Здравствуйте. В процессе миграции проекта с Quartus в Vivado столкнулся с неприятной проблемой. В Quartus проекте используется мегафункция LPM_MUX – т.е. эффективный параметризируемый Mux оптимизированный под конкретное семейство FPGA с возможностью pipelining. Аналогичного IP Core у Xilinx найти не удалось (может я плохо искал?).
Изначально в проекте использовал обычный Mux «общего назначения», ключевая часть которого выглядела приблизительно так (модуль целиком в аттаче bus_mux.vhd):
Код
-- Asynchronous Mux
MUX_P_ASYNC: process(sel, data_in)
variable idx: integer := 0;
begin
idx := conv_integer(sel);
mux_data <= data_in((idx+1)*(BUS_WIDTH)-1 downto idx*(BUS_WIDTH));
end process;]
Это простая альтернатива длинным
case структурам, которая обычно даёт такой же результат. Однако в данном проекте этот подход был неэффективным, т.к. мультиплексоры должны быть весьма
широкие – где-то от 40 до 150 входных шин, каждая шина 32/64 бита. Таких мультиплексоров несколько сотен, и они достаточно тесно «взаимосвязаны». Всё это приводило к высокой насыщенности в кристалле (congested design). В результате в процессе раскладки Routing зачастую или просто загибался, или в результате имел низкую частоту (где-то 50 МГц, тогда как целевая частота в диапазоне 100-200 МГц).
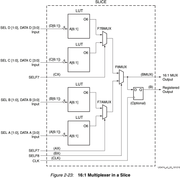
Решить проблему помогло добавление pipeline регистров. Т.е. в альтеровской мегафункции LPM_MUX можно просто параметром установить количество ступеней pipeline, и наше одно большое асинхронное дерево MUX разбивается на каскады с промежуточными регистрами между ними.
Т.к. аналогичного IP Core для Xilinx найти не удалось, озадачился поиском альтернатив. Нашёл достаточно неплохой
xapp522-mux-design-techniques (автор небезызвестный Ken Chapman). Там достаточно хорошо описывается, как наиболее эффективно реализовать мультиплексоры на базе основных «кирпичиков» Configurable Logic Blocks (CLBs) (для Spartan-6 FPGAs, Virtex-6 FPGAs, and 7 series FPGAs). И есть даже примеры исходников (
Reference Design Files). Проблема только в том что:
1) Прилагаемые примеры описывают максимум Mux 16:1 (т.е. 16 входов, один выход). Б
ольшие муксы предлагается компоновать из более мелких.
2) Само описание MUX-а низкоуровневое, специфичное для вышеупомянутых семейств, по сути, просто конструктор элементов CLB (дерево из LUT6, MUXF7, MUXF8).
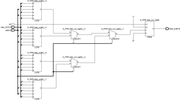
На картинке пример реализации 8:1 MUX:
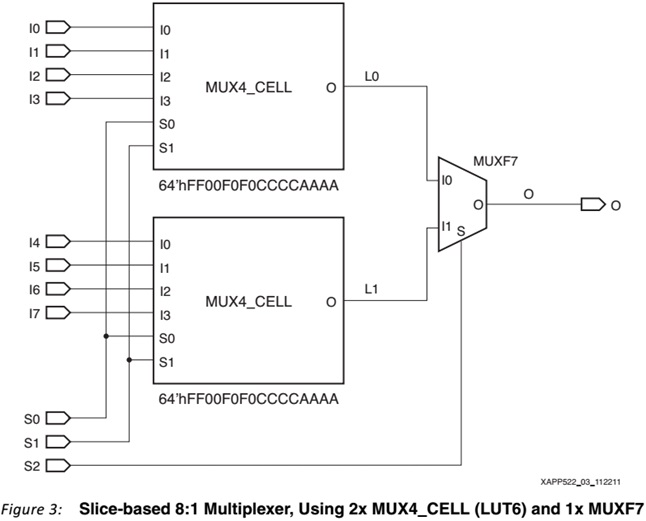
И прилагаемом в xapp-е примерах в коде прямо так и описываются все эти примитивы (особенно вставляют строки инициализации LUT6, т.е.
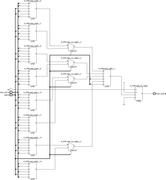
.INIT (64'hFF00F0F0CCCCAAAA) ). Ниже пример кода для 16:1 MUX (standard_mux16.v).
CODE
///////////////////////////////////////////////////////////////////////////////////////////
//
// Format of this file.
//
// The module defines the implementation of the logic using Xilinx primitives.
// These ensure predictable synthesis results and maximise the density of the
// implementation. The Unisim Library is used to define Xilinx primitives. It is also
// used during simulation.
// The source can be viewed at %XILINX%\verilog\src\unisims\
//
///////////////////////////////////////////////////////////////////////////////////////////
//
`timescale 1 ps / 1ps
module standard_mux16 (
input [15:0] data_in,
input [3:0] sel,
output data_out);
//
///////////////////////////////////////////////////////////////////////////////////////////
//
// Wires used in standard_mux16
//
///////////////////////////////////////////////////////////////////////////////////////////
//
wire [3:0] data_selection;
wire [1:0] combiner;
//
///////////////////////////////////////////////////////////////////////////////////////////
//
// Start of standard_mux16 circuit description
//
///////////////////////////////////////////////////////////////////////////////////////////
//
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection0_lut(
.I0 (data_in[0]),
.I1 (data_in[1]),
.I2 (data_in[2]),
.I3 (data_in[3]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[0]));
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection1_lut(
.I0 (data_in[4]),
.I1 (data_in[5]),
.I2 (data_in[6]),
.I3 (data_in[7]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[1]));
MUXF7 combiner0_muxf7 (
.I0 (data_selection[0]),
.I1 (data_selection[1]),
.S (sel[2]),
.O (combiner[0])) ;
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection2_lut(
.I0 (data_in[8]),
.I1 (data_in[9]),
.I2 (data_in[10]),
.I3 (data_in[11]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[2]));
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection3_lut(
.I0 (data_in[12]),
.I1 (data_in[13]),
.I2 (data_in[14]),
.I3 (data_in[15]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[3]));
MUXF7 combiner1_muxf7 (
.I0 (data_selection[2]),
.I1 (data_selection[3]),
.S (sel[2]),
.O (combiner[1])) ;
MUXF8 combiner_muxf8 (
.I0 (combiner[0]),
.I1 (combiner[1]),
.S (sel[3]),
.O (data_out)) ;
endmodule
///////////////////////////////////////////////////////////////////////////////////////////
//
// END OF FILE standard_mux16.v
//
///////////////////////////////////////////////////////////////////////////////////////////
Понятное дело, что такой код весьма далёк от generic кода общего вида. И чтобы подогнать под большие MUX-ов произвольного размера, да ещё и с добавлением промежуточных pipeline регистров для повышения производительности, нужно приложить определённые усилия.
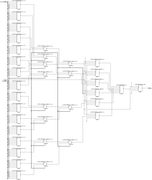
Если идти по такому пути, то написание более универсального MUX-а видится приблизительно так. Для примера возьмём MUX 150:1. Т.к. один CLB реализует максимум 16:1, то разбиваем наши 160 входов на ceil(150/16)=10 групп (9 полных 16:1 мультиплексоров, один неполный 6:1). Они образуют первый каскад, в которую можно «вставлять» промежуточные регистры (используя регистры тех же CLB, что и задействованы в имплементации самих MUX-ов). 10 выходов первого каскада заводим на каскад 2-ого уровня (MUX 10:1), с регистром на выходе если надо. Т.е. вроде можно заморочиться и просто описать этот алгоритм в HDL. Но, честно говоря, я на 100% не уверен, что такой способ наиболее эффективный с точки зрения производительности (может есть и более оптимальные решения). Ну и естественно, в идеале хотелось бы чего-то более простого и универсального. Тем более, что мне нужно это реализовать для двух семейств FPGA (Zynq7000 и UltraScale). А в семействе UltraScale CLB имеют другую архитектуру и могут реализовывать до 32:1 MUX. Опять-таки придётся это отдельным случаем описывать.
В идеале хотелось бы иметь некий код общего назначения, понятный без вникания в детали архитектуры конкретного семейства и абстрагированный от CLB. Может можно как-то аттрибутами запихать generic код в примитивы CLB (правда с промежуточными регистрами накладки получаются).
Так вот, исходя из всего вышеперечисленного, хотелось бы услышать мнения/критику, как бы наиболее эффективно (с точки зрения производительности) и не сильно проблематично с точки зрения написания кода (а хотелось бы ещё и красиво) реализовать такой конфигурируемый широкий мультиплексор с pipeline регистрами.Может кому уже приходилось сталкиваться с подобным, и можете поделиться набитыми шишками? Или подкинет кто каких полезных ссылок? Буду рад помощи.

















 Jun 24 2018, 05:57
Jun 24 2018, 05:57