| |
 Базы данных компонентов в Library Manager'е Базы данных компонентов в Library Manager'е |
|
|
|
|
 Nov 30 2009, 17:14 Nov 30 2009, 17:14
|

Частый гость

Группа: Свой
Сообщений: 120
Регистрация: 18-01-06
Из: Нижний Новгород
Пользователь №: 13 319

|
Цитата(fill) надо понять что конкретно автоматизировать Автоматизировать создание рядов элементов, к примеру. Ведь значения номиналов все равно стандартные и обозначения их (номиналов) тоже стандартные. Цитата(SM) Их эффективнее вбивать в Value прямо в DxD. А разве не нужны точные PartNumber'ы для того, чтобы потом BOM составить? (Я, конечно, недавно работаю с ЕЕ, да и проектированием печатных плат раньше не занимался, но разве для производства платы не потребуется BOM?)
|
|
|
|
|
|
|
|
Nov 30 2009, 18:19
|
Частый гость
Группа: Свой
Сообщений: 120
Регистрация: 18-01-06
Из: Нижний Новгород
Пользователь №: 13 319
|
Извините, fill, если разгневал.
Проблема заключается в том, что для элементов с высокой точностью номиналов (к примеру для ряда E96) уж больно много значений PartNumber и соответствующих Value приходится вводить вручную. Следует отметить, что все значения номиналов (ряды номиналов) стандартные и способы маркировки элементов (то есть код, определяющий номинал, почти всегда входящий в PartNumber и иногда наносимый на сам элемент) тоже стандартные.
Вопрос: Нет ли средства автоматизации создания серии элементов с номиналами из одного из стандартных рядов и с заданным способом маркировки?
Заранее спасибо.
PS. Если такого средства нет, не стесняйтесь, так и скажите, что его нет, или вы о нем не слышали, но не нужно переходить на личности и говорить, что я слишком многого хочу и т.п.
PSS. Так достаточно полно?
|
|
|
|
|
|
|
|
Nov 30 2009, 23:33
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(jericho @ Nov 30 2009, 20:14)  А разве не нужны точные PartNumber'ы для того, чтобы потом BOM составить? В большинстве случаев даже вредны, так как практически вся пассивка, например, взаимозаменяема у разных производителей, важны лишь параметры. А Part Number-ы - не важны. А если важно - что тут резистор именной этой фирмы и именно этого типа - вот его отдельно и обозначить. Можно через тот же Value указав не номинал, а конкретный part number. Хотя, конечно, все зависит от системы, принятой на предприятии. Если снабженцы - просто девочки, что сказали, то и купят, это одно. А если например главный инженер совмещает со своей основной работой подбор комплектации для закупки - совсем другое. И вот в этом втором случае - точный PartNumber для каждого резюка значительно хуже, чем просто R 0805 110 Ом 1% 0.25W, указанные в аттрибутах символа в DxD. Только представьте себе, сколько лишней работы будет по поиску замены - найти этот партнамбер, скачать доку, подобрать по параметрам такой же, да еще и непонятно, какие параметры важнее, а какие пофигу. А с третьей стороны - просто потом сделать BOM-огенератор (хоть на automation, хоть в экселе, кому как нравится), который все аттрибуты преобразует в part number-ы нужного производителя. Если уж приспичит именно такой вид BOM. Но в самой либе все равно хватит по одному компоненту на один комплект символ+паттерн.
|
|
|
|
|
|
|
|
Dec 1 2009, 08:35
|

Гуру
Группа: Модераторы
Сообщений: 4 361
Регистрация: 17-08-04
Из: КП Две Поляны
Пользователь №: 512
|
Цитата(jericho @ Nov 30 2009, 21:19) Извините, fill, если разгневал.
Проблема заключается в том, что для элементов с высокой точностью номиналов (к примеру для ряда E96) уж больно много значений PartNumber и соответствующих Value приходится вводить вручную. Следует отметить, что все значения номиналов (ряды номиналов) стандартные и способы маркировки элементов (то есть код, определяющий номинал, почти всегда входящий в PartNumber и иногда наносимый на сам элемент) тоже стандартные.
Вопрос: Нет ли средства автоматизации создания серии элементов с номиналами из одного из стандартных рядов и с заданным способом маркировки?
Заранее спасибо.
PS. Если такого средства нет, не стесняйтесь, так и скажите, что его нет, или вы о нем не слышали, но не нужно переходить на личности и говорить, что я слишком многого хочу и т.п.
PSS. Так достаточно полно? Вот именно так и надо всегда формулировать вопрос, т.к. однозначно понятно что конкретно хочет человек добиться и в каком виде видит искомое решение. На него можно однозначно ответить - в готовом виде не существует, т.к. это было бы средство одноразового использования - сгенерил и больше не для чего использовать. Цитата(SM @ Dec 1 2009, 02:33) В большинстве случаев даже вредны, так как практически вся пассивка, например, взаимозаменяема у разных производителей, важны лишь параметры. А Part Number-ы - не важны. А если важно - что тут резистор именной этой фирмы и именно этого типа - вот его отдельно и обозначить. Можно через тот же Value указав не номинал, а конкретный part number. Хотя, конечно, все зависит от системы, принятой на предприятии. Если снабженцы - просто девочки, что сказали, то и купят, это одно. А если например главный инженер совмещает со своей основной работой подбор комплектации для закупки - совсем другое. И вот в этом втором случае - точный PartNumber для каждого резюка значительно хуже, чем просто R 0805 110 Ом 1% 0.25W, указанные в аттрибутах символа в DxD. Только представьте себе, сколько лишней работы будет по поиску замены - найти этот партнамбер, скачать доку, подобрать по параметрам такой же, да еще и непонятно, какие параметры важнее, а какие пофигу.
А с третьей стороны - просто потом сделать BOM-огенератор (хоть на automation, хоть в экселе, кому как нравится), который все аттрибуты преобразует в part number-ы нужного производителя. Если уж приспичит именно такой вид BOM. Но в самой либе все равно хватит по одному компоненту на один комплект символ+паттерн. На самом деле это вопрос решаемый индивидуально на каждом предприятии- кому какой процесс больше нравится. Если используется DxDataBook и создана корпоративная база данных, то все решается достаточно просто - разработчик выбрал конкретный Part_Number с нужными ему параметрами (воспользовавшись для поиска и вставки DxDataBook)и сгенерировал BOM, далее при обработке BOM в отделе закупки выяснили что этому Part_Number есть несколько аналогов. Вариантов реализации поиска аналогов несколько, например доп. столбец в базе с перечислением аналогов или даже сам DxDataBook можно использовать для такого поиска - например Видео в котором показано, что выбрали компонент в DxDesigner, загрузили его атрибуты в DxDataBook и система нашла его в базе (или не нашла если ручки шаловливые ранее ввели неправильное значение одного из параметров  ), далее убрали несколько условий (Part_Number и посадочное место) и система показала что в базе есть 3 компонента с аналогичными параметрами, выбрали аналог и присвоили его значения в схему - соответственно и схема будет соответствовать тому что пойдет на закупку и новый измененный BOM.
--------------------
Чем больше познаю, тем больше понимаю ... насколько мало я все таки знаю. www.megratec.ru |
|
|
|
|
|
|
|
Dec 1 2009, 09:44
|
Местный
Группа: Участник
Сообщений: 222
Регистрация: 27-01-09
Из: г.Жирновск
Пользователь №: 44 025
|
Цитата(jericho @ Nov 30 2009, 19:25) Интересно, есть ли альтернативный способ создания баз данных компонентов (Parts) в Part Editor'e? Для резисторов или конденсаторов приходится забивать огромное количество значений (для каждого значения номинала)... Неужели нельзя автоматизировать этот процесс? Есть, два способа. Первый способ, выучить язык Perl, написать скрипт, который генерит из вашего текстового файла (в принципе с файла любого формата с информацией о деталях) hkp файлы для Parts, затем закодировать с помощью DataConvert и импортировать в библиотеку. Второй способ не учить Perl, сделать таблицу в Excel, затем отформатировать таблицу в формате DxDatabook и пробросить эту таблицу в Access. После чего останется вбить в Library Manager вручную детали с упрощенными названиями или даже цифрами, так чтобы они соотвествовали ключевому полю деталей DxDatabook. В библиотеке будет минимальный набор данных, а основная информация для BOM уже браться из DxDatabook. Может сумбурно написал, но когда копнете DxDatabook, все станет понятно.
Сообщение отредактировал baken - Dec 1 2009, 09:50
--------------------
Еж - птица гордая. Не пнешь - не полетит.
|
|
|
|
|
|
|
|
Dec 1 2009, 21:35
|
Профессионал
Группа: Свой
Сообщений: 1 226
Регистрация: 19-06-04
Из: Беларусь
Пользователь №: 65
|
Цитата Второй способ не учить Perl, сделать таблицу в Excel, затем отформатировать таблицу в формате DxDatabook и пробросить эту таблицу в Access.
После чего останется вбить в Library Manager вручную детали с упрощенными названиями или даже цифрами, так чтобы они соотвествовали ключевому полю деталей DxDatabook. Зачем такие сложности? DxDatabook напрямую к Excel (и даже к CSV) может подключаться (через соответствующий ODBC-драйвер системы). Это во-первых. А во-вторых PartNumber в Central Library не обязан соответствовать "ключевому полю деталей DxDatabook". Как раз наоборот - такое соответствие убьет всю универсальность. "Ключевое поле" (uniqueID) в DxDB должно быть уникальным для каждой строки в таблице (не считая поля symbol). Как правило строка соответствует конкретному manufacturer partnumber или ordercode. Но у разных строr может (и зачастую должен) быть одинаковое поле DEVICE (которое мапируется на PartNumber). Чтоб все это понять рекомендую просто потратить время на чтение всей документации в DxD-Exp, относящейся к теме. Иначе на пальцах слишком сложно объяснять, имено изза того что есть несколько путей библиотек. А по поводу языка - рекомендую Python 
|
|
|
|
|
|
|
|
Dec 7 2009, 13:33
|
Гуру
Группа: Модераторы
Сообщений: 4 361
Регистрация: 17-08-04
Из: КП Две Поляны
Пользователь №: 512
|
1. В документации все подробно изложено. 2. Возьмите ЦБ C:\MentorGraphics\2007.7EE\SDD_HOME\standard\examples\SampleLib2007 в которой все сконфигурировано и сделана база SampleLib.mdb которую можно изменить как в Access так и в Base (OpenOffice) или как видите и в самом LM. На этой ЦБ все как раз видно - можно разобраться методом научного тыка (как раз для тех кто не любит читать документацию). [attachment=38952:DxDataBook_ODBC.png] 3. Подключение всегда через ODBC, поэтому пункты для разных источников данных отличаются только на этапе формирования User Data Source в диалоге администрирования ODBC. 4. [attachment=38946:ODBC.png]
--------------------
Чем больше познаю, тем больше понимаю ... насколько мало я все таки знаю. www.megratec.ru |
|
|
|
|
|
|
|
Dec 18 2009, 12:42
|

Профессионал
Группа: Свой
Сообщений: 1 101
Регистрация: 28-06-04
Пользователь №: 200
|
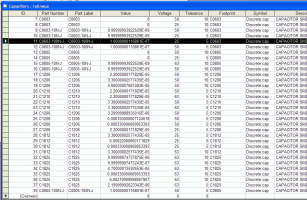
Цитата(AlexN @ Dec 8 2009, 13:52) какие-то совсем некрасивые погрешности округления value - совсем нехило DxD пересчитывает!! как обычно у индийских програмеров плоховато с устным счетом. Или у них value тоже в дюймах и при пересчете туда-сюда накапливается погрешность? Или в пинтах каких-нибудь? Глюк конечно, как обойти: в конфигурации на отображение поменять формат вывода вручную на %.3f (предлагаемые из списка %.f, %.10f, %.16f приводят к этой ерунде). И перезапустить DxD.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Dec 21 2009, 02:53
|
Профессионал
Группа: Свой
Сообщений: 1 101
Регистрация: 28-06-04
Пользователь №: 200
|
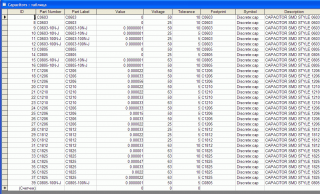
Цитата(cioma @ Dec 21 2009, 03:51) Это не компиляторы кривые - это реализация кривая. Они используют формат с плавающей запятой (float) для хранения значений. А теперь попробуйте представить 0.0000001 в двоичной системе - это бесконечная дробь (как 1/3 в десятичной системе), отсюда и получаем реальное значение, что хранится в базе равным 0.000000100000186. Возможно, со стороны пользователя это можно обойти если хранить значения как integer c единичным значением, соответствующим малой величине (например 1 мкОм, для резисторов) а я почему-то раньше думал, что float - это мантисса (целое число с довольно большой разрядностью) и порядок (тоже целое). по идее в нашем случае мантисса это типа 100000000 (а не 1000001186) а порядок - ...ну сами прикиньте. В противном случае ракеты вообще летать не должны - погрешность просто дикая (на мой взгляд). исследуем дальше. Собственно все ясно. Скорее всего, представление value в DxD - плавающее с двойной точностью. А в sampleLib.mdb - плавающее с одинарной точностью. При изменении типа поля value в sampleLib.mbd на двойную точность все это и имеем. Итог: при создании своей базы данных желательно использовать для value тип данных "двойное с плавающей точкой". Тогда артефакты исчезнут.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Dec 24 2009, 06:59
|
Местный
Группа: Участник
Сообщений: 222
Регистрация: 27-01-09
Из: г.Жирновск
Пользователь №: 44 025
|
Цитата(AlexN @ Dec 21 2009, 06:53) Собственно все ясно. Скорее всего, представление value в DxD - плавающее с двойной точностью. А в sampleLib.mdb - плавающее с одинарной точностью. При изменении типа поля value в sampleLib.mbd на двойную точность все это и имеем.
Итог: при создании своей базы данных желательно использовать для value тип данных "двойное с плавающей точкой". Тогда артефакты исчезнут. Цитата(AlexN @ Dec 21 2009, 08:10) в этом случае дробная часть не отображается совсем (посмотрите, вместо 3.3uF отображается 3uF) Вот, единственный человек, который наконец то разобрался в вопросе. Спасибо.
Сообщение отредактировал baken - Dec 24 2009, 07:07
--------------------
Еж - птица гордая. Не пнешь - не полетит.
|
|
|
|
|
|
|
|
Dec 25 2009, 17:28
|
не указал(а) ничего о себе.
Группа: Свой
Сообщений: 3 325
Регистрация: 6-04-06
Пользователь №: 15 887
|
Цитата(SM @ Dec 25 2009, 17:16) почему? Просто у строк критерии "больше-меньше" другие, сравниваются коды первых отличающихся символов. Да и я не уверен, что поиск по "больше-меньше" актуален. Тут ведь нужен всегда вполне определенный номинал, и как правило из заранее извесного ряда.
Плюс еще вот что... Я например в номинале храню "разновидности" микросемы - например компонент TPS6220x, а номинал - TPS62207 Поиск по "больше-меньше" и по диапазону актуален, ибо база может использоваться не только разработчиками, но и логистами, бухгалтерами и т.п. Им может потребоваться создавать, например, запросы для оценки стоимости комплектующих и т.п. Я лично, думаю, что в номинале нужно хранить номинал, т.е. основную характеристику компонента. У меня номиналы вообще хранятся под истинными названиями, например "Resistance" для резисторов. При аннотации в схему происхдоит замена его на VALUE. Только вот проблема: как перевели базу на SQL SERVER, начали возникать описанные выше эффекты. Кто-нибудь использует такую же конфигурацию? Какие типы полей нужны для чисел?
|
|
|
|
|
|
|
|
Dec 25 2009, 17:58
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
В любом случае string самое универсальное. В любой системе обработки БД (напр. электронных таблицах) можно интерпретировать записанное строковое значение любым образом, при этом наиточнейше храня номинал детали со всем необходимым, включая символы, а не только цифры, без ограничений на точность при хранении числом ограниченной разрядности. А поиск... Искать можно и после преобразования из строки, которая в БД, в нужный формат, и после выборки по типу детали (резистор там, кондер, и т.п.)
|
|
|
|
|
|
|
|
Dec 25 2009, 20:23
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(vitan @ Dec 25 2009, 23:03) Если это укор ментору, что есть проблемы, то присоединюсь.
Если рекомендация к действию, то не соглашусь: эдак можно все типы данных во всех языках программирования убить. Это укор ментору только в том случае, если он не поддерживает тип string в этом поле. А вообще - руководство к действию. Не надо путать разные по природе вещи - для языков программирования важен компромис по скорости обработки и занимаемому объему, а тут - эти критерии не работают. Тут важна универсальность. Не на столько велик объем этих БД, чтобы не конвертировать строки в числа в процессе обработки (сортировки, поиска и т.п.). Да и можно по ходу по мере добавления новых записей разгребать строковый полноценный value в отдельные новые (возможно скрытые) поля с числовым значением номинала, разбросом, и т.п. для ускоренной сортировки-поиска-обработки, опять же сторонними от ментора средствами работы с БД. Правда для ведения такой БД понадобится специально обученный специалист... Но я думаю, что там, где такая БД нужна в принципе, это оправдано.
|
|
|
|
|
|
|
|
Dec 26 2009, 09:35
|
Профессионал
Группа: Свой
Сообщений: 1 101
Регистрация: 28-06-04
Пользователь №: 200
|
Цитата(vitan @ Dec 26 2009, 00:28) Поиск по "больше-меньше" и по диапазону актуален, ибо база может использоваться не только разработчиками, но и логистами, бухгалтерами и т.п. Им может потребоваться создавать, например, запросы для оценки стоимости комплектующих и т.п.
Я лично, думаю, что в номинале нужно хранить номинал, т.е. основную характеристику компонента. У меня номиналы вообще хранятся под истинными названиями, например "Resistance" для резисторов. При аннотации в схему происхдоит замена его на VALUE.
Только вот проблема: как перевели базу на SQL SERVER, начали возникать описанные выше эффекты. Кто-нибудь использует такую же конфигурацию? Какие типы полей нужны для чисел? а что, sql server не поддерживает передачу double float из базы? так это может проблема его настройки или в начальной базе поле value просто float (не double)
|
|
|
|
|
|
|
|
Dec 26 2009, 16:33
|
не указал(а) ничего о себе.
Группа: Свой
Сообщений: 3 325
Регистрация: 6-04-06
Пользователь №: 15 887
|
Цитата(AlexN @ Dec 26 2009, 12:35) а что, sql server не поддерживает передачу double float из базы? так это может проблема его настройки или в начальной базе поле value просто float (не double) Проверка не проходит. В схеме атрибут такой же, как в БД, но почему-то выделяется красным. Весь компонент, соответственно, тоже. Цитата(cioma @ Dec 26 2009, 14:28) Ибо DxDB не позволяет сделать библиотеки настолько гибкими и универсальными как мне требуется. А что за гибкость нужна, если не секрет? В смысле, чем не устраивает?
|
|
|
|
|
|
|
|
Dec 27 2009, 11:59
|
Профессионал
Группа: Свой
Сообщений: 1 226
Регистрация: 19-06-04
Из: Беларусь
Пользователь №: 65
|
Я считаю, что библиотека должна быть как можно более универсальной и наименее избыточной (данные не должны дублироваться). Из этого следует, что глобальная библиотека (от логистики до сборки и поддержки) должна остоять из нескольких уровней. Для САПР печатных плат по сути нужны 4 составляющие: symbol, landpattern, pinmapping (symbol to landpatterm) и некоторые атрибуты для отображения на схеме. Для различных симуляций нужна ссылка на модели, для логистики нужна ссылка на список взаимозаменяемых комопнентов. Причем все эти параметры могут зависеть от проекта: один и тот же компонент может требовать разных посадочных мест для разных плат, или для одного устройства значение ТКС резисторов 0603 значение имеет, а для другого нет, но символы, посадочные места и маппинг резистора в обоих случаях идентичен.
Все это и приводит к идее создания generic library (без привязки к ментору или кому-либо еще) и интерфейсов в различным САПР итп.
|
|
|
|
|
|
|
|
Dec 30 2009, 19:14
|
не указал(а) ничего о себе.
Группа: Свой
Сообщений: 3 325
Регистрация: 6-04-06
Пользователь №: 15 887
|
Цитата(cioma @ Dec 28 2009, 12:11) Да не то чтобы он не угодил, просто если дойдут руки до реализации этой идеи, то делать надо правильно, а не прикручивать свою систему к DxDB, попутно тратя время на обход их косяков. Ну, не знаю... Мы вот, хоть и свою систему пишем, но и про DxDB не забываем. А вообще, если деньги есть, обратите внимание на менторовский DMS, там как раз все что надо. Даже в кейденсовский концепт можно компоненты из базы вставлять. И связи, и уровни, все есть. Жаль, самого его нет. 
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|

























 . На таким образом поставленный вопрос я могу просто ответить - выберите строчку с введенным ранее Part_Number и скопируйте нажав на соответствующую иконку. Далее в появившейся строчке копии, измените значение Part_Number и нужный параметр - например Value (если остальные параметры совпадают).
. На таким образом поставленный вопрос я могу просто ответить - выберите строчку с введенным ранее Part_Number и скопируйте нажав на соответствующую иконку. Далее в появившейся строчке копии, измените значение Part_Number и нужный параметр - например Value (если остальные параметры совпадают).
 Не понятно только, почему именно Perl? Я вот, к примеру, предпочитаю Emacs Lisp. И макросы используемого текстового редактора пока еще никто не отменял.
Не понятно только, почему именно Perl? Я вот, к примеру, предпочитаю Emacs Lisp. И макросы используемого текстового редактора пока еще никто не отменял.