| |
 Сравнение математики altrera vs xilinx Сравнение математики altrera vs xilinx, по мотивам темы о Timing Errors |
|
|
|
|
 Jan 26 2012, 18:22 Jan 26 2012, 18:22
|
Вечный ламер

Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453

|
Уважаемый bogaev_roman предложил сравнить как синтезируется и разводится математика у разных вендоров. Вот для затравки пример. Генератор шума + цепочка FIR фильтров, символьная == тактовой Чип сыклон 3, 25 ка, i7, фильтр симметричный, 93 го порядка(94 коэффициента), задержка выхода фильтра 4 такта, разрядность данных/коэффициентов 18 бит, сумматоров 36 бит(усиление фильтра +18 бит, подобранно коэффициентами), все на чистой логике, без ДСП слайсов. Задача выжать тактовую в 100МГц, для самого тормозного режима (slow 85). Оптимизация при синтезе по ресурсу. Все остальные настройки по дефолту. Временной анализатор TimeQuest. Результаты для ква 9.1сп2 1 фильтр : LE 5814(24%)/108.83MHz 2 фильтра : LE 11588(47%)/105.94MHz 3 фильтра : LE 17368(71%)/105.73MHz 4 фильтра : не влезло фитер вывалился с сообщением Error: Fitter requires 1764 LABs to implement the project, but the device contains only 1539 LABs. хотя по ресурсу запас еще был. Думаю что дело связано с 32-х битным LAB, на которые плохо ложатся 36 битные сумматоры уменьшим разрядность данных до 14 ти бит, коэффициентов оставим 18, сумматоры 32 бита. 5 фильтров : не влезло, фиттер вывалился с сообщением Error: Fitter requires 1545 LABs to implement the project, but the device contains only 1539 LABs. уменьшим данные до 13 ти бит (уж больно лень фильтр пересчитывать) 5 фильтров : LE 22867 (93%)/117.07MHz сорцы и квартусовский архивированный проект в приложении. интересны результаты спартна3/3е/3А/6 сравнимого объема, при сравнимой заполненности  ЗЫ. Если общественность попросит, то фильтр таки пересчитаю на 16 ти битные коэффициенты. И да, фильтр не сферический конь в вакууме, а из рабочего проекта.
--------------------
|
|
|
|
|
|
2 страниц  1 2 >
1 2 >
|
 |
Ответов
(1 - 26)
|
|
Jan 27 2012, 19:24
|
Знающий
Группа: Свой
Сообщений: 614
Регистрация: 12-06-09
Из: рядом с Москвой
Пользователь №: 50 219
|
Цитата(des00 @ Jan 26 2012, 22:22)  ... интересны результаты спартна3/3е/3А/6 сравнимого объема, при сравнимой заполненности ... Судя по жуткой ругани XST - это систем верилог. Так что, придётся ждать любителей симплифая или прецижина. 
|
|
|
|
|
|
|
|
Jan 28 2012, 17:16
|
Профессионал
Группа: Участник
Сообщений: 1 075
Регистрация: 30-09-05
Пользователь №: 9 118
|
Цитата(des00 @ Jan 28 2012, 20:13) нда, активность форумчан таки призывает поставить ISE и провести анализ самостоятельно, а жаль %( М/б и Icarus Verilog-а и тп достаточно будет, там несколько ошибок в синтаксисе, имхо. Ну а по поводу активности, так было и будет - если нужно вникать - активность нулевая. Просил в свое время прогнать N-ферзей на Nios/MicroBlaze, чтобы сравнить сосвоим софт-процессором, исходник на Си выложил - активность тоже 0-я.
|
|
|
|
|
|
|
|
Jan 28 2012, 21:46
|
Знающий
Группа: Участник
Сообщений: 835
Регистрация: 9-08-08
Из: Санкт-Петербург
Пользователь №: 39 515
|
Прогнал тестирование для одного канала на spartan3e(xc3s500e-4) и ecp2m(LFE2M50EFPBGA900-6). Для пяти каналов слишком долго утрамбовывать . В исходном варианте spartan3e получился на 94МГц. Добавил к умножителю дополнительную ступень конвейера, правда, без переделки остального алгоритма, так что получилось не совсем эквивалентно, но это не существенно, IMHO. В результате спартан прибавил до 137МГц, на ecp2m вышло 170МГц(без конвейера на нём не смотрел). А вот Циклону(скорее Симплифаю для Циклона) конвейер только помешал - немного упала частота и заметно увеличилось число LE. Причём для Циклона с Симплифаем получились те же 117МГц. Полные отчёты по занятым ресурсам есть в аттаче, везде около 5000 LE, но это нельзя выразить одной-двумя цифрами. Lattice расходует немного побольше, так как там неэффективно используются арифметические блоки - в каждом сумматоре бесполезно пропадают 1 или 2 LE. Отчёт по ecp2m: Number of registers: 4087 PFU registers: 4074 PIO registers: 13 Number of SLICEs: 3102 out of 23832 (13%) SLICEs(logic/ROM): 3102 out of 19620 (16%) SLICEs(logic/ROM/RAM): 0 out of 4212 (0%) As RAM: 0 out of 4212 (0%) As Logic/ROM: 0 out of 4212 (0%) Number of logic LUT4s: 565 Number of distributed RAM: 0 (0 LUT4s) Number of ripple logic: 2429 (4858 LUT4s) Number of shift registers: 0 Total number of LUT4s: 5423 Number of external PIOs: 14 out of 410 (3%) Number of PIO IDDR/ODDR: 0 Number of PIO FIXEDDELAY: 0 Number of DQSDLLs: 0 out of 2 (0%) Number of 3-state buffers: 0 Number of PLLs: 0 out of 8 (0%) Number of DLLs: 0 out of 2 (0%) Number of block RAMs: 0 out of 225 (0%) Number of CLKDIVs: 0 out of 2 (0%) Number of GSRs: 0 out of 1 (0%) JTAG used : No Readback used : No Oscillator used : No Startup used : No Notes:- 1. Total number of LUT4s = (Number of logic LUT4s) + 2*(Number of distributed RAMs) + 2*(Number of ripple logic) 2. Number of logic LUT4s does not include count of distributed RAM and ripple logic. А по Spartan он, извиняюсь, в HTML, поэтому только в аттаче. Использовался Synplify Pro E-2010.09, ISE 13.2, ispLever 7.1sp1. Интересно, можно ли как-нибудь воспитать Циклон, чтобы он тоже ускорялся от конвейера?
|
|
|
|
|
|
|
|
Jan 29 2012, 02:11
|

МедвеД Инженер I
Группа: Свой
Сообщений: 816
Регистрация: 21-10-04
Пользователь №: 951
|
Цитата(des00 @ Jan 29 2012, 01:13) нда, активность форумчан таки призывает поставить ISE и провести анализ самостоятельно, а жаль %( выходной как бы..а дома гадости не держим ISE...в пн всё в пн. Цитата(Leka @ Jan 29 2012, 02:16) М/б и Icarus Verilog-а и тп достаточно будет, там несколько ошибок в синтаксисе, имхо.
Ну а по поводу активности, так было и будет - если нужно вникать - активность нулевая.
Просил в свое время прогнать N-ферзей на Nios/MicroBlaze, чтобы сравнить сосвоим софт-процессором, исходник на Си выложил - активность тоже 0-я. хм...а кому это надо то в первую очередь? вы бы и сравнили сами, выложили бы результаты и тогда народ и подтянулся бы...наверное 
--------------------
Cogito ergo sum
|
|
|
|
|
|
|
|
Jan 29 2012, 09:39
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Timmy @ Jan 28 2012, 15:46) Прогнал тестирование для одного канала на spartan3e(xc3s500e-4) и ecp2m(LFE2M50EFPBGA900-6).
Полные отчёты по занятым ресурсам есть в аттаче, везде около 5000 LE, но это нельзя выразить одной-двумя цифрами. Lattice расходует немного побольше, так как там неэффективно используются арифметические блоки - в каждом сумматоре бесполезно пропадают 1 или 2 LE. Спасибо за участие, но мне интересен не синтез одного фильтра, т.к. этот вопрос легко решается на любой платформе. А именно деградация производительности математических блоков при заполненности ПЛИС под 80-90%. Т.к. по моему опыту проблемы с хилыми начинаются именно здесь (подозреваю что из-за разводки). Т.е. интересны не критические пути, а кол-во фильтров, ресурс в попугаях и % заполненности плис ну и тактовая. Как видно по альтере, заполненность плис слабо влияет на тактовую. По времени очень странно, 25ку с 5ю фильтрами квартус собирал минут 8 (на атлоне 640, 4 гига озу, но под хренью).
--------------------
|
|
|
|
|
|
|
|
Jan 29 2012, 12:41
|
Знающий
Группа: Свой
Сообщений: 614
Регистрация: 12-06-09
Из: рядом с Москвой
Пользователь №: 50 219
|
Цитата(des00 @ Jan 29 2012, 13:39) Спасибо за участие, но мне интересен не синтез одного фильтра, т.к. этот вопрос легко решается на любой платформе. А именно деградация производительности математических блоков при заполненности ПЛИС под 80-90%. Т.к. по моему опыту проблемы с хилыми начинаются именно здесь (подозреваю что из-за разводки). Т.е. интересны не критические пути, а кол-во фильтров, ресурс в попугаях и % заполненности плис ну и тактовая. Как видно по альтере, заполненность плис слабо влияет на тактовую.
По времени очень странно, 25ку с 5ю фильтрами квартус собирал минут 8 (на атлоне 640, 4 гига озу, но под хренью). После перевода исходников в Верилог ситуация улучшилась, но не сильно. ISE 12.4. Захотел собрать на XC6SLX25 XST начал ругаться на: 1) function automatic integer clogb2 2) task automatic ScramblerBit после часа ковыряний добавил в их тело begin и end и вроде проверка синтаксиса перестала ругаться. Но XST вконце синтеза вылетал с необъяснимой ошибкой и советовал создать webcase. При определённых настройках синтез всётаки состоялся - но DSP слайсы отключить не удалось (12 из 38 он всё-таки использовал) (хотя стояло DSP slice utilization ratio = 0 и USE DSP slice = no) - и с таймингами полсе PAR было всё плохо - всего 16нс (62МГц) -и все ошибки по таймингам были на выходах DSP слайсов. Заменил ПЛИС в проекте на "безДСПслайсовую" XC3S1400A и получил ошибку синтаксиса: "ERROR:HDLCompilers:168 - "scrambler.v" line 76 No signals referenced in statement with implicit sensitivity list" эту ошибку пофиксить так и не удалось - при удалении 76 строчки появляется ещё толпа синтаксических ошибок.
|
|
|
|
|
|
|
|
Jan 30 2012, 15:17
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
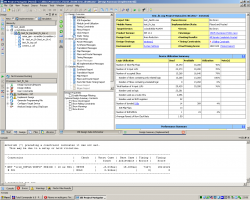
Цитата(des00 @ Jan 29 2012, 07:07) понятно, найду у кого из коллег стоит ise и добьюсь синтезируемости. потом выложу %) версия для хилых, собирается в 13.4 Цитата(VladimirB @ Jan 30 2012, 08:44) форум глючит - появляются посты в теме с синтезируемымии исходниками и исчезают это не форум глючит, это я сорцы не те выкладывал, и что бы потом небыло обвинений в том, что выложил не то, по быстрому стирал %) пришлось переделать скремблер, не понимает исе тасков по нормальному %( сделал в лоб, без красивостей + выкинул из фира не нужную функцию %) Взял спартан 3e 1600 - 4, как наиболее близкий по количеству LE к сабжевому сыклону. 33 тыс ~= 25 тыс. Разрядность данных 13 бит, коэффициентов 18, аккумуляторов 31. Констрейны Код TIMESPEC TS_false_path = FROM "PADS" TIG;
TIMESPEC TS_false_path = TO "PADS" TIG;
NET "iclk" TNM_NET = iclk;
TIMESPEC TS_iclk = PERIOD "iclk" 10 ns HIGH 50%; 1 фильтр Slice 3337(22%)/79.847MHz 2 фильтра Slice 6677(45%)/74.063MHzMHz 3 фильтра Slice 10004(67%)/59.748MHzMHz 4 фильтра Slice 13331(90%)/63.464MHzMHz заняный результат %)
--------------------
|
|
|
|
|
|
|
|
Jan 30 2012, 20:24
|
Знающий
Группа: Свой
Сообщений: 614
Регистрация: 12-06-09
Из: рядом с Москвой
Пользователь №: 50 219
|
Цитата(des00 @ Jan 30 2012, 19:17) 1 фильтр Slice 3337(22%)/79.847MHz
2 фильтра Slice 6677(45%)/74.063MHzMHz
3 фильтра Slice 10004(67%)/59.748MHzMHz
4 фильтра Slice 13331(90%)/63.464MHzMHz Да для 90нм 3-го спартана примерно так и получается для 4-х фильтров и XC3SD1800A-4 скрин в приложении. Правда без TIGов, поэтому и результат хуже. А 45нм Spartan-6 мне так и не удалось раскочегарить, что ни делал - ISE упорно вставляет DSP слайсы и сам на них ругается (для одного фильтра тайминги на выходе незарегистренных DSPслайсов плохо сходятся, а для четырёх - синтезатор вставляет DSP48 больше чем есть в Спартане и MAP завершается с сообщением о превышении числа DSP48) - видимо версия ISE не та. А Циклон 3 помнится 65нм + интерконнект получше + Кактус получше.
|
|
|
|
|
|
|
|
Jan 31 2012, 01:03
|
МедвеД Инженер I
Группа: Свой
Сообщений: 816
Регистрация: 21-10-04
Пользователь №: 951
|
Цитата(VladimirB @ Jan 31 2012, 05:24) .....
А 45нм Spartan-6 мне так и не удалось раскочегарить, что ни делал - ISE упорно вставляет DSP слайсы и сам на них ругается (для одного фильтра тайминги на выходе незарегистренных DSPслайсов плохо сходятся, а для четырёх - синтезатор вставляет DSP48 больше чем есть в Спартане и MAP завершается с сообщением о превышении числа DSP48) - видимо версия ISE не та.
.... Spartan-6 25 тоже не выходит каменный цветок. версия исе13.4. но уменя MAP вылетает с жалобами на "..The number of logical carry chain blocks exceeds the capacity for the target device. " а вы чем синтезировали? я симплифаем. +up. пробовал xst, тот же результат.
--------------------
Cogito ergo sum
|
|
|
|
|
|
|
|
Jan 31 2012, 02:38
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(VladimirB @ Jan 30 2012, 15:24) А 45нм Spartan-6 мне так и не удалось раскочегарить, что ни делал - ISE упорно вставляет DSP слайсы и сам на них ругается (для одного фильтра тайминги на выходе незарегистренных DSPслайсов плохо сходятся, а для четырёх - синтезатор вставляет DSP48 больше чем есть в Спартане и MAP завершается с сообщением о превышении числа DSP48) - видимо версия ISE не та. хммм, в ква можно было бы lpm_mult влепить и поставить синтез на логике, а в исе, если мне память не изменяет надо делать каждый умножитель в отдельности. попробую на досуге. Цитата А Циклон 3 помнится 65нм + интерконнект получше + Кактус получше. то что сыклон 3 быстрее спорить глупо, интересна именно деградация тактовой при заполненных чипах.
--------------------
|
|
|
|
|
|
|
|
Jan 31 2012, 05:40
|
Знающий
Группа: Свой
Сообщений: 614
Регистрация: 12-06-09
Из: рядом с Москвой
Пользователь №: 50 219
|
Цитата(des00 @ Jan 31 2012, 05:38) хммм, в ква можно было бы lpm_mult влепить и поставить синтез на логике, а в исе, если мне память не изменяет надо делать каждый умножитель в отдельности. попробую на досуге.
то что сыклон 3 быстрее спорить глупо, интересна именно деградация тактовой при заполненных чипах. Дык умножителей там много - не помню, вроде порядка 60 штук на фильтр, а XST упорно вставляет 12 DSP48 слайсов на 1 фильтр (для чего я так и неразобрался). Если ему разрешить вместо умножителей DSP48 ставить - то он и 1 фильтр не хочет для 6-го Спартана парить. А деградация для третьего спартана 10-15% - это очень хорошо, я думал будет хуже.
|
|
|
|
|
|
|
|
Feb 2 2012, 06:43
|
iBuilder©
Группа: Свой
Сообщений: 519
Регистрация: 14-07-04
Из: Минск
Пользователь №: 322
|
Цитата(RobFPGA @ Feb 1 2012, 21:42) Я думаю что основной проблемой и в тоже время преимуществом для Xilinx является однородна структура кристалла.
Отсюда и появляется жуткая неоднозначность при большом заполнении кристалла - так как MAP и PAR по сути рандомный начальный расклад
с последующей попыткой оптимизации. При равномерной структуре алгоритму предоставляется слишком большая свобода часто заводящая оный в тупик.
Очень часто на тяжелых (по времянке и заполнению) проектах достаточно слегка ограничить вольности задав разбиение на блоки и зафиксировав положение для ряда ключевых узлов и время MAP/PAR уменьшается на пару порядков! Не зря Xilinx сейчас так активно двигает PlanAhead
В Altera структура кристалла изначальна поделена на крупные блоки что значительно уменьшает число вариантов при MAP/PAR. Не думаю что то всё так как Вы сказали. Не вижу принципиальных проблем сделать те-же разбиения виртуально при синтезе. В конце концов альтере тоже нужно синтех делать с учётом архитектуры, а никто не отменял синтех в заданном базисе, и этот базис может быть как реальным так виртуальным. Скорее всего просто Хилые отстают в крутизне реализации самих алгоритмов под свои чипы. Возможно Альтера разработку чипа и алгоритмов синтеза делает более комллексно, а хилые по принципу - сделаем чип, а синтез как нибудь "под чип подкрутим".
|
|
|
|
|
|
|
|
Feb 2 2012, 10:08
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Builder @ Feb 2 2012, 08:43) Не думаю что то всё так как Вы сказали. Не вижу принципиальных проблем сделать те-же разбиения виртуально при синтезе. Ну Xilinx так и делает - но чтобы возмущенные юзеры не ворчали что им не дают рулить процессом это разбиение на них же и возлагается . Я давно, в одном проекте, потратил неделю на эксперименты с различными опциями при MAP/PAR. Причем синтез был сделан один раз и не менялся в процессе экспериментов. Чип был VirtexE-3200 - обработка данных SAR радара забит LUT-98%. RAM-100%, 80% обработки работало на 150 MHz. В начале - как говорится в лоб - время MAP/PAR - 2 Суток!!!! Поиск удачного начального seed - время MAP/PAR уменьшилось на до 8-10 часов. А как только задал AREA_GROUP для ряда крупных функциональных блоков и зафиксировал их положение на кристалле то время MAP/PAR стало меньше 1 часа !!! А какая красивая картинка была в FloorPlanere при этом! С тех пор методика разбиения проекта на AREA_GROUP оправдывала себя много раз. Для простых же проектов - не критичных по частоте и заполнению это особенно и не нужно. Успехов! Rob.
|
|
|
|
|
|
|
|
Feb 2 2012, 23:09
|

Знающий
Группа: Свой
Сообщений: 618
Регистрация: 7-06-08
Из: USSR
Пользователь №: 38 121
|
Цитата(RobFPGA @ Feb 2 2012, 15:08) Приветствую! Ну Xilinx так и делает - но чтобы возмущенные юзеры не ворчали что им не дают рулить процессом это разбиение на них же и возлагается . Я давно, в одном проекте, потратил неделю на эксперименты с различными опциями при MAP/PAR. Причем синтез был сделан один раз и не менялся в процессе экспериментов. Чип был VirtexE-3200 - обработка данных SAR радара забит LUT-98%. RAM-100%, 80% обработки работало на 150 MHz. В начале - как говорится в лоб - время MAP/PAR - 2 Суток!!!! Поиск удачного начального seed - время MAP/PAR уменьшилось на до 8-10 часов. А как только задал AREA_GROUP для ряда крупных функциональных блоков и зафиксировал их положение на кристалле то время MAP/PAR стало меньше 1 часа !!! А какая красивая картинка была в FloorPlanere при этом! С тех пор методика разбиения проекта на AREA_GROUP оправдывала себя много раз. Для простых же проектов - не критичных по частоте и заполнению это особенно и не нужно. Успехов! Rob. какой версией ISE делался данный эксперимент?
--------------------
Нажми на кнопку - получишь результат, и твоя мечта осуществится
|
|
|
|
|
|
|
|
Feb 3 2012, 11:50
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(BlackOps @ Feb 3 2012, 01:09) какой версией ISE делался данный эксперимент? Если не ошибаюсь то 7я вроде. Давно это было. Успехов! Rob.
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|