jcxz, всё верно, чужие библиотеки. Портирую mp3-декодер Helix. В очередной раз)
Цитата(jcxz @ Aug 28 2017, 18:49)

Если Вам нужны только старшие 32 бита (как следует из этого макроса), то всё просто:
#define MULSHIFT32(x, y) __SMMUL(x, y)
Спасибо. Даже забыл, что в IAR есть intrinsic-ассемблер, как всё просто оказывается.
Цитата(VladislavS @ Aug 28 2017, 19:14)
Дарю
Код
#define MULSHIFT32(arg1, arg2) (((int64_t)(int32_t)(arg1)*(int32_t)(arg2))>>32)
Спасибо за подарок.
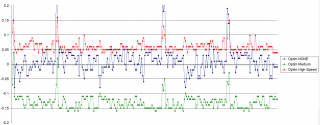
Прогнал оба варианта на разных уровнях оптимизации. По оси ординат разница выполнения алгоритма в мс. Time( __SMMUL(x, y)) - Time((((int64_t)(int32_t)(arg1)*(int32_t)(arg2))>>32)). Без оптимизации паритет, на умеренной оптимизации использование интринсик-функции __SMMUL(x, y) оказывается более быстрым, в случае максимальной оптимизации по скорости выигрывает решение от VladislavS. Разница не существенная, в районе 1%.
Дизассемблер для каждой из реализаций. Алгоритм раскладывается в одни и те же инструкции, но с использованием разных РОН.
Код
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59830: 0x1979 ADDS R1, R7, R5
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59832: 0x1bed SUBS R5, R5, R7
0x59834: 0xf852 0x7b04 LDR.W R7, [R2], #0x4
0x59838: 0xfb57 0xfc05 SMMUL R12, R7, R5
0x5983c: 0xea4f 0x0c4c LSL.W R12, R12, #1
Код
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59906: 0x1978 ADDS R0, R7, R5
b0 = a0 + a7; b7 = MULSHIFT32(*cptr++, a0 - a7) << 1;
0x59908: 0xf853 0xcb04 LDR.W R12, [R3], #0x4
0x5990c: 0x1bed SUBS R5, R5, R7
0x5990e: 0xfb5c 0xfc05 SMMUL R12, R12, R5
0x59912: 0xea4f 0x0c4c LSL.W R12, R12, #1
И хотя первоначальный вопрос про синтаксис макросов остался открытым, но задача решена другими средствами. Спасибо за помощь!

















 Aug 28 2017, 13:42
Aug 28 2017, 13:42