| |
 Производительность современных GPU при вычислении FFT Производительность современных GPU при вычислении FFT |
|
|
|
 |
Ответов
|
|
 Apr 7 2018, 13:00 Apr 7 2018, 13:00
|
Знающий

Группа: Свой
Сообщений: 726
Регистрация: 14-09-06
Из: Москва
Пользователь №: 20 394

|
Вот тут английский самоделкин на GPU от Raspberry Pi БПФ-ит. Можно прикинуть производительность для "толстых" GPU. Разбивает на мелкие с доворотом между ними. Мы таким способом делали в ПЛИС БПФ на 16М. 8 реальных каналов на XC6V240, 4 потока, разбор. Частота семплирования 80МГц, на выходе 8 комплексных спектров в 8М бинов по ~5Гц с перекрытием 50%. Сейчас на Kintex Ultrascale 16 реальных каналов (семплирование ~118МГц) получилось на 4М бинов по ~7Гц с перекрытием 25%. На GPU в потоке не получилось - думали-смотрели, но не влезло (а может не осилили). Пришлось плисоводить  .
|
|
|
|
|
|
|
|
Apr 7 2018, 16:44
|
Узкополосный широкополосник
Группа: Свой
Сообщений: 2 316
Регистрация: 13-12-04
Из: Moscow
Пользователь №: 1 462
|
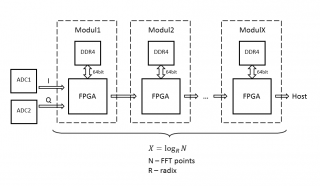
Цитата(faa @ Apr 7 2018, 16:00)  На GPU в потоке не получилось - думали-смотрели, но не влезло (а может не осилили). Пришлось плисоводить . Подсознательно кажется с GPU больше "подводных камней" и на начальном этапе они могут быть не видны. Нет прозрачности в пути ADC->PCIe->GPU->PCIe->Host. Цитата(faa @ Apr 7 2018, 16:00) Сейчас на Kintex Ultrascale 16 реальных каналов (семплирование ~118МГц) получилось на 4М бинов по ~7Гц с перекрытием 25%. Пробежимся по структуре? RobFPGA, подключайтесь. Набросал по-быстрому схему, могу ошибаться, поправляйте:
Подумал, действительно, закладываться на один "жирный" FPGA смысла не имеет. В модульной структуре легче обеспечить большую ширину памяти, ПО модулей может быть одинаковым, соответственно меньше времени на компиляцию и верификацию, выше частота работы. Последовательная структура мне показалась более удобной с точки зрения передачи данных (pipeline). Есть два вопроса: 1. Ширина полосы памяти на один модуль. По самым оптимистичным оценкам достаточно обеспечить тройную (запись, чтение, коэффициенты) ширину входной полосы с ADC, приведенную к ширине внутренней арифметики. 2. Перектрытие. За счет чего обеспечить? За счет увеличения кол-ва модулей или гарантии более высокой скорости обработки?
|
|
|
|
|
|
|
|
Apr 7 2018, 17:57
|
Знающий
Группа: Свой
Сообщений: 726
Регистрация: 14-09-06
Из: Москва
Пользователь №: 20 394
|
Цитата(rloc @ Apr 7 2018, 19:44) Есть два вопроса:
1. Ширина полосы памяти на один модуль.
По самым оптимистичным оценкам достаточно обеспечить тройную (запись, чтение, коэффициенты) ширину входной полосы с ADC, приведенную к ширине внутренней арифметики.
2. Перектрытие.
За счет чего обеспечить? За счет увеличения кол-ва модулей или гарантии более высокой скорости обработки? 16 каналов, 4 АЦП по 4 канала, квадратуры в цифре с децимацией на 4 (на 3 не пролезли по памяти). ПЛИС одна. Память: 4 контроллера DDR3-1600 - 32х, 64х, 64х, 32х; HMC - полтора линка (х8 - слева, х16 - справа ПЛИС). Наружу: PCIe Gen3 ext x8, PCIe Gen3 ext x4, HMC - два линка х16, serdes - два линка х4 (один слева, другой справа ПЛИС). Как-то так. Контроллеры DDR3 - физика из MIG, логика своя. За 6,5 мкс пишет/читает 256 отсчетов по всем каналам, регенерация, калибровка VT. Перекрытие 25%, в первый буфер пишем 192 отсчета, читаем 256. Из шишек: замирание PCIe, при пиковой (расчетной) для Gen3 x8 более 6ГБ/сек (даже при TLP128) для 4.8ГБ/сек имели некоторые неудобства. Пришлось городить эластик-буфер и резать лишнее  . Скорость DDR3 можно поднять (ПЛИС позволяет), тогда проходит и децимация на 3,5. ЗЫ: На общие вопросы могу здесь ответить, подробности - лучше в личку.
|
|
|
|
|
|
Сообщений в этой теме
 rloc Производительность современных GPU при вычислении FFT Apr 4 2018, 21:05 rloc Производительность современных GPU при вычислении FFT Apr 4 2018, 21:05 Serg76 Занимался подобной проблемой, результат неутешител... Apr 5 2018, 06:27 Serg76 Занимался подобной проблемой, результат неутешител... Apr 5 2018, 06:27  rloc Цитата(Serg76 @ Apr 5 2018, 09:27) главно... Apr 5 2018, 07:00 _pv ещё новые шарки SC58x у AD c FFT ускорителями обещ... Apr 5 2018, 08:59 rloc На DSP закладываться опасно, основная проблема - в... Apr 5 2018, 09:22 Serg76 Цитата(rloc @ Apr 5 2018, 10:00) Перейду ... Apr 5 2018, 10:43 krux длинные поточные FFT удобно делать на ПЛИСах.
под ... Apr 5 2018, 06:40 _pv за/против GPU ещё наверное зависит от того есть ли... Apr 5 2018, 13:09 rloc В моем случае данных в хосте изначально нет, снача... Apr 5 2018, 13:23 _pv 2 квадратурных канала сбора данных по 16 бит, част... Apr 5 2018, 13:44 RobFPGA Приветствую!
Цитата(_pv @ Apr 5 2018, 16... Apr 5 2018, 14:29 rloc Цитата(_pv @ Apr 5 2018, 16:44) 2*16*500 ... Apr 5 2018, 17:21 RobFPGA Приветствую!
Цитата(rloc @ Apr 5 2018, 2... Apr 5 2018, 18:20 rloc Цитата(RobFPGA @ Apr 5 2018, 21:20) Моско... Apr 6 2018, 05:49 stealth-coder GPU предусматривают 2 режима обмена данными - синх... Apr 6 2018, 15:18 rloc Цитата(stealth-coder @ Apr 6 2018, 18... Apr 6 2018, 15:54 stealth-coder Цитата(rloc @ Apr 6 2018, 18:54) Так нужн... Apr 7 2018, 08:15 Serg76 Цитата(stealth-coder @ Apr 7 2018, 11... Apr 7 2018, 11:49 Serg76 Цитата(stealth-coder @ Apr 6 2018, 18... Apr 6 2018, 19:07 RobFPGA Приветствую!
Цитата(rloc @ Apr 7 2018, 19... Apr 7 2018, 20:20 rloc Цитата(RobFPGA @ Apr 7 2018, 23:20) будем... Apr 7 2018, 22:45 RobFPGA Приветствую!
Цитата(rloc @ Apr 8 2018, 0... Apr 7 2018, 23:25 faa Цитата(rloc @ Apr 8 2018, 01:45) Очень тя... Apr 8 2018, 10:13 blackfin Цитата(rloc @ Apr 7 2018, 19:44) Подумал,... Apr 8 2018, 04:52 rloc Цитата(blackfin @ Apr 8 2018, 07:52) Pipe... Apr 8 2018, 07:18 thermit Странные показатели у вас.
gtx1060 complex fft 64... Apr 7 2018, 13:04 blackfin Цитата(thermit @ Apr 7 2018, 16:04) Стран... Apr 7 2018, 13:34 thermit Очевидно, что не успевает.
Честно говоря, обработ... Apr 7 2018, 13:59 rloc Цитата(Serg76 @ Apr 5 2018, 09:27) главно... Apr 5 2018, 07:00 _pv ещё новые шарки SC58x у AD c FFT ускорителями обещ... Apr 5 2018, 08:59 rloc На DSP закладываться опасно, основная проблема - в... Apr 5 2018, 09:22 Serg76 Цитата(rloc @ Apr 5 2018, 10:00) Перейду ... Apr 5 2018, 10:43 krux длинные поточные FFT удобно делать на ПЛИСах.
под ... Apr 5 2018, 06:40 _pv за/против GPU ещё наверное зависит от того есть ли... Apr 5 2018, 13:09 rloc В моем случае данных в хосте изначально нет, снача... Apr 5 2018, 13:23 _pv 2 квадратурных канала сбора данных по 16 бит, част... Apr 5 2018, 13:44 RobFPGA Приветствую!
Цитата(_pv @ Apr 5 2018, 16... Apr 5 2018, 14:29 rloc Цитата(_pv @ Apr 5 2018, 16:44) 2*16*500 ... Apr 5 2018, 17:21 RobFPGA Приветствую!
Цитата(rloc @ Apr 5 2018, 2... Apr 5 2018, 18:20 rloc Цитата(RobFPGA @ Apr 5 2018, 21:20) Моско... Apr 6 2018, 05:49 stealth-coder GPU предусматривают 2 режима обмена данными - синх... Apr 6 2018, 15:18 rloc Цитата(stealth-coder @ Apr 6 2018, 18... Apr 6 2018, 15:54 stealth-coder Цитата(rloc @ Apr 6 2018, 18:54) Так нужн... Apr 7 2018, 08:15 Serg76 Цитата(stealth-coder @ Apr 7 2018, 11... Apr 7 2018, 11:49 Serg76 Цитата(stealth-coder @ Apr 6 2018, 18... Apr 6 2018, 19:07 RobFPGA Приветствую!
Цитата(rloc @ Apr 7 2018, 19... Apr 7 2018, 20:20 rloc Цитата(RobFPGA @ Apr 7 2018, 23:20) будем... Apr 7 2018, 22:45 RobFPGA Приветствую!
Цитата(rloc @ Apr 8 2018, 0... Apr 7 2018, 23:25 faa Цитата(rloc @ Apr 8 2018, 01:45) Очень тя... Apr 8 2018, 10:13 blackfin Цитата(rloc @ Apr 7 2018, 19:44) Подумал,... Apr 8 2018, 04:52 rloc Цитата(blackfin @ Apr 8 2018, 07:52) Pipe... Apr 8 2018, 07:18 thermit Странные показатели у вас.
gtx1060 complex fft 64... Apr 7 2018, 13:04 blackfin Цитата(thermit @ Apr 7 2018, 16:04) Стран... Apr 7 2018, 13:34 thermit Очевидно, что не успевает.
Честно говоря, обработ... Apr 7 2018, 13:59
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|