| |
 Сложение чисел Сложение чисел, Какой метод будет работать быстрее? |
|
|
|
|
  Oct 10 2010, 23:24 Oct 10 2010, 23:24
|

Знающий

Группа: Свой
Сообщений: 618
Регистрация: 7-06-08
Из: USSR
Пользователь №: 38 121

|
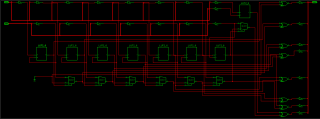
вот к примеру простенкий код: Код entity test1 is
port (
b : in std_logic_vector(7 downto 0);
c : in std_logic_vector(7 downto 0);
a : out std_logic_vector(7 downto 0)
);
end entity;
architecture Behavioral of test1 is
begin
a <= b + c;
end Behavioral; а вот РТЛ реализация прикреплена. так вот я думаю... данная сгенерированная реализация ето не что иное как Carry-Lookahead-Adder? К примеру который приведен на етой страничке: Carry-Lookahead-Adderхотя..если сравнивать подробнее то это разные реализации... Так вот вопрос такой... стоит ли однажды написать свою реализацию сумматора по принципу того что показан на линке вышеа потом инстанциировать его где нужно вместо того чтобы писать c <= a + b? Или вполне нормально писать c <= a + b в результате чего синтезатор сгенерит то что я прикрепил файлом? Что будет быстрее работать? я сейчас понял это одинаковые реализации, просто в случае с синтезатором он сгенерил мультиплексоры, а та что на линке в виде гейтов показана.. значит я так понял использовать сложение также быстро и ничего в этом плохово нету
Сообщение отредактировал BlackOps - Oct 10 2010, 22:49
Эскизы прикрепленных изображений
--------------------
Нажми на кнопку - получишь результат, и твоя мечта осуществится
|
|
|
|
|
|
|
|
Oct 11 2010, 00:46
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(BlackOps @ Oct 10 2010, 18:24)  так вот я думаю... данная сгенерированная реализация ето не что иное как Carry-Lookahead-Adder? нет, такие сумматоры в современных плис не используются Цитата стоит ли однажды написать свою реализацию сумматора по принципу того что показан на линке вышеа потом инстанциировать его где нужно вместо того чтобы писать c <= a + b? нет, это не имеет практического смысла Цитата я сейчас понял это одинаковые реализации, просто в случае с синтезатором он сгенерил мультиплексоры, а та что на линке в виде гейтов показана.. неправильно поняли, рекомендую разобраться в особенностях хилого строительного кубика(на рисунке скрин с исешки вроде), и выяснить зачем нужен MUXCY
--------------------
|
|
|
|
|
|
|
|
Oct 11 2010, 09:11
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(ViKo @ Oct 11 2010, 03:48) LUT есть в каждом LE  Какое отношение имеет LUT к схеме аппаратного переноса? Это совершенно разные вещи. И так повторю свой вопрос. Покажите FPGA, кроме cyclone I, в которой есть аппаратная реализация переносов, отличная от схемы последовательного переноса?. Цитата Смысл? - я вам привел конкретную тему, дочитайте ее до конца. та тема, не имеет никакого отношения, к этой, также как и LUT.
--------------------
|
|
|
|
|
|
|
|
Oct 11 2010, 09:25
|

Универсальный солдатик
Группа: Модераторы
Сообщений: 8 634
Регистрация: 1-11-05
Из: Минск
Пользователь №: 10 362
|
Цитата(des00 @ Oct 11 2010, 12:11) Какое отношение имеет LUT к схеме аппаратного переноса?
Это совершенно разные вещи. С чего вы взяли, что он должен быть аппаратным? Carry Lookahead означает, что перенос формируется не последовательно, а параллельно, на основании входных данных. В микросхемах счетчиков часто используется. Цитата И так повторю свой вопрос. Покажите FPGA, кроме cyclone I, в которой есть аппаратная реализация переносов, отличная от схемы последовательного переноса?. Повторю ответ - я могу в ПЛИС сделать что угодно, в том числе и Carry Lookahead. Цитата та тема, не имеет никакого отношения, к этой, также как и LUT. Да ну? Я думаю, на основании вышесказанного должно быть понятно. Как по-вашему, если включено IGNORE CARRY BUFFERS, во что превращаются цепи переноса в любой ПЛИС, например, в Cyclone III?
|
|
|
|
|
|
|
|
Oct 11 2010, 09:36
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(ViKo @ Oct 11 2010, 04:25) С чего вы взяли, что он должен быть аппаратным? С того, что вопрос автора топика был такой "Так вот вопрос такой... стоит ли однажды написать свою реализацию сумматора по принципу того что показан на линке вышеа потом инстанциировать его где нужно вместо того чтобы писать c <= a + b?". На что был дан ответ, в современных ПЛИС, вы не получите эквивалентную по тактам реализацию быстрее, чем та что реализована аппаратно. К чему ваши рассуждения о том что можно сделать, а что нельзя? Цитата Carry Lookahead означает, что перенос формируется не последовательно, а параллельно, на основании входных данных. В микросхемах счетчиков часто используется. Спасибо, теорию я еще с вуза хорошо помню. Цитата Повторю ответ - я могу в ПЛИС сделать что угодно, в том числе и Carry Lookahead. Резко просев по производительности. Но это ваше право. Причины очевидны и находятся в любом даташите на целевую ПЛИС.
--------------------
|
|
|
|
|
|
|
|
Oct 11 2010, 10:02
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(ViKo @ Oct 11 2010, 04:54) Правильно. В большинстве случаев. Но не всегда. В приведенной мной теме, когда складывается не пара чисел, а больше, аппаратные схемы последовательного переноса тормозят. Я тоже был удивлен... однако, факт! Если вы про пост №39, результат ваш видел, но считаю его неоднозначным, а ваш вывод не очевидным. Подробно разбираться с той темой не могу, и так работы много.
--------------------
|
|
|
|
|
|
|
|
Oct 11 2010, 10:05
|
Знающий
Группа: Свой
Сообщений: 845
Регистрация: 18-10-04
Из: Pereslavl-Zalessky, Russian Federation
Пользователь №: 905
|
Carry look ahead работает на длинных сумматорах, так как мультиплексор старших разрядов должен оказаться выгоднее прохождения переноса напрямую. Интуиция говорит что-то о 128 битах и больше. Нужно смотреть datasheet в разделе performance на конкретную микросхему и прикидывать.
Писание сумматора самому может быть осмыслено, если синтезатор не справляется на данной архитектуре.
Однако, использование самописного сумматора вместо абстрактоного оператора + ограничивает возможности портирования.
В упомянутой теме еще не все точки на i поставлены, так как было мало попыток для xilinx, где в принципе возможно ручное размещение и упаковка. Возможно, использование carry даст нужный результат, когда сумматоры будут расположены не кружочком, как их ставят роботы, а по уму.
|
|
|
|
|
|
|
|
Oct 11 2010, 10:18
|
Универсальный солдатик
Группа: Модераторы
Сообщений: 8 634
Регистрация: 1-11-05
Из: Минск
Пользователь №: 10 362
|
Цитата(des00 @ Oct 11 2010, 13:02) Если вы про пост №39, результат ваш видел, но считаю его неоднозначным, а ваш вывод не очевидным. До этого еще был пост №36 (не мой), который, собственно, и дал толчок к дальнейшим "извращениям". А выводов я, вроде, никаких не делал, только предположения. Пока - мой код самый быстрый. Цитата(Shtirlits @ Oct 11 2010, 13:05) Интуиция говорит что-то о 128 битах и больше. Нужно смотреть datasheet в разделе performance на конкретную микросхему и прикидывать. Сомневаюсь. LUT в LE имеют 4 входа, и это убивает все возможности создания многоразрядных Carry Lookahead.
|
|
|
|
|
|
|
|
Oct 11 2010, 10:26
|
Знающий
Группа: Свой
Сообщений: 845
Регистрация: 18-10-04
Из: Pereslavl-Zalessky, Russian Federation
Пользователь №: 905
|
QUOTE (ViKo @ Oct 11 2010, 14:18) LUT в LE имеют 4 входа, и это убивает все возможности создания многоразрядных Carry Lookahead. Не понял, какая связь вообще, что имеется в виду? Если речь идет о двух слагаемых большой длины?
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|