Цитата(faa @ Apr 7 2018, 16:00)

На GPU в потоке не получилось - думали-смотрели, но не влезло (а может не осилили). Пришлось плисоводить

.
Подсознательно кажется с GPU больше "подводных камней" и на начальном этапе они могут быть не видны. Нет прозрачности в пути ADC->PCIe->GPU->PCIe->Host.
Цитата(faa @ Apr 7 2018, 16:00)
Сейчас на Kintex Ultrascale 16 реальных каналов (семплирование ~118МГц) получилось на 4М бинов по ~7Гц с перекрытием 25%.
Пробежимся по структуре?
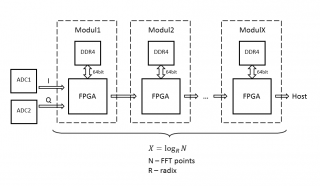
RobFPGA, подключайтесь. Набросал по-быстрому схему, могу ошибаться, поправляйте:
Подумал, действительно, закладываться на один "жирный" FPGA смысла не имеет. В модульной структуре легче обеспечить большую ширину памяти, ПО модулей может быть одинаковым, соответственно меньше времени на компиляцию и верификацию, выше частота работы. Последовательная структура мне показалась более удобной с точки зрения передачи данных (pipeline). Есть два вопроса:
1. Ширина полосы памяти на один модуль.
По самым оптимистичным оценкам достаточно обеспечить тройную (запись, чтение, коэффициенты) ширину входной полосы с ADC, приведенную к ширине внутренней арифметики.
2. Перектрытие.
За счет чего обеспечить? За счет увеличения кол-ва модулей или гарантии более высокой скорости обработки?

















 Apr 4 2018, 21:05
Apr 4 2018, 21:05