c,ADD32(MULT16_16((a),SHR((b),11)), SHR(MULT16_16((a),((b)&0x000007ff)),11)))
#define MULT16_32_P15(a,b) ADD32(MULT16_16((a),SHR((b),15)), PSHR(MULT16_16((a),((b)&0x00007fff)),15))
#define MULT16_32_Q15(a,b) ADD32(MULT16_16((a),SHR((b),15)), SHR(MULT16_16((a),((b)&0x00007fff)),15))
#define MAC16_32_Q15(c,a,b) ADD32(c,ADD32(MULT16_16((a),SHR((b),15)), SHR(MULT16_16((a),((b)&0x00007fff)),15)))
#define MAC16_16_Q11(c,a,b) (ADD32((c),SHR(MULT16_16((a),(b)),11)))
#define MAC16_16_Q13(c,a,b) (ADD32((c),SHR(MULT16_16((a),(b)),13)))
#define MAC16_16_P13(c,a,b) (ADD32((c),SHR(ADD32(4096,MULT16_16((a),(b))),13)))
#define MULT16_16_Q11_32(a,b) (SHR(MULT16_16((a),(b)),11))
#define MULT16_16_Q13(a,b) (SHR(MULT16_16((a),(b)),13))
#define MULT16_16_Q14(a,b) (SHR(MULT16_16((a),(b)),14))
#define MULT16_16_Q15(a,b) (SHR(MULT16_16((a),(b)),15))
#define MULT16_16_P13(a,b) (SHR(ADD32(4096,MULT16_16((a),(b))),13))
#define MULT16_16_P14(a,b) (SHR(ADD32(8192,MULT16_16((a),(b))),14))
#define MULT16_16_P15(a,b) (SHR(ADD32(16384,MULT16_16((a),(b))),15))
#define MUL_16_32_R15(a,bh,bl) ADD32(MULT16_16((a),(bh)), SHR(MULT16_16((a),(bl)),15))
#define DIV32_16(a,b) ((spx_word16_t)(((spx_word32_t)(a))/((spx_word16_t)(b))))
#define PDIV32_16(a,b) ((spx_word16_t)(((spx_word32_t)(a)+((spx_word16_t)(b)>>1))/((spx_word16_t)(b))))
#define DIV32(a,b) (((spx_word32_t)(a))/((spx_word32_t)(b)))
#define PDIV32(a,b) (((spx_word32_t)(a)+((spx_word16_t)(b)>>1))/((spx_word32_t)(b)))
//////////////////
#define NVALUE 32
#define ORD 2
spx_word16_t x[NVALUE];
spx_coef_t num[ORD];
spx_word16_t y[NVALUE];
spx_mem_t mem[ORD];
void fir_mem16(const spx_word16_t *x, const spx_coef_t *num, spx_word16_t *y, int N, int ord, spx_mem_t *mem, char *stack)
{
int i,j;
spx_word16_t xi,yi;
for (i=0;i<N;i++)
{
xi=x[i];
yi = EXTRACT16(SATURATE(ADD32(EXTEND32(x[i]),PSHR32(mem[0],LPC_SHIFT)),32767));
for (j=0;j<ord-1;j++)
{
mem[j] = MAC16_16(mem[j+1], num[j],xi);
}
mem[ord-1] = MULT16_16(num[ord-1],xi);
y[i] = yi;
}
}
void main()
{
asm("nop"); //for brakepoints
fir_mem16(&x[0], &num[0], &y[0], NVALUE, ORD, &mem[0], 0x0000);
asm("nop"); //for brakepoints
}
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 11 2017, 11:52
|
Знающий
Группа: Участник
Сообщений: 825
Регистрация: 16-04-15
Из: КЧР, Нижний Архыз
Пользователь №: 86 250
|
Цитата(AHTOXA @ May 10 2017, 09:51) Посмотрите, что из вашего кода делает sdcc, и успокойтесь Это да. Никакой оптимизации, к сожалению. Но, учитывая то, что больше свободных компиляторов под STM8 нет, приходится пользоваться им. Хоть что-то… Правда, мне больше нравятся STM32. Но и там не все так хорошо: "изкоробочная" сборка arm-none-eabi-gcc не работает с F0 (операции умножения и деления вызывают зависон), приходится брать готовую сборку. А еще надо от opencm3 полностью уйти на "голый CMSIS" для STM32F1. Под F0 я уже от библиотек ушел. Надо лишь с USB разобраться...
|
|
|
|
|
|
|
|
May 11 2017, 14:37
|
Частый гость
Группа: Участник
Сообщений: 161
Регистрация: 29-09-10
Пользователь №: 59 816
|
Цитата(AHTOXA @ May 11 2017, 20:00) Раз уж вы взялись тестировать, то укажите и полученный размер. (Ну и добавьте sdcc, для полноты картины). Кейл V5 Cortex-М0 L3 2673мт Program Size: Code=308 RO-data=224 RW-data=16 ZI-data=1152 Cortex-М3 L3 1651мт Program Size: Code=304 RO-data=224 RW-data=16 ZI-data=1152
Сообщение отредактировал Михась - May 11 2017, 14:39
|
|
|
|
|
|
|
|
May 12 2017, 03:40
|
Частый гость
Группа: Участник
Сообщений: 161
Регистрация: 29-09-10
Пользователь №: 59 816
|
Цитата(AHTOXA @ May 12 2017, 00:05) Это немного не то, интересны именно компиляторы для STM8. Это да, просто хотел получить некоторую калибровочную точку на основе широко распространенной архитектуры Компилятор RIDE51 6.4 для 8052 показал время выполнения 1,1 сек на частоте 1МГц с оптимизацией по скорости и 3,3 сек с оптимизацией по объему. Прогресс внушает!! Keil C51 8052 L7 52 632 тактов Program Size: data=114.0 xdata=0 code=1228
Сообщение отредактировал Михась - May 12 2017, 15:41
|
|
|
|
|
|
|
|
May 12 2017, 10:44
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Странно, но космик в удобном виде размеры не выводит. короче сравниваем .text я так понимаю Cosmic 574 байта Код --------
Segments
--------
start 00008080 end 0000808c length 12 segment .const
start 0000808f end 000082cd length 574 segment .text
start 00004000 end 00004000 length 0 segment .eeprom
start 00000000 end 00000000 length 0 segment .bsct
start 00000000 end 00000096 length 150 segment .ubsct
start 00000096 end 00000096 length 0 segment .bit
start 00000096 end 00000096 length 0 segment .share
start 00000100 end 00000100 length 0 segment .data
start 00000100 end 00000100 length 0 segment .bss
start 00000000 end 0000036c length 876 segment .info.
start 00000000 end 000003ca length 970 segment .debug
start 00008000 end 00008080 length 128 segment .const
start 0000808c end 0000808f length 3 segment .init IAR 635байт Код "P3": 0x27b
.near_func.text ro code 0x008080 0x14c main.o [1]
.near_func.text ro code 0x0081cc 0xcc long.o [4]
.iar.init_table const 0x008298 0x8 - Linker created -
.near_func.text ro code 0x0082a0 0x1e init_small.o [4]
.near_func.text ro code 0x0082be 0x17 init.o [4]
.near_func.text ro code 0x0082d5 0x13 cstartup.o [4]
.near_func.text ro code 0x0082e8 0x5 cexit.o [4]
.near_func.text ro code 0x0082ed 0x3 interrupt.o [4]
.near_func.text ro code 0x0082f0 0x3 low_level_init.o [4]
.near_func.text ro code 0x0082f3 0x3 exit.o [4]
.near_func.text ro code 0x0082f6 0x3 unhandled_exception.o [4]
.near_func.text ro code 0x0082f9 0x2 xxexit.o [3]
- 0x0082fb 0x27b SDCC что-то не сдюжил.... D:\Poligon\FIR_TEST\sdcc>sdcc -lstm8 -mstm8 --out-fmt-elf main.c main.c:126: error 9: FATAL Compiler Internal Error in file '/home/sdcc-builder/build/sdcc-build/orig/sdcc/src/SDCCopt.c' line number '805' : 0 Contact Author with source code Странно, строка 126 в тестовом файле это for (i=0;i<N;i++) в общем тут в этом посте есть исходник теста, каждый может по развлекаться и сравнить лично https://electronix.ru/forum/index.php?s=&am...t&p=1498198Вот даже готовые проекты для IAR, STVD и AVR Studio 7 Можно с опциями оптимизации поиграться на досуге https://drive.google.com/file/d/0B7dMRxCEo4...iew?usp=sharing
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 13 2017, 17:35
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
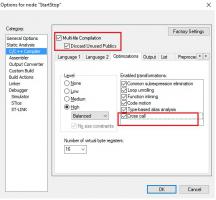
Мой товарищ сделал задержку 1us вот таким не хитрым способом Код #define ONE_US_DELAY nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop() Этот nop() есть ни что иное как макрос разворачивающийся в asm("nop") Ну а я себе на асме сделал C Callable функцию с пустым циклом и предложил ему отказаться от его метода, который занимает 17байт на каждую задержку(коих в коде у него было около десятка). В пользу моего более гибкого варианта, дающего задержки от микросекунд до миллисекунд. Но.... Внимание. Когда он заменил это на вызов моей функции - размер кода даже незначительно увеличился! О___о Расследование показало удивительный факт: его макрос превратился в вызов функции и если шагнуть в вызов то, внимание, барабанная дробь   Вы представляете, IAR даже посчитал оверхед на CALL / RET и уменьшил кол-во нопов в теле этой автогенерированной функции! Как выяснилось позднее, за это дело ответственна оптимизация CrossCall, которую можно включить в настройках... Вот так проявляется породистость компилятора, которую хочется отметить даже не смотря на некоторые явные недоработки для этой архитектуры
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 14 2017, 20:17
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Цитата Это из игры fallout. Что это за приложение для stm8? biggrin.gif Да кто ж его знает, они там игровую муть всякую делают..... Хм, кстати да, там же откуда-то второй CALL еще взялся. Короче надо будет исследовать это дело. Но то что он превратил макрос в функцию и вызывал ее - это 100%. По поводу уменьшения кол-ва нопов точных подсчетов я не проводил, но то что их меньше чем 16шт было - это тоже очевидно. Кажется на CALL/RET оверхед должен быть тактов 8, если мне не изменяет склероз. Соответственно нопов должно быть тоже 8 штук. Add: блин, были ссылки на фотки из vk. Что-то там умерло, скриншоты пропали  В самом vk эта фотка тоже щас не открывается. Что-то упало у них там...потом думаю восстановится само.
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
May 15 2017, 09:38
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(sigmaN @ May 14 2017, 22:17) Короче надо будет исследовать это дело. Но то что он превратил макрос в функцию и вызывал ее - это 100%. По поводу уменьшения кол-ва нопов точных подсчетов я не проводил, но то что их меньше чем 16шт было - это тоже очевидно. Кажется на CALL/RET оверхед должен быть тактов 8, если мне не изменяет склероз. Соответственно нопов должно быть тоже 8 штук. Я Вас просил привести макрос, из которого был сгенерён тот листинг с NOP-ами, приведённый Вами. Иначе просто вообще непонятно оценить, что и из чего Вы получили. Вы утверждали (как я понял), что IAR якобы уменьшил количество NOP-ов Вашего макроса так, чтобы в результате при оформлении их в п/п, общая задержка этой п/п была == задержке всех NOP-ов исходного макроса. Это крайне сомнительно. Так как для этого IAR-у нужно понимать назначение данного макроса, думать за программиста. Поэтому и просил привести исходный макрос. Чтобы например можно было повторить у себя и убедиться (или не убедиться). Цитата(Den64 @ May 14 2017, 20:59) Их количество такое что выполнение подпрограммы займёт 1мкС. Хотя такое впечатление что NOPов маловато. Хотя может быть и достаточно. Мой вопрос был вообще не про это. См.выше.
|
|
|
|
|
|
|
|
May 15 2017, 14:15
|
I WANT TO BELIEVE
Группа: Свой
Сообщений: 2 617
Регистрация: 9-03-08
Пользователь №: 35 751
|
Как раз эта часть отлично описана в посте со скринами Цитата Мой товарищ сделал задержку 1us вот таким не хитрым способом
Код
#define ONE_US_DELAY nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();nop();no
p();nop();nop()
Этот nop() есть ни что иное как макрос разворачивающийся в asm("nop") Макрос nop(), его конкретное определение можно найти в файле STM8S_StdPeriph_Lib\Libraries\STM8S_StdPeriph_Driver\inc\stm8s.h Код /*============================== Interrupts ====================================*/
#ifdef _RAISONANCE_
#include <intrins.h>
#define enableInterrupts() _rim_() /* enable interrupts */
#define disableInterrupts() _sim_() /* disable interrupts */
#define rim() _rim_() /* enable interrupts */
#define sim() _sim_() /* disable interrupts */
#define nop() _nop_() /* No Operation */
#define trap() _trap_() /* Trap (soft IT) */
#define wfi() _wfi_() /* Wait For Interrupt */
#define halt() _halt_() /* Halt */
#elif defined(_COSMIC_)
#define enableInterrupts() {_asm("rim\n");} /* enable interrupts */
#define disableInterrupts() {_asm("sim\n");} /* disable interrupts */
#define rim() {_asm("rim\n");} /* enable interrupts */
#define sim() {_asm("sim\n");} /* disable interrupts */
#define nop() {_asm("nop\n");} /* No Operation */
#define trap() {_asm("trap\n");} /* Trap (soft IT) */
#define wfi() {_asm("wfi\n");} /* Wait For Interrupt */
#define halt() {_asm("halt\n");} /* Halt */
#else /*_IAR_*/
#include <intrinsics.h>
#define enableInterrupts() __enable_interrupt() /* enable interrupts */
#define disableInterrupts() __disable_interrupt() /* disable interrupts */
#define rim() __enable_interrupt() /* enable interrupts */
#define sim() __disable_interrupt() /* disable interrupts */
#define nop() __no_operation() /* No Operation */
#define trap() __trap() /* Trap (soft IT) */
#define wfi() __wait_for_interrupt() /* Wait For Interrupt */
#define halt() __halt() /* Halt */
#endif /*_RAISONANCE_*/ Ну и таки уже разобрались, что IAR уменьшил кол-во нопов ради размера и везде где встречается макрос он вставил два вызова этой своей авто сгенерированной функции с нопами. Времянка конечно же не совпала, но прикольно всё равно. Настройки проекта в IAR для повторения.
--------------------
The truth is out there...
|
|
|
|
|
|
|
|
Jul 25 2017, 11:44
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(sigmaN @ May 9 2017, 23:00) ЗАЧЕМ? Зачем он делает всё это???? Посмотрите новый IAR 3.10 (есть на ftp). Он уже гораздо лучше компилит и не делает многих тех странностей, что старый. По крайней мере, там где старый генерил полный маразм: Код 95 } while (++smplN < ncell(smpl));
\ 000063 A6 01 LD A, #0x1
\ 000065 BB .. ADD A, S:smplN
\ 000067 B7 .. LD S:smplN, A
\ 000069 B6 .. LD A, S:smplN
\ 00006B A1 10 CP A, #0x10
\ 00006D 25 A7 JRC L:??McGenerate_0 новый для того же места выдаёт вполне разумно (я бы на асме так же написал-бы): Код 95 } while (++smplN < ncell(smpl));
\ 00005F 3C .. INC S:smplN
\ 000061 B6 .. LD A, S:smplN
\ 000063 A1 10 CP A, #0x10
\ 000065 25 AF JRC L:??McGenerate_0 Ну и много других мест. И это даже при "Low" оптимизации.
|
|
|
|
|
|
|
|
Jul 31 2017, 05:53
|
Местный
Группа: Свой
Сообщений: 475
Регистрация: 14-04-05
Из: Москва
Пользователь №: 4 140
|
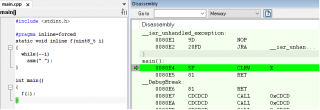
Пример из первого сообщения. STM8 Series 3.10.1 Как то так
И даже вот так
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|