| |
 делитель частоты и джиттер делитель частоты и джиттер, влияние ПЛИС на джиттер |
|
|
|
|
 May 20 2009, 07:14 May 20 2009, 07:14
|
Гуру

Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881

|
Цитата(_Anatoliy @ May 20 2009, 08:52)  Можно поинтересоваться какой частоты удалось достичь? Цитата(des00 @ May 20 2009, 10:21) я правильно понимаю при нечетных tckg_div_coeff скважность выходного сигнала не 50/50 ? и вас это устраивало? Работает эта шняга в реальном устройстве на 210 МГц на LatticeXP (LFXP3E-3TN100C, самая медленная из них) (при оценке STA в 254 МГц и макс. допустимой частоте регистра 320 МГц ), и максимально формируемая частота 52,5 МГц (т.е. мин. коэфф. деления 4, это уже мое ограничение, произрастающее из Fmax того, что от этого работает). Это, если уж совсем конкретно, формирователь TCK в сау510усб-исо, из которого я повырезал все, связанное с адаптивным тактированием, кстати критический путь в результате тоже вырезался, именно эта схема д.б. еще быстрее. Не 50/50 при нечетных коэфф. меня мало волнует, так как разница между полупериодами всего 1 клок, меня больше волнует возможность как можно более плавно задавать частоту. Цитата(des00 @ May 20 2009, 10:21) т.к. описан самый оптимальный синхронный счетчик для фпга с 4-х входовым лютом Еще не самый... Там компаратор второго переноса 8-битный, можно еще наконвейеризировать.
|
|
|
|
|
|
|
|
May 20 2009, 11:14
|
Злополезный
Группа: Свой
Сообщений: 608
Регистрация: 19-06-06
Из: Russia Taganrog
Пользователь №: 18 188
|
Цитата(sazh @ May 19 2009, 21:04) Примерчик можно? Вот пример подобного делителя (на 2,4,6,8,10,12,14,16). Код library IEEE;
use IEEE.std_logic_1164.all;
library unisim;
use unisim.vcomponents.all;
library work;
use work.HardSynP.all;
entity DIV is port (
DIV_RG_D: in std_logic_vector(2 downto 0);
DIV_RG_CE: in std_logic;
CLK: in std_logic;
OUT_CLK: out std_logic );
end entity;
architecture Tushka of DIV is
signal DIV_RG: std_logic_vector(2 downto 0);
signal DIV_CB_CY: std_logic;
signal DIV_CB_CY_L: std_logic;
signal OUT_CLK_INT_FF: std_logic := '0';
signal OUT_CLK_IOB_FF: std_logic := '0';
attribute IOB of OUT_CLK_IOB_FF: signal is "true";
begin
DIV_RG_I: entity HS_FD(FDRE)
generic map ( nInit => 0, nX => 1, nY => 0, sUSet => "DIV_CB" )
port map ( D => DIV_RG_D, CE => DIV_RG_CE, C => CLK, INIT => '0', Q => DIV_RG );
DIV_CB_CY_FF: entity HS_CB_CI_FD(CB_CI_FD)
generic map ( nInit => 0, nX => 0, nY => 3, sUSet => "DIV_CB" )
port map ( CE => '1', C => CLK, INIT => '0', Q => DIV_CB_CY_L, CI => DIV_CB_CY);
DIV_CB: entity HS_CBRELIO(CBRELIO)
generic map ( nInit => 0, nX => 0, nY => 0, sUSet => "DIV_CB" )
port map ( D => DIV_RG, L => DIV_CB_CY_L, CE => '1', C => CLK, INIT => '0', CI => '1', CO => DIV_CB_CY );
OUT_CLK_INT_FF <= not(OUT_CLK_INT_FF) when rising_edge(CLK) and DIV_CB_CY = '1';
OUT_CLK_IOB_FF <= not(OUT_CLK_INT_FF) when rising_edge(CLK) and DIV_CB_CY = '1';
OUT_CLK_OBUF: component OBUF port map ( I => OUT_CLK_IOB_FF, O => OUT_CLK);
end architecture; Если необходимо еще выше поднять рабочую частоту, то тогда вместо DIV_CB_CY необходимо использовать DIV_CB_CY_L: Код OUT_CLK_INT_FF <= not(OUT_CLK_INT_FF) when rising_edge(CLK) and DIV_CB_CY_L = '1';
OUT_CLK_IOB_FF <= not(OUT_CLK_INT_FF) when rising_edge(CLK) and DIV_CB_CY_L = '1'; Думаю необходимо дать следующие пояснения: 1. Это переработанное ядро управляемого делителя частоты (в оригинале был 24 разрядный делитель, да и использовался сам сигнал DIV_CB_CY_L) 2. Описанная выше схема использует мою собственную библиотеку HardSyn. Эта библиотека имеет набор различных элементов оптимизированных под конкретные кристаллы (в приведенном примере для Xilinx Spartan-3x). 3. Почти все примитивы в элементах библиотеки имеют constraint RLOC, что позволяет задать взаимное расположение элементов (sUSet - задает название группы, а nX и nY - относительное положение "вершины" элемента). 4. HS_FD(FDRE) - просто D триггера. 5. HS_CBRELIO(CBRELIO) - загружаемый счетчик (необычностью данного счетчика является то, что инкремент производиться всегда, а вход L задает что сейчас необходимо инкрементировать: текущее значение счетчика (L := '0'), или входные данные - D (L := '1'). Т.к. цепи переноса никогда не блокируются, а вся логика в каждом разряде использует только 1 LUT - то достигается предельно возможное быстродействие). 6. HS_CB_CI_FD(CB_CI_FD) - триггер, предназначенный для поимки выходного переноса счетчика (использует dedicated линии переноса - имеющие "нулевую" задержку). Да, понимаю, при таком подходе лучше, конечно, использовать схемное отображение соединения блоков - нагляднее и красивее... но, видать не судьба. Со схемными редакторами есть проблемы при обновлении ПО, а эта библиотека пережила Xilinx ISE от 5.1 до 11.1, да и у AHDL со схемным редактором при смене версий тоже не всё гладко. А код на языке - он для всех версий одинаков (и можно после работы в более новой среде безболезненно возвращаться к предшествующим).
|
|
|
|
|
|
|
|
May 20 2009, 11:33
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
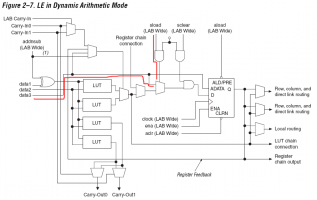
Цитата(Boris_TS @ May 20 2009, 15:14) необычностью данного счетчика является то, что инкремент производиться всегда, а вход L задает что сейчас необходимо инкрементировать: текущее значение счетчика (L := '0'), или входные данные - D (L := '1'). Т.к. цепи переноса никогда не блокируются, а вся логика в каждом разряде использует только 1 LUT - то достигается предельно возможное быстродействие). А зачем делать так хитро, не проще ли просто задействовать предразведенный вход разрешения синхронной загрузки триггера? Который также не трогает цепей переноса, и позволяет прогрузить данное непосредственно со входа без инкремента? (привешиваю для понятности того, о чем речь, пример этой цепи из одного из семейств ПЛИСов)
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
May 20 2009, 12:10
|
Злополезный
Группа: Свой
Сообщений: 608
Регистрация: 19-06-06
Из: Russia Taganrog
Пользователь №: 18 188
|
Цитата(SM @ May 20 2009, 14:33) А зачем делать так хитро, не проще ли просто задействовать предразведенный вход разрешения синхронной загрузки триггера? Который также не трогает цепей переноса, и позволяет прогрузить данное непосредственно со входа без инкремента? (привешиваю для понятности того, о чем речь, пример этой цепи из одного из семейств ПЛИСов) Вообще-то так (с мультиплексором до инкремента) даже проще получается,.. надо только привыкнуть (коэффициент для загрузки вычислять проще: Load_Data = 2^N - X, где N - разрядность счетчика, X - коэффициант деления этого счетчика). Цитата(Boris_TS @ May 20 2009, 14:14) 2. Описанная выше схема использует мою собственную библиотеку HardSyn. Эта библиотека имеет набор различных элементов оптимизированных под конкретные кристаллы (в приведенном примере для Xilinx Spartan-3x). У Xilinx несколько другое построение Logic Cell (там Slice'ы)... в которых нет SLOAD (LAB Wide), и поэтому приходиться делать именно так, как я описал. Но, собственно говоря, вопрос был про Jitter и работу на достаточно невысокой частоте. Мы же несколько отклонились от темы - как-то нехорошо получается.
|
|
|
|
|
|
|
|
May 20 2009, 18:30
|

Знающий
Группа: Свой
Сообщений: 601
Регистрация: 3-07-07
Пользователь №: 28 852
|
Всем спасибо за помощь и конструктивную критику. Я не делал никаких "assignment" - этот RTL  Квартус навалял с настройками по умолчанию. Цитата(Boris_TS @ May 19 2009, 18:25) Нормальные люди используют выходной перенос (назовём его CY) загружаемого счетчика: сам CY подается на счетный триггер, сигнал с которого подается на дополнительный выходной триггер (обязательно выходной триггер, иначе дополнительный прирост jitter’а). Дополнительно CY подаётся на вход Load это загружаемого счётчика, а вот значением, которое загружается - выбирается количество тактов, которое счетчик будет досчитывать до переноса (т.е. коэффициент деления). Спасибо за совет! Теперь у меня есть реальный шанс стать нормальным человеком! Кажется таким образом в 51-м микроконтроллере счетчики реализованы. Цитата(SM @ May 20 2009, 00:34) Ну да, в контексте конкретной задачи от автора поста самое оно, и десяток строк против килобайта текста. Моя же цель была слегка посложнее, и на частотах аццких. У меня аццких частот тут нет, всё по-божески. Цитата(dvladim @ May 20 2009, 00:12) А если есть желание избавиться от джиттера ПЛИС, то надо вынести последний триггер за пределы ПЛИС. Очень здоровая мысль! Мне требуется маленький джиттер только на одном из фронтов, по другому фронту малый джиттер не интересен.
|
|
|
|
|
|
|
|
May 20 2009, 19:25
|
Знающий
Группа: Свой
Сообщений: 654
Регистрация: 24-01-07
Из: Воронеж
Пользователь №: 24 737
|
Цитата(SM @ May 20 2009, 00:34) А я уверен. Если насильно register duplication не отключили, то если триггер не может туда лечь, то туда ложится копия этого триггера. Если отключили, то сами виноваты, констрейны это святое  Это смотря в каком случае. Если тактовый вход хитрый (формируется логикой), а глобальных линий не хватает, то не ляжет. И копия регистра не ляжет. Поэтому надо или знать арихитектуру и иметь опыт соответствующий или смотреть результаты трассировки. Цитата(sysel @ May 20 2009, 22:30) Очень здоровая мысль! Мне требуется маленький джиттер только на одном из фронтов, по другому фронту малый джиттер не интересен. Джиттер на обойх фронтах будет примерно одинаковый. Здесь основной плюс в том, что джиттер не будет зависеть от прошики в ПЛИС, а только от выбранной схемы для последнего триггера, трассировки платы и разводки питания.
|
|
|
|
|
|
|
|
May 21 2009, 18:50
|
Местный
Группа: Свой
Сообщений: 368
Регистрация: 16-11-06
Из: Тверь
Пользователь №: 22 379
|
Цитата(des00 @ May 20 2009, 10:21) т.к. описан самый оптимальный синхронный счетчик для фпга с 4-х входовым лютом А можно спросить в плане самообразования? - как я понял, увеличение быстродействия связано с изменением состояния счетчика на единицу (думаю не важно увеличение или уменьшение  ) - не нужен сумматор (довольно много логических связей), и момент достижения порога отлавливается внутренними средствами ячейки - перенос (не требуется компаратор)? Попутно - если описан компаратор, который сравнивает состояние регистра с нулем всегда будет использоваться бит переноса или иногда будет вставляться компаратор?
|
|
|
|
|
|
|
|
May 21 2009, 19:10
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Andr2I @ May 21 2009, 22:50) А можно спросить в плане самообразования? - как я понял, увеличение быстродействия связано с изменением состояния счетчика на единицу (думаю не важно увеличение или уменьшение ) - не нужен сумматор (довольно много логических связей), и момент достижения порога отлавливается внутренними средствами ячейки - перенос (не требуется компаратор)? Попутно - если описан компаратор, который сравнивает состояние регистра с нулем всегда будет использоваться бит переноса или иногда будет вставляться компаратор? Чего-то Вы все в кучу смели. Увеличение быстродействия достигается за счет уменьшения разрядности сумматоров, и укорочения длины цепочек переноса исходя из компромиса между длиной цепочки переноса (она хоть и очень быстрая, но все же не с нулевой задержкой) и задержкой управления от соседнего LUT, конвейеризирующего перенос через локальную разводку. Увеличение на единицу делается тоже сумматором. Точнее цепочкой полусумматоров, но для ПЛИС разницы в данном случае особой нет. И в сумматоре, реализованном в ПЛИС, нет "довольно много логических связей", ПЛИСы (LUT-based) оптимизированы в первую очередь на построение сумматоров. В общем изучайте внутреннюю структуру ПЛИС, задержки по разным цепям... Анализируйте... Сравнение состояния регистра с любой константой, если требуется только равенство - это просто логическая функция всех его выходов. Сравнение с переменной величиной - это тот же сумматор между первой величиной и дополнением второй, выход переноса показывает < или >=. Равенство анализируется отдельно по нулевому результату выхода сумматора, т.е. логическому ИЛИ-НЕ всех его выходов.
|
|
|
|
|
|
2 чел. читают эту тему (гостей: 2, скрытых пользователей: 0)
Пользователей: 0
|
|
|