| |
 Графический фильтр на Cortex-M7 Графический фильтр на Cortex-M7, Увеличение ровно в 2 раза |
|
|
|
|
 Jul 16 2018, 05:35 Jul 16 2018, 05:35
|

Местный

Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126

|
Бьюсь над реализацией графического фильтра HQ2X на STM32H743 (Cortex-M7). Фильтр работает, но притормаживает, когда в кадре много мелких деталей. Была предпринята оптимизация: Switch/Case из 256 значений был заменён на JumpTable. Не помогло. Исходный код фильтра (Keil ARM MDK):  HQ2x.rar
HQ2x.rar ( 8.36 килобайт )
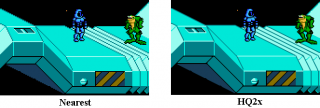
Кол-во скачиваний: 21Требуется растянуть кадр в 2 раза по обеим осям. Есть другие фильтры Scale2x, SaI2x , LQ2x - с ними проблем нет, на STM32H743 они идут довольно шустро(написанные на C, без Asm-а). Вот тут чувак заточил под NEON и DSP фильтр HQnX (что не годится для Cortex-M7): https://pyra-handheld.com/boards/threads/ru...sp.69047/page-5Существуют ли аналогичные графические фильтры (в частности HQ 2x), оптимизированные на ассемблере для ядер ARM Cortex-M7? Работа фильтра пояснена на рисунке:
Сообщение отредактировал __inline__ - Jul 16 2018, 05:37
|
|
|
|
|
|
|
 |
Ответов
|
|
Jul 16 2018, 16:21
|
Местный
Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126
|
Цитата(Obam @ Jul 16 2018, 16:52)  Т.к. кортекс-М умеет только команды Tumb-2, то загрузка 32битной константы выполняется за 2 команды: movw (младшее полуслово) и movt (старшее). А смысл 0x00300706 вам знать.
LDR value1, =_00300706 одной командой не будет быстрее? Обращение к ячейке памяти. Предположим, что это STM32H743 и переменная в DTCM и адрес выровнен на 4 байта. Что будет быстрее: один LDR или 2 MOV ? К тому же LDR загрузит адрес, а не значение, а это уже 2 LDR: LDR r0, =DATA00300706 LDR r1,[r0] или у меня недопонятки?
|
|
|
|
|
|
|
|
Jul 17 2018, 11:11
|
Местный
Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126
|
Цитата(jcxz @ Jul 17 2018, 07:17) Кстати - по этой найденной Вами ассемблерной Diff() уже видно как значительно можно выиграть, написав весь блок вызовов Diff() в виде асм-функции и заинлайнив туда саму Diff(). Из неё сразу выпадают: Код mov tmp2,#0 // tmp2 = 0
movw value1,#0x0706
movt value1,#0x30 // value1 = 0x300706 Которые запросто выносятся за рамки цикла. И вызовов/возвратов не нужно. Пытался обдумать, не выходит. Там слева более простое выражение, которое если "ложь", то Diff() не вычисляется. Может вычислять все Diff не надо? В цикле строки: Код if ((w1 != w5) && (Diff(y, RGBtoYUV[w1]))) pattern |= (1 << 0);
if ((w2 != w5) && (Diff(y, RGBtoYUV[w2]))) pattern |= (1 << 1);
if ((w3 != w5) && (Diff(y, RGBtoYUV[w3]))) pattern |= (1 << 2);
if ((w4 != w5) && (Diff(y, RGBtoYUV[w4]))) pattern |= (1 << 3);
if ((w6 != w5) && (Diff(y, RGBtoYUV[w6]))) pattern |= (1 << 4);
if ((w7 != w5) && (Diff(y, RGBtoYUV[w7]))) pattern |= (1 << 5);
if ((w8 != w5) && (Diff(y, RGBtoYUV[w8]))) pattern |= (1 << 6);
if ((w9 != w5) && (Diff(y, RGBtoYUV[w9]))) pattern |= (1 << 7); Если я Вас не понял, то можете более подробнее изложить суть предлагаемых изменений?
|
|
|
|
|
|
|
|
Jul 17 2018, 15:59
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(__inline__ @ Jul 17 2018, 14:11) Если я Вас не понял, то можете более подробнее изложить суть предлагаемых изменений? Ну что непонятного? Код int w[8], w5;
int *p = &w[0], i;
u32 pattern = 0, c = 1 << 23;
do if ((i = *p++) != w5) if (Diff(y, RGBtoYUV[i])) pattern |= c;
while ((s32)(c <<= 1) >= 0);
pattern &= 255; Типа так. Вместо w1-w9 - w[8], а w5 - отдельно. Изменив в остальных местах соответственно. Подставьте вместо вызова Diff() само тело функции в цикл (она больше нигде не вызывается у Вас) если сам компилятор не заинлайнит. Скомпилите, а затем возьмите полученный asm-листинг и сделайте из него функцию и оптимизируйте её (раз сами не можете сразу асм-функцию написать). Вот как раз одна из оптимизаций будет - вынести те три команды наружу цикла, отдав под них пару регистров. Операцию pattern &= 255 можно выкинуть, если сделать c = 1 << 24 и условие завершения цикла - перенос из старшего бита во флаг переноса по команде LSLS (не знаю как в си такое сделать). Когда будет асм-функция там думаю можно будет и другие возможности оптимизации увидеть. PS: Глядя на SEL yuv1,z,yuv1 // yuv1=(YUVMASK>=abs(yuv1-yuv2))?0:YUVMASK сдаётся мне что там вообще можно Код MOV yuv1,#YUVMASK // yuv1=YUVMASK
MOV z,#0 выкинуть, если Diff() будет встроена в тело цикла. Как я понимаю - в зависимости от результата предыдущей команды SEL выбирает один из своих регистров-аргументов и копирует его в целевой регистр. Но потом это используется только как флаг. Так что можно заменить z и yuv1 в ней на другие подходящие регистры, выкинув вообще пару команд указанную выше. Надо читать описание команды SEL - не использовал её никогда, не уверен.
|
|
|
|
|
|
|
|
Jul 18 2018, 03:03
|
Местный
Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126
|
Цитата(jcxz @ Jul 17 2018, 16:59) Код int w[8], w5;
int *p = &w[0], i;
u32 pattern = 0, c = 1 << 23;
do if ((i = *p++) != w5) if (Diff(y, RGBtoYUV[i])) pattern |= c;
while ((s32)(c <<= 1) >= 0);
pattern &= 255; Типа так. Вместо w1-w9 - w[8], а w5 - отдельно. Изменив в остальных местах соответственно. Подставьте вместо вызова Diff() само тело функции в цикл (она больше нигде не вызывается у Вас) если сам компилятор не заинлайнит. Скомпилите, а затем возьмите полученный asm-листинг и сделайте из него функцию и оптимизируйте её (раз сами не можете сразу асм-функцию написать). Вот как раз одна из оптимизаций будет - вынести те три команды наружу цикла, отдав под них пару регистров. Операцию pattern &= 255 можно выкинуть, если сделать c = 1 << 24 и условие завершения цикла - перенос из старшего бита во флаг переноса по команде LSLS (не знаю как в си такое сделать). Когда будет асм-функция там думаю можно будет и другие возможности оптимизации увидеть. PS: Глядя на SEL yuv1,z,yuv1 // yuv1=(YUVMASK>=abs(yuv1-yuv2))?0:YUVMASK сдаётся мне что там вообще можно Код MOV yuv1,#YUVMASK // yuv1=YUVMASK
MOV z,#0 выкинуть, если Diff() будет встроена в тело цикла. Как я понимаю - в зависимости от результата предыдущей команды SEL выбирает один из своих регистров-аргументов и копирует его в целевой регистр. Но потом это используется только как флаг. Так что можно заменить z и yuv1 в ней на другие подходящие регистры, выкинув вообще пару команд указанную выше. Надо читать описание команды SEL - не использовал её никогда, не уверен. Попробовал. Стало хуже. Но это по вине компилятора: 1) int w[8] - это обращение к памяти, в то время как w1..w9 - очевидно регистры 2) Цикл разворачивается 8 раз. Никакие #pragma GCC optimize ("no-unroll-loops") и #pragma GCC optimize ("no-peel-loops") не помогают. Только -Ofast глобально убирать. 3) Одна итерация цикла строится от 11 до 13 инструкций. Зависит от настроения компилятора. 4) Не получается гарантировать сохранность регистров(для 0 и YUVMASK) внутри цикла -компилятор их внаглую затирает. Если объявить пару регистров глобально или -ffixed-reg, то работает, но эти регистры более нигде не применяются за пределами цикла(что тоже плохо). 5) И ещё вызов Diff() идёт в Case/Switch, а не только где сжали циклом: Код case 255:
{
if (Diff(RGBtoYUV[w[3]], RGBtoYUV[w[1]]))
{
X2PIXEL00_0
}
else ................ Делал так: Код //Diff:
static inline int Diff(u32 yuv1,u32 yuv2)
{
register u32 tmp1;
asm(
"usub8 %[tmp1], %[value1], %[value2] \n\t"
"usub8 %[value2], %[value2], %[value1] \n\t"
"sel %[tmp1], %[value2], %[tmp1] \n\t"
"usub8 %[value2], r6, %[tmp1] \n\t"
"sel %[value1], r7, %[value1] "
: [value1] "+r" (yuv1), [value2] "+r" (yuv2), [tmp1] "=r" (tmp1)
:
: "cc"
);
return yuv1;
}
//В цикле строки:
u32 *p=&w[0],i;
u32 c=1;
register u32 r6 asm("r6")=YUVMASK;
register u32 r7 asm("r7")=0;
do if((i=*p++)!=w5)if(Diff(y,RGBtoYUV[i]))pattern|=c;
while((c<<=1)<256); Тут только на ассемблере писать, иначе компилятор фигню будет строить.
Сообщение отредактировал __inline__ - Jul 18 2018, 03:07
|
|
|
|
|
|
|
|
Jul 18 2018, 08:57
|
Гуру
Группа: Свой
Сообщений: 5 228
Регистрация: 3-07-08
Из: Омск
Пользователь №: 38 713
|
Цитата(__inline__ @ Jul 18 2018, 06:03) Попробовал. Стало хуже. Но это по вине компилятора:
1) int w[8] - это обращение к памяти, в то время как w1..w9 - очевидно регистры
2) Цикл разворачивается 8 раз. Никакие #pragma GCC optimize ("no-unroll-loops") и #pragma GCC optimize ("no-peel-loops") не помогают. Только -Ofast глобально убирать.
...
Тут только на ассемблере писать, иначе компилятор фигню будет строить. Я вообще-то Вам и говорил, что это надо на асме писать. А код привёл для иллюстрации примерного алгоритма (на асме было писать дольше - лень). Вы уже дошли до пределов возможностей оптимизатора си, дальше только брать всё в свои руки - писать на чистом асме. Как бы ни были хороши современные оптимизаторы, а если взять листинг какой-либо функции скомпилённой IAR-ом на самой максимальной оптимизации, то там как правило сразу видно много путей оптимизации. Да и во многих местах даже последний IAR очень сильно лажает, добавляя кучу бессмысленных команд даже на макс. оптимизации. Так что: компилите функцию, берёте листинг, берёте даташит на систему команд Cortex-M и - вперёд! 
|
|
|
|
|
|
|
|
Jul 21 2018, 02:38
|
Местный
Группа: Участник
Сообщений: 257
Регистрация: 5-09-17
Пользователь №: 99 126
|
Цитата(jcxz @ Jul 18 2018, 09:57) Я вообще-то Вам и говорил, что это надо на асме писать. А код привёл для иллюстрации примерного алгоритма (на асме было писать дольше - лень). Вы уже дошли до пределов возможностей оптимизатора си, дальше только брать всё в свои руки - писать на чистом асме. Как бы ни были хороши современные оптимизаторы, а если взять листинг какой-либо функции скомпилённой IAR-ом на самой максимальной оптимизации, то там как правило сразу видно много путей оптимизации. Да и во многих местах даже последний IAR очень сильно лажает, добавляя кучу бессмысленных команд даже на макс. оптимизации. Так что: компилите функцию, берёте листинг, берёте даташит на систему команд Cortex-M и - вперёд! Попробовал вручную оптимизировать ASM-листинг с GCC и потом его в объектник с помощью ассемблера. Что заметил: 1) Много лишних переприсавиваний (верхние 2 строки закомментировал, ниже свой вариант): Код @ ldr r3, [r8, r2, lsl #2]
@ mov ip, r3
ldr ip, [r8, r2, lsl #2]
.syntax unified
@ 128 "HQ2x.cpp" 1
usub8 r3, lr, ip
usub8 ip, r5, r3
sel ip, ip, r3
usub8 ip, r7, ip
sel ip, r5, r7 Причем избавиться от этого не вышло, манипулируя разными комбинациями в объявлении входных/выходных/clobber- переменных 2) Цикл, переходы на метки - всё разворачивает. Объявление переменной границы цикла как volatile не даёт развернуть цикл, и он работает медленее, чем когда развёрнуто. Для моих целей оказался лучше другой фильтр - SaI. Он лучше сглаживает края (антиалиасинг), чем HQ2x и LQ2x. Исходники SaI фильтра + makefile + бинарник под Win32:
SaI2x_Win32.rar ( 39.11 килобайт )
Кол-во скачиваний: 11Входные данные: test.raw 160x144 RGB 8:8:8 Выходные: test2x.raw 288x320 RGB 8:8:8 (разворот на 90 градусов!) Картинка, иллюстрирующая работу фильтров:
BSpline - это "обычный фотошопный" фильтр (изображение размыто) SaI 320x240 - попытка втиснуть 320x288 в дисплей 320x240. Каждая 6-я строка выходного буфера пропускается, получается 240 линий вместо 288. Вроде б неплохо, если сравнивать с 320x240. И что самое главное, алгоритм менее ресурсозатратный , чем HQ2x : нет переходов и считываний из лукапов 
|
|
|
|
|
|
Сообщений в этой теме
 __inline__ Графический фильтр на Cortex-M7 Jul 16 2018, 05:35 __inline__ Графический фильтр на Cortex-M7 Jul 16 2018, 05:35 Genadi Zawidowski А попорбовать вместо ассемблерных вставок (которые... Jul 16 2018, 06:12 Genadi Zawidowski А попорбовать вместо ассемблерных вставок (которые... Jul 16 2018, 06:12  __inline__ Цитата(Genadi Zawidowski @ Jul 16 2018, 07... Jul 16 2018, 07:49 ViKo Рисунок врет. Например, глаза лягушонка он размыл ... Jul 16 2018, 07:26 aaarrr Цитата(ViKo @ Jul 16 2018, 10:26) Рисунок... Jul 16 2018, 07:49 ViKo Цитата(aaarrr @ Jul 16 2018, 10:49) Прост... Jul 16 2018, 07:54 __inline__ Цитата(ViKo @ Jul 16 2018, 08:26) Рисунок... Jul 16 2018, 07:54 KnightIgor Цитата(__inline__ @ Jul 16 2018, 08:54) Н... Jul 16 2018, 11:54 __inline__ Цитата(KnightIgor @ Jul 16 2018, 12:54) О... Jul 21 2018, 09:26 Arlleex Цитата(__inline__ @ Jul 21 2018, 12:26) В... Jul 21 2018, 10:13 __inline__ Цитата(Arlleex @ Jul 21 2018, 11:13) А за... Jul 21 2018, 10:41 Genadi Zawidowski CMSIS обычно подключен через соответствующий проце... Jul 16 2018, 07:53 jcxz Цитата(__inline__ @ Jul 16 2018, 08:35) Б... Jul 16 2018, 08:00 __inline__ Цитата(jcxz @ Jul 16 2018, 09:00) Уже пис... Jul 16 2018, 08:07 jcxz Цитата(__inline__ @ Jul 16 2018, 11:07) П... Jul 16 2018, 08:17 AVI-crak Цитата(__inline__ @ Jul 16 2018, 11:35) В... Jul 16 2018, 08:35 Genadi Zawidowski Там тоже ассемблер с "неоном". Неон умее... Jul 16 2018, 08:39 jcxz Я так понимаю - Вы сами пытались оптимизировать фу... Jul 16 2018, 08:50 __inline__ Цитата(jcxz @ Jul 16 2018, 09:50) Я так п... Jul 16 2018, 14:54 jcxz Цитата(__inline__ @ Jul 16 2018, 19:21) Ч... Jul 16 2018, 18:30 __inline__ Проделал несколько экспериментов.
1) Переписал Di... Jul 17 2018, 09:01 AVI-crak Цитата(__inline__ @ Jul 17 2018, 15:01) 3... Jul 17 2018, 15:26 __inline__ Цитата(Genadi Zawidowski @ Jul 16 2018, 07... Jul 16 2018, 07:49 ViKo Рисунок врет. Например, глаза лягушонка он размыл ... Jul 16 2018, 07:26 aaarrr Цитата(ViKo @ Jul 16 2018, 10:26) Рисунок... Jul 16 2018, 07:49 ViKo Цитата(aaarrr @ Jul 16 2018, 10:49) Прост... Jul 16 2018, 07:54 __inline__ Цитата(ViKo @ Jul 16 2018, 08:26) Рисунок... Jul 16 2018, 07:54 KnightIgor Цитата(__inline__ @ Jul 16 2018, 08:54) Н... Jul 16 2018, 11:54 __inline__ Цитата(KnightIgor @ Jul 16 2018, 12:54) О... Jul 21 2018, 09:26 Arlleex Цитата(__inline__ @ Jul 21 2018, 12:26) В... Jul 21 2018, 10:13 __inline__ Цитата(Arlleex @ Jul 21 2018, 11:13) А за... Jul 21 2018, 10:41 Genadi Zawidowski CMSIS обычно подключен через соответствующий проце... Jul 16 2018, 07:53 jcxz Цитата(__inline__ @ Jul 16 2018, 08:35) Б... Jul 16 2018, 08:00 __inline__ Цитата(jcxz @ Jul 16 2018, 09:00) Уже пис... Jul 16 2018, 08:07 jcxz Цитата(__inline__ @ Jul 16 2018, 11:07) П... Jul 16 2018, 08:17 AVI-crak Цитата(__inline__ @ Jul 16 2018, 11:35) В... Jul 16 2018, 08:35 Genadi Zawidowski Там тоже ассемблер с "неоном". Неон умее... Jul 16 2018, 08:39 jcxz Я так понимаю - Вы сами пытались оптимизировать фу... Jul 16 2018, 08:50 __inline__ Цитата(jcxz @ Jul 16 2018, 09:50) Я так п... Jul 16 2018, 14:54 jcxz Цитата(__inline__ @ Jul 16 2018, 19:21) Ч... Jul 16 2018, 18:30 __inline__ Проделал несколько экспериментов.
1) Переписал Di... Jul 17 2018, 09:01 AVI-crak Цитата(__inline__ @ Jul 17 2018, 15:01) 3... Jul 17 2018, 15:26
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|