| |
 Эффективный широкий pipelined mux Эффективный широкий pipelined mux, как альтеровский LPM_MUX, но для Xilinx |
|
|
|
|
 Jun 24 2018, 05:57 Jun 24 2018, 05:57
|
Частый гость

Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149

|
Здравствуйте. В процессе миграции проекта с Quartus в Vivado столкнулся с неприятной проблемой. В Quartus проекте используется мегафункция LPM_MUX – т.е. эффективный параметризируемый Mux оптимизированный под конкретное семейство FPGA с возможностью pipelining. Аналогичного IP Core у Xilinx найти не удалось (может я плохо искал?). Изначально в проекте использовал обычный Mux «общего назначения», ключевая часть которого выглядела приблизительно так (модуль целиком в аттаче bus_mux.vhd): Код -- Asynchronous Mux
MUX_P_ASYNC: process(sel, data_in)
variable idx: integer := 0;
begin
idx := conv_integer(sel);
mux_data <= data_in((idx+1)*(BUS_WIDTH)-1 downto idx*(BUS_WIDTH));
end process;] Это простая альтернатива длинным case структурам, которая обычно даёт такой же результат. Однако в данном проекте этот подход был неэффективным, т.к. мультиплексоры должны быть весьма широкие – где-то от 40 до 150 входных шин, каждая шина 32/64 бита. Таких мультиплексоров несколько сотен, и они достаточно тесно «взаимосвязаны». Всё это приводило к высокой насыщенности в кристалле (congested design). В результате в процессе раскладки Routing зачастую или просто загибался, или в результате имел низкую частоту (где-то 50 МГц, тогда как целевая частота в диапазоне 100-200 МГц). Решить проблему помогло добавление pipeline регистров. Т.е. в альтеровской мегафункции LPM_MUX можно просто параметром установить количество ступеней pipeline, и наше одно большое асинхронное дерево MUX разбивается на каскады с промежуточными регистрами между ними. Т.к. аналогичного IP Core для Xilinx найти не удалось, озадачился поиском альтернатив. Нашёл достаточно неплохой xapp522-mux-design-techniques (автор небезызвестный Ken Chapman). Там достаточно хорошо описывается, как наиболее эффективно реализовать мультиплексоры на базе основных «кирпичиков» Configurable Logic Blocks (CLBs) (для Spartan-6 FPGAs, Virtex-6 FPGAs, and 7 series FPGAs). И есть даже примеры исходников ( Reference Design Files). Проблема только в том что: 1) Прилагаемые примеры описывают максимум Mux 16:1 (т.е. 16 входов, один выход). Б ольшие муксы предлагается компоновать из более мелких. 2) Само описание MUX-а низкоуровневое, специфичное для вышеупомянутых семейств, по сути, просто конструктор элементов CLB (дерево из LUT6, MUXF7, MUXF8). На картинке пример реализации 8:1 MUX: 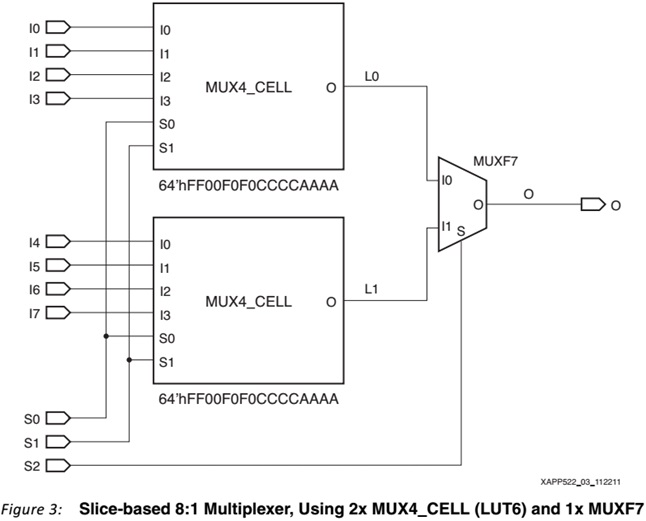 И прилагаемом в xapp-е примерах в коде прямо так и описываются все эти примитивы (особенно вставляют строки инициализации LUT6, т.е. .INIT (64'hFF00F0F0CCCCAAAA) ). Ниже пример кода для 16:1 MUX (standard_mux16.v). CODE ///////////////////////////////////////////////////////////////////////////////////////////
//
// Format of this file.
//
// The module defines the implementation of the logic using Xilinx primitives.
// These ensure predictable synthesis results and maximise the density of the
// implementation. The Unisim Library is used to define Xilinx primitives. It is also
// used during simulation.
// The source can be viewed at %XILINX%\verilog\src\unisims\
//
///////////////////////////////////////////////////////////////////////////////////////////
//
`timescale 1 ps / 1ps
module standard_mux16 (
input [15:0] data_in,
input [3:0] sel,
output data_out);
//
///////////////////////////////////////////////////////////////////////////////////////////
//
// Wires used in standard_mux16
//
///////////////////////////////////////////////////////////////////////////////////////////
//
wire [3:0] data_selection;
wire [1:0] combiner;
//
///////////////////////////////////////////////////////////////////////////////////////////
//
// Start of standard_mux16 circuit description
//
///////////////////////////////////////////////////////////////////////////////////////////
//
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection0_lut(
.I0 (data_in[0]),
.I1 (data_in[1]),
.I2 (data_in[2]),
.I3 (data_in[3]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[0]));
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection1_lut(
.I0 (data_in[4]),
.I1 (data_in[5]),
.I2 (data_in[6]),
.I3 (data_in[7]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[1]));
MUXF7 combiner0_muxf7 (
.I0 (data_selection[0]),
.I1 (data_selection[1]),
.S (sel[2]),
.O (combiner[0])) ;
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection2_lut(
.I0 (data_in[8]),
.I1 (data_in[9]),
.I2 (data_in[10]),
.I3 (data_in[11]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[2]));
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection3_lut(
.I0 (data_in[12]),
.I1 (data_in[13]),
.I2 (data_in[14]),
.I3 (data_in[15]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[3]));
MUXF7 combiner1_muxf7 (
.I0 (data_selection[2]),
.I1 (data_selection[3]),
.S (sel[2]),
.O (combiner[1])) ;
MUXF8 combiner_muxf8 (
.I0 (combiner[0]),
.I1 (combiner[1]),
.S (sel[3]),
.O (data_out)) ;
endmodule
///////////////////////////////////////////////////////////////////////////////////////////
//
// END OF FILE standard_mux16.v
//
/////////////////////////////////////////////////////////////////////////////////////////// Понятное дело, что такой код весьма далёк от generic кода общего вида. И чтобы подогнать под большие MUX-ов произвольного размера, да ещё и с добавлением промежуточных pipeline регистров для повышения производительности, нужно приложить определённые усилия. Если идти по такому пути, то написание более универсального MUX-а видится приблизительно так. Для примера возьмём MUX 150:1. Т.к. один CLB реализует максимум 16:1, то разбиваем наши 160 входов на ceil(150/16)=10 групп (9 полных 16:1 мультиплексоров, один неполный 6:1). Они образуют первый каскад, в которую можно «вставлять» промежуточные регистры (используя регистры тех же CLB, что и задействованы в имплементации самих MUX-ов). 10 выходов первого каскада заводим на каскад 2-ого уровня (MUX 10:1), с регистром на выходе если надо. Т.е. вроде можно заморочиться и просто описать этот алгоритм в HDL. Но, честно говоря, я на 100% не уверен, что такой способ наиболее эффективный с точки зрения производительности (может есть и более оптимальные решения). Ну и естественно, в идеале хотелось бы чего-то более простого и универсального. Тем более, что мне нужно это реализовать для двух семейств FPGA (Zynq7000 и UltraScale). А в семействе UltraScale CLB имеют другую архитектуру и могут реализовывать до 32:1 MUX. Опять-таки придётся это отдельным случаем описывать. В идеале хотелось бы иметь некий код общего назначения, понятный без вникания в детали архитектуры конкретного семейства и абстрагированный от CLB. Может можно как-то аттрибутами запихать generic код в примитивы CLB (правда с промежуточными регистрами накладки получаются). Так вот, исходя из всего вышеперечисленного, хотелось бы услышать мнения/критику, как бы наиболее эффективно (с точки зрения производительности) и не сильно проблематично с точки зрения написания кода (а хотелось бы ещё и красиво) реализовать такой конфигурируемый широкий мультиплексор с pipeline регистрами.Может кому уже приходилось сталкиваться с подобным, и можете поделиться набитыми шишками? Или подкинет кто каких полезных ссылок? Буду рад помощи.
|
|
|
|
|
|
|
 |
Ответов
|
|
Jun 26 2018, 11:42
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Ещё в процессе экспериментов выяснилось, что не всегда синтезатор оптимально размещает муксы используя специальные внутренние примитивы (MUXF8, MUXF9). Не знаю, можно ли вставлять сразу картинки большего качества, пока получилось через ссылки и в аттаче.Начнём с семейства Zynq7000. Как уже писалось выше 1 слайс (поправка именно Slice; в CLB два Slice, но сути это не меняет) используя все 4xLUT6, 2xMUXF и 1xMUXF8 можно превратить в mux 16:1 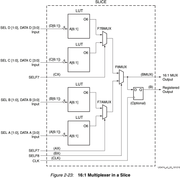 Когда из кода общего вида делаю синтез для mux с 16 входами, то как раз получается такой «канонический» результат: 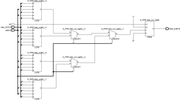 Однако когда делаем синтез для 32 входов, картина меняется. Почему-то MUXF8 не задействованы, а лишь MUXF7 (хотя ничто не мешает просто продублировать как было в mux_16_1 два раза и объединить через LUT). 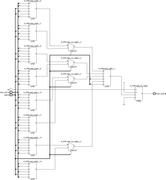 Что ещё более интересно, для 64 входов (mux_64_1) вновь синтезируется корректно, задействует MUX8 (т.е. повторяем четыре раза mux_16_1 и объединяем через LUT):  И кстати вот ещё картинка, где показано, как для mux_64_1 работает атрибут retiming_backward и «задвигает» добавочные регистры пайплана на промежуточную стадию (до входа на конечный LUT): 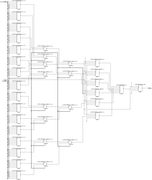 Для муксов большего размера ситуация повторяется - каждые дополнительные 32 входа MUXF8 то используется, то нет. -------------------------------------------------------------------------------------------------------------------------------------------- В семействе Zynq UltraScale+ ситуация немного другая, чуть хуже. Начнём с того, что тут другая архитектура CLB – два слайса объединены в один и поэтому можно на базе одного CLB делать mux 32:1 (используя примитив MUXF9): 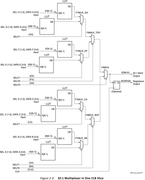 Однако, какого бы размера муксы не пытался синтезировать, ни в одном случае не удавалось задействовать MUXF9. Для примера вот так синтезируется mux_32_1 (нет ни MUXF8, ни MUXF9): 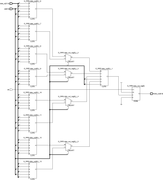 В муксах большего размера ситуация похожая как в семейтсве Zynq7000 (т.е. MUXF8 то используется, то нет). Но MUXF9 увидеть ни разу не удалось. Перепробовал все стратегии синтеза – не помогло. Даже в одном случае для стратегии AlternateRoutability вместо всех MUXF[5-8] использовались LUT (что и соответствует заданной стратегии). Вроде бы должна помочь стратегия AreaOptimized_high, в описании которой присутствует фраза “area optimized mux optimization” - но результаты не менялись. Начал смотреть в документации, как можно заставить использовать эти самые MUXF[7-9]. Вроде нашёл подходящую опцию. В ug901, Глава 3 “Using Block Synthesis Strategies” имеется перечень поддерживаемых Вивадо опций стратегии блочного синтеза. Среди них есть опция: Код MUXF_MAPPING
INTEGER 0/1
• 0 – Disable MUXF7/F8/F9 inference
• 1 – Enable MUXF7/F8/F9 inference Попробовал использовать – не помогло (убедился, что xdc файл с этой опцией действительно читается и парсится синтезатором). Прогонялось в Vivado 2017.4 Вопрос: может есть идеи, как ещё можно попытаться задействовать эти самые MUXF[8-9] там, где им положено бы быть, не запихивая их туда вручную из кода? Возможно в более новых версиях Вивадо ситуация может быть другая, но пока проверить это имею возможности. По идее есть смысл спросить на форуме Xilinx, но что-то тамошние ответы или отсутствуют, или не шибко-то помогают… P.S.: в аттаче pdf файлы генерируемых схематик, которые легче масштабировать.
Сообщение отредактировал Vengin - Jun 26 2018, 11:51
|
|
|
|
|
|
|
|
Jun 27 2018, 09:57
|
Частый гость
Группа: Свой
Сообщений: 180
Регистрация: 17-02-09
Из: Санкт-Петербург
Пользователь №: 45 001
|
Цитата(Vengin @ Jun 26 2018, 14:42)  Однако когда делаем синтез для 32 входов, картина меняется. Почему-то MUXF8 не задействованы, а лишь MUXF7 (хотя ничто не мешает просто продублировать как было в mux_16_1 два раза и объединить через LUT).
..
Что ещё более интересно, для 64 входов (mux_64_1) вновь синтезируется корректно, задействует MUX8 (т.е. повторяем четыре раза mux_16_1 и объединяем через LUT): Синтезатор не глуп и придерживается принципа "бритвы оккама". В том случае, в котором Вы сетуете на отсутствие MUX8 всё равно без ЛУТа не обойтись, а значит эти муксы - лишние сущности. Цитата(Vengin @ Jun 26 2018, 14:42) В муксах большего размера ситуация похожая как в семейтсве Zynq7000 (т.е. MUXF8 то используется, то нет). Но MUXF9 увидеть ни разу не удалось. Здесь может быть всё, что угодно - от синтезатора, который просто "не знает" про MUXF9 или немного не корректно по каким-либо причинам обсчитывает через него времянки, до хардварных с ними проблем, о которых предпочитают не говорить, но дали указание "низя". Может как-нибудь проверю симплифаем, да сейчас лень.. Да и вообще, сознательное использование специфических элементов, типа этих муксов, carry логики или линий связи между дсп накладывает кучу ограничений на описание. Главное из которых, ИМХО, это выносить описание этих элементов в отдельные модули и жёстко контролировать оптимизацию на всех уровнях, чтобы какой-нибудь ресинтез не уничтожил все Ваши труды. К тому же такое низкоуровневое описание имеет смысл в действительно больших и быстрых проектах, а так же с чётким осознанием цели их применения.
|
|
|
|
|
|
|
|
Jun 28 2018, 07:07
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(TRILLER @ Jun 27 2018, 12:57) Синтезатор не глуп и придерживается принципа "бритвы оккама". В том случае, в котором Вы сетуете на отсутствие MUX8 всё равно без ЛУТа не обойтись, а значит эти муксы - лишние сущности. В этом есть смысл, хотя опять-таки всплывают нюансы. Вот, например, как для mux_32_1 при использовании только MUXF7 происходит добавление pipeline регистров атрибутом retiming_backward: 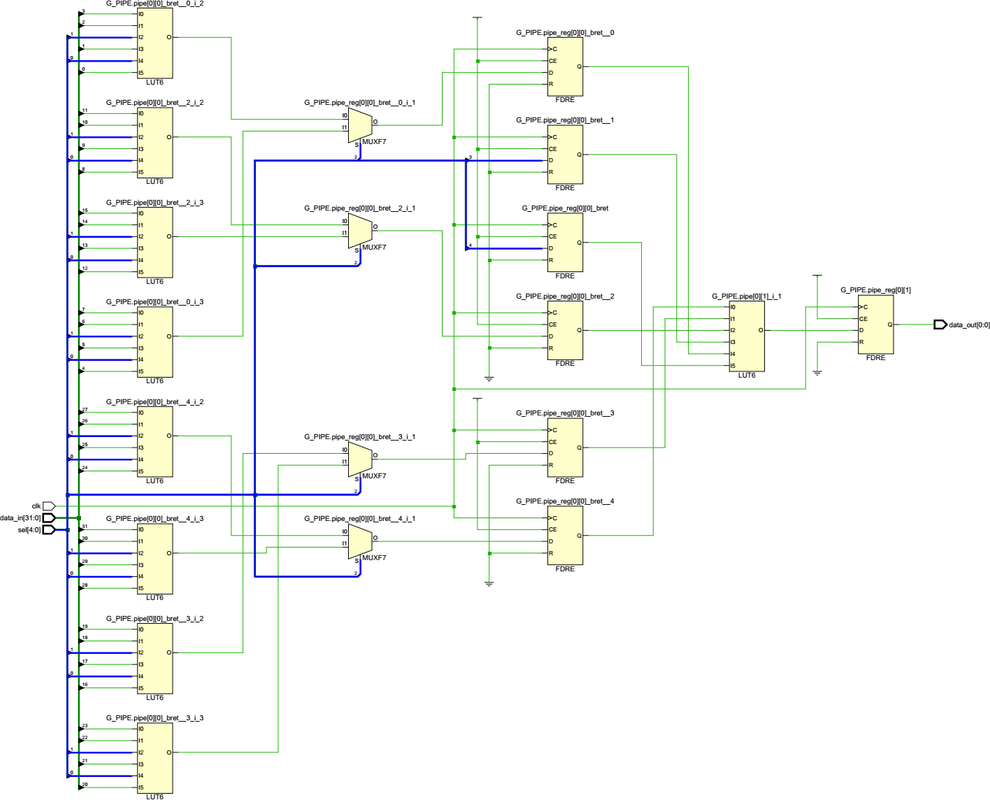 Как видно, на промежуточной стадии добавляется аж 6 регистров – 4 для сигналов данных и 2 для «задержки» сигнала выбора sel (которые синтезатор вставляет по собственной инициативе, в коде их нет). Если бы первый каскад заканчивался не на четырёх MUXF7, а на двух MUXF8, то промежуточных регистров было бы по идее только 3 (2 для сигнала данных, 1 для sel). Короче чем дальше в лес…
|
|
|
|
|
|
|
|
Jun 28 2018, 07:45
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 28 2018, 10:07) В этом есть смысл, хотя опять-таки всплывают нюансы. Вот, например, как для mux_32_1 при использовании только MUXF7 происходит добавление pipeline регистров атрибутом retiming_backward:
Как видно, на промежуточной стадии добавляется аж 6 регистров – 4 для сигналов данных и 2 для «задержки» сигнала выбора sel (которые синтезатор вставляет по собственной инициативе, в коде их нет). Если бы первый каскад заканчивался не на четырёх MUXF7, а на двух MUXF8, то промежуточных регистров было бы по идее только 3 (2 для сигнала данных, 1 для sel).
Короче чем дальше в лес… Экономить на регистрах тут смысла нет - так как критично по ресурсам будет число LUT. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 28 2018, 07:56
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(RobFPGA @ Jun 28 2018, 10:45) Приветствую!
Экономить на регистрах тут смысла нет - так как критично по ресурсам будет число LUT. Тут вроде не совсем в экономии дело, а в том, что чем больше регистров (и вооще ресурсов), тем больше скажем этот мукс размазывается по кристаллу (разным CLB и слайсам) и в итоге расходует больше ресурсов, хуже времянка и т.п. Цитата(TRILLER @ Jun 28 2018, 10:48) Скорее всего атрибут применяется уже после получения схемы, отсюда и такой результат. Это более чем логично, что retiming_backward применяется позже или имеет более низкий приоритет. Просто пытаюсь указать на всякие не совсем предвиденные вещи. Цитата(TRILLER @ Jun 28 2018, 10:48) И совет Вам: не пытайтесь скрещивать бульдога с носорогом. Атрибуты, подобные retiming_backward и низкоуровневый rtl не совместимы. ИМХО. Так а в данном случае опция retiming_backward применяется к коду общего вида (в этом и весь смысл), а не низкоуровневому описанию. Т.е. итоговая "композиция" - результат синтеза кода "общего вида". Естественно, если вручную компоновать примитивы, то можно сделать по другому. Но вот даже исходя из этого относительно простого примера, может возникнуть масса нюансов, которые не так то легко учесть.
|
|
|
|
|
|
|
|
Jun 28 2018, 08:57
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 28 2018, 10:56) Тут вроде не совсем в экономии дело, а в том, что чем больше регистров (и вооще ресурсов), тем больше скажем этот мукс размазывается по кристаллу (разным CLB и слайсам) и в итоге расходует больше ресурсов, хуже времянка и т.п. Для структуры SLICE в Xilinx для элементарных mux 4:1, 8:1 16:1 что есть регистр на выходе что нет - число занятых SLICE не меняется. Бывают правда ситуации когда при P&R регистр выносится из SLICE где стоить LUT который кормит этот регистр Это может быть если есть запас времянки на входе в LUT а с выхода от регистра на следующий каскад его нет. Тогда регистр выносится в SLICE поближе к получателю. Что касается размазывания тоже не все так однозначно - вариант на каскадах 4:1 требует больше ресурсов НО при R&R элементарные модули можно гибче распределять по площади чем жесткие блоки 16:1. Опять же - это все относительно и начинает играет роль при заполненном кристалле для сильно-связанного проекта. Удачи! Rob.
|
|
|
|
|
|
Сообщений в этой теме
 Vengin Эффективный широкий pipelined mux Jun 24 2018, 05:57 Vengin Эффективный широкий pipelined mux Jun 24 2018, 05:57 iosifk Цитата(Vengin @ Jun 24 2018, 08:57) т.к. ... Jun 24 2018, 07:00 iosifk Цитата(Vengin @ Jun 24 2018, 08:57) т.к. ... Jun 24 2018, 07:00  Vengin Цитата(iosifk @ Jun 24 2018, 10:00) Возьм... Jun 24 2018, 07:34 iosifk Цитата(Vengin @ Jun 24 2018, 10:34) В тео... Jun 24 2018, 07:43 Vengin Цитата(iosifk @ Jun 24 2018, 10:43) Разве... Jun 24 2018, 07:47 RobFPGA Приветствую!
Цитата(iosifk @ Jun 24 2018... Jun 24 2018, 08:19 Vengin Цитата(RobFPGA @ Jun 24 2018, 11:19) Все ... Jun 24 2018, 08:31 RobFPGA Приветствую!
Цитата(Vengin @ Jun 24 2018,... Jun 24 2018, 09:16 Vengin Цитата(RobFPGA @ Jun 24 2018, 12:16) Это ... Jun 24 2018, 10:47 blackfin Цитата(Vengin @ Jun 24 2018, 13:47) На да... Jun 24 2018, 10:53 Vengin Цитата(blackfin @ Jun 24 2018, 13:53) (*r... Jun 24 2018, 11:02 RobFPGA Приветствую!
Цитата(Vengin @ Jun 24 2018,... Jun 24 2018, 11:53 Vengin Цитата(RobFPGA @ Jun 24 2018, 14:53) Для ... Jun 24 2018, 13:18 RobFPGA Приветствую!
Цитата(Vengin @ Jun 24 2018,... Jun 25 2018, 09:54 Vengin Поэкспериментировал немного с атрибутом retiming_b... Jun 25 2018, 13:12 RobFPGA Приветствую!
Цитата(Vengin @ Jun 26 2018,... Jun 26 2018, 12:36 blackfin Цитата(Vengin @ Jun 28 2018, 10:07) Как в... Jun 28 2018, 07:40 TRILLER Цитата(Vengin @ Jun 28 2018, 10:07) Как в... Jun 28 2018, 07:48 blackfin Попробовал сделать на LUT6 4-дерево из MUX 4:1 для... Jun 26 2018, 12:53 Vengin Цитата(blackfin @ Jun 26 2018, 15:53) Поп... Jun 26 2018, 13:09 blackfin Цитата(Vengin @ Jun 26 2018, 16:09) Т.е.,... Jun 26 2018, 13:13 RobFPGA Приветствую!
Цитата(blackfin @ Jun 26 201... Jun 26 2018, 13:50 blackfin Цитата(Vengin @ Jun 24 2018, 08:57) ... м... Jun 28 2018, 08:09 Vengin Цитата(blackfin @ Jun 28 2018, 11:09) На ... Jun 28 2018, 11:43 blackfin Цитата(Vengin @ Jun 28 2018, 14:43) Тогда... Jun 28 2018, 12:00 Vengin Цитата(blackfin @ Jun 28 2018, 15:00) В т... Jun 28 2018, 12:08 Vengin Цитата(iosifk @ Jun 24 2018, 10:00) Возьм... Jun 24 2018, 07:34 iosifk Цитата(Vengin @ Jun 24 2018, 10:34) В тео... Jun 24 2018, 07:43 Vengin Цитата(iosifk @ Jun 24 2018, 10:43) Разве... Jun 24 2018, 07:47 RobFPGA Приветствую!
Цитата(iosifk @ Jun 24 2018... Jun 24 2018, 08:19 Vengin Цитата(RobFPGA @ Jun 24 2018, 11:19) Все ... Jun 24 2018, 08:31 RobFPGA Приветствую!
Цитата(Vengin @ Jun 24 2018,... Jun 24 2018, 09:16 Vengin Цитата(RobFPGA @ Jun 24 2018, 12:16) Это ... Jun 24 2018, 10:47 blackfin Цитата(Vengin @ Jun 24 2018, 13:47) На да... Jun 24 2018, 10:53 Vengin Цитата(blackfin @ Jun 24 2018, 13:53) (*r... Jun 24 2018, 11:02 RobFPGA Приветствую!
Цитата(Vengin @ Jun 24 2018,... Jun 24 2018, 11:53 Vengin Цитата(RobFPGA @ Jun 24 2018, 14:53) Для ... Jun 24 2018, 13:18 RobFPGA Приветствую!
Цитата(Vengin @ Jun 24 2018,... Jun 25 2018, 09:54 Vengin Поэкспериментировал немного с атрибутом retiming_b... Jun 25 2018, 13:12 RobFPGA Приветствую!
Цитата(Vengin @ Jun 26 2018,... Jun 26 2018, 12:36 blackfin Цитата(Vengin @ Jun 28 2018, 10:07) Как в... Jun 28 2018, 07:40 TRILLER Цитата(Vengin @ Jun 28 2018, 10:07) Как в... Jun 28 2018, 07:48 blackfin Попробовал сделать на LUT6 4-дерево из MUX 4:1 для... Jun 26 2018, 12:53 Vengin Цитата(blackfin @ Jun 26 2018, 15:53) Поп... Jun 26 2018, 13:09 blackfin Цитата(Vengin @ Jun 26 2018, 16:09) Т.е.,... Jun 26 2018, 13:13 RobFPGA Приветствую!
Цитата(blackfin @ Jun 26 201... Jun 26 2018, 13:50 blackfin Цитата(Vengin @ Jun 24 2018, 08:57) ... м... Jun 28 2018, 08:09 Vengin Цитата(blackfin @ Jun 28 2018, 11:09) На ... Jun 28 2018, 11:43 blackfin Цитата(Vengin @ Jun 28 2018, 14:43) Тогда... Jun 28 2018, 12:00 Vengin Цитата(blackfin @ Jun 28 2018, 15:00) В т... Jun 28 2018, 12:08
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|


























