| |
 Принять и ПАРАЛЛЕЛЬНО распарсить поток 10Гбит/с. Как решаются такие задачи? Принять и ПАРАЛЛЕЛЬНО распарсить поток 10Гбит/с. Как решаются такие задачи? |
|
|
11 страниц  1 2 3 > »
1 2 3 > »
|
 |
Ответов
(1 - 99)
|
|
 Dec 23 2017, 12:09 Dec 23 2017, 12:09
|

Профессионал

Группа: Свой
Сообщений: 1 262
Регистрация: 13-10-05
Из: Санкт-Петербург
Пользователь №: 9 565

|
Цитата(Студент заборстроительного @ Dec 23 2017, 14:12)  Память должна быть разбита на 1000 сегментов и доступ к каждому сегменту должен быть возможен НЕЗАВИСИМО от других
ПЛИСина должна читать из 1000 дампов/сегментов ОДНОВРЕМЕННО и обрабатывать 1000 потоков параллельно и потом формированные данные 1000 потоков параллельно: каждый узел обработки пишет, читает собрабатывает свой дамп. Берёте ПЛИС Xilinx у которой количество BRAM > 1000 (Kintex7, Vertex7...) и организовываете на ней двухпортовую память. Цитата(Студент заборстроительного @ Dec 23 2017, 14:12) Или описанные мной задачи решаются как-то иначе? Может память вообще не нужна? В ПЛИС же не только 1000 ОЗУ можно сделать, но и 1000 АЛУ. Зачем складывать в память и асинхронно обрабатывать, когда пакет можно сразу отправлять на обработку соответствующему АЛУ синхронно?
|
|
|
|
|
|
|
|
Dec 23 2017, 12:13
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(_4afc_ @ Dec 23 2017, 15:09) Берёте ПЛИС Xilinx у которой количество BRAM > 1000 (Kintex7, Vertex7...) и организовываете на ней двухпортовую память. Спасибо. Но не очень понятно. Я нуб в ПЛИСах. Я понял только что мою задачу можно реализовать на ПЛИС. Так? Цитата(_4afc_ @ Dec 23 2017, 15:09) Может память вообще не нужна? В ПЛИС же не только 1000 ОЗУ можно сделать, но и 1000 АЛУ.
Зачем складывать в память и асинхронно обрабатывать, когда пакет можно сразу отправлять на обработку соответствующему АЛУ синхронно? Не знаю. Я нуб в ПЛИС. А если память не нужна, то где будет формироваться пакет для отправки по 10G эзернету? И как будет выполняться сериализация/десереализация?
Сообщение отредактировал Студент заборстроительного - Dec 23 2017, 12:14
|
|
|
|
|
|
|
|
Dec 23 2017, 13:36
|
Знающий
Группа: Участник
Сообщений: 916
Регистрация: 3-10-08
Из: Москва
Пользователь №: 40 664
|
Цитата(Студент заборстроительного @ Dec 23 2017, 15:09) Скажите своими словами Нет. Своими словами: "Эта задача не для вас. Пойдите и получите немного образования".
|
|
|
|
|
|
|
|
Dec 23 2017, 18:28
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(one_eight_seven @ Dec 23 2017, 16:36) Нет.
Своими словами: "Эта задача не для вас. Пойдите и получите немного образования". Скажите хотя бы это реализуемо на ПЛИС так как я описал? Прием потока данных по 10G эзернету и его парсинг в 1000 потоков с помощью ПЛИС? Цитата(one_eight_seven @ Dec 23 2017, 16:36) Эта задача не для вас. Естественно. Мы наймём ПЛИСовода со стороны. Мне нужно просто ТЗ написать. Вот и выясняю: реализуемо это или нет: чтобы 1000 узлов ПЛИС читали данные из памяти параллельно, в 1000 потоков, а приемопередатчик, чтобы читал последовательно. Все подряд. Не замечая границ дампов
|
|
|
|
|
|
|
|
Dec 23 2017, 18:41
|
Местный
Группа: Свой
Сообщений: 256
Регистрация: 3-05-05
Из: г. Волжский
Пользователь №: 4 714
|
QUOTE (Студент заборстроительного @ Dec 23 2017, 14:12) Поясню... То что Вы описали легко реализует специалист среднего уровня. ПЛИС для того и созданы чтобы создавать десятки, сотни и тысячи независимых узлов, которые работают параллельно. С доступом памяти тоже самое, не проблема сделать двух, трех... сто портовую память. Полагаю если Вы пишете ТЗ, Вам надо просто написать что Вы хотите, и пускай ПЛИСовод сам решает каким образом это реализовать. И не заморачивайтесь над вопросами реализуемости. Тоже самое ПЛИСовод сам подберет элементную базу под проект, это его прямая задача.
|
|
|
|
|
|
|
|
Dec 23 2017, 21:14
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(vvvv @ Dec 23 2017, 21:41) То что Вы описали легко реализует специалист среднего уровня. Отлично.  Цитата(vvvv @ Dec 23 2017, 21:41) ПЛИС для того и созданы чтобы создавать десятки, сотни и тысячи независимых узлов, которые работают параллельно. Я слышал об этом. Поэтому и пришло в голову "ПЛИС" когда размышлял о реализации задачи Цитата(vvvv @ Dec 23 2017, 21:41) С доступом памяти тоже самое, не проблема сделать двух, трех... сто портовую память. Вот "память" у меня больше всего сомнений вызывает. Про двухпортовую память я слышал. А про N-портовую - нет. Вы мне скажите. Это реально? Чтобы 1000 схемных узлов ОДНОВРЕМЕННО (ПАРАЛЛЕЛЬНО) считывали данные из памяти. Причем из РАЗНЫХ дампов Я просто хочу понять, как это выглядит ФИЗИЧЕСКИ: из одной микросхемы памяти торчат 1000 штук 20 битных шин адреса? Ведь получается 20000 контактов?Цитата(vvvv @ Dec 23 2017, 21:41) Полагаю если Вы пишете ТЗ, Вам надо просто написать что Вы хотите, и пускай ПЛИСовод
сам решает каким образом это реализовать.
И не заморачивайтесь над вопросами реализуемости. Тоже самое ПЛИСовод сам подберет
элементную базу под проект, это его прямая задача. Я "заморачиваюсь", чтобы не попасть впросак. Не написать ТЗ такое, что его будет невозможно реализовать даже на самой современной элементной базе. Но раз Вы говорите, что ничего сверх естественного в этой задаче нет. Все вполне реализуемо. И с проектом справится даже "середнячок" по ПЛИС, то тогда вопрос закрыт. Спасибо за помощь.
Сообщение отредактировал Студент заборстроительного - Dec 23 2017, 21:45
|
|
|
|
|
|
|
|
Dec 24 2017, 03:56
|
Местный
Группа: Свой
Сообщений: 256
Регистрация: 3-05-05
Из: г. Волжский
Пользователь №: 4 714
|
QUOTE (jcxz @ Dec 24 2017, 01:03) А может где и спорит сам с собой?  Как любят все ставить диагнозы. У меня параллельно не менее 3 ников, и вы не поверите сколько ников я тут уложил на форуме в борьбе за свободу ежиков. Не менее двух десятков точно. И большая часть из них "свои". QUOTE (Студент заборстроительного @ Dec 24 2017, 00:14) Про двухпортовую память я слышал. А про N-портовую - нет.
Вы мне скажите. Это реально? Если объем памяти небольшой, то делается "в лоб" на внутренней памяти ПЛИС. В Вашем случае это 1000 блоков двухпортовой памяти. Если объем памяти большой, то создается куча FIFO и блок обмена с внешней DDR3,4 памятью. Ну да 1000 блоков FIFO будут иметь "тысячи проводов" к блоку обмена с внешней памятью.
|
|
|
|
|
|
|
|
Dec 24 2017, 04:29
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
при проектировании в ПЛИС, нужно знать "сколько вешать в граммах", т.е. считать биты и такты.
ваша проблема в том, что вы рисуете 1000 одновременных обработчиков, без четкого понимания в их необходимости.
может, будет достаточно одного? или десяти? или ста? почему 1000? как считали и чем обосновываете необходимость?
далее про память. в ПЛИС не надо ничего хранить, нужно всё обрабатывать "на лету". если по алгоритму обрабатывать "на лету" невозможно, и рисуется необходимость хранить - нужна внешняя память.
и опять нужно считать биты и такты, поскольку доступ в память - всегда "бутылочное горлышко" с точки зрения пропускной способности.
для начала, посчитайте, сколько пакетов в секунду вам нужно обрабатывать. какой минимальный и максимальный размер пакета.
у вас в ПЛИС будет множество обрабатывающих блоков. прикиньте, какой разрядности будут их входные и выходные шины данных, и на какой частоте вы сможете работать.
опять пересчитайте биты и такты, и проверьте что вы обеспечиваете нужную производительность для минимального и максимального размера пакета. проверьте есть ли запас.
ну а дальше приходите сюда уже с выкладками и может, со схемой обрабатывающих блоков, тогда будут более конкретные советы.
про 1000-портовую память забудьте, так никто не делает. можно конечно сделать "для галочки" просто из прихоти что "так захотелось", но работать это будет с очень низкой тактовой, которая вас сразу не устроит по производительности.
для максимальной производительности, пакет в ПЛИС формируется не в памяти, а "на лету".
например. с АЦП есть поток данных.
он нарезается по 1024 байта, перекладывается на 32-битную шину данных, т.е. пакет "длится" 256 тактов. это блок формирования данных.
далее данные с этого блока потоком поступают на блок "дописывания к пакету заголовка".
Блок "дописывания к пакету заголовка" формирует в свою выходную шину N штук тактов с данными заголовка, после чего прозрачно передает данные со своего входа на выход (данные АЦП).
далее этот поток передается в блок ethernet MAC
ethernet MAC потоком передает данные наружу, дописывая впереди перед пакетом start sequence, выдавая биты пакета в линию наружу, вычисляя "на лету" FCS, и выдавая биты FCS в конце кадра ethernet.
и заметьте, ничего нигде специально в некоей "памяти" не хранится.
а как же дописываемый заголовок UDP/IP? так он на половину из констант, которые интегрируются в конечный автомат, а вторая половина хранится в регистрах, которые настраиваются при запуске системы.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Dec 24 2017, 14:15
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(krux @ Dec 24 2017, 06:30) если потери не сильно критичны, то даже DPDK с 10 Гбитами справится, без необходимости изучения ПЛИС. Во блин  Как я отстал от прогрессу. Я думал что поток 10Гбит/с не сможет даже i7 в реалтайме "переварить". И что это вообще очень сложная задача. Возможно не решаема так как я описал. А оказывается сейчас с ней любой студент справится и даже DPDK (правда не знаю, что значит эта аббревиатура). Ну если парсить 10Гигабитный поток в реалтайме в 1000 потоков - это рядовая задача, с которой даже студент справится, то смело буду закладывать такое решение в ТЗ  Цитата(krux @ Dec 24 2017, 07:29) при проектировании в ПЛИС, нужно знать "сколько вешать в граммах", т.е. считать биты и такты.
ваша проблема в том, что вы рисуете 1000 одновременных обработчиков, без четкого понимания в их необходимости.
может, будет достаточно одного? или десяти? или ста? почему 1000? как считали и чем обосновываете необходимость? Я уже говорил. Что есть 1000 ОДИНАКОВЫХ удаленных девайсов. Поэтом алгоритм обработки данных, поступающих от них один и тот же. kruxА по поводу всего остального .... Отвечу позже. Мне нужно время, что "переварить" и осмыслить все что вы сказали. Спасибо за большой и развёрнутый ответ.
|
|
|
|
|
|
|
|
Dec 24 2017, 16:33
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
Цитата(Студент заборстроительного @ Dec 24 2017, 17:15) Во блин Как я отстал от прогрессу. Я думал что поток 10Гбит/с не сможет даже i7 в реалтайме "переварить". И что это вообще очень сложная задача. Возможно не решаема так как я описал. А оказывается сейчас с ней любой студент справится и даже DPDK (правда не знаю, что значит эта аббревиатура). производительность DPDK на специфических задачах: http://fast.dpdk.org/doc/perf/DPDK_16_11_I...ance_report.pdf
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Dec 27 2017, 18:44
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(krux @ Dec 24 2017, 07:29) далее про память. в ПЛИС не надо ничего хранить, нужно всё обрабатывать "на лету". если по алгоритму обрабатывать "на лету" невозможно, и рисуется необходимость хранить - нужна внешняя память. "На лету" обрабатывать - это значит за наносекунды закончить всю обработку? Не. Не получится. На обработку где-то несколько тысяч тактов уйдет. Цитата(krux @ Dec 24 2017, 07:29) доступ в память - всегда "бутылочное горлышко" с точки зрения пропускной способности. Вы хотите сказать, что памяти, к которой ПАРАЛЛЕЛЬНО/ОДНОВРЕМЕННО могут обращаться 1000 узлов ПЛИС, не бывает? Ну т.е. невозможно, чтобы каждый схемный узел ПЛИС читал данные из своего дампа параллельно с 999-ю другими узлами, читающими из своих дампов?
Сообщение отредактировал Студент заборстроительного - Dec 27 2017, 18:45
|
|
|
|
|
|
|
|
Dec 27 2017, 19:16
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 27 2017, 21:44) "На лету" обрабатывать - это значит за наносекунды закончить всю обработку?
Не. Не получится. На обработку где-то несколько тысяч тактов уйдет.
Вы хотите сказать, что памяти, к которой ПАРАЛЛЕЛЬНО/ОДНОВРЕМЕННО могут обращаться 1000 узлов ПЛИС, не бывает? Ну т.е. невозможно, чтобы каждый схемный узел ПЛИС читал данные из своего дампа параллельно с 999-ю другими узлами, читающими из своих дампов? Да такое сделаеть что забор покрасить - берете 1000 FPGA к каждой цепляете свою DDR4/QDRII, 10G/100G роутите на каждую FPGA и вперед - считайте все в паралель. Делов то ... Удачи! Rob.
|
|
|
|
|
|
|
|
Dec 27 2017, 19:57
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(RobFPGA @ Dec 27 2017, 22:16) Приветствую!
Да такое сделаеть что забор покрасить - берете 1000 FPGA к каждой цепляете свою DDR4/QDRII, 10G/100G роутите на каждую FPGA и вперед - считайте все в паралель. Делов то ...
Удачи! Rob. Воблин А мне чуть выше писали, что это реализовать любой студент может. А по Вашему получается, что теоретически решить задачу теоретически вроде бы можно, но вот практически задача не имеет решения. И кому мне верить? 
|
|
|
|
|
|
|
|
Dec 27 2017, 20:09
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 27 2017, 22:57) Воблин А мне чуть выше писали, что это реализовать любой студент может. А по Вашему получается, что теоретически решить задачу теоретически вроде бы можно, но вот практически задача не имеет решения. И кому мне верить? Никому, (мне можно ...) -= Где я написал что задачу решить нельзя ? Как раз вполне ПРАКТИЧНОЕ и реализуемое решение в полном соответствии поставленной задаче! Да к тому же и легко масштабируемое - вдруг Вам 10000 устройств надо будет обслуживать? Удачи! Rob.
|
|
|
|
|
|
|
|
Dec 27 2017, 21:07
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 27 2017, 23:28) Мне говорили, что можно обойтись одной (ОДНОЙ, Карл) ПЛИСиной.
Просто прошить её так, чтобы внутри неё было 1000 узлов Ааа... Ну если так то тогда Вам все ж придется как студенту, засесть за расчеты как выше советовал уважаемы krux. А может даже как прилежному студенту еще и доки по FPGA почитать . Тогда не придется беспокоится заранее о 1000 головой гидр.. RAM. Скукота... Эх! а можно было такое ТЗ сваять - домашний аналог Amazon F1 ! Удачи! Rob.
|
|
|
|
|
|
|
|
Dec 27 2017, 22:05
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Цитата(RobFPGA @ Dec 28 2017, 00:07) Приветствую! Ааа... Ну если так то тогда Вам все ж придется как студенту, засесть за расчеты как выше советовал уважаемы krux. А может даже как прилежному студенту еще и доки по FPGA почитать . Тогда не придется беспокоится заранее о 1000 головой гидр.. RAM. Скукота... Эх! а можно было такое ТЗ сваять - домашний аналог Amazon F1 ! Удачи! Rob. 
|
|
|
|
|
|
|
|
Dec 28 2017, 04:11
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
Цитата(Студент заборстроительного @ Dec 27 2017, 21:44) "На лету" обрабатывать - это значит за наносекунды закончить всю обработку?
Не. Не получится. На обработку где-то несколько тысяч тактов уйдет. здесь мне видится рассуждение программиста, у которого за один такт может выполняться только одна вычислительная операция. для ПЛИС это тупиковый путь, и поэтому так не делают. этот вычислительный алгоритм должен быть полностью перелопачен для того чтобы его можно было эффективно реализовать на ПЛИС.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Dec 28 2017, 05:05
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(RobFPGA @ Dec 28 2017, 00:07) Приветствую! Ааа... Ну если так то тогда Вам все ж придется как студенту, засесть за расчеты как выше советовал уважаемы krux. А может даже как прилежному студенту еще и доки по FPGA почитать . Тогда не придется беспокоится заранее о 1000 головой гидр.. RAM. Скукота... Эх! а можно было такое ТЗ сваять - домашний аналог Amazon F1 ! Удачи! Rob. Ваш сарказм означает, что насчёт "любой студент сможет" и "можно обойтись одной ПЛИСиной" меня тупо обманули? Вы мне просто скажите одно: можно ли на ПЛИС реализовать такую память, к которой можно было с одной стороны обращаться как к единому целому, а с другой как к 1000 независимых дампов памяти в 1000 потоков одновременно? Если нет, то как на серверах обрабатываются потоки даже не 10Гбит/с, а в терабиты и более? Как там паралеллят обработку принятых данных?
Сообщение отредактировал Студент заборстроительного - Dec 28 2017, 05:08
|
|
|
|
|
|
|
|
Dec 28 2017, 06:38
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 28 2017, 08:05) Ваш сарказм означает, что насчёт "любой студент сможет" и "можно обойтись одной ПЛИСиной" меня тупо обманули? Я бы сказал что тонко пошутили  Цитата(Студент заборстроительного @ Dec 28 2017, 08:05) Вы мне просто скажите одно: можно ли на ПЛИС реализовать такую память, к которой можно было с одной стороны обращаться как к единому целому, а с другой как к 1000 независимых дампов памяти в 1000 потоков одновременно? Можно! Цитата(Студент заборстроительного @ Dec 28 2017, 08:05) Если нет, то как на серверах обрабатываются потоки даже не 10Гбит/с, а в терабиты и более?
Как там паралеллят обработку принятых данных? Вы сами уже ответили "... паралеллят обработку принятых данных ..." и обычно сервер для "любого студента" выглядит как на картинке внизу - на таком запросто(тонкая шутка!) можно обрабатывать поток 4 x 10G Ethernet. Успехов! Rob. 
|
|
|
|
|
|
|
|
Dec 28 2017, 21:00
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Lutovid @ Dec 28 2017, 14:43) Я на всякий случай добавлю, вдруг поможет - если одинаковые пакеты приходят и на них формируются "ответки" по одному алгоритму, то может можно и не параллелить - можно отвечать на фреймы, используя очередь, Не успеет. Данные поступают со скоростью 10 Гбит/с, а обрабатываются (если обрабатывать в один поток) со скоростью 10 Мбит/сек
|
|
|
|
|
|
|
|
Dec 28 2017, 21:33
|

В поисках себя...
Группа: Свой
Сообщений: 729
Регистрация: 11-06-13
Из: Санкт-Петербург
Пользователь №: 77 140
|
Цитата(Студент заборстроительного @ Dec 29 2017, 00:00) Не успеет.
Данные поступают со скоростью 10 Гбит/с, а обрабатываются (если обрабатывать в один поток) со скоростью 10 Мбит/сек Я чего-то не понимаю, но откуда Вы взяли 1000 потоков ? Данные то приходят последовательно.... Не думаю, что одновременно данные приходят сразу от 1000 устройств. А раз данные приходят последовательно, то почему бы их так-же последовательно не обрабатывать ? Расписали бы примерную блок схему проекта. И как замешаны данные в потоке. Да и отдавать данные Вы сможете так-же последовательно....
Сообщение отредактировал Flip-fl0p - Dec 28 2017, 21:34
|
|
|
|
|
|
|
|
Dec 29 2017, 03:49
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Flip-fl0p @ Dec 29 2017, 00:33) Я чего-то не понимаю, но откуда Вы взяли 1000 потоков ? Данные то приходят последовательно.... Не думаю, что одновременно данные приходят сразу от 1000 устройств. А раз данные приходят последовательно, то почему бы их так-же последовательно не обрабатывать ? Я же уже объяснял. Что "последовательно обрабатывать" даже i7 не успеет. Что поток данных гораздо больше, чем успевает "перемалывать" даже самый крутой интеловский процессор
|
|
|
|
|
|
|
|
Dec 29 2017, 08:37
|
Местный
Группа: Свой
Сообщений: 307
Регистрация: 14-03-06
Пользователь №: 15 243
|
Цитата(vvvv @ Dec 24 2017, 06:56) Как любят все ставить диагнозы. У меня параллельно не менее 3 ников, и вы не поверите сколько ников я тут уложил на форуме в борьбе
за свободу ежиков. Не менее двух десятков точно. И большая часть из них "свои". OFF Вас банили или что значит уложил?
|
|
|
|
|
|
|
|
Dec 29 2017, 15:05
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Flip-fl0p @ Dec 29 2017, 11:24) Последовательная обработка или параллельная. Да какая разница то ? Данные то вы будете выплёвывать последовательно ! Да что ж до Вас доходит-то всё как до жирафа!  Гигабитный приемопередатчик работает в сотни раз быстрей обработчика данных. Так понятно. Поэтому ОЗУ обновляется приемопередатчиком в сотни раз быстрей, чем обработчик успевает их обработать Цитата(Tpeck @ Dec 29 2017, 11:37) OFF
Вас банили или что значит уложил? А что? Разве в природе существуют люди, которых СОТНИ раз не банили на форумах рунета? Хотелось бы посмотреть на таких экземпляров
Сообщение отредактировал Студент заборстроительного - Dec 29 2017, 15:07
|
|
|
|
|
|
|
|
Dec 29 2017, 15:45
|
Местный
Группа: Участник
Сообщений: 221
Регистрация: 6-07-12
Пользователь №: 72 653
|
Студент заборстроительного... 1. Что значит 10Gb? Если это просто скорость линка, то можно на 10Gb 1 килобайт принять, 3 часа обрабатывать и снова на тех же 10Gb передать. Т.е. линк получается 10Gb, а эффективная пропускная способность 1килобайт в 3 часа. Чувствуете разницу? Если нет, то проконсультируйтесь с человеком из вашей команды, который понимает, что происходит. 2. Предположим, что вы определили, что на линке 10Gb к вам приходит поток данных в 500Мбайт/сек (для примера). Для решения задачи нужно понимать суть алгоритма обработки. А именно, каковы требования по памяти, какова глубина конвейера. Исходя из этих данных уже более-менее можно будет прикинуть по ресурсам можно ли это сделать на ПЛИС, какие потребуются ресурсы, чтобы обработка на ПЛИС не стала "горлышком от бутылки" в потоке данных. Уже третья страница пошла, а вы никак не можете толком сформулировать задачу.
|
|
|
|
|
|
|
|
Dec 29 2017, 16:31
|
В поисках себя...
Группа: Свой
Сообщений: 729
Регистрация: 11-06-13
Из: Санкт-Петербург
Пользователь №: 77 140
|
Цитата(Inanity @ Dec 29 2017, 18:45) Студент заборстроительного... Ещё раз. Допустим данные вы нарезаете блоками по 46 байт в кадры. Эти кадры передаёте по линку 10Gb/s. И скорость поступления кадров будет 10Gb/"размер кадра" (разделить). Приведу простейший пример. Допустим у вас классический UART со классической скоростью 9600 без паритета и чётности - 8N1. Вы передаете данные. Данные нарезаны блоками по 8 бит, которые вы обрабатываете. Данные окружены стартовым и стоповым бит. Т.е ваш кадр данных - 10 бит. Итого реальная скорость поступления данных для обработки 9600/10 = 960 кадров в секунду. С вашей задачей ситуация аналогичная. Скорость 10Gb/s - это скорость бит в линии. Но общаетесь то вы кадрами. И обрабатывать должны кадры. Откуда у вас 1000 потоков взялось ?
|
|
|
|
|
|
|
|
Dec 29 2017, 18:54
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Inanity @ Dec 29 2017, 18:45) Студент заборстроительного...
1. Что значит 10Gb? Если это просто скорость линка, то можно на 10Gb 1 килобайт принять, 3 часа обрабатывать и снова на тех же 10Gb передать. Т.е. линк получается 10Gb, а эффективная пропускная способность 1килобайт в 3 часа. Чувствуете разницу? Если нет, то проконсультируйтесь с человеком из вашей команды, который понимает, что происходит. Вы думаете я совсем дурак? Вы думаете, что я просто так написал, что даже i7 захлебнётся от такого потока? Цитата(Flip-fl0p @ Dec 29 2017, 19:31) Ещё раз.
Допустим данные вы нарезаете блоками по 46 байт в кадры.
Эти кадры передаёте по линку 10Gb/s.
И скорость поступления кадров будет 10Gb/"размер кадра" (разделить).
...
С вашей задачей ситуация аналогичная.
Скорость 10Gb/s - это скорость бит в линии.
Но общаетесь то вы кадрами. И обрабатывать должны кадры.
Откуда у вас 1000 потоков взялось ? А почему 46, а не 1500? Так что "КПД" канала у меня более 90% А про 1000 потоков уже объяснял, что данные представляют собой данные 1000 ОДИНАКОВЫХ устройств, которые нужно обрабатывать ОДИНАКОВО
Сообщение отредактировал Студент заборстроительного - Dec 29 2017, 18:55
|
|
|
|
|
|
|
|
Dec 30 2017, 07:45
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(krux @ Dec 30 2017, 07:36) ничего личного, но начинает складываться такое мнение, да. Я же писал, что я нуб в ПЛИС. Никогда с ними дело не имел. Поэтому и тему создал, чтобы у спецов спросить, можно ли такое реализовать на ПЛИС. А Вы хамить. Цитата(zombi @ Dec 30 2017, 00:23) Без разницы какой длины кадр. Только при минимальной длине пакета "КПД" канал 4%, а при максимальной - 90%. А Вы говорите "какая разница" Цитата(zombi @ Dec 30 2017, 00:23) Вы принимаете 1GB в секунду, нужно его обработать и отправить обратно.
На работу с одним байтом можно выделить не более 1нс, с пакетом - N*1нс Ну по самым грубым прикидками где-то так. А я прикидывал так. Каждое удаленное устройство описывается дампом в 64 байта. Всего устройств - 1000. Значит данные всех устройств занимают 64 000 байт Скорость порядка 1 000 000 000 байт/сек Значит скорость обновления инфы 64 000/1 000 000 000 = 64 мкс Т.е. в дампы каждого из 1000 устройств каждые 64 мкс поступает очередная порция инфы объемом 64 байта При обработке инфы полученной от устройства нужно анализировать не только последний 64-х байтный блок, но и 9 предыдущих. Таким образом ты за 64 мкс должен обработать блок длиной 640 байт. Казалось бы не много. Но если обработку вести последовательно для всех 1000 устройств, то ты должен тратить на обработку 640-ка байтного блока: 64мкс/1000=64нс Таким образом в среднем на обработку 1 байта нужно тратить не более 0,1 нс, а не 1 нс, как Вы посчитали. А реально для улучшения точности и адекватности результатов нужно КАЖДЫЙ РАЗ анализировать не 10, а 100 последних блоков, плюс сравнить результаты с результатами других устройств. Таким образом за 64 мкс ты будешь должен для каждого устройства перелопатить не 640 байт, а, как примеру 64 кбайта. Тогда чтобы успеть обработать данные всех 1000 устройств получается, что 1 байт ты должен обрабатывать за 0,001нс А если сеть будет расти и будет не 1000 устройств, а 10000? И сеть будет не 10G, а 100G? Тогда я байт ты должен обрабатывать за 0,0001 нс Даже при тактовой 5ГГц получается, что за 1/2000 такта нужно обработать 64 кбайта. А даже при ширине шины 256 бит только чтобы прочесть 64 кбайт данных из ОЗУ потребуется минимум 2000 тактов
Сообщение отредактировал Студент заборстроительного - Dec 30 2017, 07:51
|
|
|
|
|
|
|
|
Dec 30 2017, 08:34
|
Местный
Группа: Свой
Сообщений: 377
Регистрация: 23-12-06
Из: Зеленоград
Пользователь №: 23 811
|
Студент,
трудно, конечно, проникнуться вашими выкладкам...
Попробуйте зайти с другого боку в своих рассуждениях.
У вас на входе поток данных, каждые 6.4нс вы принимаете 8 байт данных по 10G.
Вы говорите, что блок обработчик данных имеет пропускную способность 10Мбит/c.
Посмотрите на зависимость данных в вашем алгоритме, можно ли обработку разложить
на N стадий последовательно идущих друг за другом. Если это так, то можно сделать
pipeline который будет работать на частоте потока данных 156Мгц.
Преимущество pipeline в том, что на каждом такте потребляется одна порция данных и
воспроизводиться одна порция данных. Работа идет на максимальной пропускной способности сети.
В таком случае, не надо ни чего параллелить, один инстанс ядра.
Да, конечно, для pipeliene нужно будет правильно формировать сигналы управления.
|
|
|
|
|
|
|
|
Dec 30 2017, 10:09
|
Гуру
Группа: Модераторы
Сообщений: 4 011
Регистрация: 8-09-05
Из: спб
Пользователь №: 8 369
|
Цитата(Студент заборстроительного @ Dec 30 2017, 12:44) Mad_max
Можно конечно поизвращаться с оптимизацией данного конкретного алгоритма.
А если придется изменить алгоритм - мне заново перепроектировать систему?
Это никуда не годиться
Я хотел бы получить УНИВЕРСАЛЬНУЮ "зубодробилку", работающую в 1000 потоков параллельно немного про оптимизацию... До сих пор не сказано о том, как работают датчики. Если имеется в виду большой физический объект, то обычно в разных ветвях алгоритма информация от датчиков имеет разное значение. Например выпущены ли шасси имеет смысл проверять только при взлете... Поэтому сомнительно, что все 1000 датчиков имеют равное значение по требуемому быстродествию... А это значит, что датчики можно разделить по группам и опрашивать с разной периодичностью... Далее. Не сказано о взаимосвязи датчиков. Не бывает, чтобы алгоритм в одной какой-то ветви требовал полностью информацию обо всех 1000 датчиков. А это значит, что физически схему контроля датчиков можно разнести по разным физическим устройствам обработки. Ну, естественно, что часть датчиков будет обмолачиваться разными устройствами.... Ну и наконец, при таком большом количестве датчиков и большой "завязке" между ними в алгоритме, наверняка потребуется все разделить на две части. Одна будет только снимать информацию с объекта, а другая - ее обрабатывать...
--------------------
www.iosifk.narod.ru
|
|
|
|
|
|
|
|
Dec 30 2017, 11:26
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(iosifk @ Dec 30 2017, 13:09) немного про оптимизацию...
До сих пор не сказано о том, как работают датчики.
Если имеется в виду большой физический объект, то обычно в разных ветвях алгоритма информация от датчиков имеет разное значение. Например выпущены ли шасси имеет смысл проверять только при взлете... Поэтому сомнительно, что все 1000 датчиков имеют равное значение по требуемому быстродествию... А это значит, что датчики можно разделить по группам и опрашивать с разной периодичностью...
Далее. Не сказано о взаимосвязи датчиков. Не бывает, чтобы алгоритм в одной какой-то ветви требовал полностью информацию обо всех 1000 датчиков. А это значит, что физически схему контроля датчиков можно разнести по разным физическим устройствам обработки. Ну, естественно, что часть датчиков будет обмолачиваться разными устройствами....
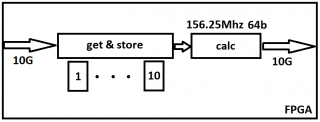
Ну и наконец, при таком большом количестве датчиков и большой "завязке" между ними в алгоритме, наверняка потребуется все разделить на две части. Одна будет только снимать информацию с объекта, а другая - ее обрабатывать... Вот опять. Мне в очередной раз предлагают подумать над тем как НЕ обрабатывать поток 10G в 1000 потоков.. Как используя разные грязные хаки, привязанные к данному конкретному случаю уменьшить объём вычислений в разы или даже на порядки. А у меня задача сделать УНИВЕРСАЛЬНУЮ "числодробилку" без привязки как какому-то конкретному случаю. Без разных хаков, работающих только при определенных условиях. Мне нужно, чтобы "числодробилка" могла использоваться в ЛЮБЫХ случаях, а не только в каких-то конкретных Цитата(Flip-fl0p @ Dec 29 2017, 22:12) А Вы, уважаемый, игнорируете просьбы предоставить более подробное описание ! Хотя это нужно было делать в первую очередь ! И это нужно Вам, а не нам... Ну вот Вам картинка, как примерно должно всё выглядеть:  Сообщение отредактировал Студент заборстроительного - Dec 30 2017, 11:16
Сообщение отредактировал Студент заборстроительного - Dec 30 2017, 11:16
|
|
|
|
|
|
|
|
Dec 30 2017, 11:50
|
В поисках себя...
Группа: Свой
Сообщений: 729
Регистрация: 11-06-13
Из: Санкт-Петербург
Пользователь №: 77 140
|
Цитата(Студент заборстроительного @ Dec 30 2017, 14:26) Вот эти вот длинные прямоугольники, к которым у Вас подключаются датчики - это что такое ? Как этот прямоугольник работает ? Что он делает ?
|
|
|
|
|
|
|
|
Dec 30 2017, 11:51
|
Местный
Группа: Свой
Сообщений: 372
Регистрация: 14-02-06
Пользователь №: 14 339
|
Предложу такой вариант: раз пакет 64 байта, делаете 10 блоков (глубина запомненных значений) памяти на 64КБ каждый. При получении каждого нового пакета, определяете номер устройства - по сути адрес для всех блоков, в один пишете, с других читаете, когда в какой писать и читать определяете по отдельной карте адресов также хранящихся на блочной памяти. Затем этот блок остается ждать следующий пакет, а следующий блок берется за расчет в конвейерном режиме. Если получится обеспечить работу алгоритма создания ответной части конвейерно и на частоте 156МГц, Ваша задача решена.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Dec 30 2017, 13:39
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 30 2017, 14:26) Вот опять.
...
А у меня задача сделать УНИВЕРСАЛЬНУЮ "числодробилку" без привязки как какому-то конкретному случаю. Без разных хаков, работающих только при определенных условиях.
Мне нужно, чтобы "числодробилка" могла использоваться в ЛЮБЫХ случаях, а не только в каких-то конкретных
... В таком виде Ваша задача НЕ имеет ИНЖЕНЕРНОГО решения. Можно только фантазировать на тему ".. какой универсально длинный забор можно зафигачить чтобы огородить все ...".У Вас к сожалению полного понимания задачи пока не видно отсюда и метания от "кольцевой сетки микроконтроллеров" до "1000 устройств на 10G". Обрабатывать realtime потоки >1 GByte/s сейчас не сложно ЕСЛИ четко ставить задачу что и как. Я делал несколько систем с потоковой обработкой 4-9 GByte/s и в каждом случае выбор железа делался только после анализа и оптимизации КОНКРЕТНЫХ алгоритмов. А у Вас то Цитата(Студент заборстроительного @ Dec 23 2017, 14:12) Т.к. устройства одинаковые, то алгоритм работы и логика обработки дампа от каждого устройства одинакова. А через некоторое время уже другое Цитата(Студент заборстроительного @ Dec 30 2017, 10:45) А реально для улучшения точности и адекватности результатов нужно КАЖДЫЙ РАЗ анализировать не 10, а 100 последних блоков, плюс сравнить результаты с результатами других устройств. И если Вы не понимаете ОГРОМНУЮ разницу между двумя этими вариантами то реальной системы Вы так и не построите. Поэтому начните с одной дощечки забора - опишите алгоритм обработки данных одного устройства с учетом всех требований и подумайте как и на чем можно его реализовать. Ну или мы все вместе так и продолжим фантазировать на тему формы и цвета дощечек Вашего универсального забора для всего. Удачи! Rob.
|
|
|
|
|
|
|
|
Dec 30 2017, 14:34
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(RobFPGA @ Dec 30 2017, 16:39) В таком виде Ваша задача НЕ имеет ИНЖЕНЕРНОГО решения. А в таком?  Цитата(RobFPGA @ Dec 30 2017, 16:39) опишите алгоритм обработки данных одного устройства Зачем? Вы хотите взяться его реализовать? Зачем Вы постоянно хотите увести тему в несущественные детали? Тут ведь решается более общий вопрос. Вопрос выбора архитектуры системы. А Вы все пытаетесь "закопать" темы в каких-то частных случаях и не существенных деталях.. Я уже несколько страниц пытаюсь добиться от господ ПЛИСоведов ответа на один простой вопрос: можно ли в ОДНОЙ (!!!) ПЛИС создать 1000 схемных узлов так, чтобы, они читал/писали данные из общей оперативной памяти ОДНОВРЕМЕННО/ПАРАЛЛЕЛЬНО? Всё.
|
|
|
|
|
|
|
|
Dec 30 2017, 15:08
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) А в таком? О... , даааа! Красный забор^2! Это конечно все радикально меняет ... (толстая шутка !)  Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) Зачем?
Вы хотите взяться его реализовать? Я никогда не возьмусь за разработку системы с такой постановкой задачи. Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) ...
Зачем Вы постоянно хотите увести тему в несущественные детали?
Тут ведь решается более общий вопрос. Вопрос выбора архитектуры системы. А Вы все пытаетесь "закопать" темы в каких-то частных случаях и не существенных деталях..
... Я пытаюсь Вам донести мысль что НЕЛЬЗЯ выбирать архитектуру системы не зная КОНКРЕТНЫХ требований алгоритмов ее работы. Вот ведь предложенная мной УНИВЕРСАЛЬНАЯ архитектура с 1000 FPGA Вам ведь почему то не понравилась.  Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) Я уже несколько страниц пытаюсь добиться от господ ПЛИСоведов ответа на один простой вопрос: можно ли в ОДНОЙ (!!!) ПЛИС создать 1000 схемных узлов так, чтобы, они читал/писали данные из общей оперативной памяти ОДНОВРЕМЕННО/ПАРАЛЛЕЛЬНО? Вам уже отвечали что в общем случае МОЖНО! Ну а "частные случаи" - тип памяти, объем, диаграмма доступа, суммарный throughput, тип/расположение, и будет ли это достаточно для Вашей обшей задачи это ведь НEВАЖНО! Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) ...
Всё. Ой не говорите .... Удачи! Rob.
|
|
|
|
|
|
|
|
Dec 30 2017, 15:09
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) Зачем?
...
Зачем Вы постоянно хотите увести тему в несущественные детали? Скорее всего за тем, что по умолчанию понимается следующее: если есть обработка данных, то результат этой обработки, зачастую, много меньше самих исходных данных. Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) Тут ведь решается более общий вопрос. Вопрос выбора архитектуры системы. А Вы все пытаетесь "закопать" темы в каких-то частных случаях и не существенных деталях.. Общим ответом в поставленном вопросе будет ссылка на сайты плисопроизводителей с указанием "ищите плис у которой будет не меньше 1000 блоков памяти (очень грубо смотрите по числу умножителей в плис)". Что касается тех деталей - чуть выше написал. Цитата(Студент заборстроительного @ Dec 30 2017, 17:34) Я уже несколько страниц пытаюсь добиться от господ ПЛИСоведов ответа на один простой вопрос: можно ли в ОДНОЙ (!!!) ПЛИС создать 1000 схемных узлов так, чтобы, они читал/писали данные из общей оперативной памяти ОДНОВРЕМЕННО/ПАРАЛЛЕЛЬНО? А есть ли вообще устройства, способные одновременно по одному каналу (шине данных) прочитать 1000 ячеек памяти с разными адресами? Если не ошибаюсь, то их нет, следовательно Вашу задачу, в такой постановке, не решить.
|
|
|
|
|
|
|
|
Dec 30 2017, 15:14
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Александр77 @ Dec 30 2017, 18:09) А есть ли вообще устройства, способные одновременно по одному каналу (шине данных) прочитать 1000 ячеек памяти с разными адресами? Если не ошибаюсь, то их нет, следовательно Вашу задачу, в такой постановке, не решить. Почему "по одному каналу"? Мне тут что-то говорили про многопортовую память
|
|
|
|
|
|
|
|
Dec 30 2017, 15:27
|
Гуру
Группа: Модераторы
Сообщений: 4 011
Регистрация: 8-09-05
Из: спб
Пользователь №: 8 369
|
Цитата(Александр77 @ Dec 30 2017, 18:09) Скорее всего за тем, что по умолчанию понимается следующее: если есть обработка данных, то результат этой обработки, зачастую, много меньше самих исходных данных.
...
А есть ли вообще устройства, способные одновременно по одному каналу (шине данных) прочитать 1000 ячеек памяти с разными адресами? Если не ошибаюсь, то их нет, следовательно Вашу задачу, в такой постановке, не решить. Мне кажется, что прикол вообще не в этом. представим себе физический объект с 1000 датчиков. Объект может быть 2-х типов. 1. Что-то вроде стенда для испытаний чего-то быстро-меняющегося, например плазмы... Тогда надо просто достаточно быстро записать данные по 1000 каналам в 1000 компьютеров и только потом их обрабатывать... 2. Речь идет об Объекте Управления. Которым надо рулить в реальном времени. Но тогда задается основной вопрос не о времени доставки сообщений, а о времени реагирования. И далее встанет вопрос об алгоритме управления и об исполнительных механизмах. Реальные механизмы - это доли секунд. К чему тогда разговоры о "нс"? А как ТС хочет реализовать алгоритм управления, если он заявляет, что устройство должно быть "универсальным" и не зависеть от "проекта"??? На аппаратной реализации языка Си??? Или еще каким либо образом. 3. А если это быстрое устройство, облепленное умными датчиками? А кто будет проводить согласование временных меток от датчиков? Ведь как не подстраивай часы в датчиках за "нс" они расползутся... 4. Теперь вопрос о сети... 1000 датчиков они где расположены? В прямой видимости? Или через свитчи? А свитчи тоже исказят время, если временной метки нет в пакете... Ну и так далее. Вообще все это похоже на лохотрон. Ну скучно перед праздником... Вот и тема появилась потрепаться.... 1000 датчиков из памяти читать одновременно... Смешно и грустно...
--------------------
www.iosifk.narod.ru
|
|
|
|
|
|
|
|
Dec 30 2017, 15:40
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Студент заборстроительного @ Dec 30 2017, 18:14) Почему "по одному каналу"?
Мне тут что-то говорили про многопортовую память Прошу прощения, понимал как доступ к внешней оперативной памяти. Внутри плис, можно "создать" аналог многопортовой памяти, но это детали проектирования, которые требуют раскрытия некоторых деталей обработки. Вполне возможно, что раскрыв "несущественную деталь" Вы, не раскрывая сверхсекретного алгоритма, сможете получить ответ как на одной плис, обработать 64КБ данных за определенный промежуток времени много меньший скорости приема и не потерять при этом никакой информативной части результатов. Цитата(iosifk @ Dec 30 2017, 18:27) Вообще все это похоже на лохотрон. Ну скучно перед праздником... Вот и тема появилась потрепаться.... 1000 датчиков из памяти читать одновременно...  А мне напоминает моих начальников. То они начитавшись\наслушавшись о плис с блеском в глазах приходят "да там такие возможности!!!", а после некоторых бесед "мне сказали плис все может, а ты меня к земле приколачиваешь, да еще и говоришь что дел не на 15 минут, как рассказывал привлеченный консультант". И как всегда, никакой конкретики.
|
|
|
|
|
|
|
|
Dec 30 2017, 16:03
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(iosifk @ Dec 30 2017, 18:27) Мне кажется, что прикол вообще не в этом.
представим себе физический объект с 1000 датчиков. Объект может быть 2-х типов.
1. Что-то вроде стенда для испытаний чего-то быстро-меняющегося, например плазмы... Тогда надо просто достаточно быстро записать данные по 1000 каналам в 1000 компьютеров и только потом их обрабатывать...
2. Речь идет об Объекте Управления. Которым надо рулить в реальном времени. Но тогда задается основной вопрос не о времени доставки сообщений, а о времени реагирования. И далее встанет вопрос об алгоритме управления и об исполнительных механизмах. Реальные механизмы - это доли секунд. К чему тогда разговоры о "нс"? А как ТС хочет реализовать алгоритм управления, если он заявляет, что устройство должно быть "универсальным" и не зависеть от "проекта"??? На аппаратной реализации языка Си??? Или еще каким либо образом.
3. А если это быстрое устройство, облепленное умными датчиками? А кто будет проводить согласование временных меток от датчиков? Ведь как не подстраивай часы в датчиках за "нс" они расползутся... Вы зря стараетесь меня "выудить" у меня детали ноу-хау нашей системы управления и "развести", чтобы я забесплатно устроил Вам ликбез по современным АСУТП. Хотя у меня ест чем возразить и дополнить по каждому из перечисленных Вами пунктов. Но я "калач тёртый". И на "слабо рассказать?" не ведусь И повторяю Вас. Не надо пытаться научить меня как избежать необходимости принимать и обрабатывать в реалтайме поток 10G. Я про эти способы прекрасно в курсе. Поэтому давайте вернемся все же к теме: "Принять и ПАРАЛЛЕЛЬНО распарсить поток 10Гбит/с. Как решаются такие задачи?" Цитата(iosifk @ Dec 30 2017, 18:27) Вообще все это похоже на лохотрон. Ну скучно перед праздником... Вот и тема появилась потрепаться.... 1000 датчиков из памяти читать одновременно... Смешно и грустно... Если Вам скучно - сходите на фишки.нет и петросян.ком. А тут серьёзный технический форум
|
|
|
|
|
|
|
|
Dec 30 2017, 16:23
|
В поисках себя...
Группа: Свой
Сообщений: 729
Регистрация: 11-06-13
Из: Санкт-Петербург
Пользователь №: 77 140
|
Цитата(Студент заборстроительного @ Dec 30 2017, 19:03) Если Вы всё знаете зачем тогда спрашиваете ? Цитата Поэтому давайте вернемся все же к теме: "Принять и ПАРАЛЛЕЛЬНО распарсить поток 10Гбит/с. Как решаются такие задачи?" Задача имеет решение только если известно как в потоке замешаны данные ! Т.е надо знать как формируется поток ! Какой применяется алгоритм для обработки данных ? Очень странно, что такой профессионал, как Вы, этого не понимаете ! Пока можно сказать что: В некоторых FPGA есть трансиверы для приема/передачи потока 10Гбит/с, при имеющейся постановки задачи большего сказать нельзя. Допустим Вы приняли поток 10Гбит/с. Распарсили его паралельно, обработали вашим супер-алгоритмом. Как вы данные будете обратно отдавать ?
Сообщение отредактировал Flip-fl0p - Dec 30 2017, 20:14
|
|
|
|
|
|
|
|
Dec 30 2017, 16:39
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Flip-fl0p @ Dec 30 2017, 19:23) Если Вы всё знаете зачем тогда спрашиваете ? Потому, что: 1) в голове есть архиважный алгоритм с запредельными характеристиками; 2) кто-то из окружения бросил фразу "делай на плис - она всё может"; 3) дальше расчетов на бумаге\в матлабе ничего не сделано. И все уперлось в те самые детали, о которых ТС не желает ничего говорить. Вообще, тема по моему, лишена продолжения - уже прозвучали слова о том что ничего не скажу - все необходимое дано выше.
|
|
|
|
|
|
|
|
Dec 30 2017, 16:58
|
Местный
Группа: Свой
Сообщений: 256
Регистрация: 3-05-05
Из: г. Волжский
Пользователь №: 4 714
|
QUOTE (Александр77 @ Dec 30 2017, 19:39) Вообще, тема по моему, лишена продолжения - уже прозвучали слова о том что ничего не скажу - все необходимое дано выше. Более того, ТС мог давным давно проверить работу своего алгоритма в Матлабе и посчитать затраты на обработку, пропускную способность и все остальное. Что и предлагаю сделать ТС, а нам всем удачи и весело отметить Новый Год! С наступающим Новым Годом! 
|
|
|
|
|
|
|
|
Dec 30 2017, 17:00
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Студент заборстроительного @ Dec 30 2017, 19:03) Вы зря стараетесь меня "выудить" у меня детали ноу-хау нашей системы управления и "развести", чтобы я забесплатно устроил Вам ликбез по современным АСУТП. Хотя у меня ест чем возразить и дополнить по каждому из перечисленных Вами пунктов. Но я "калач тёртый". И на "слабо рассказать?" не ведусь Ой как неуважитеоьно по отношению к собеседникам! Ведь судя по всему это Вы пытаетесь выудить ноу-хау "...как же черт возми это можно сделать ..." и забесплатно получить техническое решение для Вашей системы управления. Ай ай ай. Цитата(Студент заборстроительного @ Dec 30 2017, 19:03) ...
Поэтому давайте вернемся все же к теме: "Принять и ПАРАЛЛЕЛЬНО распарсить поток 10Гбит/с. Как решаются такие задачи?" А зачем ? Ведь Вы же уже все знаете: Цитата(Студент заборстроительного @ Dec 30 2017, 19:03) И повторяю Вас. Не надо пытаться научить меня как избежать необходимости принимать и обрабатывать в реалтайме поток 10G.
Я про эти способы прекрасно в курсе. Цитата(Студент заборстроительного @ Dec 30 2017, 19:03) ...
А тут серьёзный технический форум Серьезным он будет тогда когда Вы как задавший вопрос и ищущий способы решения Вашей проблемы будете внимательны к замечаниям участвующих в обсуждении. Ну техническим он будет если для постановки задачи и оценки способов ее решения будут использоваться конкретные количественные параметры и термины, а не домыслы и догадки. А иначе это превращается в филиал битвы экстрасенсов! Удачи! Rob.
|
|
|
|
|
|
|
|
Dec 30 2017, 21:23
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Flip-fl0p @ Dec 30 2017, 19:23) Задача имеет решение только если известно как в потоке замешаны данные ! Т.е. чтобы решить задачу "в лоб" так как я описал (параллельное чтение и обработка в 1000 потоков) - ресурсов даже мощной ПЛИС не хватит? Цитата(RobFPGA @ Dec 30 2017, 20:00) Приветствую!
Ой как неуважитеоьно по отношению к собеседникам! Просто достало слушать ликбез по устройству АСУТП. Коими я занимаюсь лет 30. Мне не по устройству АСУТП инфа нужна, а по ПЛИС. Точнее их возможностей в части реализации описанной задачи. И я честно признался, что я нуб в ПЛИС (но не в АСУТП) А мне вместо ПЛИС начинают объяснят АЗЫ устройства АСУТП. Вот я и вспылил Цитата(RobFPGA @ Dec 30 2017, 20:00) Серьезным он будет тогда когда Вы как задавший вопрос и ищущий способы решения Вашей проблемы будете внимательны к замечаниям участвующих в обсуждении. Когда эти замечания по существу я к ним внимателен. А когда эти замечания с целью увести тему в сторону - меня это выводит из себя. Вот же задача. Что тут не понятного?
Сообщение отредактировал Студент заборстроительного - Dec 30 2017, 21:13
|
|
|
|
|
|
|
|
Dec 30 2017, 21:56
|
В поисках себя...
Группа: Свой
Сообщений: 729
Регистрация: 11-06-13
Из: Санкт-Петербург
Пользователь №: 77 140
|
Цитата(Студент заборстроительного @ Dec 31 2017, 00:13) Т.е. чтобы решить задачу "в лоб" так как я описал (параллельное чтение и обработка в 1000 потоков) - ресурсов даже мощной ПЛИС не хватит? Решением задачи "в лоб" было предложено товарищем RobFPGA. Других разумных решений в рамках поставленой задачи быть не может из-за недостатка исходных данных. Ваше описание 1000 параллельных процессов - есть результат ошибочного суждения. У вас могут данные с датчиков собираться как угодно: параллельно, перпендикулярно - это значение не имеет ! Имеет значение что, данные с датчика как-то обрабатываются и упаковываются в ethernet кадры, которые передаются по линку 10gb/s. FPGA ловит эти данные и начинает обработку по какому-то алгоритму. Результат обработки выдает по каналу 10gb/s. Я нарисовал картинку как я представляю Вашу задачу:  Так вот самой важной информацией является то, как данные с датчиков запакованы в Ethernet кадр. И по какому алгоритму данные с датчиков будут обрабатываться. В простейшем случае - это конвейер, который будет обрабатывать данные темпе приёма этих кадров и отправлять на передачу по каналу 10gb/s. Я до сих пор не могу понять откуда у вас взялось 1000 параллельных потоков ! Но при любом варианте у вас данные будут приниматься и отправляться последовательно.
|
|
|
|
|
|
|
|
Dec 31 2017, 05:06
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Flip-fl0p @ Dec 31 2017, 00:56) Я до сих пор не могу понять откуда у вас взялось 1000 параллельных потоков ! 1000 потоков у ТС берутся перед обработкой. Приняв весь этот 10 гигабитный шалман (еще большой вопрос что там с заполненностью, может, как уже говорили он принимает раз в час свои 64КБ и гигабиты избыточны), ТС желает его тут же на лету разобрать по обработчикам. Т.е. в его понимании каждый новый принятый бит направить к своему узлу обработки. Но при этом сильно скрывает (от себя?) тот факт, что перед тем как получить 1000 потоков, ему надо разделить блоки данных от каждого формирователя к каждому узлу обработки, выполнив тем самым обратную задачу относительно приведенной блок-схемы. И когда до него дойдет что на получение блока данных в 64 КБ понадобится 64 мкс, тогда станет понятно, что все требования по обработке за наносекунды станут никчемны. Остается ТС посчитать, сможет его алгоритм уложиться в 64 мкс или нет. Если сможет - надо искать плис у которой будет как минимум 1000 умножителей и 10G приемо-передатчик и пытаться передложить работу на нее. А еще правильнее, приняв 10G данные, раскидать по блокам и отправить на обработку в графическую карту - та точно должна смочь обсчитать всего коня. С наступающим Новым годом!
|
|
|
|
|
|
|
|
Dec 31 2017, 06:18
|
Знающий
Группа: Свой
Сообщений: 574
Регистрация: 9-10-04
Из: FPGA-city
Пользователь №: 827
|
Цитата(Александр77 @ Dec 31 2017, 09:06) А еще правильнее, приняв 10G данные, раскидать по блокам и отправить на обработку в графическую карту - та точно должна смочь обсчитать всего коня. Этакого коня можно локально обсчитать на простеньком Virtex Ultrascale+ в 2000-ногом корпусе. Ну или нельзя, нужно больше конкретики.
|
|
|
|
|
|
|
|
Dec 31 2017, 08:03
|
Частый гость
Группа: Свой
Сообщений: 135
Регистрация: 8-01-12
Из: Беларусь
Пользователь №: 69 226
|
Давайте ответим человеку. Каждый свое мнение. Он посчитает вероятность исходя из ответов Отвечаем только ДА или НЕТ! ДА! Всех с наступающим Новым годом! выполнения констрейнов и соответсвия поведения проектов в симуляции и реальности!!!
|
|
|
|
|
|
|
|
Dec 31 2017, 10:21
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Это несправедливо, требовать ответа только с вариантами "Да" и "Нет"! Правильнее дополнить вариантами: "Наверное Да"; "Наверное Нет"; "Скорее Да"; "Скорее Нет"; "Возможно при/если..."; "Невозможно при/если...". Ну а конкретнее, думаю если использовать Stratix V GS, то можно реализовать, но есть шанс лупануть из пушки по стае воробьёв. Ибо умножителей много, а что делать с 640 байтами в одном узле? Обиднее будет посчитать их сумму потратив несколько сотен тысяч деревянных на плис, плату (особенно своей разработки) и все для того, чтобы засветить пару светодиодов.
|
|
|
|
|
|
|
|
Dec 31 2017, 11:15
|
Местный
Группа: Свой
Сообщений: 256
Регистрация: 3-05-05
Из: г. Волжский
Пользователь №: 4 714
|
Вот одного не пойму или я полный идиот и чего то крупно не догоняю, или на форуме все мозги пропили окончательно, включая ТС.
Все же крайне очевидно. Прилетает из вселенной поток в 10Gb/s. 10 гигабит в секунду.
Его надо:
1. распотрошить на блоки по 64 байта
2. каждый блок 64 байта обработать каким то образом, пускай это будет сдвиг и XOR с неким ключом
3. считать обработанные данные в некий большой пул памяти.
Считаем. Данные поступают со скоростью 10Gbit в секунду, пускай это будет чистая скорость поступления данных, уже за вычетом накладных расходов.
Данные со скоростью 10Gbit вдвигаются в сдвиговый регистр длиной 64*8 = 512 бит.
Полное заполнение регистра происходит за 512*0.1 = 51ns. После заполнение на следующем такте все 512 байт улетают в копию регистра.
Дальше работа с копией, и у нас есть 51 ns на все про все.
Что же нужно сделать за это время.
1.Скопировать регистр 64 байта из копии сдвигового регистра в один из 1000 блоков распределенной памяти размером 64 байта
2. ВСЕ. Больше НИЧЕГО делать не нужно. 51ns на эту операцию это более чем достаточно раза в 4 наверное.
Так как у нас 1000 блоков, в каждый прилетает 64 байта или 512 бит, то обновление каждого блока памяти из 1000 происходит... происходит... происходит один раз в 50мкс.
За 50мкс каждый блок должен:
1. произвести сдвиг данных и операцию XOR (пункт 2 выше).
2. выставить флаг что блок данные подготовил.
Это даже не вагон времени, для 64 байт данных это вагон времени.
И наконец у нас есть третий игрок, арбитр внешней памяти, который шерстит все блоки по кругу и по флагу готовности пересылает 64 байта данных из блока во внешнюю памяти.
Арбитр должен перекачивать данные во внешнюю DDR3 памяти со скоростью 10Gb/s что является нормой для данного типа памяти.
Все.
Что в вышеописанном неверно.
И если верно, то справится с этим плисовод среднего уровня и
почему тогда столько грамотных людей морочат голову автору темы.
PS: Вот тут кстати спрашивали как это я "уложил своих". Ну вот, модераторы навесили предупреждение 10% репутации. Мелочь, но проблема в том, что они, модераторы
НИКОГДА не снимают эти предупреждения. И смотреть теперь на это до конца веков.
Чтобы этого не было, я в честь праздника никого вежливо посылать не буду. Но всем говорю прощайте. Ник будет деактивирован.
Это последнее сообщение.
|
|
|
|
|
|
|
|
Dec 31 2017, 11:31
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(vvvv @ Dec 31 2017, 14:15) Что в вышеописанном неверно. И если верно, почему тогда столько грамотных типа людей морочат голову автору темы. ТС заморочил своим забором всем мозг. А остальные не понимают как можно говорить о достаточности/недостаточности ресурсов, когда неизвестно все, начиная с поступления новых данных, ибо то у него 90% 10G потока ими заполнено, то может быть меньше. А может и будут не все 1000 блоков по 64 Байта, а может и не всегда придется обрабатывать с предыдущими 9*64 результатами? (это я от себя добавил, так сказать интуитивно). И есть у ТС стойкое нежелание понимать, что новый блок данных (со всех датчиков) требует времени приема и лишь затем обработки. И что ресурсы надо считать по интервалу между блоками, а не битами в скоростном канале. Опять же, результат обработки выдаваться будет едва ли не 10Мбит/с или 100Мбит/с каналу(где-то в начале промелькнуло значение). Но боюсь Вы окажетесь правы - вся новая хау сведется к подсчету контрольной суммы или просто среднему арифметическому.
|
|
|
|
|
|
|
|
Dec 31 2017, 14:29
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(syoma @ Dec 31 2017, 16:55) ... В любом случае задача должна решаться на ПЛИСе, но нужно для начала знать алгоритм обработки и сколько тактов и ресурсов он будет занимать. Тогда можно будет подсчититать нужное окличество и размер ПЛИС Шел четвертый год войны... Беда в том, что ТС сказал что все описанное на предыдущих пяти страницах ему известно уж более 30 лет. А все наши попытки детализирования - это происки завистников, желающих любой ценой выкрасть уникальный универсальный алгоритм вычисления абсолютного уравнения Вселенной. Но он нас раскусил и потому, никогда ни под каким соусом не расскажет что же он собирается делать с вновь поступившими 64 байтами, да еще с учетом предыдущих (9 или 10)*64 байт. А именно от этой самой обработки будет зависеть сможет ли справиться одна плис или нет?
|
|
|
|
|
|
|
|
Dec 31 2017, 14:43
|
Профессионал
Группа: Свой
Сообщений: 1 817
Регистрация: 14-02-07
Из: наших, которые работают за бугром
Пользователь №: 25 368
|
Цитата(Александр77 @ Dec 31 2017, 16:29) Шел четвертый год войны...
Беда в том, что ТС сказал что все описанное на предыдущих пяти страницах ему известно уж более 30 лет.
А все наши попытки детализирования - это происки завистников, желающих любой ценой выкрасть уникальный универсальный алгоритм вычисления абсолютного уравнения Вселенной. Но он нас раскусил и потому, никогда ни под каким соусом не расскажет что же он собирается делать с вновь поступившими 64 байтами, да еще с учетом предыдущих (9 или 10)*64 байт.
А именно от этой самой обработки будет зависеть сможет ли справиться одна плис или нет? Ну я бы сказал, что по опыту решения аналогичных задач, вряд-ли у него там какой-то супер-пупер алгоритм, требующий всех ресурсов ПЛИС, раз даже обычный процессор может переварить такой поток, хоть и не на 10Гбит/с. Поэтому подозреваю, что этот алгоритм легко можно впихнуть в логику, только для этого, ессно, его надо из Си переделать в VHDL, что может в корне его видоизменить. Но это в принципе не страшно. Поэтому я бы сказал, что одна ПЛИС справится, а для ответа на вопрос - какая - надо делать. В крайнем случае получите большую латентность, чем желаемую. А по поводу памяти и дампов и пр. - похоже ТС описывает обычную двухпортовую память - базовый блок ПЛИС и да - она также может использоваться именно таким образом - сериализатор/десериализатор для гигабитных интерфейсов(точнее кластеризатор на пакеты) ИМХО протокол у ТС похож на EtherCAT, только быстрый. Предыдущие пакеты - это, наверное для фильтрации.
|
|
|
|
|
|
|
|
Jan 2 2018, 12:04
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(one_eight_seven @ Dec 31 2017, 00:56) Вы нуб, но почему-то решили, что можете судить по существу вопрос или не по существу, когда его задают те, кто в вопросе не нуб.
Это та причина, по которой вас считают на этом форуме не специалистом по АСУТП, а недалеким болтуном. Вы не поняли. Я нуб в ПЛИС, но не устройстве АСУТП. А некоторые начинают выяснять про детали устройства АСУТП, чтобы выявить "завязки по данным", "скорость работы устройств" и т.п., чтобы посоветовать мне решение как НЕ парсить поток 10Гб/с. Господа! Повторяю в третий и последний раз: мне не нужны советы как ИЗБЕЖАТЬ парсинга 10Гб/с в 1000 потоков. Если бы мне нужны были такие советы - я бы и тему назвал по другому. Типа "есть задача парсить в 1000 потоков приходящие данные с 10 Гб/с. Как путем разных хаков свести его к потоку в 1 Мб/с и парсингу в 1 поток?" Но я же так не назвал тему. Поэтому не надо. Нужно парсить именно в 1000 потоков и данные поступающие со скоростью 10 Гб/с.Единственно, что уточню (поскольку да. Из заголовка темы это не ясно): поток 10Гб/с идет постоянно. Без пауз. Т.е. предположения, что приняв 64 байта на скорости 10Гб/с езернетовский приемопередатчик выключается на полчаса НЕ ВЕРНЫ. Он колбасит ПОСТОЯННО. Т.е. данные от приемопередатчика поступают в ОЗУ постоянно Цитата(Flip-fl0p @ Dec 31 2017, 00:56) Решением задачи "в лоб" было предложено товарищем RobFPGA. Других разумных решений в рамках поставленой задачи быть не может из-за недостатка исходных данных. Т.е. ставить 1000 ПЛИСин? А почему нельзя (я никак врубиться не могу) "1000 ПЛИСин" реализовать внутри одной ПЛИСины? Меня учили, что ПЛИС как раз и предназначены для формирования внутри неё одинаковых схемных узлов, работающих ПАРАЛЛЕЛЬНО. Или это не так? Цитата(Flip-fl0p @ Dec 31 2017, 00:56) Ваше описание 1000 параллельных процессов - есть результат ошибочного суждения. В памяти есть 1000 одинаковых дампов. Я хочу чтобы все они обрабатывались ПАРАЛЛЕЛЬНО, поскольку имеют одинаковый формат данных и одинаковый алгоритм обработки. В чем я не прав? Цитата(Flip-fl0p @ Dec 31 2017, 00:56) Я нарисовал картинку как я представляю Вашу задачу: Да. Всё правильно. Цитата(Flip-fl0p @ Dec 31 2017, 00:56) Так вот самой важной информацией является то, как данные с датчиков запакованы в Ethernet кадр. И по какому алгоритму данные с датчиков будут обрабатываться. Это важно. Но это уже детали реализации. Пока нужно определиться с архитектурой: можно в ПЛИСине создать 1000 одинаковых узлов, работающих со своим дампом НЕЗАВИСИМО от других или нет. Цитата(Flip-fl0p @ Dec 31 2017, 00:56) Но при любом варианте у вас данные будут приниматься и отправляться последовательно. С этим я и не спорил. Цитата(Александр77 @ Dec 31 2017, 08:06) 1000 потоков у ТС берутся перед обработкой. Приняв весь этот 10 гигабитный шалман (еще большой вопрос что там с заполненностью, может, как уже говорили он принимает раз в час свои 64КБ и гигабиты избыточны), ТС желает его тут же на лету разобрать по обработчикам. Т.е. в его понимании каждый новый принятый бит направить к своему узлу обработки. Но при этом сильно скрывает (от себя?) тот факт, что перед тем как получить 1000 потоков, ему надо разделить блоки данных от каждого формирователя к каждому узлу обработки, выполнив тем самым обратную задачу относительно приведенной блок-схемы. И когда до него дойдет что на получение блока данных в 64 КБ понадобится 64 мкс, тогда станет понятно, что все требования по обработке за наносекунды станут никчемны.
Остается ТС посчитать, сможет его алгоритм уложиться в 64 мкс или нет. Если сможет - надо искать плис у которой будет как минимум 1000 умножителей и 10G приемо-передатчик и пытаться передложить работу на нее.
А еще правильнее, приняв 10G данные, раскидать по блокам и отправить на обработку в графическую карту - та точно должна смочь обсчитать всего коня.
С наступающим Новым годом! Ещё раз. Как я представлю решению. 10G Приемопередатчик заполняет оперативную память данными, полученными по езернету. При этом для него память не сегментируется. Она для него как единое целое. Это память представляет собой единое "логическое пространство задачи" (как пишут в умных книжках по распределенным системам управления). Такое же "логическое пространство задачи" находится на другой стороне эзернетовского кабеля. Так вот задачей приемопередатчиков является создание "ЗЕРКАЛА". Т.е. точных копий "логического пространства задачи" на обоих сторонах. Для этого используется 10G езернет "Логическое пространство задачи" представляет собой 1000 дампов одинакового формата И теперь наконец то, чем тема: можно ли эти 1000 дампов обрабатывать одной ПЛИСиной ПАРАЛЛЕЛЬНО? Чтобы с каждым дампом был связан свой схемный узел ПЛИСины, работающий независимо от других узлов Цитата(vvvv @ Dec 31 2017, 14:15) Вот одного не пойму или я полный идиот и чего то крупно не догоняю, или на форуме все мозги пропили окончательно, включая ТС.
Все же крайне очевидно. Прилетает из вселенной поток в 10Gb/s. 10 гигабит в секунду.
Его надо:
1. распотрошить на блоки по 64 байта
2. каждый блок 64 байта обработать каким то образом, пускай это будет сдвиг и XOR с неким ключом
3. считать обработанные данные в некий большой пул памяти. Конгениально, коллега Именно эту простую мысль я пытаюсь донести до коллег уже 7-ю страницу Цитата(vvvv @ Dec 31 2017, 14:15) Вот одного не пойму или я полный идиот и чего то крупно не догоняю, или на форуме все мозги пропили окончательно, включая ТС.
Все же крайне очевидно. Прилетает из вселенной поток в 10Gb/s. 10 гигабит в секунду.
Его надо:
1. распотрошить на блоки по 64 байта
2. каждый блок 64 байта обработать каким то образом, пускай это будет сдвиг и XOR с неким ключом
3. считать обработанные данные в некий большой пул памяти.
Считаем. Данные поступают со скоростью 10Gbit в секунду, пускай это будет чистая скорость поступления данных, уже за вычетом накладных расходов.
Данные со скоростью 10Gbit вдвигаются в сдвиговый регистр длиной 64*8 = 512 бит.
Полное заполнение регистра происходит за 512*0.1 = 51ns. После заполнение на следующем такте все 512 байт улетают в копию регистра.
Дальше работа с копией, и у нас есть 51 ns на все про все.
Что же нужно сделать за это время.
1.Скопировать регистр 64 байта из копии сдвигового регистра в один из 1000 блоков распределенной памяти размером 64 байта
2. ВСЕ. Больше НИЧЕГО делать не нужно. 51ns на эту операцию это более чем достаточно раза в 4 наверное.
Так как у нас 1000 блоков, в каждый прилетает 64 байта или 512 бит, то обновление каждого блока памяти из 1000 происходит... происходит... происходит один раз в 50мкс.
За 50мкс каждый блок должен:
1. произвести сдвиг данных и операцию XOR (пункт 2 выше).
2. выставить флаг что блок данные подготовил.
Это даже не вагон времени, для 64 байт данных это вагон времени.
И наконец у нас есть третий игрок, арбитр внешней памяти, который шерстит все блоки по кругу и по флагу готовности пересылает 64 байта данных из блока во внешнюю памяти.
Арбитр должен перекачивать данные во внешнюю DDR3 памяти со скоростью 10Gb/s что является нормой для данного типа памяти.
Все.
Что в вышеописанном неверно. Всё верно Цитата(vvvv @ Dec 31 2017, 14:15) И если верно, то справится с этим плисовод среднего уровня Спасибо. Понял. Цитата(vvvv @ Dec 31 2017, 14:15) И если верно, то справится с этим плисовод среднего уровня и
почему тогда столько грамотных людей морочат голову автору темы. Тоже не понимаю. Почему меня пытаются постоянно увести куда-то в сторону от темы, предлагают решения НЕ МОЕЙ задачи и прочее... Наверное просто издиваются
Сообщение отредактировал Студент заборстроительного - Jan 2 2018, 11:33
|
|
|
|
|
|
|
|
Jan 2 2018, 16:09
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Студент заборстроительного @ Jan 2 2018, 15:04) Тоже не понимаю. Почему меня пытаются постоянно увести куда-то в сторону от темы, предлагают решения НЕ МОЕЙ задачи и прочее...
Наверное просто издиваются Потому что Вы в свою очередь не хотите понять простой истины, прием пакета требует времени и пока пакет не принят - обработка не начнется. Весь Ваш обмен данными выродится в мультиплексор с одной стороны и демультиплексор с другой. Время приема Ваших 1000 пакетов уже не представил лишь самый ленивый, т.е. Вы сами. Уже шесть страниц Вам советуют посчитать интервал приема новых данных (со всеми накладными расходами в виде заголовков, контрольных сумм и т.п.), и затем смотреть, как Ваш алгоритм уложится в этот интервал. И если он укладывается в этот интервал, то остается выбрать плис в которой можно поместить ваши 1000 однотипных узлов. И уже дальше решать, искать готовую плату с этой плис или ее большими собратьями, или делать свою. Так что большой вопрос, кто над кем издевается? Цитата(Студент заборстроительного @ Jan 2 2018, 15:04) Вы не поняли. Я нуб в ПЛИС, но не устройстве АСУТП. Скажите, только честно. Вы 30 лет назад закончили институт и больше по специальности не работали, а теперь решили вернуться в системотехники?
|
|
|
|
|
|
|
|
Jan 2 2018, 17:21
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Александр77 @ Jan 2 2018, 19:09) Потому что Вы в свою очередь не хотите понять простой истины, прием пакета требует времени и пока пакет не принят - обработка не начнется. Почему "не хочу понять"? Я прекрасно это понимал еще до создания этой темы. Ещё лет 30 назад Давайте очень грубо прикинем. Допустим длина пакета (со всеми служебными полями) порядка 1600 байт Прием такого пакета займет 1.6 мкс Один такой пакет несёт в себе дампы 25 узлов. Значит чтобы обновить всё "логическое пространство задачи" потребуется примерно 40 циклов шины или 64 мкс. Т.е. получается что дамп (размером 64 байта) каждого из 1000 устройств в "логическом пространстве задачи" обновляется с периодом ПОРЯДКА 64 мкс. Пока всё ясно? Или уже тут есть какие-то сомнения? ----- Идём далее. Схемные узлы в ПЛИСине обрабатывают каждый свой дамп ПОСТОЯННО. Они не ждут какого-то специального сигнала "данные обновились" Они (эти узлы) работают со своим собственным циклом и им ПЛЕВАТЬ с какой частотой обновляются данные в дампе 10G приемопередатчиком. Тут понятно?
Сообщение отредактировал Студент заборстроительного - Jan 2 2018, 17:24
|
|
|
|
|
|
|
|
Jan 2 2018, 17:40
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Inanity @ Jan 2 2018, 20:37) Алгоритм обработки для каждого из 1000 узлов одинаковый? Абсолютно. Потому что удаленные устройства относятся к одному и тому же типу. Но хотя алгоритм одинаковый устройства могут находится в разных состояниях (автомат состояний) Поэтому для одного узла может потребоваться сделать одно, а для другого - другое (потому что он находится в другом состоянии)
|
|
|
|
|
|
|
|
Jan 2 2018, 18:01
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Студент заборстроительного @ Jan 2 2018, 20:21) Почему "не хочу понять"? Я прекрасно это понимал еще до создания этой темы. Ещё лет 30 назад
Давайте очень грубо прикинем.
...
Т.е. получается что дамп (размером 64 байта) каждого из 1000 устройств в "логическом пространстве задачи" обновляется с периодом ПОРЯДКА 64 мкс.
Пока всё ясно? Или уже тут есть какие-то сомнения? Хвала всевышнему. Читаем сообщение 65 (стр 5) и сравниваем, как далеко разошлись интервалы. Цитата(Студент заборстроительного @ Jan 2 2018, 20:21) Идём далее.
Схемные узлы в ПЛИСине обрабатывают каждый свой дамп ПОСТОЯННО.
Они не ждут какого-то специального сигнала "данные обновились"
Они (эти узлы) работают со своим собственным циклом и им ПЛЕВАТЬ с какой частотой обновляются данные в дампе 10G приемопередатчиком.
Тут понятно? Вот тут Вы неправы!!! Необходимо всегда указывать "Данные обновлены", реализация всегда вариативна - можно ставить сигнал по совпадению контрольной суммы принятого дампа, или отсчитывать байты, но конец сообщения по 10G каналу должен генерировать метку изменения данных. А дальше, все стандартно - новые данные = новый расчет. Если конечно Вам хочется - делайте непрерывно пересчет. Но как ни крутите, один обсчет в каждом из 1000 должен пройти за 64 мкс
|
|
|
|
|
|
|
|
Jan 2 2018, 18:35
|
Местный
Группа: Участник
Сообщений: 221
Регистрация: 6-07-12
Пользователь №: 72 653
|
Цитата(Студент заборстроительного @ Jan 2 2018, 20:40) Абсолютно.
Потому что удаленные устройства относятся к одному и тому же типу.
Но хотя алгоритм одинаковый устройства могут находится в разных состояниях (автомат состояний)
Поэтому для одного узла может потребоваться сделать одно, а для другого - другое (потому что он находится в другом состоянии) 1. Отлично, уже что-то. В любом случае будем считать, что можно написать такой алгоритм обработки, чтобы он мог обслужить любое из устройств, в любом из их внутренних состояний. Итого мы получили некоторый обработчик (будем называть его так). Этот обработчик по своей сути - некоторая логическая схема, включающая в себя конечный автомат, буфер памяти, умножители и прочие функции, которые необходимы для обработки. 2. Итого, что мы имеем. Поток 10Gb разбирается (десериализируется) и раскидывается на N-ное количество обработчиков, далее, на выходе от обработчиков результат собирается обратно (сериализируется) в 10Gb. Теперь нам нужно понять сколько нужно таких обработчиков, чтобы канал не захлебнулся (когда новые данные поступают, а обработка старых не закончилась). В идеальном варианте обработчик должен представлять из себя конвейер, который на каждом такте будет принимать новые данные, D - тактов обрабатывать и в конце выдавать на каждом такте результат. Другими словами у вас получится задержка на обработке в количестве D-тактов. 3. Теперь, чтобы эта мясорубка завелась, нужно прикинуть из чего состоит один обработчик, какие ему нужны ресурсы, сколько тактов уйдёт на обработку одного блока данных от одного устройства. Основные ресурсы для ОДНОГО обработчика: -> количество памяти -> количество FF и LUT (в терминалогии ПЛИС это регистры и логические функции) -> количество DSP блоков, они нужны для математики, если она у вас есть (умножение/деление/корень и тд). Математику лучше делать на DSP иначе потратите много FF и LUT. Ресурсы любой ПЛИС ограничены, как вы понимаете. Чем "легче" будет один обработчик, тем больше их можно будет впихнуть в параллельную обработку, чтобы справиться с 10Gb данных. Если предположить, один обработчик работает с производительностью 100Мбит, то таких нужно будет 100 штук. Чтобы уместить 100 обработчиков + логику для разборки/сборки этого потока, нужно понимать сколько весит один обработчик, т.е. возвращаемся к пункту 3. Я понимаю, что у вас не было опыта работы с ПЛИС, но если вы скажете, что обработчик должен, например: 1. иметь буфер памяти на 1КБ 2. Сделать 10-20 проверок (логических сравнений). 3. пару раз умножить числа разрядностью N x M с аккумуляцией результата где-то... 4. Взять квадратный корень из результата... 5. сложить результат с какой-нибудь фигнёй и таким образом сформировать итоговый результат. То тут хотя бы можно будет прикинуть ресурсы, число тактов и даже может конкретную ПЛИС порекомендовать с запасом по объёму. Иначе - это всё разговоры ни о чём. Если ваш алгоритм требует 100.000 тактов сложной математики, то это ни в какую ПЛИС не влезет с такой пропускной способностью...
Сообщение отредактировал Inanity - Jan 2 2018, 18:48
|
|
|
|
|
|
|
|
Jan 2 2018, 19:07
|
Профессионал
Группа: Свой
Сообщений: 1 817
Регистрация: 14-02-07
Из: наших, которые работают за бугром
Пользователь №: 25 368
|
ИМХУется мне, что ТС вообще будет достаточно одного обработчика - нужно просто обьяснить, как в ПЛИС работает time division multiplexing.
Если у вас обработчик одинаков для всех 1000 устройств, то даже если он включает автоматы состояний с разными состояниями для каждого из них, его все равно очень просто переключать между разными потоками данных от разных устройств используя мультиплексор и демультиплексор.
Т.е на практике 1000 одинаковых обработчиков в ПЛИС никто не пихает, так как полный парралелизм обычно никому не нужен - даже в задаче ТС входные данные не приходят одновременно, а идут по последовательному каналу, один за другим, оставляя огромное время на обработку. Возможно это пытаются донести ТС тоже?
|
|
|
|
|
|
|
|
Jan 2 2018, 19:45
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Александр77 @ Jan 2 2018, 21:01) Вот тут Вы неправы!!!
Необходимо всегда указывать "Данные обновлены" Зачем? По хорошему бы надо. Но можно и без него. Для универсальности Главная проблема не в этом. А в принципе. Можно ли реализовать такую архитектуру Цитата(Александр77 @ Jan 2 2018, 21:01) Но как ни крутите, один обсчет в каждом из 1000 должен пройти за 64 мкс Не обязательно. Критичность скорости реакции зависит от текущего состояния удалённого устройства Да и необязательно цикл обновления дампов будет фиксированным и равным 64мкс. Частота передачи дампов удаленным контроллером может зависеть от текущего состояния устройства. Поэтому какие-то дампы будут обновляться каждый 1,6 мкс, а какие-то раз в 320 мкс P.S. Господа! И реагируйте поспокойней. Я понимаю, что у Вас "мозг взрывается" и с такими сложными задачами Вам, видимо, ещё не приходилось работать. Но что поделать. Цитата(syoma @ Jan 2 2018, 22:07) Т.е на практике 1000 одинаковых обработчиков в ПЛИС никто не пихает, так как полный парралелизм обычно никому не нужен - даже в задаче ТС входные данные не приходят одновременно, а идут по последовательному каналу, один за другим, оставляя огромное время на обработку. Возможно это пытаются донести ТС тоже? Ну вот смотрите. Каждые 1.6мкс приходит новый пакет, содержащий 25 дампов состояния объёмом 64 байта каждый. И какие дампы будут обновлены заранее неизвестно. И скорость реакции заранее неизвестна. Она зависит от того, что пришло. Т.е. от состояния устройства. Поэтому какие-то дампы требуют НЕМЕДЛЕННОЙ реакции, а для каких-то и задержка 320 мкс приемлима
Сообщение отредактировал Студент заборстроительного - Jan 2 2018, 19:53
|
|
|
|
|
|
|
|
Jan 2 2018, 19:55
|
Профессионал
Группа: Свой
Сообщений: 1 700
Регистрация: 2-07-12
Из: дефолт-сити
Пользователь №: 72 596
|
с таким подходом - НЕТ. дело в том что я был в подобной ситуации, и для того чтобы задача легла на архитектуру плис её пришлось переписывать трижды. Уточняя "мелочи" в ТЗ, которые превращались в жирные кляксы, перечеркивая уже проделанную работу. 2 ТСумеете работать с x86 - берите DPDK в руки. это если нужен практический результат. если практический результат пофиг и вы пишете кандидатскую, ничего не зная про предметную область плис - вас на защите как катком раскатают. Цитата Нужно парсить именно в 1000 потоков и данные поступающие со скоростью 10 Гб/с. поясняю: парсинг в плис - это не 1000 раз сравнить один байт с "чем-то". для понимания в чем эффективность ПЛИС - нужно окунуться с головой в поиск по бинарному дереву, когда речь идёт не про сравнение строк, байтов ли чего ещё, а про сравнение СЛЕДУЮЩЕГО ПРИХОДЯЩЕГО БИТА. блин. нового решения по поиску исходя из сравнения очередного бита. за счет этого собственно производительность и достигается. в том числе, если необходима оперативность по передаче команд управления - то это делается до создания системы, и учитывается при создании протокола взаимодействия, но не после. а сейчас я вижу как производится попытка впихнуть некое "распарсивание" без понимания последствий. таким образом, налицо все попытки "скрыть это дерьмо" за какой-нибудь ПЛИС, которая будет никому не понятна, кроме тебя.
--------------------
провоцируем неудовлетворенных провокаторов с удовольствием.
|
|
|
|
|
|
|
|
Jan 2 2018, 21:19
|
Профессионал
Группа: Свой
Сообщений: 1 129
Регистрация: 19-07-08
Из: Санкт-Петербург
Пользователь №: 39 079
|
Цитата(Студент заборстроительного @ Dec 29 2017, 21:54) Вы думаете я совсем дурак?
Вы думаете, что я просто так написал, что даже i7 захлебнётся от такого потока? Да ладно Вам. Давайте на чистоту -- судя по тому, как Вы описали свою задачу в этой теме, Вы вряд ли достаточно компетентны, чтобы знать, что может обработать современный i7. Поэтому коллеги и интересуются у Вас конкретными исходными условиями задачи. Цитата(Студент заборстроительного @ Dec 30 2017, 19:03) Вы зря стараетесь меня "выудить" у меня детали ноу-хау нашей системы управления и "развести", чтобы я забесплатно устроил Вам ликбез по современным АСУТП. Хотя у меня ест чем возразить и дополнить по каждому из перечисленных Вами пунктов. Но я "калач тёртый". И на "слабо рассказать?" не ведусь А ноу-хау о том, как обрабатывать в одной ПЛИС сразу 1000 потоков, и читать/писать из общей памяти, значит хотите выудить забесплатно? Ахаха, как говорится, не выйдет Что мне реально интересно?Почему достаточно адекватные участники форума, так сказать, "ведутся" на такие темы и пытаются помогать ТС (даже диаграммы рисовать не лень ). Просто тут всего 2 варианта: - Автор темы тролль и просто решил постебаться
- Автор не тролль, у него реально есть такая задача, но ему лень напрячься, подумать и расписать условие нормально.
Лично моё мнение, что и в 1-ом и во 2-ом случаях ни в коем разе нельзя помогать автору темы. В первом случае, думаю, это очевидно. А во втором случае, помогая, мы поощеряем умственную лень и отсутствие культуры задания вопросов.
--------------------
|
|
|
|
|
|
|
|
Jan 2 2018, 22:51
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(des333 @ Jan 3 2018, 00:19) ни в коем разе нельзя помогать автору темы Так Вы, насколько мне помниться, и не "помогали"? Тогда чего так возбудились? P.S. И сотрите своё хамство, флуд и "переходы на личности" пока я не обратился к модераторам
Сообщение отредактировал Студент заборстроительного - Jan 2 2018, 22:53
|
|
|
|
|
|
|
|
Jan 3 2018, 12:41
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(krux @ Jan 2 2018, 22:55) дело в том что я был в подобной ситуации, и для того чтобы задача легла на архитектуру плис её пришлось переписывать трижды. Уточняя "мелочи" в ТЗ, которые превращались в жирные кляксы, перечеркивая уже проделанную работу. Ну а я то причем? Не я же Вам ТЗ писал. Да и в этой теме не стоит задача проработать ТЗ вплоть до мельчайших деталей реализации.
Здесь обсуждается сама концепция, архитектура. Возможно ли её реализовать на одной ПЛИС или нет.Ну если Вам трудно мыслить абстрактно, то давайте к конкретике (пример вымышленный /но все же он передает то, чего в реале я хотел бы получить/, поэтому обсуждение "для чего оно нужно?" давайте оставим "за кадром"). Допустим каждый из тысячи узел ПЛИС просто каждые 10 мкс считывает байт за байтом инфу из своего дампа (64 байта) памяти 10G приемника, делает операцию XOR с некоей константой и записывает в память 10G передатчика. Приемник и передатчик никак не синхронизируются между собой и с узлами. Узлы в ПЛИС также работают совершенно независимо от других узлов, 10G-приемника и 10G-передатчика Каждый просто ТУПО делает свою работу не взирая на то, в каком состоянии находятся данные. Теперь. Когда есть конкретика Вы можете оценить сложность реализации такого проекта? Если сильно утрировать, вся система с 1000 устройств на одной стороне 10G эзернет кабеля и 1000 узлов ПЛИС на другой должна работать также, как 1000 удаленных устройств подключенных 1000 кабелями каждый к своему микроконтроллеру. Т.е. вся затея служит для того, чтобы не "тащить" 1000 кабелей и не использовать 1000 микроконтроллеров, а обойтись одним кабелем, ПЛИСиной и 10G приемопередатчиками на обоих сторонах кабеля
Сообщение отредактировал Студент заборстроительного - Jan 3 2018, 12:33
|
|
|
|
|
|
|
|
Jan 3 2018, 13:32
|
Местный
Группа: Участник
Сообщений: 221
Регистрация: 6-07-12
Пользователь №: 72 653
|
Цитата(Студент заборстроительного @ Jan 3 2018, 15:41) Допустим каждый из тысячи узел ПЛИС просто каждые 10 мкс считывает байт за байтом инфу из своего дампа (64 байта) памяти 10G приемника, делает операцию XOR с некоей константой и записывает в память 10G передатчика. Такая задача имеет решение. Но для её решения не нужно 1000 узлов. Ядро 10Gb ethernet выдаёт обычно 64 бита на частоте ~156Мгц. Далее XOR с константой, запись в промежуточный регистр и вывод на ядро передатчика в том же виде (64 бит ~156Мгц). Глубина конвейера - 1 такт, частота работы ~156Мгц. Просто немного смешно. Это такая пушка по воробьям))
Сообщение отредактировал Inanity - Jan 3 2018, 13:34
|
|
|
|
|
|
|
|
Jan 3 2018, 14:15
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Inanity @ Jan 3 2018, 16:32) ...
Просто немного смешно. Это такая пушка по воробьям)) Невнимательно читаете к сожалению столь немногочисленные и неоднозначные условия задачи - отсюда такие поспешные и "смешные" выводы. А TC то и обрадуется. Удачи! Rob.
|
|
|
|
|
|
|
|
Jan 3 2018, 17:40
|
Местный
Группа: Участник
Сообщений: 317
Регистрация: 16-09-17
Пользователь №: 99 334
|
Цитата(Inanity @ Jan 3 2018, 16:32) Такая задача имеет решение. Но для её решения не нужно 1000 узлов.
...
Просто немного смешно. Это такая пушка по воробьям)) Вот опять "снова здорова". Да плевать, что "из пушки по воробьям", плевать, что можно НЕ решать такую задачу. Плевать что с помощью разных хаков можно свести задачу к меньшей размерности. ПЛЕВАТЬ. Мне нужно решить задачу именно так, как я указал в заголовке. Чтобы "обкатать" саму архитектуру И потом, я же сказал, что пример с "ХОR" вымышленный. В реальности же каждый узел ПЛИС будет целым микроконтроллером и обработка дампа будет описываться достаточно большой прогой на Си. Но с точки зрения идеологии построения системы, с точки зрения архитектуры НЕ ВАЖНО, будет ли "программа обработки" просто XOR-ом или большой программой. Это понятно? Я сначала думал для обеспечения "параллелизма" поставить 1000 маленьких микроконтроллеров. Но потом вспомнил, что можно создать эти самые микроконтроллеры внутри одной ПЛИС Теперь понятно "откуда ноги растут"?
Сообщение отредактировал Студент заборстроительного - Jan 3 2018, 17:41
|
|
|
|
|
|
|
|
Jan 3 2018, 18:51
|
Знающий
Группа: Свой
Сообщений: 608
Регистрация: 10-07-09
Из: Дубна, Московская область
Пользователь №: 51 111
|
Цитата(Студент заборстроительного @ Jan 3 2018, 20:40) Теперь понятно "откуда ноги растут"? Понятно что ноги пустились вскачь! Еще на первой странице Вам сказали - более или менее реальную задачу надо обсчитать от начала до конца: что с какой скоростью откуда загружается, что как потом представляется внутри ПЛИС передатчика, как потом восстанавливать данные в ПЛИС приемнике, сколько на это будет затрачено времени, ресурсов и т.д. И в итоге, что будет в выходном потоке куда и как идти. Теперь у Вас появились микроконтроллеры, которые Вы хотите запихнуть в ПЛИС или заменить микроконтроллеры узлами ПЛИС, не суть важно. Нет, так можно сварить только одну кашу - в голове. Разгребайте авгиевы конюшни, рисуйте структуру своей гипотетической системы, расставляйте времена, порядок представления данных, желаемый вид в оконечном устройстве и тогда лишь преступайте к вопросам о "влезет не влезет?".
|
|
|
|
|
|
4 чел. читают эту тему (гостей: 4, скрытых пользователей: 0)
Пользователей: 0

|
|
|