Приветствую!
Цитата(rloc @ Apr 7 2018, 19:44)

Подсознательно кажется с GPU больше "подводных камней" и на начальном этапе они могут быть не видны.
Нет прозрачности в пути ADC->PCIe->GPU->PCIe->Host.
Вот вот ...
Цитата(rloc @ Apr 7 2018, 19:44)
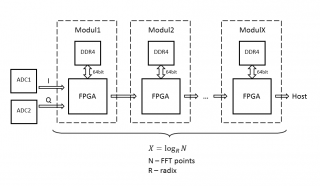
Пробежимся по структуре? RobFPGA, подключайтесь. Набросал по-быстрому схему, могу ошибаться, поправляйте:
Нее - я предпочитаю медленно спустится с горы и ...

Цитата(rloc @ Apr 7 2018, 19:44)
Подумал, действительно, закладываться на один "жирный" FPGA смысла не имеет. В модульной структуре легче обеспечить большую ширину памяти, ПО модулей может быть одинаковым, соответственно меньше времени на компиляцию и верификацию, выше частота работы. Последовательная структура мне показалась более удобной с точки зрения передачи данных (pipeline). Есть два вопроса:
Еще не знаем что делать но будем делать универсально и модульно

!
Цитата(rloc @ Apr 7 2018, 19:44)
1. Ширина полосы памяти на один модуль.
По самым оптимистичным оценкам достаточно обеспечить тройную (запись, чтение, коэффициенты) ширину входной полосы с ADC, приведенную к ширине внутренней арифметики.
2. Перектрытие.
За счет чего обеспечить? За счет увеличения кол-ва модулей или гарантии более высокой скорости обработки?
Смотрим что есть на входе FFT=64K, I,Q=16 6ит, для таких N коэффициенты нужны не меньше 20 бит.
Начинаем кумекать как можно это считать - например смотрим структуру FFT R22.
Если не забыл то для N точек нужно N слов (I,Q) памяти для данных и N/4 слов коэффициентов.
Грубо - надо 64K * 4 * 1.5 + 16K * 5 = 384 + 80 KByte, + 64 KByte + таблица для окна. ~ 528 KByte.
Влезет даже в средний чип. Если нужно перекрытие %50 + еще 256K на входной буфер.
Если немного по оптимизировать то часть памяти для коэффициентов и таблицу окна можно сэкономить считая на логике все на лету. Самые большие (входных и для первых stage) можно и во внешнюю память вынести (если полосы хватить).
Структура FFT R22 считает семпл за такт - на заморачиваясь можно получить 300 MHz - если "котика выжать" можно получить
еще 5 капе.. и 400 MHz тактовой.
Ну а дальше как игра в наперстки - как крутить вертеть данными либо по очереди в один FFT - если успеваем по частоте.
Либо распределяем на несколько FFT по очереди, либо и то и другое.
Вот когда для конкретной системы будут такие квадратики структуры с цифрами ресурсов и со стрелочками описывающими основные потоки данных - тогда можно будет выбирать "тощий" чип и строить универсальный конвейер.
Ах да - а что с данными после FFT делать не забудьте прикинуть и посчитать. Там ведь тоже будет сюрпризов.
Удачи! Rob.

















 Apr 4 2018, 21:05
Apr 4 2018, 21:05






 .
.

 Ваши слова да начальству бы в уши
Ваши слова да начальству бы в уши 




