Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум разработчиков электроники ELECTRONIX.ru _ Системы на ПЛИС - System on a Programmable Chip (SoPC) _ Свои процессоры
Автор: PVL Mar 12 2009, 19:51
Занимаюсь разработкой своего проца под SoC. Если есть предложения по системе команд и практической реализации пишем сюда.
Автор: SM Mar 12 2009, 19:58
Как классно поставлен вопрос  Свои процы делаются для своих задач и исходя из каких-то своих требований. А не так вот - давайте, мол, все советуйте и систему команд, и реализацию. Хотя бы сказали, что это за процессор, какая архитектура в основе, и т.д.
Свои процы делаются для своих задач и исходя из каких-то своих требований. А не так вот - давайте, мол, все советуйте и систему команд, и реализацию. Хотя бы сказали, что это за процессор, какая архитектура в основе, и т.д.
Автор: PVL Mar 12 2009, 20:05
 Свои процы делаются для своих задач и исходя из каких-то своих требований. А не так вот - давайте, мол, все советуйте и систему команд, и реализацию. Хотя бы сказали, что это за процессор, какая архитектура в основе, и т.д.
Свои процы делаются для своих задач и исходя из каких-то своих требований. А не так вот - давайте, мол, все советуйте и систему команд, и реализацию. Хотя бы сказали, что это за процессор, какая архитектура в основе, и т.д.Сейчас видится МИСК архитектура. Арифметика целочисленная, под простую сигналку и ИО.
Автор: Methane Mar 12 2009, 20:13
Что такое МИСК?
Автор: PVL Mar 12 2009, 20:16
Почти тоже что РИСК только с бОльшим количеством рабочих регистров 256... 1024. Идеально для блочной памяти в ПЛИС.
Автор: Methane Mar 12 2009, 20:20
И тремя тактами на операцию?
Автор: PVL Mar 12 2009, 20:23
Не для сигналки можно и больше тактов, данные ведь независимые. Сейчас прикидываю конвейер на 8... 11 тактов. Затык с тем что разные инструкции имеют разное их число. Как райт бэк согласовывать.
Автор: Methane Mar 12 2009, 20:37
Как вы из регистрового файла, сразу несколько значений собираетесь вытаскивать за один такт?
Автор: PVL Mar 12 2009, 20:39
Не поверишь...
 в плисках память двухпортовая.
в плисках память двухпортовая.
Автор: Methane Mar 12 2009, 20:49
в плисках память двухпортовая.А я и не заметил.
Пусть по две такта на команду. Или по одному но с аккумулятором. Ж)
Автор: PVL Mar 12 2009, 20:53
Пусть по две такта на команду. Или по одному но с аккумулятором. Ж)
На спартане 3Е при частоте 300 МГц за один такт ничего кроме логического И или пересылки не выполняется. Сложение 4 такта, умножение от 8 - ми. Деление пока совсем не фурычит. Плиске пришлось радиатор довесить - греется. Система команд пока не для записи во внешнюю память - аж 57 бит на инструкцию.
Автор: Methane Mar 12 2009, 21:02
Жуть Сартан, на 300, (это же типа циклона, только более убогого?) Я помню что циклона, первая, "в лоб" умножает 16х16 в 32 за 16 наносекунд умножает. Жуть.
Автор: des00 Mar 13 2009, 03:47
пройтись по этому форуму, только на моей памяти подобных пионерских тем около 5-6. В том числе я собирался заняться парой тем, но времени нет.
затем пройтись по опенкоресам, там много реализаций.
ЗЫ. на будующее учитесь писать компиляторы, отладчики и прочее
Автор: SM Mar 13 2009, 07:51
Угу, поддерживаю... У меня только порт бинутилсов занял полмесяца. А вот про С - даже думать боюсь.
Автор: Ynicky Mar 13 2009, 10:23
А у меня уже есть свой процессор. LCC осилил, а вот с ассемблером напряг.
По образованию я не программист, но приходится писать программы для отладки
железа. Нашел вот такой проект:
http://electronix.ru/redirect.php?http://sun.hasenbraten.de/vasm/index.php?view=source
Но из исходников собрать .exe не могу. Может кто поможет.
Поставил "Visual Studio 2008". Но с ней тоже надо разбираться.
У меня "Windows XP SP3".
Николай.
Автор: SM Mar 13 2009, 10:55
По образованию я не программист, но приходится писать программы для отладки
железа.
Мой совет, как уже прошедшего этот этап - берите binutils, и делайте на основе какого-то уже существующего там. Неделя на то, чтобы въехать, ну и неделя на то, чтобы свой сделать. Там, в бинутилс, "все для людей", т.е. добавить свою систему команд достаточно просто, при том, что сразу будут работать все фичи и объектного кода, и линковки.
Что интересно - я давал объявление на эту работу (за деньги), ни одного желающего не нашлось! Не то, что бы условия не устроили, а они были вполне щедрыми, а именно не было даже желающих!
Автор: Sefo Mar 13 2009, 11:40
Какой формат инструкции?
Автор: SM Mar 13 2009, 18:41
Ну почему же - расширить до 64 бит, и при шине внешней памяти шириной 128 и больше бит очень даже смотреться будет, выборка по паре или более инструкций за такт. Хотя лично я предпочитаю variable length, правда ведущую за собой серьезные усложнения декодера и схемы буфера предвыборки. (я так понял, что речь все таки в данном случае идет о суперпроизводительной числомолотилке, а не о CPU общего назначения, перекошенного под что-то конкретное)
Автор: PVL Mar 19 2009, 16:03
57 бит нужно ядру ,чтобы выполнить инструкцию. Типа откуда взять, как переключить мультиплексор разультата, как положить. С положить напряг - умноженеи и деление результат 64 бита, умножение 9 тактов, сложение 4, деление 12 кароче баги с конвейером.
Во первых систему команд, хочется уложить в 16 бит дабы не юзать БГА корпус. Народный проц хочу сделать.
Во вторых уже не просто числомолотилка поскольку есть спец узлы под фурье и вейвлет, на числомолотилке раз в 10 медленнее будет.
Шина 96 бит - читать шесть инструкций за такт дабы работать на СРАМ. С динамикой пока лениво связываться.
И вообще сейчас есть спартан 3Е - 500к. На нем не далеко уити от числомолотилки..
Автор: SM Mar 19 2009, 17:28
Автор: Harbour Mar 21 2009, 11:19
Не надо ля-ля, помню обьяву, просто был дико занят в тот момент

Автор: PVL Mar 24 2009, 14:54
Что такое binutils? Готовая среда для разработки С - компайлера? Где взять? Подскажите , а то сейчас с программерами сношаюсь - достали
Автор: Ynicky Mar 24 2009, 16:53
http://electronix.ru/redirect.php?http://ftp.gnu.org/gnu/binutils/binutils-2.19.1.tar.gz
Автор: SM Mar 24 2009, 19:13
нет, готовая среда для разработки С компайлера это gcc
А binutils это binutils - ассемблер, линкер, objdump, и прочее вокруг
Автор: Maverick Mar 25 2009, 06:29
А можно узнать как Вы делаете целочисленное деление за 12 тактов, наверное при разрядности данных 32 или 16.
Поделитесь пожалуйста алгоритмом, а лучше описанием на VHDL (идеальный вариант
 )/Verilog (если конечно это возможно) А binutils это binutils - ассемблер, линкер, objdump, и прочее вокруг
)/Verilog (если конечно это возможно) А binutils это binutils - ассемблер, линкер, objdump, и прочее вокруга не подскажите где можно взять готовую среду - gcc?
Автор: SM Mar 25 2009, 08:33
Поделитесь пожалуйста алгоритмом, а лучше описанием на VHDL (идеальный вариант
)/Verilog (если конечно это возможно)А в чем вопрос-то? Например деление за два такта делается при помощи комбинаторного "полуделителя", который при N-битном входе дает N/2-битное частное и N-битный остаток. Деление за 3 такта - "третьделителя" - соотв N/3 и N. Ну и так далее.
вот пример полнофункционального делителя, который делит 8/8 бит за 1 такт, а 16/16 бит за два такта, с поддержкой дробного деления и чисел со знаком.
input [15:0] num; // numerator
input [15:0] den; // denominator
output [15:0] quot; // quotient
output [15:0] rem; // remainder
output divz, n_out; // divide-by-zero & sign bits
input m16, sn, sd, frct, n_in, cycle, clock; // 8/16_mode, numerator_signed, denominator_signed, fractional/normal, sign_from_PSW, cpu_cycle_#, clock
wire [15:0] int_den, int_num, int_quot, ext_num, ext_den, int_rem;
wire nsgn, dsgn, qsgn;
assign nsgn = sn & (m16 ? num[15] : num[7]);
assign dsgn = sd & (m16 ? den[15] : den[7]);
assign qsgn = nsgn ^ dsgn;
assign ext_num = m16 ? num : { {8{nsgn}}, num[7:0]};
assign ext_den = m16 ? den : { {8{dsgn}}, den[7:0]};
assign int_num = (ext_num ^ {16{nsgn}}) + nsgn;
assign int_den = (ext_den ^ {16{dsgn}}) + dsgn;
assign divz = !(|int_den);
wire en_frct = frct & (int_num < int_den); // fractional mode only if |num| < |den|
wire numz = !(|int_num);
reg [3:0] i;
reg [16:0] temp;
reg [15:0] save_rem;
reg [17:0] temp1;
reg [7:0] out, save_out;
always @*
begin
temp = cycle ? {save_rem, int_num[7] & !(en_frct)} :
(en_frct ? {int_num, 1'b0} : {16'h0000,int_num[m16?15:7]});
for (i=0; i<8; i = i+1'b1)
begin
temp1 = temp - int_den;
out[7-i] = !temp1[17];
if (i != 7) temp = {(temp1[17] ? temp[15:0] : temp1[15:0]), int_num[(cycle | !m16) ? (6-i) : (14-i)] & !(en_frct)};
else temp = {1'b0, (temp1[17] ? temp[15:0] : temp1[15:0])};
end
end
always @(posedge clock)
if (!cycle) save_rem <= temp[15:0];
always @(posedge clock)
if (!cycle) save_out <= out;
assign int_quot = {save_out, out};
assign int_rem = temp[15:0];
// sign of remaider :
// sign of remainder is equal to sign of numerator.
assign rem = (int_rem ^ {16{nsgn}}) + nsgn;
// sign of quotient :
// fractional mode - quotient always positive
// integer mode - quotient has sign of den*num
wire t_qsgn = qsgn & !frct;
assign quot = (int_quot ^ {16{t_qsgn}}) + t_qsgn;
// sign output:
// fractional mode - if numerator not zero, put sign into N
// integer mode - put sign into N
assign n_out = (!numz | !frct) ? qsgn : n_in;
endmodule
ну как бы gcc.gnu.org
Автор: Maverick Mar 25 2009, 11:03
Спасибо за исчерпающий ответ
Автор: yes Mar 25 2009, 18:01
я всегда думал, что MISC это minimal instruction ...
то есть по русски - безоперандный (или стековый) комп
http://electronix.ru/redirect.php?http://en.wikipedia.org/wiki/Minimal_instruction_set_computer
(кстати там по ссылке есть и OISC one ... - имхо, cool)
примеры таких - всякие лисп/форт/жава компутеры
для ПЛИС есть ZPU (имхо, интересно, но мне не увы нужно)
http://electronix.ru/redirect.php?http://www.zylin.com/zpu.htm
Автор: PVL Mar 29 2009, 15:34
то есть по русски - безоперандный (или стековый) комп
http://electronix.ru/redirect.php?http://en.wikipedia.org/wiki/Minimal_instruction_set_computer
(кстати там по ссылке есть и OISC one ... - имхо, cool)
примеры таких - всякие лисп/форт/жава компутеры
для ПЛИС есть ZPU (имхо, интересно, но мне не увы нужно)
http://electronix.ru/redirect.php?http://www.zylin.com/zpu.htm
Это ЛАЖА ,а не процессор. 300 ЛУТ таблиц 95 МГц. ААААхренеть производительность. У меня без нагрева шарашит на 240 МГц комерческий Спартан 3е работает. Индустриальные добегают до 300... 350 или 200 МГц на -40 градусов цельсия. Правда ПЛИС на 500 к ушла вся.
Автор: yes Mar 30 2009, 10:35
а что С++ и eCos у Вас работают?
имхо, не надо путать теплое с мягким - написать стэйтмашинку которая работает на спартане это одно (у меня в прошлом проекте автоматом вышло ~200МГц без каких-либо усилий с моей стороны), а написать процессор, который можно применять для процессорных задач (то есть компилятор, ОСь и т.п.) это совершенно другой уровень задачи
Автор: Ynicky Jun 13 2009, 11:04
Чтобы не плодить новую тему, напишу сдесь. Если, конечно, автор темы не против.
Недавно прикрепили ко мне студента, а так как в связи с кризисом и мне то делать
особо нечего, то чего уж говорить про бедного студента. Поэтому решил ему дать
интересную тему (с моей точки зрения) для обучения разработке soc проектов
со встроенным процессорным ядром (чем собственно я и занимаюсь).
За основу взяли студенческое risc ядро, описанное в книге Сергиенко А.М.
“VHDL для проектирования вычислительных устройств”. Систему команд и архитектуру
немного доработали. Сделали простенький soc проект в Active-HDL81 для FPGA ф.Actel.
Его, собственно, и предлагаю для повторения всеми желающими. С некоторыми доработками
его можно реализовать и для других FPGA. Пока, для простоты,
пзу команд сделали в виде vhdl. Хотелось бы общими усилиями протестировать
процессорное ядро. Да и может кому пригодится. Оговорюсь сразу, проект сырой.
Поэтому будут исправления и доработки. Может у кого будут дельные предложения.
Готов рассмотреть. Краткое описание процессора можно найти в Директории "Doc".
Ассемблер - в директории "st16asm". Я его делал в "Microsoft Visual Studio 2008".
Еще не разобрался, как сделать, чтобы ".exe" файл запускался на других компьютерах,
где нет MSVC2008 (не программист). Компилятор сделаю попозже, после отработки
системы команд. Это будет LCC, так как есть уже опыт написания
"machine description" файлов под свою систему команд. Ну вот, собственно, пока все.
Будут вопросы, задавайте.
Николай.
Автор: Ynicky Jun 14 2009, 14:30
Выкладываю новую версию проекта.
Просьба сообщить, работает ли ассемблер у кого нет "Microsoft Visual Studio".
Николай.
Автор: Leka Jun 14 2009, 18:27
Команды Break и LU - что делают?
И зачем выделенный регистр SP (при отсутствии команд push/pop и аппаратном стеке возвратов)?
Автор: Ynicky Jun 14 2009, 19:02
И зачем выделенный регистр SP (при отсутствии команд push/pop и аппаратном стеке возвратов)?
LU - Load Byte Unsigned. Беззнаковая загрузка байта.
Команда Break нужна только при отладке ПО с помощью внутрисхемного эмулятора, если память программ является оперативной. Вместо команды на которой ставится точка останова заносится Break. При дальнейшем пуске Break заменяется обратно на штатную команду. Если память программ - ПЗУ, то точки останова прописываются через JTAG в специальный регистр внутрисхемного эмулятора. С помощью аппаратного компаратора сравнивается текущий адрес команды и адрес точки останова. При совпадении происходит остановка процессора. Через JTAG процессор можно снова запустить, блокировав сигнал с компаратора на один период тактовой частоты процессора.
Регистр SP - это регистр общего назначения, используемый программой в качестве указателя на стек данных.
Николай.
Автор: Leka Jun 14 2009, 19:39
Работает.
Автор: des00 Jun 15 2009, 02:59
для тех кто альдеком не пользуется, могли бы и vhd файл из risc_cpu.bde сгенерировать, делов то на минуту

зачем "По сигналу RESET разряды всех регистров обнуляются." вот это сделали ? это сразу режет вам крылья, при использовании на хилой платформе + файл rfile.vhd -> R_RF4:process(CLK,RST,data_w,rfsel) вот вас прибило каждый регистр ручками описывать %)))
в файле tst_alu.asm есть такой код
lea r5,0x0
но в доке Doc\to101st16.doc
команды lea нет.
Автор: Ynicky Jun 15 2009, 06:42
зачем "По сигналу RESET разряды всех регистров обнуляются." вот это сделали ? это сразу режет вам крылья, при использовании на хилой платформе + файл rfile.vhd -> R_RF4:process(CLK,RST,data_w,rfsel) вот вас прибило каждый регистр ручками описывать %)))
в файле tst_alu.asm есть такой код
lea r5,0x0
но в доке Doc\to101st16.doc
команды lea нет.
1. Эти файлы генерятся автоматически при каждой компиляции и находятся в директории compile.
2. Виноват, соврал. При использовании в качестве регистрового файла внутренней памяти исходное значение берется из файлов инициализации (r8x256_M0.mem). rfile.vhd - как пример на регистрах.
3. lea - Load Effective Address. Это псевдокоманда для занесения в регистры констант.
lea r5,0xFF00 преобразуется ассемблером в
imm 0xFF00
addi r5,r0,0
Но можно писать и как в tst_alu.asm.
Если успею, вечером добавлю в описание.
Николай.
Автор: SFx Jun 15 2009, 07:34
смотрите файлы из архива, они как раз вам и нужны
risc_st.rar\risc_st\risc_st_core\compile\risc_st_core.vhd
risc_st.rar\risc_st\risc_st_core\compile\risc_sync.vhd
З.Ы. пардон, страницу не обновил....
Автор: Ynicky Jun 15 2009, 17:13
Исправили ошибки загрузки/выгрузки.
Николай.
Автор: Ynicky Jun 17 2009, 15:07
Подкорректировали проект.
Проверили прерывания.
Дополнил описание.
В принципе проект "готов".
Осталось доделать внутрисхемный эмулятор для работы с отладчиком (программа на PC).
Николай.
Автор: Ynicky Jul 1 2009, 05:52
Написали JTAG на vhdl, чтобы можно было проект зашить в другие FPGA (останется поменять ОЗУ).
Отмоделировали команды (stop, step, run) внутрисхемного эмулятора.
Подработал ассемблер.
Написал еще несколько тестовых программок.
Проверили в железе работу с семисегментным индикатором.
Николай.
Автор: Ynicky Jul 8 2009, 07:06
Добавили 2 блока к внутрисхемному эмулятору.
Отмоделировали чтение памяти команд и данных в режиме отладки.
Остальное - после отпуска.
Николай.
Автор: Ynicky Sep 10 2009, 18:18
Добавили блок чтения регистрового файла в режиме отладки.
Николай.
Автор: kuchynski Oct 16 2009, 06:37
Пользуюсь своим процессором 5 год, за это время и отладил до безглючности. Работает на Xilinx.
Из плюсов:
язык форт, встроенные uart, фильтры с плавающей точкой, делители, разрядность до 32 бит с/без знака, переменное число поддерживаемых команд.
Из минусов:
средний текстовый редактор, недописанный отладчик, полностью отсутствует описание.
Автор: Aner Oct 16 2009, 09:58
Из плюсов:
язык форт, встроенные uart, фильтры с плавающей точкой, делители, разрядность до 32 бит с/без знака, переменное число поддерживаемых команд.
Из минусов:
средний текстовый редактор, недописанный отладчик, полностью отсутствует описание.
респект и уважение за такое.
Хотелось узнать следующее из плюсов/ минусов:
Тактовая, производительность в ~мипсах для математики, если подсчитывали.
Если сравнить с имеющимися ARM_ами то вот к какому ближе (по архитектуре) и есть ли преимущество и в чем?
По потреблению наверное проигрыш. Насколько хорош компилятор из форта получился?
Дебагер тоже наверное медленный, не реалтайм. С описанием понимаю вас, такое часто бывает. Поскольку требует много времени.
Автор: kuchynski Oct 21 2009, 09:10
Если сравнить с имеющимися ARM_ами то вот к какому ближе (по архитектуре) и есть ли преимущество и в чем?
По потреблению наверное проигрыш. Насколько хорош компилятор из форта получился?
Дебагер тоже наверное медленный, не реалтайм.
Несколько лет назад таких ARM не было, сейчас не знаю. Основное преимущество - переменная разрядность, требуеться 23 разряда - будет 23-х разрядный проц, знаковый бит не надо - убираем, лишнего в микросхеме никто не возмёт.
Все операции(кроме деления, фильтра) выполняются за один такт, работает на 48 Мгц на XC3S400-4PQ208C при 20 разрядах ядра, больше просто не подавал.
Форт хорош тем, что: 1. небольшой код программы(отсутствует поле адреса регистра); 2. при прерываниях не нужно сохранять ни одного регистра; 3. более высокий уровень письма, чем у ассемблера, поскольку компилятор самоделанный, писать можно в буквальном смысле на русском языке.
Дебагер - отстой, не пользуюсь.
и не для кого его писать! Похвастался здесь и хорошо, платят совсем за другое.
Автор: OverDrewk Oct 23 2009, 04:57
По образованию я не программист, но приходится писать программы для отладки
железа. Нашел вот такой проект:
http://electronix.ru/redirect.php?http://sun.hasenbraten.de/vasm/index.php?view=source
Но из исходников собрать .exe не могу. Может кто поможет.
Поставил "Visual Studio 2008". Но с ней тоже надо разбираться.
У меня "Windows XP SP3".
Николай.
Смотри инструкцию, под Windows может и не соберешь. Исходя из содержимого vasm.tar.gz по данному линку надо ставить Linux, ну или minGW(под Windows) и собирать проект. Инструкция http://electronix.ru/redirect.php?http://sun.hasenbraten.de/vasm/index.php?view=compile
Автор: Ynicky Oct 23 2009, 16:07
Пошел по пути наименьшего сопротивления. Переделал свой процессор на MIPS32,
т.к. изначально делал его под эту архитектуру.
Поставил SDE v6. И теперь не знаю проблем ни с С ни с ASM-ом.
Единственное разочарование - не своя система команд.
Николай.
Автор: Leka Oct 23 2009, 17:32
Ну и каковы результаты синтеза?
Автор: Ynicky Oct 23 2009, 19:27
Пока не доделал блок MDU (multiply divide unit), поэтому результат синтеза без него.
Николай.
Автор: Leka Oct 23 2009, 20:26
~2K LUT - немного по сравнению с LEON/OpenRISC/Cortex-M и тп.
Без внешней памяти получится запустить что-либо дельное, написанное на Си?
Автор: Ynicky Oct 23 2009, 20:39
Так это только ядро. Без кэш программ и данных. Без FPU.
Я в свое время синтезил leon2, точные цифры не помню, но сравнивал со своим процессором.
Результаты были не в мою пользу. Но у меня было много мультимедийных инструкций.
Николай.
Эту версию (MIPS32) еще не применял в серьезных разработках.
Но предыдущий процессор используется в MP3 камкордере со встроенной памятью
128 кБ ПЗУ программ и 64кБ ОЗУ программ/данных (правда в ASIC-е на 0,18мкм).
Николай.
Автор: Leka Oct 23 2009, 20:45
Вот и спрашиваю, можно каким Си-компилятором создавать более-менее практичные приложения для системы с несколькими Кбайтами памяти(те без внешней памяти).
Для FPGA, не для ASIC.
Автор: Ynicky Oct 23 2009, 20:47
Можно, например WEB камера (без звука, в системах безопасности) на основе камкордера занимает у меня 32 кБ кода, написанного на С.
А FPGA - это промежуточная стадия перед ASIC-ом.
Николай.
Автор: Leka Oct 23 2009, 21:20
Значит все-таки для ASIC. Для FPGA и 8КБ памяти м/б максимумом (для кода+данные).
Автор: flipflop Dec 5 2009, 14:19
Кто-нибудь реализовал MMU? Поделитесь опытом.
Не совсем понятно, как его реализовать таким образом, чтобы чтение и запись из памяти проходило за один такт (не хочется отходить от классической схемы 5-6 ступенчатого конвейера).
Автор: Ynicky Dec 6 2009, 09:41
Не совсем понятно, как его реализовать таким образом, чтобы чтение и запись из памяти проходило за один такт (не хочется отходить от классической схемы 5-6 ступенчатого конвейера).
А что значит за один такт?
Если обращение происходит к внутренней памяти малого объема (например к встроенной в FPGA)
или к кеш первого уровня (также малого объема) то это можно сделать и за один такт.
Если Вам надо обратиться к дальней памяти или кеш второго уровня (например для заполнения кеш первого уровня),
то в этом случае нужна остановка процессора (stall). А количество тактов в конвейере тут не причем.
Николай.
Автор: flipflop Dec 6 2009, 10:27
Если обращение происходит к внутренней памяти малого объема (например к встроенной в FPGA)
или к кеш первого уровня (также малого объема) то это можно сделать и за один такт.
Если Вам надо обратиться к дальней памяти или кеш второго уровня (например для заполнения кеш первого уровня),
то в этом случае нужна остановка процессора (stall). А количество тактов в конвейере тут не причем.
Николай.
Это понятно. Рассматриваем только кэш первого уровня: все равно, получается так, что выборка команды и доступ к памяти данных тянет за собой всю производительность.
У меня 32-разрядный RISC (load/store) процессор, целевая микросхема Spartan-3AN (XC3S700AN-FG484):
1) Какую память использовать для кэша: блочную или распределенную?
2) Какой уровень ассоциативности/размер тэга оптимален?
3) Есть ли смысл (с точки зрения производительности) разбить выборку команды и доступ к памяти на 2 ступени? Выигрыш в частоте вполне реален, но конвейер становиться на 2 ступени длиннее, причем одна из них всегда работает в холостую.
Автор: Ynicky Dec 6 2009, 12:45
В моем последнем процессоре как раз это и используется.
Команды ветвления при этом имеют два слота задержки, но я на это пошел,
так как только используя слоты можно не потерять в производительности.
Только приходится критичный код править в ассемблере, т.е. переставлять команды,
т.к. компилятор не может это сделать сам.
Еще я сделал флаг в командах ветвления для аннулирования слотов задержки.
Это позволяет немного сократить код (не надо в пустые слоты добавлять nop).
Но этим я пользуюсь редко.
Так же и с данными. Если результат загрузки регистра не используется в следующих
командах, то процессор не останавливается.
Но при этом также, в большинстве случаев, требуется правка кода вручную.
Что касается первых двух пунктов, то оптимальный результат может дать только перебор различных комбинаций.
Николай.
Автор: flipflop Dec 6 2009, 12:54
Команды ветвления при этом имеют два слота задержки, но я на это пошел,
так как только используя слоты можно не потерять в производительности.
Только приходится критичный код править в ассемблере, т.е. переставлять команды,
т.к. компилятор не может это сделать сам.
...
Что касается первых двух пунктов, то оптимальный результат может дать только перебор различных комбинаций.
Николай.
Ясно, значит я все правильно понимаю и проблемы вполне реальные .
Если не секрет, какой частоты и на каком кристалле вам удалось добиться?
Автор: Ynicky Dec 6 2009, 13:06
Если не секрет, какой частоты и на каком кристалле вам удалось добиться?
В ASIC-е на 0,18 - 250 МГц.
Но там много мультимедийных инструкций, тормозящих процессор.
Николай.
Автор: flipflop Dec 6 2009, 13:21
Но там много мультимедийных инструкций, тормозящих процессор.
Николай.
Ого, а где вы их производите?
Автор: Ynicky Dec 6 2009, 13:34
Ну не в России же.
Николай.
Автор: Ynicky May 23 2010, 16:56
Перешел в тему "Свои процессоры" из "Цифровой видеокамеры".
Предлагается всем поучаствовать в обсуждении открытого RISC процессора
с большим регистровым файлом. Выкладываю краткое описание процессора.
Пока не охвачена тема доступа к специализированным регистрам, т.е
формат команд для доступа к ним. Какие еще нужны (frame pointer, variable pointer)?
По мере устаканивания архитектуры и системы команд, буду
выкладывать проект на VHDL.
Николай.
Автор: Leka May 24 2010, 21:01
Я бы упростил систему команд, все-таки большинству ASIC недоступен, и упор лучше делать на достижение приемлемых характеристик в FPGA.
В "своих процессорах" до сих пор самой сложной задачей являлся софт, так что конкретно обсудить архитектуру лучше после первых версий компилятора с "ассемблерного Си" (начал делать).
Мой ник лучше убрать из титульного листа, тк не автор данной архитектуры, и VHDL не знаю. У меня архитектура другая - нет типов, нет флагов АЛУ, и тд.
Автор: Ynicky May 25 2010, 05:43
Я как раз и собираюсь "пощупать" процессор в FPGA.
Хотя это будет Virtex5 (на работе отдаю новую схему пп для разводки). Туда много чего влезет.
Планирую одну такую платку взять домой на время.
Но можно и попроще.
А как можно сделать if...else без флагов?
Можно, конечно, сделать команды "branch" (BR) без CMP так:
BR if RD = 0, RD /= 0, RD < 0, RD >= 0 и т.д.
Хотя это теже флаги без сохранения в регистре.
Но при этом смещение будет в 12 разрядов или в 32 разряда с предварительной командой IMM.
Николай.
Автор: =AK= May 25 2010, 07:26
1. RISC неэффективно расходует память программ
2. Большой регистровый файл - значит, контекст сохранять долго. Значит, на прерывания медленно будет реагировать.
А кто компилятор будет делать под такую архитектуру? Или предполагается его на ассемблере мутузить?
Автор: Leka May 25 2010, 08:01
Пример бесфлагового процессора - NIOS II, даже переноса нет.
А зачем сохранять контекст? Все переменные подпрограммы прерывания - статические. Если нужна реентрабельность - свой собственный статический стек.
Для начала - "ассемблерное" подмножество Си (см пример "N-ферзей" в предыдущей ветке), потом расширяем компилируемое подмножество.
Автор: Ynicky May 25 2010, 11:12
Мой опыт в проектировании процессоров говорит, что надо начинать проверку с условных команд
ветвления (BR) и конвейера обработки данных. Так что желательно сейчас сосредоточиться
на этих командах. Если бы места в коде команд хватило бы на 2 регистра и смещение, то я бы
сделал команды условных ветвлений как в NIOSII и MIPS32.
Николай.
Автор: Ynicky May 25 2010, 15:21
Начал делать АЛУ и сразу возникла мысль: в операциях формата RI
поменять местами RD и RS. Тогда получим:
RR: RD = RD opalu RS (пример на ассемблере: add rd,rs)
RI: RD = RS opalu IMM (пример на ассемблере: addi rd,rs,imm)
При этом в формате RI регистр-источник и регистр-приемник могут быть разными.
To Leka: это не усложнит компилятор?
Николай.
Автор: Leka May 25 2010, 17:45
Не усложнит.
Автор: Leka May 25 2010, 21:47
Проблема вот в чем.
На уровне "ассемблерного" Си нет оптимизации, поэтому для 2х- и 3х- операндных архитектур запись одного и того-же алгоритма д/б различной для достижения оптимума по объему кода и быстродействию.
На примере кода N-ферзей.
Если для 3х-операндной архитектуры оптимально использование индексных массивов "arow[pos]", "arow[pos1]", и тд, то для 2х-операндной архитектуры оптимальнее будет использование модифицируемых указателей "*arow", "*arow1", и тд. Тк одной 3х-операндной инструкции:
arow[pos1] = temp;
непосредственно соответствуют три 2х-операндные инструкции:
tmp = arow;
tmp += pos1;
*tmp = temp;
Ветвления:
"if( pos != N )..." - одна бесфлаговая 3х-операндная инструкция, или
"if( pos - N != 0 )..." - две флаговые 2х-операндные инструкции (сравнение + ветвление), или
"if( tmp=pos, tmp -= N, tmp != 0 )..." - три бесфлаговые 2х-операндные инструкции.
Пришел к выводу, что используемое "ассемблерное" подмножество Си д/б жестко привязано к целевой архитектуре, те все преобразования выражений вынести из уровня компиляции:
"ассемблерное" подмножество Си --> машинные коды,
на уровень компиляции:
к-л подмножество Си --> "ассемблерное" подмножество Си.
На код самого компилятора ("ассемблерное" подмножество Си --> машинные коды) это слабо повлияет, тк все особенности архитектуры предполагаю вынести во внешние таблицы(файлы) - делаю универсальным, чтобы и для своих процессоров использовать.
Автор: =AK= May 26 2010, 07:43
Для того, чтобы обработку прерывания делать на С. И для того, чтобы более высокоприоритетное прерывание могло прервать низкоприоритетное (это не совсем реентерабельность).
А если свой собственный стек - что в нем сохранять-то? Все регистры - слишком долго, веть их же много. А если запретить использовать все, то на фиг их надо было делать много?
Две страницы регистров - отдельно для "нормальной" работы, отдельно для прерываний - выглядит более прогрессивным решением, чем просто много регистров. Еще больше страниц регистров, которые бы образовали стековую структуру, выглядит еще более заманчивым. А на каждой странице много регистров не нужно.
Ссылочку приведите
Автор: Leka May 26 2010, 08:28
Если регистры не используются одновременно разными подпрограммами, то сохранять их не нужно. Если регистров много - их можно без конфликтов распределить по подпрограммам, и сохранять ничего не придется.
Прерывания в процессоре с 1К регистров у меня реализованы, пишутся на "автокоде"( http://electronix.ru/forum/index.php?showtopic=52166&st=120&p=605442&#entry605442 ), никаких потерь на входе/выходе.
"Ассемблерный" Си для 3х-операндной архитектуры: http://electronix.ru/forum/index.php?showtopic=76026&view=findpost&p=760789
Автор: =AK= May 26 2010, 11:14
Если вы пишете на ассемблере и вручную распределяете регистры и задаете их использование, то не нужно. Да, еще одно условие: вы не используете подпрограмм. Вся ваша программа должна быть написана как линейный "спагетти" код на ассемблере, это обязательное условие, чтобы не сохранять регистры.

Автор: Leka May 26 2010, 12:36
Из:
int
count,
arow[20],
...
автоматически создается:
queens_return;
queens_N;
queens_count,
queens_arow[20],
...
queens(){
...
с соответствующим переименованием всех переменных.
Все переменные стали глобальными, вызов "cnt=queens(8);" преобразуется в:
queens();
cnt=queens_return;
И так для всех подпрограмм.
Если не хватит ~1К адресного пространства для всех таких переменных, тогда только и придется организовывать программное сохранение/восстановление контеста, и тп - для некритичного кода. И вовсе не обязательно сохранять/восстанвливать весь регистровый файл. Имхо, очень удобно для небольших систем без монстроидальных ОС.
Автор: =AK= May 26 2010, 12:46
...
И так для всех подпрограмм.
Я в одной подпрограмме вызову другую, а она пропишет свои временные переменные поверх задействованных. Вот и придется вам весь код раскатать в плоский "блин", без подпрограмм (функций). Или же строго следить за "уровнем": main может использовать одни переменные, подпрограммы первого уровня (их можно вызывать только из main) - другие, подпрограммы второго уровня - свой набор, и т.п. Маразм, короче. Архаическое программирование в стиле старых PIC-ов на ассемблере.
Автор: Leka May 26 2010, 13:11
А нету временных переменных. Как после:
#define int static int
и тп.
Проверено на практике на "автокоде" - подпрограммы из подпрограмм вызываются без к-л ограничений, прерывания тоже работают.
Автор: Ynicky May 26 2010, 17:40
Может я, конечно, чего не понимаю.
Я пока не задавал глупых вопросов про служебные регистры, потому что думал рано. Но их в систему команд все равно придется вводить. К ним я планировал добавить "frame pointer" или как его там назвать. Компилятор знает сколько регистров надо зарезервировать для подпрограммы. При вызове подпрограммы во "frame pointer" записывается это значение (или добавляется к его содержимому). А дальше адрес регистров вычисляется в аппаратуре прибавлением текущего адреса к "frame pointer".
При выходе из подпрограммы - вычитать это значение.
Но что делать, если "frame pointer" перешагнет через максимальное число регистров? Тут я могу завести это событие на NMI или вызвать TRAP. Поправьте, если что-то недопонял.
Николай.
Автор: Leka May 26 2010, 19:59
потому что думал рано. Но их в систему команд все равно
придется вводить. К ним я планировал добавить "frame pointer"
или как его там назвать...
Тогда регистры придется делить на локальные и глобальные, и делать мультиплексор(или что другое) на входе адреса. И сразу делать 3х-операндную архитектуру, тк для 2х-операндной такое не имеет смысла, имхо.
Как обращаться к служебным регистрам из Си - еще не решил, важно обеспечить простоту отладки "ассемблерного" Си-кода на ПК со стандартным Си-компилятором (сам использую открытый Tiny C Compiler). Предлагайте варианты.
http://electronix.ru/redirect.php?http://ru.wikipedia.org/wiki/Tiny_C_Compiler
Автор: Leka May 27 2010, 05:04
Гораздо проще придумать свой язык и компилятор к нему, чем делать компилятор к Си.
Масса вопросов типа:
В каком порядке будут вызываться функции a(), b(), c(), и почему?

Автор: Leka May 27 2010, 08:08
Вся система команд с учетом архитектуры будет описываться в отдельном файле, в таком примерно формате:
001 01000 dddddddddddd ssssssssssss
dddddddddddd += kkkkkkkkkkkk
010 01000 kkkkkkkkkkkk dddddddddddd
dddddddddddd += hhhhhhhhhhhhhhhhhhhhkkkkkkkkkkkk
000 00101 xxxxhhhhhhhh hhhhhhhhhhhh
010 01000 kkkkkkkkkkkk dddddddddddd
* ssssssssssss = dddddddddddd
011 xx110 dddddddddddd ssssssssssss
dddddddddddd = * ssssssssssss
011 xx010 dddddddddddd ssssssssssss
dddddddddddd < ssssssssssss
001 00110 dddddddddddd ssssssssssss
110 x0100 pppppppppppp pppppppppppp
...
Это избавит от необходимости переделывать компилятор с "ассемблерного" Си при изменениях в архитектуре (система и разрядность команд, число операндов, регистров, ...).
Автор: =AK= May 27 2010, 08:59
Насколько мне известно, типичная программа на С в основном использует как раз таки временные переменные. Глобальных в программах немного, зато чуть не в каждой функции - несколько локальных: счетчик цикла, промежуточные результаты, и т.п. Вы предлагаете процессор, при использовании которого временных переменных вообще нет, все они сделаны глобальными. Соответственно, программы потребуют в несколько раз больше памяти данных. То есть, мало того, что ваш процессор неэффективен по использованию памяти программ (поскольку RISC), он, оказывается, и память данных (регистры) транжирит. По-моему, от таких архитектур давным-давно отказались, как от неэффективных.
Я, кстати, свои первые программы писал для машины с 45-разрядными словами и 3-адресными командами. БЭСМ-4 называлась, чудо техники начала 60-х. Дежавю.
Автор: Ynicky May 27 2010, 09:21
Как обращаться к служебным регистрам из Си - еще не решил, важно обеспечить простоту отладки "ассемблерного" Си-кода на ПК со стандартным Си-компилятором (сам использую открытый Tiny C Compiler). Предлагайте варианты.
Вообще то лучше сделать служебные регистры в виде сопроцессора как в MIPS32,
и доступ к ним организовать через команды mtcp (move to coprocessor) и mfcp (move from coprocessor).
А что касается компиляторов, то я дело имел только с LCC.
И еще, меня никто не поправил насчет нового формата RI.
Тут я ошибся (сказывается опыт работы с 3-х операндными командами).
Для регистров есть только одно поле в команде, так что 2 регистра и смещение не могут быть
в одной команде 2-х операндных инструкций.
Описание нужно вернуть к версии 1.0.0.
Николай.
Вы, наверно, имеете в виду процессоры с фиксированной длиной команд, а не RISC.
Есть RISC-и с переменной длиной команд, где код используется эффективно.
Но это (фиксированная длина команд) окупается простотой реализации.
Николай.
Автор: Leka May 27 2010, 09:31
На проценты, а не в разы, тк память данных - не только простые переменные и указатели, но и массивы, и в большинстве полезных программ основной объем данных приходится на массивы. А массивы хранятся не в регистровом файле.
В ветке, где приводил пример программы N-ферзей на автокоде, предлагал сравнить эффективность архитектур на разных софт-процессорах - никто не откликнулся.
Эффективность использования памяти программ гораздо сильнее зависит от качества кода, чем от разрядности команд. Пример - Tiny C Compiler, 100Кб кода против десятков Мб от других разработчиков.
Удачное разбиение кода на маленькие подпрограммы - самый эффективный способ сжать код, поэтому важны малые издержки на вызовы пп. Например, у меня команда call совмещена с пересылкой регистр-регистр, а ret - c любой операцией алу:
f(&a); - одна инструкция на вызов пп с передачей аргумента,
f(int *a){ return *a >>= 8; } - одна инструкция на всю пп.
Автор: =AK= May 27 2010, 10:04
Есть специальная контора, которая сравнивает - http://electronix.ru/redirect.php?http://www.eembc.org/ Бенчмарки, приведенные в http://electronix.ru/redirect.php?http://www.ptsc.com/documentation/PTSC_Presentation.pdf, меня лично вполне убедили, что с большим отрывом лидирует стековая архитектура
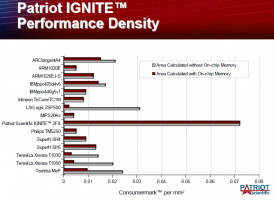
|
Автор: Leka May 27 2010, 12:19
Презентации - неинтересно.
Первая попавшаяся нерекламная ссылка по IGNITE: http://electronix.ru/redirect.php?http://java.epicentertech.com/Archive_Embedded/Patriot_Scientific/Ignite%20Processor%20-%20Java/
Автор: Ynicky May 30 2010, 07:15
Ну вот, выкладываю первую версию процессора.
Проект сделан в ACTIVE-HDL 8.2. На нем проще моделировать.
На конечном этапе сделаю в ISE для Xilinx и в QuartusII для альтеры.
Память программ и регистровый файл сделал пока поведенческими для быстроты моделирования.
Программу проверки пишу в кодах (файл prg.txt). Оказалось не очень нудно,
т.к. простые форматы команд. Отладил почти все условия ветвления в командах BRcc.
АЛУ полностью пока не проверял (только частично в тестах BRcc).
To Leka: В принципе, можно уже моделировать программу N-ферзей.
Хорошо бы компилятор мог на выходе записывать текстовый файл (как prg.txt).
Но это не обязательно. Я, наверно, смогу сам преобразовать из других форматов.
И еще: В директории doc находится новая версия описания RF32.
Николай.
Автор: des00 May 30 2010, 10:32
Спасибо конечно, но вот те кто не пользуются альедеком должны вытаскивать структуру из скомпилированного bdf файла? Это я к тому что структурная и функциональная схема не помешали бы, также как и описание портов ввода/вывода процессора %)
Автор: Leka May 31 2010, 22:17
На этой неделе постараюсь выложить первую версию компилятора. Отвлекают вопросы методического характера, например: Си ориентирован на явное использование указателей --> получается неудобно для архитектуры с большим регистровым файлом, тк указатели нельзя применять к регистрам...
Нужна еще память данных для массивов, косвенно адресуемых LOAD/STORE.
Автор: Ynicky Jun 1 2010, 05:56
На днях сделаю.
Учту.
Автор: Leka Jun 1 2010, 22:29
Чтобы проще было вылавливать ошибки в компиляторе с "ассемблерного" подмножества Си, решил добавить промежуточный уровень "машинного" подмножества Си:
... --> "ассемблерный" Си --> "машинный" Си --> машинные коды.
Пример: N-ферзей на "машинном" Си для 3х-операндной архитектуры без типов,
main() - тестовая программа на Си - игноируется компилятором в машинные коды по пробелу в начале строки.
R2;
R3[20];
R4[20];
R5[20];
R6[20];
R7;
R8;
R9;
R10;
R11;
R12;
R13;
R14;
queens(){
L1:R2=0;
L2:R12=R1&1;
L3:R13=1<<R1;
L4:R9=R13-1;
L5:R13=R1>>1;
L6:R7=R9>>R13;
L7:R3[1]=0;
L8:R4[1]=0;
L9:R5[1]=0;
L10:R6[1]=R7;
L11:R10=1;
L12:if(R7==0)goto L46;
L13:R13=0-R7;
L14:R8=R7&R13;
L15:R13=-1-R8;
L16:R7=R7&R13;
L17:if(R10!=R12)goto L20;
L18:if(R7!=0)goto L20;
L19:R2=R2<<1;
L20:if(R10==R1)goto L44;
L21:R11=R10+1;
L22:R6[R10]=R7;
L23:R13=R3[R10];
L24:R13=R13|R8;
L25:R3[R11]=R13;
L26:R13=R4[R10];
L27:R13=R13|R8;
L28:R13=R13<<1;
L29:R4[R11]=R13;
L30:R13=R5[R10];
L31:R13=R13|R8;
L32:R13=R13>>1;
L33:R5[R11]=R13;
L34:R13=R3[R11];
L35:R14=R4[R11];
L36:R13=R13|R14;
L37:R14=R5[R11];
L38:R13=R13|R14;
L39:R13=-1-R13;
L40:R13=R13&R9;
L41:R7=R13;
L42:R10=R11;
L43:goto L45;
L44:R2=R2+1;
L45:goto L48;
L46:R10=R10-1;
L47:R7=R6[R10];
L48:if(R10!=0)goto L12;
L49:if(R12!=0)goto L51;
L50:R2=R2<<1;
L51:return(R2);
}
main(){
int n,cnt;
for(n = 1; n < 15; n = n + 1){
R1= n;
queens();
cnt = R2;
printf("queens(%d)=%d \n", n, cnt);
}
}
Автор: Ynicky Jun 2 2010, 06:50
А что означают выражения?:
R6[R10]=R7;
R13=R3[R10];
Николай.
Автор: Leka Jun 2 2010, 10:31
Косвенную адресацию памяти
R6[R10]=R7; --> STORE R7,(R6+R10)
R13=R3[R10]; --> LOAD R13,(R3+R10)
Для 2х-операндной архитектуры:
R6[R10]=R7; -->
MOV R0,R6
ADD R0,R10
ST R7,(R0)
R13=R3[R10]; -->
MOV R0,R3
ADD R0,R10
LD R13,(R0)
или переписать "ассемблерный" код под 2х-операндную архитектуру с использованием указателей R6 R3 вместо пар база-индекс:
*R6=R7;
R13=*R3;
и учесть такие мнемоники в трансляторе в машинные коды.
Вариант N-ферзей с указателями на "ассемблерном" Си (кроме main(){}).
int
count,
arow[20],
aleft[20],
aright[20],
aposs[20],
poss,
place,
val,
pos,
pos1,
N1,
temp,
temp1,
*prow,
*pleft,
*pright,
*pposs,
*prow1,
*pleft1,
*pright1,
*pposs1;
count = 0;
N1= N & 1;
temp = 1 << N;
val = temp - 1;
temp = N >> 1;
poss = val >> temp;
pos = 1;
//
prow=arow+1;
pleft=aleft+1;
pright=aright+1;
pposs=aposs+1;
//arow[1] = 0;
//aleft[1] = 0;
//aright[1] = 0;
//aposs[1] = poss;
*prow = 0;
*pleft = 0;
*pright = 0;
*pposs = poss;
do{
if( poss != 0 ){
temp = -poss;
place = poss & temp;
temp = ~place;
poss = poss & temp;
if( pos == N1 && poss == 0 )
count = count << 1;
if( pos != N ){
pos1 = pos + 1;
//
prow1 = prow+1;
pleft1 = pleft+1;
pright1 = pright+1;
pposs1 = pposs+1;
//aposs[pos] = poss;
*pposs = poss;
//temp = arow[pos];
temp = *prow;
temp = temp | place;
//arow[pos1] = temp;
*prow1 = temp;
//temp = aleft[pos];
temp = *pleft;
temp = temp | place;
temp = temp << 1;
//aleft[pos1] = temp;
*pleft1 = temp;
//temp = aright[pos];
temp = *pright;
temp = temp | place;
temp = temp >> 1;
//aright[pos1] = temp;
*pright1 = temp;
//temp = arow[pos1];
temp = *prow1;
//temp1 = aleft[pos1];
temp1 = *pleft1;
temp = temp | temp1;
//temp1 = aright[pos1];
temp1 = *pright1;
temp = temp | temp1;
temp = ~temp;
temp = temp & val;
poss = temp;
pos = pos1;
//
prow += 1;
pleft += 1;
pright += 1;
pposs += 1;
}else
count = count + 1;
}else{
pos = pos - 1;
//
prow -= 1;
pleft -= 1;
pright -= 1;
pposs -= 1;
//poss = aposs[pos];
poss = *pposs;
}
}while( pos != 0 );
if( N1 == 0 )
count = count << 1;
return count;
}
main(){
int N;
for(N = 1; N < 15; N = N + 1){
printf("queens(%d)=%d \n", N, queens(N));
}
}
Автор: Ynicky Jun 2 2010, 19:34
Закончил "в черне" процессор.
Вынес память программ и данных из ядра.
Дополнил системной шиной AMBA AHB и отладочными блоками для
работы через JTAG.
Теперь только тесты, тесты, правка и еще раз тесты.
Описание дополню в выходные.
Николай.
Автор: Leka Jun 2 2010, 20:50
Написал компилятор "ассемблерный" Си --> "машинный" Си, причешу - выложу (либо завтра, если успею, либо в понедельник).
Надо-бы побольше программ на "ассемблерном" Си для тестирования (как компилятора, так и процессора).
"Машинный" Си --> машинные коды на этой неделе уже не успею, но эта задачка заметно проще.
Автор: Ynicky Jun 5 2010, 16:47
Дополнил описание.
Автор: Leka Jun 7 2010, 19:40
Первая версия компилятора "ассемблерный" Си --> "машинный" Си.
Поддерживаются: int, if-else, do-while, блоки { }, см. примеры N-ферзей.
В текущей версии не поддерживаются вложенные круглые скобки и круглые скобки в выражениях.
Запуск из командной строки:
a2m < входной_файл > входной_файл
Например(см. a.bat):
a2m < q3.c > q3..c
Выходные (и входные) файлы можно проверить любым Си-компилятором, например, Tiny C Compiler в скриптовом режиме:
c:\tcc\tcc.exe -run q3..c
При установленном TinyCC:
a q3
Под "ассемблерным" подмножеством Си подразумевается отсутствие длинных арифметических и логических выражений, допускаются только 3х-операндные выражения(с учетом адреса перехода), которые м/б непосредственно преобразованы в машинные коды.
По поводу FP(указателя на кадр) - как в подпрограммах получать доступ к глобальным переменным в регистровом файле?
Автор: Leka Jun 7 2010, 21:25
У меня указатель на область локальных переменных аппаратно "разворачивал" нумерацию регистров, так что R(0), R(1), R(2), ... в подпрограмме любой вложенности указывали на глобальные переменные, а R(-1), R(-2), R(-3) - на локальные, или наоборот. Например, для 8 регистров:
R0 R7 R6 R5 R4 R3 R2 R1 - main(){ int R7, R6, R5; f1( R5 ); }
R0 R1 R2 R7 R6 R5 R4 R3 - f1( int R7 ){ int R6, R5; f2( R5 ); }
R0 R1 R2 R3 R4 R7 R6 R5 - f2( int R7 ){ int R6, R5; ... }
С программной точки зрения подобная перенумерация регистров очень удобна. Проверил и в железе, и в ассемблере. Единственный недостаток - лишняя ступень логики.
Автор: Ynicky Jun 8 2010, 06:39
Тут я не понял. Я всегда считал, что глобальные переменные находятся в памяти данных.
И доступ к ним осуществляется через load/store.
Если они будут находиться в регистровом файле, тогда без переключения регистров не обойтись.
И сколько их может потребоваться?
Николай.
P.S.
Предлагаю пока не заморачиваться по поводу FP.
А дальше будет видно.
Автор: Leka Jun 8 2010, 08:21
Для вспомогательной подпрограммы основные данные - внешние, "в противном случае зовется ... иначе" - задача. Локальных по своей сути данных немного, это промежуточные результаты выражений, счетчики циклов, и тп.
Нет никакого смысла делать большой регистровый файл для локальных данных: 16 уровней вложенности пп * 4 локальные переменные в среднем = 64 регистра.
Если основные данные не в регистровом файле, имеет смысл отказаться от load/store архитектуры, добавив косвенно-регистровую адресацию ( *a=*b+*c; if(*a==*d)...; и тп ). Была у меня такая в железе, см ветку "посоветуйте простой софт-процессор".
Согласен, сначала нужен компилятор "машинный" Си --> машинные коды.
Автор: Ynicky Jun 9 2010, 09:55
To Leka:
Попробовал написать простенький тест.
После компиляции a2m запустил LCC.
Пока 2 явных замечания:
1. return надо отделить от 1 и 0.
2. в разных подпрограммах повторяющиеся метки.
Проект во вложении.
Николай.
Автор: Leka Jun 9 2010, 12:52
Забыл написать, надо "return(1);" вместо "return 1;" Сделано специально - как вызов функции, а не ключевое слово.
Вроде это не противоречит стандарту (локальность меток в пределах функции), но если надо - могу добавлять имя функции к метке.
Автор: Leka Jun 9 2010, 13:59
В a2m пока только один тип "int", поэтому "void" не допускается.
Ошибки потом поправлю, сейчас прорабатываю компилятор в машинные коды.
Из-за зависимости длины инструкции от данных (вставка imm20 и тп), решил поменять концепцию.
Автор: Ynicky Jun 9 2010, 16:29
Исправил несколько ошибок.
Проверил АЛУ без SMUL (пока нет), load/store.
Николай.
Автор: Leka Jun 9 2010, 20:41
Принцип получения hex-файла машинных кодов:
компилятор a2m в "машинный"Си будет также автоматически генерировать файл "code.c" для Си-скрипта "machine.c", запускаемого после a2m. Си-скрипт м/б выполнен TinyCC с ключом "-run".
В приложении пробная версия "machine.c"(с выводом мнемоник вместо hex-кодов) и тестовый "code.c".
Для настройки на конкретную систему команд в "machine.c" надо поменять текстовый вывод мнемоник на вывод соответствующих hex-кодов. Переменная "p" обеспечивает несколько проходов(2) для "подгонки" относительных адресов инструкций, тк их число зависит от данных(добавлений "imm20"). "t"!=0 означает константу. Остальное, думаю, понятно будет из исходника.
"a2m" позже подправлю под вывод "code.c".
Автор: Leka Jun 16 2010, 10:45
Концепцию немного поменял, "a2.exe" выводит код для Си-препроцессора.
Не хватает времени, не сделал вывод hex-кодов для конкретного процессора - в "a2b.c" надо поменять текстовый вывод мнемоник на вывод соответствующих hex-кодов ("a2a.c" настроил для конкретного 2х-операндного процессора).
Автор: Leka Jun 16 2010, 15:48
Пример вывода hex-кодов для некоторых команд (mov, cmp, и тп) в "a2b.c", для остальных делается аналогично. М/б стоит переписать "a2a.c" и "a2b.c", чтобы проще было вводить/править hex-коды команд.

Автор: Ynicky Jun 17 2010, 09:23
Что означает hex-код? Файлы a2a.c и a2b.c идентичны.
Николай.
P.S.
С hex-кодом разобрался. Это AL2 в a2b.txt.
А в hex-код можно добавить комментарий в виде мнемоники команд?
Тогда будет проще править.
Автор: Leka Jun 17 2010, 10:03
В "a2b.c" я еще исправил ошибку, вернул необходимые пары "{" "}" (случайно выкинул, когда "причесывал") - иначе неправильно считает адреса команд.
Думаю, надо переписать "a2a.c" и "a2b.c", чтобы были комменты, и удобно было править. Но сейчас много дел навалилось, освобожусь - займусь.
Автор: Leka Jun 17 2010, 21:37
В "a2b.c" надо вместо "00" кодов операций поставить реальные.
Вывод комментов добавил.
Автор: Leka Jun 18 2010, 08:34
По поводу слотов задержки в командах условных переходов. В FPGA вся память - двухпортовая, можно использовать для упреждающей выборки альтернативной инструкции из памяти программ - выигрываем 1 такт.
Автор: Ynicky Jun 18 2010, 11:50
В принципе, можно вообще обойтись без слотов задержки, как, например, в ARM-е.
Тогда мы будем терять 3 слота задержки при невыполнении условия перехода (flush).
Можно, конечно, сделать альтернативную выборку команд и не терять ни одного слота,
переключаясь на альтернативную ветку конвейера.
Но это, по моему, будет привязывать данную архитектуру только к FPGA.
Как это может сочетаться с кеш, пока не знаю.
Николай.
Автор: Ynicky Jun 20 2010, 09:42
Вывод комментов добавил.
Есть вопросы по командам в "a2b.c".
1. "TST" - это операция "AND" без записи в регистр (т.е. только изменение флагов)?
2. "BZ","BNZ" - ветвление, если результат "=0" и "/=0"? Дело в том, что с командами "CMP"
все условия ветвления сравниваются с '0'. Значит ли это, что их можно приравнять
к командам "BEQ" и "BNE"?
3. Что из себя представляют команды: "COM", "LDI", "LDD", "LDDI", "STI", "STD", "STDI"?
4. "ASL" и "ASR" - это команды арифметического или логического сдвига?
Исправил еще несколько ошибок в процессоре.
Николай.
Автор: Leka Jun 20 2010, 14:41
любая операция без записи в регистр, устанавливающая нужные флаги для "BZ","BNZ".
Можно "CMP" с нулевой константой.
Да.
Напрямую не получится, тк "0" задан неявно.
Либо в "ассемблерном" Си всегда писать "if(a!=0)..." и "if(a==0)..." вместо "if(a)..." и "if(!a)...", либо ввести формальные команды "BZ" и"BNZ", подразумеавющие сравнение с нулем. В фактической системе команд они не нужны, и в машинных кодах
заменяются "BEQ" и "BNE" с нулевой константой.
COM: Ra=~Ra;
LDI: Ra=*Imm;
LDD: Ra=Rb[Rc];
LDDI: Ra=Rb[Imm];
STI: *Imm=Ra;
STD: Ra[Rb]=Rc;
STDI: Ra[Rb]=Imm;
"LDD" и "STD" - для 3х-операндной системы команд.
"LDDI" и "STDI" получаются "за компанию".
То-же, что и "<<" и ">>" в Си.
Можно добавлять свои команды например:
#define MAX( a, b ) AL2( max, maxi, a, b );
и определить соответствующие коды "max" и "maxi", из Си можно вызывать:
MAX( a, b );
Но тогда для отладки в Си надо определить в тестовых программах:
#define MAX( a, b ) if( a < b ) a = b
и тд и тп.
Для другой архитектуры "a2a.c" и "a2b.c" будут другими, а вот "a2с.c" менять не понадобится.
Автор: Ynicky Jun 20 2010, 16:28
Насколько я знаю, "<<" - это всегда логический сдвиг, а ">>" - либо логический либо арифметический,
в зависимости от переменной (беззнаковой или знаковой). Это так?
Николай.
Автор: Leka Jun 20 2010, 17:03
Для чисел в дополнительном коде арифметический и логический сдвиг влево - результат одинаковый.
в зависимости от переменной (беззнаковой или знаковой). Это так?
Да. У меня пока только один тип "int", и поэтому подразумевается только арифметический сдвиг.
В принципе, ввести дополнительные типы несложно, но проект, судя по всему, развиваться не будет(мало участников) - поэтому не вижу смысла (сам предпочитаю "бестиповую" архитектуру).
Автор: Ynicky Jun 20 2010, 17:11
Согласен.
Автор: Leka Jun 20 2010, 17:18
На всякий случай посмотрел стандарт на ANSI C, там результат сдвига вправо знаковых чисел - зависит от реализации.
Надеюсь, кое-какая польза все-таки была извлечена из этого проекта.
Автор: Ynicky Jun 20 2010, 17:46
Для меня - да.
Автор: Leka Jun 20 2010, 19:15
Посмотрел "a2h.c" и "aaa.txt".
Тк в системе команд rf32 нет "sti",
то либо предварительно загружать константы в определенный регистр(например R0),
либо все константы загружать в регистры в начале программы.
Например, по второму способу надо изменить "INT(a,b )" (объявление константы) в "a2h.c":
и "ST(a,b )":
в этом случае определять код sti не нужно.
Аналогично можно менять/добавлять другие команды.
"INT(a,b )" - объявление константы (int n=1; ), м/б код записи в регистр.
"ARR(a,b )" - объявление массива (int arow[20]; ) - д/б выделение памяти, пока игноируется. Д/б код типа "heap+=b; v[a]=heap;"
"CHR(a,b )" - объявление строковой константы (int s="hello,world!"; ) - д/б выделение и инициализация памяти, пока игноируется.
Автор: Leka Jun 20 2010, 22:04
Пример "a2h.c" с печатью секции ".REG" - начальные значения регистров, в тч адреса массивов. Там-же вариант разворачивания "sti" в 2 команды: "movi" и "st".
Автор: Leka Jun 20 2010, 23:14
Для примера переопределил "bz", "bnz", "neg", "com",
и исправил "ALxx" - чтобы проще было определять инструкции с константами.
Автор: Ynicky Jun 21 2010, 09:57
To Leka: А что делать с секцией ".REG"?
Надо прописывать в регистровый файл?
Николай.
P.S.
Понял, надо.
Автор: Ynicky Jun 23 2010, 18:38
Попробовал отмоделировать программу "queens".
Работает не правильно.
Тогда стал писать тесты. Сразу обнаружил следующее:
{
int iA = 1;
int iB = 2;
iB = iA;
}
=>
.REG
000:00000000
001:00000001
002:00000002
.CODE
000001:45002001 ;iB=iA; //формат RI вместо RR!!!
000002:12000000 ;}
Но если переменную iA не инициализировать, то все нормально:
{
int iA;
int iB = 2;
iB = iA;
}
=>
.REG
000:00000000
001:00000000
002:00000002
.CODE
000001:25002001;iB=iA; //!!!
000002:12000000;}
Николай.
Автор: Leka Jun 23 2010, 20:43
Поправил "a2" и "a2h.c" (помимо "#define REG" поменял также "#define STR" - это потом может пригодиться, для работы со строками, после определения "#define CHR").
Не ту версию прикрепил, поправил.
Автор: Ynicky Jun 27 2010, 10:38
{
int *ptr1;
int *ptr2;
int iA,iB;
*ptr1 = 0xA;
*ptr2 = 0xB;
iA = *ptr1;
iB = *ptr2;
}
=>
.REG
000:00000000
001:00000000
002:00000000
003:00000000
004:00000000
005:0000000A
006:0000000B
.CODE
000001:4500000A ;
000002:66001000 ;*ptr1=0xA;
000003:4500000B ;
000004:66002000 ;*ptr2=0xB;
000005:62003001 ;iA=*ptr1;
000006:62004002 ;iB=*ptr2;
000007:12000000 ;}
Помоему, в командах "STORE" (опкод 66) перепутаны местами RD и (RS).
У меня в системе команд RD и (RS) находятся в одном и том же месте для формата "LOAD/STORE".
Николай.
Автор: Leka Jun 28 2010, 18:05
В "a2h.c" "#define ST(a,b )..." надо исправить на "#define ST(b,a)...".
Автор: Ynicky Jun 29 2010, 09:10
Исправил, заработало, проверяю дальше.
Николай.
Автор: Ynicky Jul 3 2010, 18:52
Промоделировал "queens".
Результаты совпадают с "q.c".
Указатели в "q2.c" изменяются на 1, в то время как у меня в процессоре байтовая адресация,
т.е. указатели должны меняться на 4. Временно сдвинул адрес в процессоре на 2 разряда вправо
и все заработало.
2 Leka: Что нужно (или можно) посмотреть по результатам моделирования?
И еще, для чего в программе "q2.c" мы обращаемся к памяти через указатели?
Почему нельзя обойтись только регистрами?
Ошибок в процессоре больше пока не обнаружил.
Николай.
Автор: Leka Jul 5 2010, 19:20
Это общая проблема арифметики указателей.
По стандарту на Си, в "q2.c" все правильно, тк это компилятор должен делать поправку на тип данных (у меня не делает). Варианты выхода из этого положения:
1) добавить в компилятор полную поддержку типов, как в Си,
2) использовать в SoC раздельную память для байтов/слов,
3) ...
Сам использовал 2-ой вариант, тк SoC под конкретную задачу, и память разбивается на отдельные блоки нужного размера, и с нужной разрядностью(и не обязательно кратной 8).
А 1-ый вариант в одиночку делать не буду, тк предпочитаю бестиповые языки/архитектуры, и индексную адресацию.
Не понял.
В программе используются массивы, обращаться к элементам массива можно либо при помощи индексной адресации, либо через указатели. Как еще? Если процессор поддерживает косвенную адресацию регистрового файла, все-равно на Си это будет либо индексная адресация, либо указатели.
Автор: Leka Jul 6 2010, 22:53
Например, код на Си:
int *a, i; ... a+=i; *a=i; ...
и эквивалентный код на "ассемблерном" Си для 2х-операндной 32х-разрядной архитектуры:
int a, i, tmp; ... tmp=i; tmp<<=2; a+=tmp; *(int*)a=i; ...
--> имхо, громоздко, неэффективно, и непереносимо на другую разрядность/архитектуру.
Поэтому и нравятся бестиповые языки/архитектуры.
И с индексной адресацией.
Пример N-ферзей с явной арифметикой указателей:
queens(){
int
arow[20], aleft[20], aright[20], aposs[20],
poss, place, val, pos, pos1, n1, temp, temp1,
prow, pleft, pright, pposs,
prow1, pleft1, pright1, pposs1;
count = 0;
n1 = n;
n1 &= 1;
val = 1;
val <<= n;
val -= 1;
temp = n;
temp >>= 1;
poss = val;
poss >>= temp;
pos = 1;
prow = arow;
prow += 4;
pleft = aleft;
pleft += 4;
pright = aright;
pright += 4;
pposs = aposs;
pposs += 4;
prow1 = prow;
prow1 += 4;
pleft1 = pleft;
pleft1 += 4;
pright1 = pright;
pright1 += 4;
pposs1 = pposs;
pposs1 += 4;
*(int*)prow = 0;
*(int*)pleft = 0;
*(int*)pright = 0;
*(int*)pposs = poss;
do
if( poss ){
temp = poss;
temp = - temp; //0-temp;
place = poss;
place &= temp;
temp = place;
temp = ~temp; //^=-1;
poss &= temp;
if( pos == n1 )
if( ! poss )
count <<= 1;
if( pos != n ){
*(int*)pposs = poss;
temp = *(int*)prow;
temp |= place;
*(int*)prow1 = temp;
temp = *(int*)pleft;
temp |= place;
temp <<= 1;
*(int*)pleft1 = temp;
temp = *(int*)pright;
temp |= place;
temp >>= 1;
*(int*)pright1 = temp;
temp = *(int*)prow1;
temp1 = *(int*)pleft1;
temp |= temp1;
temp1 = *(int*)pright1;
temp |= temp1;
temp ^= -1;
temp &= val;
poss = temp;
pos += 1;
prow += 4;
pleft += 4;
pright += 4;
pposs += 4;
prow1 += 4;
pleft1 += 4;
pright1 += 4;
pposs1 += 4;
}else
count += 1;
}else{
pos -= 1;
prow -= 4;
pleft -= 4;
pright -= 4;
pposs -= 4;
prow1 -= 4;
pleft1 -= 4;
pright1 -= 4;
pposs1 -= 4;
poss = *(int*)pposs;
}
while( pos );
if( ! n1 )
count <<= 1;
}
main(){
do{
queens();
printf("queens(%d)=%d\n",n,count);
n = n + 1;
}while( n < 15 );
}
Чтобы такое можно было компилировать в hex-файл, надо слегка поправить компилятор:
1) убрать возможность объявления указателей "int*",
2) заменить в выражениях "*" на "*(int*)".
Стоит овчинка выделки?
Автор: Leka Oct 1 2010, 19:15

Между первым э/м реле: http://electronix.ru/redirect.php?http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BB%D0%B5
и первой вычислительной машиной на них: http://electronix.ru/redirect.php?http://ru.wikipedia.org/wiki/Z3
>100 лет... Что мешало?
Автор: DevL Oct 25 2010, 20:20
очень интересный пример!
для уточнения - при симуляции надо использовать rf32sim_TB_runtest.do , правильно ?
и несколько для ленивых - есть ли описание signal names, что бы проследить исполнение src\prg.txt ?
Автор: Leka Jan 11 2011, 16:29
Жаль, что проект с компилятором заглох...
Делаю апгрейд своего софтпроцессора - вместо Фон-Неймановской архитектуры взял Гарвардскую, и выделил 1К регистровый файл в отдельную 3х-портовую память. После P&R для минимального 18-разрядного ядра без периферии:
Спартан3 ~120 ЛУТ, ~120МГц,
Циклон3 ~250 ЛУТ, ~120МГц.
a=b+c; - 1 такт,
a[i]=b[j]+c[k]; - 2 такта.
Автор: PVL Feb 22 2011, 23:37
Программеров разогнали, деньги кончились. Сейчас работаю только на основной работе.
По поводу производительности - сейчас рулят синтетические наборы инструкций с сетевой организацией вычислительных блоков. Одна российская контора пытается сделать это на ПЛИС. Цель - обогнать видеокарту по производительности. Блажен кто верует...
Автор: DevL Apr 20 2011, 21:02
кстати , для гибкости в выборе ассемблера - оказался очень забавный вариант описанные тут "Пакет для разработки ПО для ПК "Специалист""
http://electronix.ru/redirect.php?http://shoorick.ho.ua/spec/index.html
в частности использование winasm + fasm - где по большому , даже не важно что fasm не сильно работает с нужным 8080, а просто используется для трансляции например комадны
LXI в то что fasm может обработать
[b]db [/b]((r1 and 6) shl 3) + 1
[b]dw [/b]imm }
в итоге - получается удобство winasm как IDE + полная компиляция

Автор: Lexey May 7 2011, 22:03
Давно маюсь с софт-процессором для ПЛИС, решил поделиться своеми соображениями.
Ни один из готовых вариантов меня не радует, хотя в моих требованиях нет ничего оригинального и нереального:
1. FPGA не BGA (производство мелкосерийное, множество проектов с оригинальным железом)
2. SDRAM до 64MB (один 16-битный чип),
3. Полноценное ядро OC, файловая система, т.п. чтобы беспроблемно портировалось готовое.
5. Несложная но гибкая и разнообразная обработка потоков данных, cравнимых с пропускной способностью SDRAM
Ключевая проблема тут в том что имеющиеся процессоры очень непроизводительны при работе с SDRAM.
Я пытаюсь решить ее
1.Интеграция процессора с контроллером SDRAM:
1a. отказ от использования стандартной шины
1b. асинхронное выполнение команд загрузки/cохранения контроллером SDRAM
контроллер имеет 2 интерфейса c ядром: интерфейс приема команд и интерфейс возврата данных в регистры.
контроллер одновременно может обрабатывать около десятка команд, что позволяет оптимизировать работу шины.
2.Отказываюсь от кэша данных, как от вещи малоэффективной и ресурсоемкой в данной ситуации.
3.Интерфейс между ядром и потоковым железом реализуется через 2-x портовые блоки EBR, на что предполагается израсходовать
большинство доступных EBR.
При такой организации отпадает необходимость прямого доступа железо<->SDRAM, поскольку сам процессор сможет пересылять данные по прерываниям между EBR и SDRAM не менее производительно чем любой железный DMA (но при этом гораздо гибче и удобней),
a "DMA контроллер" железо<->EBR тривиален.
За основу взял архитектуру LM32, FPGA Lattice XP2, verilog,
Прочие подробности:
-Mинимальный MMU на 512 страниц в пространcтве 64MB (вся таблица страниц текущей задачи вмещается в один EBR)
-1KB 2-way Instruction cache+ 1KB local instruction memory (1 EBR)
-Регистры в распределенной памяти
-Минимальная конвейеризация (простейшие команды читают регистр, выполняются и сохраненяют результат в одном такте)
-Предполагаемая тактовая : 125 MHz (общая для ядра и SDRAM)
-Предполагаемый размер 2500 LUT+2EBR (без учета интерфейсных EBR)
-Возможность экономной реализации 2x-SIMD путем раздвоения ALU. (регистровый файл по-любому 2-x банковый)
-Потери перехода: прямой 1 такт , косвенный 2 такта.
Стадия разработки: около 50% исходников, через 3-4 месяца надеюсь дойдет до отладки
Автор: alexPec May 7 2011, 23:20
Отказываюсь от кэша данных, как от вещи малоэффективной и ресурсоемкой в данной ситуации.
Так кэш то и призвана решать эту проблему. Хотя смотря под какие задачи и какая кэш.
Предполагаемая тактовая : 125 MHz (общая для ядра и SDRAM)
На каких fpga? Если бюджетные, то мне например идея асинхронщины не нравится
a "DMA контроллер" железо<->EBR тривиален.
Опять же смотря под какие задачи. Если для обработки видео - без дма сразу нет. Да и вобще софт процессор без дма...
Автор: Lexey May 29 2011, 09:05
Интерфейс ядра - удобная штука для разделения проекта софтпроцессора на части.
При соблюдении несложных правил, определенных этим интерфейсом можно делать свои софт-процессоры используя готовую подсистему MMU, поддерживающую такой интерфейс, или наоборот.
- Подсистема MMU берет на себя все вопросы интерфейса процессора с внешним миром, включая по мере необходимости
такие вещи как организацию кэшей, трансляцию адресов и организацию внешних шин.
- Подсистема ядра определяет архитектуру процессора.
Предлагаю свою концепцию интерфейса:
input clk,rst,
//-- Instruction readout ----------------
input [31:0]C, //P3 Codeword
input [23:0]PC,//Program Counter
input CFault, //P3 Page Fault detected on current codeword
input CRdy, //P3 CodeWord Ready from IC
output CFRq, //P6 Next Codeword Fetch Request (keep it until CRdy become active)
input [1:0]PWords,// Prefetched words beyond the current codeword, sat@3
//-- Jumps ---------------
output JI,JR,JE, //Jump {Indirect,Relative,Exception} requests (Jx=JI|JR|JE)
input JB, //Jump Buffered, mutex{JI,JR,JE,JB}
output JxU, //Jump Unresolved for use with JI,JR,JE (most usable for JR)
input JBU, //Jump Buffered unresolved
output JAbort,JTake, //P7 Jump Abort/Take for unresolved buffered jump
output JFE, //Jump Fetch Enable (last slot word already fetched)
input Jmp, //P7+ Jump destination fetch
//Jx can be asserted only when all intended slot instructions
//already prefetched (see PWords)
//-- virtual adress from core ----------
output [23:0]JRA, //P6 JR address (from decoder)
output [23:0]JEA, //P4? JE address (Exception handler address)
output [25:0]LSA, //P3..P5 LS/JI address (from AU)
//-- Data Memory request interface -----------------
output MRq, //request
output MRqWr, //direction
output MRqSigned, //Load Mode
output [4:0]MRqGPR, //destination GPR
output [1:0]MRqSize,//data Size (bytes-1)
output [31:0]MRqWrD,//Write Data, M-aligned
output MRqExt, //Extended transfer (8 bytes), option for SIMD-like LS instructions
output [31:0]MRqWrExD,//Extended Data, 4-byte aligned, optional
input MRqAc, //Request Acception
input MRqFault, //last accepted request failed
input MRqWS, //Wait State for split-page translation
//MRqFail normally occurs next clock after MRqAc, only exception is rare case when
//unaligned request cross page boundary (MRqWS asserted for this case).
//MRqWS will be used as wait state for execution unit to prevent any next
//instruction from changing arch. state.
//-- Data Readout interface ------------------------
input MRdRq, //request
input [1:0]MRdSize,input [4:0]MRdGPR,input MRdSigned,//Destination descriptor
input [31:0]MRdD, //P4+m Read Data, M-aligned
input MRdEx, input [31:0]MRdExD, //optional
output MRdAc, //acception
)
P0..P7 - cтупени комбинаторной логики в 8-ступенчатой модели
Автор: svrdc Oct 31 2012, 07:00
Может кого интересуют IP дла плавающей точки. Могу предложить быстрый multifunc fp для вычисления DIV, RECP, SQRT, RSQRT
Автор: ArtemDement Dec 5 2012, 17:28
Ни у кого 10 000 000 $ не завалялось для спонсирования открытого процессора от http://electronix.ru/redirect.php?http://www.qimod.com ?
http://electronix.ru/redirect.php?http://habrahabr.ru/post/161489/
Автор: Victor® Dec 5 2012, 17:57
http://electronix.ru/redirect.php?http://habrahabr.ru/post/161489/
Лохотроном каким-то попахивает....
Вот это гораздо прозрачнее и понятнее.
http://electronix.ru/redirect.php?http://opencores.org/donation
Автор: SyncLair Dec 6 2012, 21:30
Я что-то не понимаю зачем городить процессор, вроде и так все процессоры что есть имеют свободную спецификацию. Вот городить ВИДЕОпроцессор ну для трёхмерной графики -- это толк может и будет
Автор: Wic Dec 7 2012, 05:34
Свободная спецификация != открытый код/бесплатная лицензия. Если бы тот же арм имел открытый код, его бы очень быстро клонировали для специфичных применений. То о чем писали на хабре, имхо, фантастика. Современный процессор за 10Му.е. не сделать. А вот софтверный процессор с открытым кодом для FPGA реальная задача. Но ее нужно решать с оглядкой на ОС, которые на нем буду крутиться *nix/win/etc.
Автор: Leka Dec 7 2012, 07:17
"- Хочу предложить последнее свое изобретение. Это автомат для бритья. Клиент опускает монеты, просовывает голову в отверстие, и две бритвы автоматически бреют.
- Но ведь у каждого индивидуальное строение лица...
- Так это только в первый раз!"
ОС и интерфейсы - это и есть "автоматические бритвы". И какой смысл в "индивидуальном строении" процессоров?

Автор: alman Dec 23 2012, 23:31
такие вещи как организацию кэшей, трансляцию адресов и организацию внешних шин.
Вы ещё не забросили разработку процессора? У меня есть пожелания к реализации MMU и пожелание расширить систему команд.
Автор: alexey123_45 Aug 1 2013, 05:58
А как Вы относитесь к построению и применению forth-процессоров? Мне кажется, что это перспективное направление
Автор: Corner Aug 17 2013, 20:04
А мне больше нравиться архитектура, когда в одном программном слове указатели на данные и их формат. Одна инструкция содержит до 11 скрытых операций: две загрузки, три модификации данных, три пост модификации адреса, сохранение и две арифметические операции. Мало кода, четкая параллельность...
Автор: Егоров Aug 17 2013, 21:03
Прошу прощения, если невпопад, давно отошел от этих дел. Но то, что Вы описали - система команд, не архитектура. Архитектура тут одна - микропрограммное выполнение инструкций. Можно при одной и той же архитектуре ЦП создать множество систем команд, было бы умение прошить микропрограммник. Да, код сокращает, но время обработки растет даже непропорционально и с обработкой прерываний сложности возникают. Прервать можно безболезненно программу, а длиннючую микропрограмму уже рисковано.
По-настоящему архитектуру ЦП затрагивают другие критерии. Например, в одной разработке нужно было за один такт, а не побитно подпрограммой, развернуть слово , младший разряд в старший и т.д, наоборот. Вот там в архитектуру был включен специальный аппаратный блок.
Ну и еще фундаментальные общие определения архитектуры - гарвардская, фон-неймановская, теговая. Это относится к взаимодействию ЦП и памяти.
Автор: Corner Aug 21 2013, 16:21
http://electronix.ru/redirect.php?http://multiclet.com/ - будущее российских систем на кристалле.
Сколько не читал так и не понял, что тут за архитектура и на каких частотах работает. Такое ощущение, что это несколько ALU с шедулером и КП.
Автор: Paviaa Feb 21 2014, 12:19
Изучаю verilog, делаю свой процессор.
Чувствую что застрял. Какие есть архитектуры процессоров и что по ним можно прочитать?
Автор: Postoroniy_V Feb 21 2014, 13:38
Чувствую что застрял. Какие есть архитектуры процессоров и что по ним можно прочитать?
Computer Architecture A Quantitative Approach
осторожно трафик -> http://electronix.ru/redirect.php?http://eecs.oregonstate.edu/research/vlsi/teaching/ECE570_WIN13/computer_arch_quantitative_approach.pdf
http://electronix.ru/forum/index.php?showtopic=88548
Автор: Ynicky Feb 24 2014, 16:29
Мне очень помогло это: lec9_2.pdf ( 822.35 килобайт )
: 341
lec9_2.pdf ( 822.35 килобайт )
: 341
http://electronix.ru/redirect.php?http://www.kurtm.net/archive/2003-Fall-cs152-public_html/lecnotes/
Автор: alman Apr 29 2014, 01:01
Позвольте и мне показать "микропроцессор". Это 32-х битное ядро, которое выглядит так:
Ядро использует собственную систему команд, нескромно названную "Эверест":
- 16 регистров общего назначения
- позиционно независимый код
- большой запас для расширения системы команд
Частичное описание системы команд: http://electronix.ru/redirect.php?http://everest.l4os.ru/core/
Несколько слов об ассемблере: http://electronix.ru/redirect.php?http://everest.l4os.ru/assembler/
Пример пошаговой отладки ядра: http://electronix.ru/redirect.php?http://everest.l4os.ru/test_of_strlen/
Выполнение команд занимает 2-3 клока, не считая тактов ожидания внешних устройств. Ядро проверено на плате "Марсоход2" и показало возможность работы на 100МГц. В перспективе возможна реалиазция конвейерного исполнения команд. В более далёкой перспективе - одновременное выполнение нескольких команд за такт. Причём, параллельное выполнение некоторых команд можно достичь с небольшими издержками за счёт коротких команд и 40-битной входной шины. Т.е. в перспективе ожидается параллельное выполнение нескольких команд, если они не взаимозависимы и целиком поместились на входную 40-битную шину. Впрочем, это отдалённые перспективы, потому что...
Процессор создаётся с надеждой на то, что в скором будущем он обзаведётся аппаратным планировщиком и расширенным MMU с поддержкой универсальных страниц виртуальной памяти. В результате процессор станет первым в мире микропроцессором с аппаратно реализованным микроядром http://electronix.ru/redirect.php?http://l4hq.org/. Если успеет...
Собственно, ради реализации аппаратного микроядра и был затеян этот проект. Процессор создаётся под уже существующую микроядерную операционную систему (точнее - http://electronix.ru/redirect.php?http://L4os.ru).
Автор: alman May 5 2014, 11:55
Разреште поделиться небольшим успехом - процессор научился программно писать в последовательный порт.
Подробности по клику:
http://electronix.ru/redirect.php?http://everest.l4os.ru/hello_world/
Автор: alman May 9 2014, 19:47
Такое живое обсуждение процессоров в этой теме
Между тем, процессор "Everest" научился читать из последовательного порта. И кое-чему ещё, о чём можно узнать перейдя по ссылке. Для этого достаточно кликнуть на картинку.
http://electronix.ru/redirect.php?http://everest.l4os.ru/second_demo/
Автор: alman May 21 2014, 05:00
В соседней теме кипят нешуточные страсти и люди (язык не поворачивается сказать "народ") активно делятся идеями и наработками. Между тем, кто-то продолжает "тянуть лямку" и не жалея сил продолжает готовить процессор для встраивания в него аппаратного микроядра планировщика.
Сегодня расскажу ещё об одном устройстве, выполнящиюм функции арбитра шины. Сейчас оно выглядит как-то вот так:
Как видно из картинки, устройство почти полностью симметрично показанному выше ядру, за исключением добавленных ног - serial_rx, serial_tx.
Внутри этого устройства находится UART, ПЗУ с микрокодом и два региона ОЗУ.
ПЗУ и ОЗУ сгенерированы с помощью мегафункций Altera.
Один блок ОЗУ зарезервирован для регистров собщений, второй блок ОЗУ - кэш инструкций. Но это в будущем, а в настоящий момент эти два региона ОЗУ задействованы для тестирования отладки.
Выглядит это так. После старта в подключенном терминале появляется следующее меню:
│ 1 - Load binary file via X-modem protocol │
│ 2 - Run previously loaded binary file │
│ 3 - Show RAM (0x100000-0x100140) │
│ 4 - Test of message registers │
│ 5 - Show previously loaded ANSI picture │
│ 6 - Show built-in ANSI pic #1 │
│ 7 - Show built-in ANSI pic #2 │
└──────────────────────────────────────────────────────────────────────────────┘
А дальше всё тривиально - после нажатия клавиши 1, устройство ожидает принятия файла по протоколу X-modem
Нажатие клавиши 2 в терминале запустит загруженный файл.
И т.д.
Устройство постепенно обрастает библиотечными функциями. Последние из реализованных -
_mul - умножение двух целых числел,
_div - деление целых числел,
_print_dec - вывод числа в десятичной форме в терминал.
Автор: Serhiy_UA May 21 2014, 07:17
Есть две платы с Cyclone III и StratixII. На обоих у меня было несколько проектов на NiosII, при работе с программатором USB Blaster.
А как поработать на этих ПЛИС с Вашим ядром, это коммерческая тема или есть доступ для тестирования?
То есть, как сравнить все, что относится к NiosII с Вашими наработками по Эвересту...
Просмотрел Ваши сайты, но пока еще не разобрался...
Автор: alman May 21 2014, 09:27
А как поработать на этих ПЛИС с Вашим ядром, это коммерческая тема или есть доступ для тестирования?
Если согласны не передавать исходный код ядра третьим лицам, то могу передать архив с проектом, например, расшарив его через Google диск.
Формат QAR, помещённый в запароленный ZIP будет удобен?
Пароль сообщу личным сообщением.
Прошу понять меня правильно - сам по себе процессор ценности почти не имеет - он создан для реализации аппаратного microkernel совместимого с L4. Таким образом "просто процессор" готов раздать всем желающим, на условиях нераспространения его исходного кода. А вот что касается микроядра, то его пока нет и если оно будет реализовано, то будет коммерческим.
p.s. Откровенно, Ваш вопрос выбил меня из колеи. Уже как-то привык, что никакого отклика, а как получил первый вопрос, то лишился дара речи.
p.p.s. Прошивку для платы Марсоход2 можно скачать здесь - http://electronix.ru/redirect.php?http://marsohod.org/index.php/forum/8--/2542----#2609.
Автор: Aner May 21 2014, 10:17
А не поздно ли в нашем "болоте" ядрами заниматься? Понятно, что отстали технологически, ну оч намного. Откуда у вас вера в коммерцию для вашего ядра, вот чего не пойму. В той же калифорнии, полно обанкротившихся компаниями с шикарными решениями ядер, причем у них под боком ну оч приличная топо технология. И вы туда же?
Автор: alman May 21 2014, 10:59
Вы будете смеяться, но вся вера построена на одном допущении. Предистория такова - в 2003 году был перенсён код самописной файловой системы из консольного тестового проекта MS Visual Studio в задачу, исполняющуюся поверх микроядра L4Ka::Pistachio на архитектуре ia32. С учётом того, что микроядро L4 синхронное, файловая система заблокировала всю систему в момент чтения со stdin (проще говоря - система заблокировалась в ожидании нажатия клавиши на клавиатуре). Самое смешное, что все писатели операционных систем, использующих синхронные микроядра, сталкиваются с этой проблемой и решают её по своему. В результате, почти случайно, было найдено оригинальное решение развязывания синхронных вызовов в асинхронные, которое давало минимальный оверхед по ресурсам. Собственно, многолетняя убеждённость в том, что решение удачное, уникальное и никому пока ещё не пришло в голову - вот эта убеждённость и придаёт силы.
Когда работа ведётся много лет на энтузиазме и вере, когда в работу вкладываюся собственные средства, когда нет кредиторов и хозяев, диктующих что и как делать, то обанкротится сложно. Сильно рисковать желания нет, пусть со стороны это выглядит как риск, а изнутри это смотрится как целенаправленная многолетняя работа.
Кстати, собственно почему пришла идея сделать свой микропроцессор? Такие мысли были давно, но желание превратилось в намерение после переноса операционной системы "Хамелеон" с x86-32 на x86-64. В какой-то момент перенести удалось, но само микроядро L4-Pistachio работает нестабильно на 64-битах. Это очень нехорошее чувство, когда то, на что опирается ваш код, работает нестабильно, а трудозатраты на исправление чужого кода сопоставимы с трудозатратами при разработке с нуля. В общем, тут сам Бог велел забыть о "чужих" проблемах и недоработках, а сделать то, что нужно самому.
Не то, чтобы в Калифорнии никто не делал аппаратных планировщиков - такие исследования проводились разными командами, но вот чтобы кто-то реализовал аппаратно синхронное микроядро (microkernel) - такого ещё не сделал никто. Во всяком случае не сделал нечто, опирающееся на идеи из вот этой спецификации - http://electronix.ru/redirect.php?http://www.l4ka.org/l4ka/l4-x2-r7.pdf
Простите за многословность. Я теряю самообладаение когда речь идёт об микроядре L4.
Автор: Serhiy_UA May 26 2014, 06:39
Меня же пока интересует маленький процессор на 8 или 16 разрядов, с ограниченным набором команд, который загружался бы в ПЛИС типа Cyclone III, например, с EPCS16. И помимо процессора, чтобы можно было загружать программы к нему, а также другую аппаратную обвязку.
Для подобных загрузок надо знать, как вместе с процессором разместить в EPCS программу к нему, и как все это из EPCS выгрузить. Для NiosII это решается интегрированной средой и с применением jic-файла, но не понятны детали, как это все делать и увязать самому.
Конечно, NiosII удовлетворяет с лихвой, но есть задачи и для души...
Автор: iosifk May 26 2014, 06:48
Для подобных загрузок надо знать, как вместе с процессором разместить в EPCS программу к нему, и как все это из EPCS выгрузить. Для NiosII это решается интегрированной средой и с применением jic-файла, но не понятны детали, как это все делать и увязать самому.
Конечно, NiosII удовлетворяет с лихвой, но есть задачи и для души...
У меня есть на сайте статьи "микропроцессор своими руками"...
А вообще маленький микроконтроллер делается быстро. Самое главное - это сделать систему команд. И еще 2 стека: стек возвратов и стек данных. Двухпортовка в качестве регистрового файла... И команды перехода по выбору бита из байта.
Будут вопросы - могу подробнее объяснить.
Автор: Stewart Little May 26 2014, 06:59
Для подобных загрузок надо знать, как вместе с процессором разместить в EPCS программу к нему, и как все это из EPCS выгрузить. Для NiosII это решается интегрированной средой и с применением jic-файла
Автор: alman May 26 2014, 10:01
Это должно получиться в результате, но пока ещё работа далека от завершения. В текущем состоянии устройство представляет из себя маленький и довольно простой 32-битный микропроцессор. Единственное, что может оттолкнуть от его использования - отсутствие прерываний. При желании прерывания можно реализовать сверху, обернув ядро, но в конечном устройстве прерывания будут замещены сообщениями, поэтому не вижу особого смысла разрабатывать то, от чего потом придётся откзаться.
Посмотрите вот это (кликабельно):
http://electronix.ru/redirect.php?http://everest.l4os.ru/show_scan_code/
Для подобных загрузок надо знать, как вместе с процессором разместить в EPCS программу к нему, и как все это из EPCS выгрузить. Для NiosII это решается интегрированной средой и с применением jic-файла, но не понятны детали, как это все делать и увязать самому.
Конечно, NiosII удовлетворяет с лихвой, но есть задачи и для души...
Задачи для души, по моему скромному мнению, это самый лучший стимул для разработки.
Я использовал мегафункцию ROM для размещения интерактивного монитора и загрузчика по протоколу X-modem непосредственно в ПЛИС.
В принципе, в микрокод можно поместить довольно сложные программы.
Ой... Вы имеете в виду как загрузить из EPCS пользовательскую программу в процессор и что NiosII умеет это делать.
Да, я тоже хотел бы это знать, как можно "программно" прочитать регион памяти из EPCS, в которой зашита прошивка устройства. Некоторая информация есть http://electronix.ru/redirect.php?http://marsohod.org/index.php/ourblog/11-blog/261-sfl.
Автор: Грендайзер Jun 25 2014, 12:28
Здравствуйте, товарищи! Не совсем пишу туда куда надо, но не хочу создавать целую тему, во всяком случае пока что, так что выскажусь здесь. Не имю большого опыта в работе с софт процессорами, но весчь безусловна интересная и архиполезная! Вот и я гуляя по просторам тырнета в поисках халявный ядрышек набрёл на сайтик http://electronix.ru/redirect.php?http://www.oreganosystems.at/?page_id=96 на коем валяется бесплатный проектик ядра 8051. Вообщем собрал я его и запустил, удачно поморгал сетодиодиками, но вот в итоге встал вопрос, что дальше то? У меня стоит задача общения с n-ым кол-вом устройств по уарт на скорости до 1Мб/с. Однако как я понял, по диодикам, ядро работает не так что б аж "В ЛЁТ"! На симулирование времени не было. Досканально разбирать код - крыша съедит, нет ни времени ни желания. Правда прогнал его через TimeQuest, в коем я совсем и не спец (ограничения задал лишь на клоковую частоту) ну и на 25МГц полезли слаки (хотя в даташитах написано, что эту частоту выставлять и надо). В составе ядра имеется т.н. datamux, который и портил картину - весь проект тактируется по переднему фронту, а этот блок по заднему! В следствии точо, что как я понял из схемы он и не нужен вообщем (схема видимо сыровата и последний раз правилась аж 10 лет назад) то я его исключил. И вроде на 25МГц завелось. Но вот мож но ли ещё частоту задрать? Вообщем вопрос в следующем, кто нибудь вообще с этой штукой ковырялся и стоит ли вообще её ковырять?
P.S.
Сложно представить, во всяком случае если он эконом класса... т.е. БЕСплатный! АВРка и та могутнее в ряде случаев будит, хотя конечно если количество интерфейсов или счётчиков не нормировано... то да-с...
Автор: iosifk Jun 25 2014, 12:34
Вообщем вопрос в следующем, кто нибудь вообще с этой штукой ковырялся и стоит ли вообще её ковырять?
На открытых проектах полно разных процессоров. Так зачем их искать по "помойкам", да еще тех, которые не поддерживаются...
Чем не устраивают те, к которым есть компиляторы? Скажем Альтеровские? Или бесплатные Актеловские?
А может вообще, N+1 автомат нужен и все дела?
Автор: Грендайзер Jun 25 2014, 12:56
Ну по поводу открытых проектов - как я понял эти занимаются все у кого душа к этому тяготеет, и прожжёный спец и начинающий любитель... так что как попадёшь, и в этом плане данное ядро ничем не отличается от открытых ресурсов. А вот дока на него очень качественная! Теперь, что значит
Программку то я для него написал и скомпилил!!! Более того скоомпилил в последней (бесплатной версии) Keil, её я скачал с сайта совсем не давно. Да и ядро это тащем то популярное... относительно, даже в нынешнее время! Ниос же как я писал эконом класа меня не устроил (не успевает он достойно обрабатывать прерывания на той скорости что я указывал), а "экспропреировать" его не выходит. С актеловскими вообще не знаком и как вообще аолучится ли их в альтеру то засунуть?
Автор: Leka Sep 1 2014, 14:16
Для нового проекта перешел на Altera. Попробовал перенести давнишнее ядро, оптимизированное под Xilinx:
http://electronix.ru/forum/index.php?showtopic=52166&st=105&p=597323&#entry597323
и сразу проблемы:
1) Квартус ни под каким соусом не хочет есть Верилоговское описание True Dual Port памяти с сигналом разрешения клока. Это действительно так, или плохо смотрел?
2) Квартус не хочет автоматом размещать в MLAB мелкие регистровые файлы с асинхронным чтением, без явного размещения атрибута (* ramstyle = "MLAB, no_rw_check" *) перед каждым объявлением мелкой памяти. Это действительно так, или плохо смотрел?
Пока-что двухпортовую память выделил в отдельную мегафункцию, и вставил нужный атрибут перед объявлением регистрового файла (но это неудобно, тк Верилоговский код синтезируется автоматом из другого описания). Дизайн заработал, результат синтеза для 32-разрядного ядра(Фон-Неймановская архитектура с 1К РФ в памяти) + память(2К слов) + UART + кнопки + светодиоды:
; Fitter Summary ;
+---------------------------------+--------------------------------------------+
...
; Family ; Cyclone V ;
; Device ; 5CGXFC5C6F27C7 ;
; Timing Models ; Final ;
; Logic utilization (in ALMs) ; 203 / 29,080 ( < 1 % ) ;
; Total registers ; 197 ;
; Total pins ; 26 / 364 ( 7 % ) ;
; Total virtual pins ; 0 ;
; Total block memory bits ; 73,728 / 4,567,040 ( 2 % ) ;
...
+---------------------------------+--------------------------------------------+
Как описать такую память на Верилоге, чтобы Квартус понял?
|
Автор: Kopa Sep 1 2014, 14:44
А вообще маленький микроконтроллер делается быстро. Самое главное - это сделать систему команд. И еще 2 стека: стек возвратов и стек данных. Двухпортовка в качестве регистрового файла... И команды перехода по выбору бита из байта.
Будут вопросы - могу подробнее объяснить.
"Наследие" MISC архитектуры?
Автор: Leka Sep 1 2014, 17:57
Не понял, к кому вопрос. Но могу пояснить, зачем мне понадобилось реанимировать собственное маленькое ядро - для проверки кое-каких идей по описанию схем с целью синтеза. Верилог (и тп) в синтезе == ассемблер в программировании. Ушли от ассемблера - давно уже пора уходить и от Верилога (и тп).
Поэтому и встал вопрос описания памяти. В ISE именно с этим проблем нет (но есть другая принципиальная проблема, почему и перешел на Квартус).
Автор: Stewart Little Sep 2 2014, 09:02
...
Как описать такую память на Верилоге, чтобы Квартус понял?
Не оно: http://electronix.ru/redirect.php?http://www.altera.com/support/examples/verilog/ver-true-dual-port-ram-sclk.html ?
Ну и другие примеры там посмотреть можно...
Автор: Kuzmi4 Sep 2 2014, 09:34
У меня вот такое нормально работает на альтере и хилых, не совсем разрешение клока конечно но может вам подойдёт:
//////////////////////////////////////////////////////////////////////////////////
module sdpram #(parameter p_DW = 0, parameter p_AW = 0)
(
// SYS_CON
input i_clk,
// IN / port-a
input i_we_a,
input [p_AW-1:0] iv_addr_a,
input [p_DW-1:0] iv_data_a,
// OUT / port-b
input i_rd_b,
input [p_AW-1:0] iv_addr_b,
output reg [p_DW-1:0] ov_data_b
);
//////////////////////////////////////////////////////////////////////////////////
// ram-MEM
reg [p_DW-1:0] sv_mem [2**p_AW-1:0];
//////////////////////////////////////////////////////////////////////////////////
//
// Construct "Simple Dual Port RAM" logic
//
always @ (posedge i_clk)
begin : RAM_LOGIC
// IN / port-a
if (i_we_a)
sv_mem[iv_addr_a] <= iv_data_a;
// OUT / port-b
if (i_rd_b)
ov_data_b <= sv_mem[iv_addr_b];
end
//////////////////////////////////////////////////////////////////////////////////
endmodule
Автор: Serhiy_UA Sep 2 2014, 10:20
Уточните, в чем проблема и почему переход на Квартус ее решил...
Сделал недавно небольшой софт RISC-процессор на 8 разрядов. Память команд и данных по 4К. Система команд - 25 инструкций, схожая на MCS51. Всего 20% времени ушло на verilog-синтез и 80% - на программирование на С++ транслятора с ассемблера в машинные коды.Память программ сначала была одно-, а потом двух-портовая, что в итоге позволило двухбайтные команды также выполнять за один такт. На Cyclone III скорость 100 MГц.
Выгода этого дела - процессор можно постоянно улучшать как по системе команд и функционалу, так и по производительности. Если будет свободное время…
Автор: Leka Sep 2 2014, 16:22
Такое описание синтезируется:
module mem(
output reg [10-1:0] qA, qB,
input [10-1:0] dA, dB,
input [10-1:0] aA, aB,
input weA, weB, reA, reB, clkA, clkB
);
//(* ramstyle = "M10K, no_rw_check" *)
reg [10-1:0] ram[2**10-1:0];
always@(posedge clkA)
if(weA)
ram[aA] = dA;
always@(posedge clkB)
if(weB)
ram[aB] = dB;
always@(posedge clkA)
//if(reA)
qA <= ram[aA];
always@(posedge clkB)
//if(reB)
qB <= ram[aB];
endmodule
а с сигналами разрешения чтения не синтезируется. Придется костыль приделывать...
Мои интересы сейчас - переход на более высокий уровень описания синхронных схем.
И Quartus намного быстрее ISE синтезирует кошмар, сгенерированный моими прогами.
По поводу простого ядра - могу выложить свое 5-летней давности (более поздние еще не реанимировал) с простым компилятором(без исходника), но код малочитаем: 1) некоторые блоки ручками соптимизированы, 2) весь код автоматически сгенерирован из другого описания, в котором все сигналы по-умолчанию 64-разрядные(и тп), 3) док нет, тк это просто один из экспериментов по поиску "оптимальной" архитектуры.
Автор: Serhiy_UA Sep 3 2014, 05:29
Leka, если не трудно, то уточните.
Меня еще интересует метод повышения быстродействия для стандартных инструкций для RISC-процессоров за счет конвейеризации. Где бы почитать об этом?
Автор: Leka Sep 3 2014, 07:56
top.v - топ-модуль
soc.v - ядро + uart + кнопки + светодиоды
memA.v - RAM для CycloneV
memX.v - RAM для Xilinx
top.hex - код для загрузки ядра по uart (содержит служебную информацию)
q.pas - тестовая программа (конструкции языка + N-ферзей)
c.bat - запуск компилятора и симулятора
compile.exe - компилятор (без каких-либо проверок синтаксиса и тп, winXP), создает top.hex
core.exe - потактовый симулятор ядра (winXP), исполняет top.hex .
sof.bat - вызывает jtag загрузчик и устанавливает параметры uart, надо поправить путь к top.sof и номер uart
top.bat - компилирует программу и загружает код в ядро, надо поправить номер uart
u.exe - выводит на экран поток из uart (u.c, winXP)
По отношению к верилогу.
Это целый опус писать надо, не сейчас.
Автор: Leka Sep 4 2014, 20:39
Кстати, top.v для CycloneV Квартус 9sp1 (какой был с моделями старых Циклонов) без переделки собрал для CycloneIII, заменив асинхронный MLAB на синхронный M9K 
Платы с CycloneIII под рукой нет (только с CycloneV), если кто проверит в железе - буду признателен.
Автор: Копейкин Dec 18 2014, 13:21
Многоуважаемые проектировщики собственных процессоров.
Поделитесь, пожалуйта, информацией, где можно почитать про микрокоды,
для разработки собственного процессора.
Разработка, инструментарий, практические советы, внятные примеры...
Автор: yes Dec 18 2014, 15:10
есть книжка в свободном доступе VHDL Coocbook
там в качестве примера процессор
но по хорошему, нужно брать на Opencores.org ядро процессорное и смотреть, как сделано. еще есть leon от gaisler-а - но это лучше для понимания как делать микропроцессорную систему, само ядро там, по-моему, сложно описано - трудно разбираться
ведь процессор не для развлечения, а для исполнения программ - то есть нужны компиляторы, отладчики и пр. поэтому совсем "свой" процессор смысла делать мало
для совсем простого - просто посмотреть Zylin ZPU проект
Автор: Serhiy_UA Jan 13 2015, 10:47
Представляю свой 8-разрядный софт процессор miniByte, реализованный в среде QII 8.1 на Cyclone III.
Приложение miniByte.rar включает:
miniByte.pdf – краткое описание структуры процессора и сиcтемы команд.
mb.exe - транслятор с ассемблера mb.asm в файл mb.mif
mb.asm – пример кода с выводом текста «HELLO» на LCD.
Процессор miniByte предназначен для программирования внутри ПЛИС, с возможностью изменять под задачу его архитектуру и систему команд.
Система команд miniByte схожа с 51 архитектурой, но сокращена до 32 команд с длинами в один или два байта.
Тактовая частота до 100 МГц, а команды выполняются за 1 или 2 такта. Память RAM и ROM емкостью по 4096*8 реализована на 2-х портовой внутренней памяти М9К. Стек в RAM произвольной длины. Систему прерывания пока не делал.
Синтез софт процессора на verilog и транслятор на С++ написал сам.
Для трансляции запустить mb.exe в том же директории, где и mb.asm. Создастся файл mb.mif, используемый далее в QII при загрузках в ROM.
Средствами QII 8.1 можно симулировать программу из mb.mif до уровня регистров.
После конфигурирования ПЛИС, процессор сбрасывается сигналом locked от мега-функции ALTPLL.
Автор: alman Feb 15 2015, 11:13
Конкуренция растёт.
А я предлагаю 32-разрядный микропроцессор. Точнее, архитектуру. Вот, намедни сделал карту системы команд.
http://electronix.ru/redirect.php?http://everest.l4os.ru/cpu_commands_map_v1_1/
Разумеется, по простоте и компактности он не может конкурировать с 8-ми битными микроконтроллерами, но у него есть другие преимущества - отличная расширяемость и высокая плотность кода. Желтым помечены неназначенные коды операций.
Когда (и если) заработает встроенная многозадачность, то проект будет достоин отдельной темы в этом подфоруме.
А вот так может выглядеть программа на ассемблере для этого процессора
http://electronix.ru/redirect.php?http://everest.l4os.ru/aliases_for_registers/
Знаю проекты, которые продвинулись значительно дальше моего, но с точки зрения возможностей архитектуры я готов пободаться.
Автор: Serhiy_UA Feb 16 2015, 06:35
Здесь мне интересны методы аппаратной реализации процессора в HDL, а также способы и детали программирования транслятора с ассемблера, ну и архитектура в целом. То есть, кто и как это все реализует…
У Вас, как я понимаю, задача аппаратной реализации операционной системы... Один мой знакомый, правда в Америке, что-то подобное делает.
Автор: ~Elrond~ Mar 11 2015, 20:40
Serhiy_UA
Автор: Maverick Mar 12 2015, 07:04
А исходники самого проца (rtl) и ассемблера вы можете выложить?
http://electronix.ru/forum/index.php?s=&showtopic=60367&view=findpost&p=1305466
на 2 поста выше...
Автор: ~Elrond~ Mar 12 2015, 07:51
Maverick
А вы вообще скачивали этот архив? Буду весьма благодарен, если вы найдёте там хоть один verilog файл.
Автор: Timmy Mar 12 2015, 08:36
Мне кажется, что miniByte подходит только для самых простых задач - ну типа светодиодом поморгать, передать в ком порт константную строчку и т.п. Поскольку в нём нет даже сложения двух регистров(сложение возможно только с константой), более сложные операции придётся выполнять, примерно как на машине Тьюринга .
Автор: des00 Mar 12 2015, 08:45
.ну не факт. вот на http://electronix.ru/redirect.php?https://ru.wikipedia.org/wiki/Motorola_MC14500B народ даже работал, минибайт по сравнению с этим супер пупер проц
Автор: Serhiy_UA Mar 12 2015, 09:02
.Timmy, спасибо за замечание!
Проглядел, исправлю. Бывает, когда все делаешь сам.
Теперь вместо команды INC A, введу двухбайтную ADD A, Rx. Ведь аккумулятор инкрементируется и через ADD A, xy.
Проблем нет, я как раз и хотел обсуждения…
Сравнение с машиной Тьюринга забавно, а какая на самом деле там была система команд, кто знает?
Да, еще для затравки. Хотел сделать софт-процессор "полуБайт". То есть с данными в 4 бита. Пока только хочу... Тоже для микро применений.
Автор: des00 Mar 12 2015, 09:16
описание языка brainfuck почитайте. это оно и есть
возьмите пикоблейз и прокачайте его до нормального уровня (большой регистровый файл, 4К команд, AXI), вот это будет дело
Автор: x736C Mar 12 2015, 09:30
Как раз 3 команд не хватает до pic'а (35 команд).
Может тогда все команды, где осуществляются операции с заданной константой, перевести в режим работы с аккумулятором, как у Motorola MC14500B, ссылку на который привел ув. des00.
#2 AND B RR ← A • B
#3 STO TEMP RR = A • B → TEMP
#4 LD C RR ← C
#5 AND D RR ← C • D
#6 OR TEMP RR ← C • D + (TEMP = A • B) = A • B + C • D
#7 STO LOAD RR = A • B + C • D → LOAD
Автор: Maverick Mar 12 2015, 11:33
А вы вообще скачивали этот архив? Буду весьма благодарен, если вы найдёте там хоть один verilog файл.
честно признаюсь, не скачивал - verilog файлов в архиве действительно не оказалось...

Автор: Leka Mar 12 2015, 11:37
У меня для проекта "Си как HDL, или Верилог без always" (см. marsohod.org ) написан софт-процессор, совместимый по ассемблеру с ядром msp430 - программы можно писать на Си с использованием GCC. Но компиляция с ассемблера в машинные коды делается самопальной программой. Проект делался только как демо-пример, поэтому без поддержки библиотек и тп. Без периферии занимает ~350 ЛЕ, быстродействие ~50МГц msp430.
Автор: des00 Mar 12 2015, 15:36
ткните пожалуйста носом, поиск в проектах на этом сайте привел меня в никуда
 Спасибо.
Спасибо. Автор: ~Elrond~ Mar 12 2015, 15:59
des00
Я так понял, вот эта тема http://electronix.ru/redirect.php?http://marsohod.org/index.php/forum-33/razdel-predlozhenij/3028-online-sintez-proshivki#3101
Только там нет исходников процессора.
Автор: Timmy Mar 19 2015, 06:05
Однажды я из любопытства и для тренировки написал за 4 дня на верилоге клон Lattice mico8(это примерно то же, что пикоблейз), когда он ещё был сам по себе. В результате у меня получилась fmax 145MHz против 85 у оригинала, меньше объём LE, и один такт на инструкцию(кроме исполняемых переходов), вместо двух. Потом посмотрел, как криво mico8 интегрировали в систему с wishbone, и энтузиазм сделать так же и опубликовать почему-то пропал
. В общем, я легко могу сделать на верилоге свободный и открытый аналог пикоблейза с улучшенной растактовкой и системой команд(по прикидке, можно, например, сделать 64 общих регистра и 4килослова кода), присобачить его мастером к AXI/Avalon, и написать на TCL ассемблер. А вот сделать под него порт binutils+gcc энтузиазма уже не хватит. Хотя можно, например, сделать точный клон mico8 под AXI, чтобы к нему подходил софт от Латтис.
Автор: ~Elrond~ Mar 19 2015, 07:24
Timmy
Поделитесь пожалуйста своими наработками по клону Mico8 (если это не коммерческий проект, конечно).
Автор: des00 Mar 19 2015, 09:13
При всем уважении не верю. По тому как : один такт на инструкцию вида reg = opA + opB означает регистровый файл с асинхронным чтением + асинхронное АЛУ. Регистровый файл у латекса сделан на распределенной памяти, поэтому при переводе на однотактность, вы могли только убрать из АЛУ регистры. Этим, при всем желании, вы не могли увеличить тактовую частоту, тем более 1,7 раза.
Поэтому имею следующее предубеждение :
1. затык по тактовой мико8 находиться не в АЛУ и причина такой низкой тактовой в чем то другом (двухтактовость как раз можно объяснить).
2. в своей реализации вы явно/неявно вырезали то место, которое к этому приводило и ваш проц не является полнофункциональным аналогом мико8
будет интересно отреверсить ваш код, если выложите
Вот это будет интересно, неужели вы на асихронном АЛУ получите больше 200-250МГц которые дает пикоблейз со своим синхронным АЛУ. Ну и если начнете пилить систему команд, то интересно как вы решите ограничение ширины слова команды == оптимальной разрядности блочной памяти
Автор: Timmy Mar 19 2015, 11:30
Поделитесь пожалуйста своими наработками по клону Mico8 (если это не коммерческий проект, конечно).
Автор: ~Elrond~ Mar 19 2015, 11:34
Timmy
Не знаю, я обычно не заморачиваюсь правовыми вопросами, выкладывая что-либо в общий доступ. Вроде как LGPL самая свободная лицензия, типа делайте вообще что хотите.
Автор: x736C Mar 19 2015, 11:53
BSD
~Elrond~, отнюдь. Далеко не такая свободная, как Вам представляется.
Автор: des00 Mar 19 2015, 14:54
лучше всего MITовская лицензия, у меня все открытые проекты под ней идут. Смысл простой : используется как есть, на свой страх и риск. Из ограничений не убирать шапку файла с указанием автора
Автор: x736C Mar 19 2015, 15:04
То есть можно использовать в закрытых коммерческих проектах, менять исходный код? Неплохо.
Автор: des00 Mar 19 2015, 15:31
MIT License
// this software and associated documentation files (the "Software"), to deal in
// the Software without restriction, including without limitation the rights to
// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
// the Software, and to permit persons to whom the Software is furnished to do so,
// subject to the following conditions:
//
// The above copyright notice and this permission notice shall be included in all
// copies or substantial portions of the Software.
//
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
// FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
// COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
// IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
// CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
//
правда что-то про автора я тут не вижу
Автор: NikolayXXX Mar 19 2015, 17:54
. В общем, я легко могу сделать на верилоге свободный и открытый аналог пикоблейза с улучшенной растактовкой и системой команд(по прикидке, можно, например, сделать 64 общих регистра и 4килослова кода), присобачить его мастером к AXI/Avalon, и написать на TCL ассемблер. А вот сделать под него порт binutils+gcc энтузиазма уже не хватит. Хотя можно, например, сделать точный клон mico8 под AXI, чтобы к нему подходил софт от Латтис.
Большие получились отличия по системе команд от lm8? Не писать же программы в исходных кодах.
Автор: des00 Mar 19 2015, 17:56
меги 128ые (128к флеша) забивали на асме, а тут всего 4к команд. мельчает народ

Автор: Leka Mar 19 2015, 20:35
Зависит от компилятора ЯВУ - насколько переносимым является генерируемый ассемблерный код. Например, переходы - на метку, или же смещение задается константой, и тд и тп.
Для msp430, например, GCC выдает хороший ассемблерный код в плане независимости от системы команд и машинных кодов - можно внести заметные изменения.
Автор: Timmy Mar 20 2015, 09:46
Выкладываю обещанный клон Мики8. mica8.7z ( 417.5 килобайт )
: 63
mica8.7z ( 417.5 килобайт )
: 63
Собирается под XP2 на частоте 137МГц(ну немножко медленнее, чем хвастался).
С пикоблейзом его сравнить по частоте невозможно, так как нужна оптимизированная версия под Ксайлинкс. Думаю, что будет примерно одинаково(+-20%). Латтис по частоте удалось обогнать за счёт того, что они вообще толком не оптимизируют код. Мой дизайн эффективнее за счёт двухступенчатого конвейера. Ступени: выборка из BRAM(а это доолго); декодирование+выполнение+обратная запись. В сравнении с Picoblaze или LatticeMico8, у меня к критическому пути добавляется вторая половина АЛУ, зато убирается выборка из BRAM, так что выходит примерно то же самое.
Теоретически процессор должен быть полностью совместим по командам со старым LatticeMico8, до того, как его пришили к Вишбону.
Думаю, что использование 8-битных ядер с кодом более 8-16K нецелесообразно, так как площадь памяти начинает существенно превышать площадь процессора, 8-битное управление большой памятью требует извращений, а ресурсы чипа при этом используются неэффективно. Единственная причина появления монстров типа atmega128, IMHO, в том, что некоторые разработчики страдают синдромом утёнка, изучив в молодости 8051 или AVR или PIC.
Всем спасибо за советы по лицензии.
Автор: ~Elrond~ Mar 20 2015, 11:21
Timmy
Спасибо за исходники. Там есть модуль pmi_rom, это корка ксайлинксовой памяти? Какая у неё latency на чтение?
Автор: Timmy Mar 20 2015, 12:14
Спасибо за исходники.
Там есть модуль pmi_rom, это корка ксайлинксовой памяти? Какая у неё latency на чтение?Там всё под Латтис. pmi_rom - это корка блочной памяти в режиме ПЗУ, латентность один такт.
Автор: Leka Mar 20 2015, 13:18
А отдельного Си компилятора нету, чтобы на Альтеру имело смысл перенести ядро?
Автор: NikolayXXX Mar 20 2015, 16:57
Как мой вопрос связан с количеством ассемблерных инструкций?
Вопрос был связан со средствами разработки (отладчик, симулятор, транслятор/компилятор). Новая система команд - новые инструменты.
А 128к ассемблерных инструкций меня не испугаешь.
Для msp430, например, GCC выдает хороший ассемблерный код в плане независимости от системы команд и машинных кодов - можно внести заметные изменения.
От компилятора ЯВУ на мой взгляд отличия системы команд не зависят вообще. Не процессор же пишут под конкретный компилятор, а компилятор под систему команд процессора. Править ассемблерный код после компилятора на мой взгляд не очень продуктивное занятие.
А как система команд зависит о шины? Там вроде всего две команды работы с шиной import/inp и export/outp.
Автор: Timmy Mar 23 2015, 06:13
Для LatticeMico8 есть backend к gcc, так что компилятор Си как бы есть. Правда, я что-то не видел исходников патча для binutils, только gcc. С-компилятор там какой-то странный, он во всех моделях памяти(включая 8-битную) делает 32-битные указатели(по-крайней мере, так в мануале написано). В случае переноса на классические Циклоны, придётся хранить регистры, стек и scratchpad в одном M9K(туда же можно запихнуть и код
), при этом один такт на инструкцию невозможен. Предполагаемый объём для клона Mico8 - 270LE.
Автор: Leka Mar 23 2015, 10:18
Если С-компилятор - интегрированный в софт от Lattice, тогда смысла в переносе lm8 на Циклоны нет, наверно.
Согласен, у M9K/etc нет гарантированного режима "write before read", чтение и запись _данных_ в одном такте рискованно делать (без проверки адресов).
Автор: des00 Mar 23 2015, 10:20
), при этом один такт на инструкцию невозможенквазиасинхронку сделать.
Автор: ~Elrond~ Mar 23 2015, 11:09
Leka
Для имитации асихронного поведения блочной памяти на cyclone III я прибегал к чтению/записи данных по negedge, частота конечно падает, но работает нормально.
Автор: Serhiy_UA Mar 23 2015, 11:55
В моем miniByte на Cyclone III с памятью М9К, инструкция выполняется за один период тактовой частоты. Это при входном регистре адреса в М9К и без выходного регистра данных... Для обработки двухбайтных команд применил двухпортовый доступ, где текущий и последующий байт считываются одновременно..
Что тут не так, в чем вопрос?
Автор: ~Elrond~ Mar 23 2015, 12:10
Serhiy_UA
А как вам удалось обойтись без выходного регистра данных, если память в cyclone III синхронная? на выражение типа такого
Автор: Serhiy_UA Mar 23 2015, 12:32
А как вам удалось обойтись без выходного регистра данных, если память в cyclone III синхронная?
Для памяти программ используется Tools ->MegaWizard Plag-In-Manager ->Memory Compiler ->ROM 2-PORT, где в диалоге задается регистр адреса на входе и выход памяти без регистра данных. А далее двухпортовая память включается в проект примерно таким кодом. То есть, я задал в Memory Compiler тактирование только регистра адреса:
[//------- ROM 2 ------
rom_2p rom_2p_inst (
.address_a ( a),
.address_b ( a+1),
.clock ( clk),
.q_a ( q),
.q_b ( q1)
);
][/code]
Автор: ~Elrond~ Mar 23 2015, 12:41
Serhiy_UA
Отключение этой опции в мегавизарде приводит к уменьшению latency с 2 до 1 такта, но никак не ликвидирует её полностью.
Автор: Serhiy_UA Mar 23 2015, 12:58
Отключение этой опции в мегавизарде приводит к уменьшению latency с 2 до 1 такта, но никак не ликвидирует её полностью.
always @ (posedge clk or posedge reset) //write PC
if (reset) PC<=0;
else PC<=a;
То есть, какая-то комбинационная схема КС, что в момент выполнения текущей, формирует адрес "а" для следующей команды.
С выхода КС адрес "а" одновременно записыается и в программный счетчик РС и в регистр адреса, что есть на входе памяти М9К.
Таким образом все выполняется за такт, и с одним фронтом clk,
Да еще, второй регистр на выходе М9К, позволит на конвейере выполнять две команды одновременно. Но здесь надо почитать теорию, что бы не изобретать велосипед. Пока мои поиски соответствующей литературы ничего не дали..
Автор: Timmy Mar 23 2015, 13:54
Что тут не так, в чем вопрос?
Да, можно сделать ,то что надо, на двух M9K, плюс потребуются два bypass регистра и схема обнаружения коллизий чтения/записи по одному адресу, это +30LE примерно. Так в nios2 делают, просто для пикопроцессора это чересчур, IMHO.
Автор: ~Elrond~ Mar 23 2015, 14:15
Timmy
А можете поподробнее рассказать, как альтеровцы сделали однотактовое чтение из блочной памяти в ниосе?
Автор: Timmy Mar 25 2015, 16:40
А можете поподробнее рассказать, как альтеровцы сделали однотактовое чтение из блочной памяти в ниосе?
Конкретно у альтеровцев, полагаю, классическая архитектура MIPS, по ней в Сети достаточно материала.
А по-простому, это можно сделать так: берутся две двухпортовых M9k, порты записи объединяются, в результате оба M9k содержат одинаковую информацию. А порты чтения независимо читают первый и второй операнды. Только необходимо, чтобы память поддерживала режим "сначала пишу, потом читаю", что означает, что при совпадении адресов чтения и записи на выходе должны появиться свежезаписанные данные. Поскольку M9K такой режим не поддерживает, придётся его эмулировать при помощи внешней обвески:
req addr_eq;
always @(posedge clk)begin
addr_eq <= wr_addr == rd_addr;
bypass <= wr_data;
end
assign rd_data = addr_eq? bypass: m9k_rd_data;
Такую обвеску надо независимо добавить к обоим M9k, работающим у нас параллельно. Странно, что это не умеет делать Мегавизард
.Автор: des00 Mar 26 2015, 04:59
.это умеет делать квартус сам, при синтезе памяти из описания, как рекомендовано в темплейтах
Автор: Leka Mar 26 2015, 08:42
Из даташита на CycloneIII (для CycloneV то-же самое):
"Mixed-Port Read-During-Write Mode
This mode applies to a RAM in simple or true dual-port mode, which has one port reading and the other port writing to the same address location with the same clock. In this mode, you also have two output choices: Old Data mode or Don't Care mode. In Old Data mode, a read-during-write operation to different ports causes the RAM outputs to reflect the old data at that address location. In Don't Care mode, the same operation results in a “Don't Care” or unknown value on the RAM outputs."
А синтезировать память из описания Квартус не может, если есть сигнал разрешения клока.
Автор: des00 Mar 26 2015, 09:58
В темплейтах 9.1 квартуса.
// Simple Dual Port RAM with separate read/write addresses and
// single read/write clock
module simple_dual_port_ram_single_clock
#(parameter DATA_WIDTH=8, parameter ADDR_WIDTH=6)
(
input [(DATA_WIDTH-1):0] data,
input [(ADDR_WIDTH-1):0] read_addr, write_addr,
input we, clk,
output reg [(DATA_WIDTH-1):0] q
);
// Declare the RAM variable
reg [DATA_WIDTH-1:0] ram[2**ADDR_WIDTH-1:0];
always @ (posedge clk)
begin
// Write
if (we)
ram[write_addr] <= data;
// Read (if read_addr == write_addr, return OLD data). To return
// NEW data, use = (blocking write) rather than <= (non-blocking write)
// in the write assignment. NOTE: NEW data may require extra bypass
// logic around the RAM.
q <= ram[read_addr];
end
endmodule
Автор: ~Elrond~ Mar 26 2015, 10:21
// NEW data, use = (blocking write) rather than <= (non-blocking write)
// in the write assignment. NOTE: NEW data may require extra bypass
// logic around the RAM.
И это всё конечно хорошо, но всё равно ни о каком чтении за один такт из синхронной памяти речи здесь не идёт. ) Защёлкивать данные по заднему фронту - это конечно решение, но вряд ли получится даже 100 МГц тактовая. Есть ли другие варианты? Как альтера сделала регистровый файл на М9К, если у неё латенси 1 такт, а для регистрового файла нужно 0?
Автор: Timmy Mar 26 2015, 10:55
И это всё конечно хорошо, но всё равно ни о каком чтении за один такт из синхронной памяти речи здесь не идёт. ) Защёлкивать данные по заднему фронту - это конечно решение, но вряд ли получится даже 100 МГц тактовая. Есть ли другие варианты? Как альтера сделала регистровый файл на М9К, если у неё латенси 1 такт, а для регистрового файла нужно 0?
От регистрового файла не нужно 0, если правильно применять конвейер. Даже в моём вышеприведённом mica8 с двухступенчатым конвейером латентность регистрового файла 1. В первом такте/первой ступени выбирается код инструкции и номера регистров из этой инструкции подаются непосредственно на адресные входы модуля регистров, где будут защёлкнуты при смене тактов. Вскоре после начала следующего такта на выходе регистов будут необходимые значения, которые прогоняются через АЛУ, и к концу такта результат стабилизируется на входе данных записи регистрового файла. Из-за особенностей распределённой памяти удаётся обойтись двумя портами адреса, это особенно эффектно смотрится на Ксайлинксах.
А у Ниоса конвейер пятиступенчатый, там целый такт выделен на выборку из регистровой памяти и защёлкивание в FF непосредственно перед АЛУ.
Автор: Serhiy_UA Mar 26 2015, 11:19
к ~Elrond~
Вы намерены регистровый файл разместить в М9К?
Каков объем этого файла?
Если объем малый, то почему бы этот файл не разместить на регистрах?
Если все же остаться с М9К, то может сбрасывать часть данных из М9К в регистры, работать там с ними, а потом опять весь блок возвращать в М9К. Что-то типа кеша... Иначе только конвейер...
Автор: ~Elrond~ Mar 26 2015, 11:30
Serhiy_UA
Я знаю, что так сделано в ниосе, и мне интересно, как. Если конвейер - то это не интересно, так и я умею. )) Регистровый файл мне нужен в разных модулях разный, в зависимости от задачи. Обычно это 4-16 32-битных регистров, что в случае 16ти на LUT'ах делать довольно накладно.
Автор: Golikov A. May 19 2015, 12:43
Всем привет!
Есть немного странный вопрос, если коротко зачем процессору регистры? У меня есть очень длинное объяснение откуда возник этот вопрос, но его никто не прочтет.
Потому кому не трудно напишите что особенного вы видите в регистрах, в сравнении например с РАМ. А там тему можно будет и развить.
Автор: Alex77 May 19 2015, 12:53
Есть немного странный вопрос, если коротко зачем процессору регистры? У меня есть очень длинное объяснение откуда возник этот вопрос, но его никто не прочтет.
Потому кому не трудно напишите что особенного вы видите в регистрах, в сравнении например с РАМ. А там тему можно будет и развить.
быстрый + "без адресный" доступ.
алтернатива:
стек (форт)
spark (???) - там регистры отображены на общую память.
Автор: yes May 19 2015, 13:03
кто такое сказал?
у спарка регистровый файл как в обычном ARM-е, просто он больше по размеру и рабочее окно "ездит" по этому файлу. собственно, цель всего этого как раз избавится от стека на общей памяти - то есть когда следуют call-call-return-return то рабочие регистры можно в стек не сохранять а оставлять, вызываемый код к ним доступа не имеет
Автор: Golikov A. May 19 2015, 13:54
насчет безадресный не согласен, если регистров больше 1 то адресовать регистр надо. То есть мультиплексор все равно появляется
быстрый-возможно, вот думаю 3 блока РАМ чтобы можно было делать R1 + R2 -> R3, а учитывая 2 портовость брамов интересная идея. И опять же уход от стека, можно младшие адреса - адрес регистра, а старшие - адрес страницы, вход в прерывание, перебросил адрес страницы и дальше погнали. Что я не учитываю?
Автор: Leka May 19 2015, 16:31
http://electronix.ru/forum/index.php?showtopic=60367&st=60&p=763390&#entry763390
http://electronix.ru/forum/index.php?showtopic=60367&st=135&p=866940&#entry866940
http://electronix.ru/forum/index.php?showtopic=60367&st=165&p=1277540&#entry1277540
Автор: Golikov A. May 19 2015, 18:58
По ссылкам видно вы проделали большую работу,
Основной вопрос имеет ли смысл регистры делать массивом на ЛУТах, если сделать их на БРАМах где возникнут сложности?
Автор: krux May 19 2015, 19:07
|
свободного выхода от этого регистра в BRAM-е напрямую обратно в матрицу - нету.
т.е. регистр обратно не считать, автоинкремент не сделать
Автор: Timmy May 20 2015, 04:14
Потому кому не трудно напишите что особенного вы видите в регистрах, в сравнении например с РАМ. А там тему можно будет и развить.
Регистры - это вообще-то тоже РАМ, причём в хард процессорах они обычно делаются на такой же матрице, что и большая SRAM. В процессоре регистры отличаются короткой прямой адресацией, быстрым доступом без необходимости кэширования, локальностью(нет необходимости их синхронизировать в многоядерной системе). Хотя локальная РАМ в многоядерных DSP тоже бывает. Для эффективного хранения регистров в BRAM используется конвейер, типа http://electronix.ru/redirect.php?http://mi.eng.cam.ac.uk/~ahg/MIPS-Datapath/. Там рабочие копии регистров гуляют по быстрым защёлкам на границах ступеней конвейера ID/EX/MEM/WB, а за синхронностью рабочих копий и общей матрицы(которая на ступени ID) следит Forwarding Unit.
Автор: Golikov A. May 20 2015, 05:35
ну то есть надо на самом деле сделать 3 портовую оболочку брам, даже чуть проще 2 порта чтения и один запись, и автоматом получиться огромный регистровый файл.
А вот теперь вопрос, зачем регистры в таком решении отделять от РАМ проца? Выигрыш только в сокращении шины адресации?
В регистрах на LUTах можно за один такт складывать любые 2 и писать в третий, но эта возможность порождает дикие мультиплексоры которые жрут все LUTы, альтернативой я так понимаю служит несколько тактовая операция R1+R2->R3, реализуемая через 3 портовую БРАМ.
И в этом случае у меня получается что нет смысла делать отдельно БРАМ регистров, и включить его в общий РАМ проца. Правильно рассуждаю или я что-то не учел?
Автор: Ynicky May 20 2015, 17:09
А вот теперь вопрос, зачем регистры в таком решении отделять от РАМ проца? Выигрыш только в сокращении шины адресации?
В регистрах на LUTах можно за один такт складывать любые 2 и писать в третий, но эта возможность порождает дикие мультиплексоры которые жрут все LUTы, альтернативой я так понимаю служит несколько тактовая операция R1+R2->R3, реализуемая через 3 портовую БРАМ.
И в этом случае у меня получается что нет смысла делать отдельно БРАМ регистров, и включить его в общий РАМ проца. Правильно рассуждаю или я что-то не учел?
Давайте порассуждаем.
Команда в Вашем случае должна содержать:
Опкод - 1 слово.
Адрес первого операнда - 1 слово.
Адрес второго операнда - 1 слово.
Адрес приемника - 1 слово.
+ 2 такта минимум на чтение операндов.
+ 1 такт на исполнение в АЛУ.
+ 1 такт запись результата.
Итого получили 8 тактов.
В RISC процессоре:
2 такта на загрузку первого операнда.
2 такта на загрузку второго операнда.
1 такт на исполнение в АЛУ.
1 такт на запись результата.
Итого получили 6 тактов.
В Вашем случае можно сэкономить 1 такт начиная считывать первый операнд
не дождавшись конца загрузки команды.
Можно еще укоротить адреса операндов (например в одном слове 2 адреса источников).
Автор: Golikov A. May 21 2015, 05:08
не понял расчета)
у меня тогда получается 4 такта.
2 такта на чтение операндов и 1 такт на исполнение, 1 такт на запись.
Почему вы в такты включили размер команды? Или почему вы в RISC процессоре исключили загрузку команды?
Автор: Ynicky May 21 2015, 05:26
у меня тогда получается 4 такта.
2 такта на чтение операндов и 1 такт на исполнение, 1 такт на запись.
Почему вы в такты включили размер команды? Или почему вы в RISC процессоре исключили загрузку команды?
А где 4 такта на извлечение команды?
Если, конечно, Вы не сделаете извлечение 4 слов команды за 1 такт.
Иначе нарушается конвейер при выполнении каждой команды за 1 такт.
Я уже не говорю о том, что команды обработки данных перемежаются с командами ветвления.
Хотя это справедливо и для тех RISC, где каждая команда имеет длину в 1 слово.
Автор: Golikov A. May 21 2015, 07:28
Ну РИСКу тоже надо извлекать команду как не крути, так что им один такт тоже надо добавить.
Потом код операции размером в слово - очень много, нафига столько команд.
То есть остаются адреса, если память длинная, то они большие, это верно.
1. извлекаем адрес 1 операнда
2. Задаем адрес 1 операнда на РАМ, читаем адрес 2 операнда
3. Читаем 1 операнд, выставляем адрес 2 операнда, извлекаем код операции
4. Читаем второй операнд, извлекаем адрес результата
5. Обрабатываем команду, выставляем адрес результата
6. Сохраняем результат.
Команду даже можно в 2 такта выполнять, на 4 и 5. .
А я хочу пойти дальше ограничить адреса 256 значениями и словной адресацией, и сделать 32 битную команду с 8 битным кодом операции, тогда получаем за 1 такт все адреса и команды, читаем их, выполняем, сохраняем.
Но в целом я понял в чем смысл отделения регистров в особую группу, основное - сокращение поля адресов в команде.
Спасибо народ! %)
Автор: Timmy May 21 2015, 12:17
А я хочу пойти дальше ограничить адреса 256 значениями и словной адресацией, и сделать 32 битную команду с 8 битным кодом операции, тогда получаем за 1 такт все адреса и команды, читаем их, выполняем, сохраняем.
Ну если достаточно 256 слов памяти, почему бы и нет. Можно предусмотреть и команды доступа к "большой" памяти с непосредственным смещением 8-10 бит(2 бита откусить от кода операции), OpenRISC с этим как-то живёт
.А как вы будете кодировать команды с непосредственным операндом? Их, правда, можно сделать двухадресными, а не трёхадресными, как в MIPS, тогда появятся 16 свободных бит под непосредственный операнд.
Автор: krux May 21 2015, 12:53
забыли ещё про регистр-адрес текущей выполняемой инструкции.
если его тоже в озу хранить, то добавляйте такты на его чтение, а также при условных/безусловных переходах такты на его запись и чтение.
Автор: Golikov A. May 21 2015, 20:33
планировал его вторым словом после команды. Что-то аля Thumb2, то есть там 16 бит команда, но если надо 32. У меня будет 32 бита - стандарт, если надо 64.
Память команд будет с 64 шиной чтения, то есть после задания счетчика команд будет доступно сразу 2 слова, на случай если понадобиться операнд (таких случаев будет на самом деле 90%) в работе проца.
Счетчика команд, как и контрольный регистр - это будут 2 единственных регистра сделанных в ядре на ЛУТах. Счетчик команд будет жестко посажен на шину памяти команд, как адрес.
Как то так планировал. Мне и РАМ то по хорошему не нужна, для того что делаю, больше нужны всякие РОНы, но надо чтобы ядро все луты не сожрало.
Автор: Pavia Aug 22 2015, 17:34
Есть такой вопрос. Наверное на него легко найти ответ. Но что-то я не нашёл.
Процессор без портов в/в это не процессор. Собственно вопрос как их организовать? Наверно где-то есть статья для зелёных новичков, но что-то я не заметил. С примерами на Virelog.
Изучая схему IBM AT компьютеров там наглядно показана работа с портами. Но всё таки такой вопрос как принято это делать у плисоводов?
Обязательно ли в процессоре должен быть блок УУ(устройство управления, анг Control unit) который осуществляет выбор функции по #CS (chip select)
В IBM AT было всего 6 основных чипов по 16 портов каждый.
А вот в IBM PS/2 уже более "оптимально" каждый чип мог иметь произвольное число портов. Поэтому располагались они плотнее.
Отсюда вопрос какие есть инструменты для автоматического генерирования дешифратора адреса?
Ещё можно включить проверку адреса в сами функции, как это сделано в PIIX когда перешли с шины ISA на LPC.
PS. Наверно мне надо ещё что-то прочитать про мультиплексоры.
Автор: iosifk Aug 22 2015, 18:37
Процессор без портов в/в это не процессор. Собственно вопрос как их организовать? Наверно где-то есть статья для зелёных новичков, но что-то я не заметил. С примерами на Virelog.
PS. Наверно мне надо ещё что-то прочитать про мультиплексоры.
Странные выкладки приводят к еще более странным результатам...
Процессоры " без портов в/в" живут себе вполне прилично... Просто Вы не умеете их готовить. Примеров - полно на opencores...
"статья для зелёных новичков" - хотя бы у меня на сайте...
Автор: Pavia Aug 22 2015, 20:49
Процессоры " без портов в/в" живут себе вполне прилично... Просто Вы не умеете их готовить. Примеров - полно на opencores...
"статья для зелёных новичков" - хотя бы у меня на сайте...
А как тогда процессоры без портов получаю данные и выдают их в мир? Они же должны как-то взаимодействовать с окружающим миром.
По поводу ваших статей, так я их читал и перечитал. Но так и не нашёл где в них можно прочитать про дерево дешифровки адреса...
Автор: iosifk Aug 22 2015, 21:03
По поводу ваших статей, так я их читал и перечитал. Но так и не нашёл где в них можно прочитать про дерево дешифровки адреса...
Там есть статья о битовом процессоре. Это процессор, который работает как "память - память"... И к памяти добавлен блок ДМА, который сам циклически копирует содержимое этой памяти во внешние устройства ввода-вывода... А портов как таковых у процессора может и не быть. Например DEC или по нашему Электроника-60 не имела отдельных команд для ввода-вывода. Они располагались в общем поле памяти... А интеловская система придумана для сокращения дешифратора адресов и упрощения узла контроля...
Если в статьях что-то не понятно, то могу по скайпу словами рассказать..
Автор: agregat Aug 23 2015, 03:24
http://electronix.ru/redirect.php?http://www.fpgacpu.org/papers/soc-gr0040-paper.pdf, тут на стр.14 показана реализация портов ввода вывода
Автор: Pavia Aug 23 2015, 07:27
Мой вопрос касался "5.10 Control bus encoder" стр 13.
Спасибо, не совсем то, что я ожидал увидеть. Но ответ я понял, надо рисовать схему.
Автор: Serhiy_UA Oct 30 2015, 11:16
Еще один свой 8-разрядный софт процессор miniByte-2.
Отличия с предыдущей версией miniByte такие:
Число команд - 28
Доступных портов – до 256 (команды доступа IN и OUT).
Команды SBS и SBC условного перехода по значению любого бита порта.
Команды PBS и PBC модификации любого бита порта.
Работает на тактовой частоте 50 МГц.
.
Приложение miniByte_2.rar включает:
miniByte-2.pdf – краткое описание структуры процессора и сиcтемы команд.
mb2.exe - транслятор с ассемблера mb2.asm в файл mb2.mif и листинг mb2.lst,
mb2.asm – пример кода с выводом текста «HELLO» на LCD типа SC1602D.
Предыдущий miniByte был в http://electronix.ru/forum/index.php?showtopic=60367&st=180
Автор: Leka Nov 3 2015, 11:20
Сегодня только заметил новый пост в этой ветке...
Общие соображения. Если уж делать свой софт-процессор, то нужно подчеркивать, что именно, какая идея, отличает этот процессор от множества других. И делать упор на улучшение именно этих особенностей. И в описаниях/обсуждениях надо выделять эти изюминки.
Сейчас делаю проект, в который напрашивается мелкий софт-процессор.
Мелкий, поскольку 1) сам проект ориентирован на использование самых дешевых ПЛИС, 2) софт-процессор играет вспомогательную роль, в данном случае - сжимать-разжимать по простому алгоритму ~20..200КБайт/сек (20 в сжатом, до 200 в разжатом), и дрыгать ножками последовательного устройства. Скорости, как видно, небольшие, но алгоритмы желательно писать/отлаживать на ЯВУ, и программы в софт-процессор загружать без перепрошивки/перезагрузки ПЛИС.
И много кандидатов на эту роль?
Автор: Serhiy_UA Nov 3 2015, 12:44
Проект на verilog и транслятор к нему с ассемблера уже на C/C++ писал сам. В обеих этих стихиях много тонкостей, которые полезно бы здесь и обсуждать. А процессор хотел сделать свой и небольшой, в котором в каждый угол можно бы дотянуться, ну и чтоб работали, например, в мультипроцессорном режиме, вместе с аппаратными блоками ПЛИС…
На NiosII у меня было три крупных проекта, приемник и первичный обработчик от радара с выходом на Ethernet-100 и два имитатора радарных сигналов. Ну и в больших задачах я бы использовал NiosII...
Посмотрел Ваш топик «Си как HDL, или Verilog без always». Мне тоже приходила идея использовать для своего проектируемого софт-процессора сокращенный набор команд и уже готовую IDE (с кодированием в asm). Но здесь мои предпочтения на стороне 51-архитектуры как, например, МК Silabs и их среды uVision 3 от Keil, так как с ними много работал и в ассемблере, и в С. Может следующая генерация и будет такой…
...Интересное есть в "SoC для платы Марсоход2", что в http://electronix.ru/redirect.php?http://www.marsohod.org/forum-33/proekty-polzovatelej/1419-soc-dlya-platy-marsokhod2?limitstart=0
Автор: Leka Nov 3 2015, 16:12
Я о том, что хорошо-бы пояснить главную идею "своего" софт-процессора.
Например, процессор - "для души", тогда главное в нем - чтобы был "красивым". И ЛУТы/тактовая/ПО отходят на второй план, если это не входит в понятие "красоты". Можно уточнить/обсудить/поспорить, что делает архитектуру красивой, и как/куда двигаться.
Или процессор - "для дела". Тогда ЛУТы/тактовая/ПО выйдут на первый план. Можно уточнить/обсудить/поспорить, что важнее "для дела", и тд.
Автор: Leka Nov 3 2015, 17:14
"Для дела" я считал бы идеальным софт-процессор с архитектурой, оптимизированной под последовательное выполнение кода, написанного на _подходящем_ HDL.
Из плюсов - один язык описания как синтезируемого "параллельного" дизайна, так и компилируемой "последовательной" программы.
Сложный проект тогда можно безболезненно поделить на "параллельную" часть, требующую больших ресурсов ПЛИС + длительное время синтеза/сборки, и "мгновенно" компилируемую последовательную часть, жрущую только память (которая все дешевле, и которой все больше как внутренней, так и внешней). И по ходу дела менять границу между "параллельной" и "последовательной" частью.
Минус только один - отсутствие подходящего HDL...
Автор: Serhiy_UA Nov 4 2015, 06:28
Из 8-, 16- и 32-разрядных софт процессоров, я остановился бы сейчас на обсуждении 8-разрядных. Где важным был бы минимальный объем аппаратуры и минимальная система команд. Быстродействие пока на втором плане. Ну и еще ориентация на работу с портами, как в моем miniByte-2. И также важно, что есть свои, полностью открытые коды (на verilog и c/c++), где волен и добавлять, и убавлять все по своему усмотрению в зависимости от текущих требований.
Все что больше этого, а также при работе с 16- и 32-разрядными данными, решал бы в NiosII с его IDE, так удобней.
Автор: Leka Nov 4 2015, 10:30
Тогда предлагаю существенно переработать архитектуру, с целью уложиться в 200 ЛЕ + 1 М9К, получив при этом 50МIPS, и ортогональную систему команд. Как в miniByte-2 выполнить a=b&c, где a,b,c - переменные?
Автор: Serhiy_UA Nov 4 2015, 14:00
Автор: Leka Nov 4 2015, 18:18
8-разрядная аккумуляторная фон Неймановская архитектура,
2х-портовая память с 16-разрядной шиной адреса, и 8-разрядной шиной данных,
в общем адресном пространстве - команды, данные, 15 РОН, I/O порты.
РОН физически расположены в одной памяти с командами и данными.
Команда - 4 бита на код операции + 4 бита на номер регистра,
Rn(n=1..15) - 15 8-разрядных РОН, или 7 16-разрядных в командах косвенной адресации (Ra, a=1..7).
n=0 для Rn означает 8-разрядную константу после команды, например: ADD R0 -- A = A + const8.
a=0 для Ra означает 16-разрядную константу после команды, например: LDM R0 -- A = @const16.
Доступ к портам - через общую адресацию, специальных команд не предусмотрено (специальные функции можно передавать в полях адреса).
Аппаратного стека нет, 16-разрядный адрес возврата сохраняется в указанной паре РОН.
NOP X -- резерв, 1байт/1такт
ADD Rn -- A = A + Rn, 1..2б/1т
ADC Rn -- A = A + Rn + C, 1..2б/1т
SUB Rn -- A = A - Rn, 1..2б/1т
SBC Rn -- A = A - Rn - C, 1..2б/1т
AND Rn -- A = A & Rn, 1..2б/1т
XOR Rn -- A = A ^ Rn, 1..2б/1т
OR Rn -- A = A | Rn, 1..2б/1т
LD F -- A = F(A), 1б/1т
LD Rn -- A = Rn, 1..2б/1т
LDM Ra -- A = @Ra, 1..3б/2т
ST Rn -- Rn = A, 1б/1т
STM Ra -- @Ra = A, 1..3б/2т
JMP case -- if(case) PC = const16, 3б/2т
CALL Ra -- Ra = PC + 3, PC = const16, 3б/3т
RET Ra -- PC = Ra, 3б/2т
Автор: Serhiy_UA Nov 5 2015, 07:11
JMP case -- if(case) PC = const16, 3б/2т
Уточните смысловое содержание этих команд
Автор: Leka Nov 5 2015, 07:59
LD F -- A = F(A), 1б/1т
-- F - 4х-разрядный код функции одной переменной, эта мнемоника просто резервирует до 16 команд с аккумулятором, не стал конкретизировать. Например, операции сдвига, инкремента, очистки, и тп
RR A
RL A
CLR A
INC A
DEC A
...
JMP case -- if(case) PC = const16, 3б/2т
--на код условия выделено 4 бита, эта мнемоника просто резервирует до 16 команд условного перехода (включая безусловный).
Но я еще подумал, и переработал систему команд, изменив адресацию - с упором на табличный метод. Позже выложу.
Состав команд почти не изменился, но уменьшилась длина команд. Например, CALL Ra, RET Ra, стали 1-байтовыми.
Автор: Genadi Zawidowski Nov 5 2015, 08:15
чтение/запись памяти с автоинкрементом/автодекрементом нужно...
Автор: Leka Nov 5 2015, 09:30
Такое требование выльется в _дополнительный_ 16-разрядный сумматор (уменьшение разрядности до, например 12, непринципиально) - архитектура потеряет всякий смысл. Проще сразу делать 16-разрядную, выиграем сразу по всем параметрам - и по плотности кода, и по быстродействию, и по числу ЛЕ.
Надо учитывать, что в нишевых ПЛИС Альтеры отсутствует распределенная память (есть у Xilinx/Lattice), поэтому регистровые файлы на логике очень затратны по ресурсам. Клон 51 в Альтере займет больше ресурсов, чем Ниос2.
Поэтому 8-разрядный софт-процессор имеет смысл только там, где не требуется быстродействие, и инкремент 16-разрядного указателя можно делать в отдельной подпрограмме за много-много тактов.
Автор: Leka Nov 5 2015, 10:37
Вроде все укладывается в 8-разрядный код:
Ta - 64 16-разрядных указателя на данные,
Ti - 32 16-разрядных указателя на подпрограммы,
Si - 32 16-разрядных регистра возврата из подпрограмм,
Rn - 7 8-разрядных регистров АЛУ, перекрываются с 3-мя указателями Ta (a=1..3),
R0 - const8, дополнительный байт после команды.
LDM Ta -- A = @Ta, a=0..63, 1б/2т
STM Ta -- @Ta = A, a=0..63, 1б/2т
CALL Ti -- Si = PC + 1, PC = @Ti, i=0..31, 1б/3т
RET Si -- PC = Si, i=0..31, 1б/2т
JMP label -- PC = const16, 3б/2т
JC label -- if(A[8]) PC = const16, 3б/2т
JNC label -- if(!A[8]) PC = const16, 3б/2т
JZ label -- if(A==0) PC = const16, 3б/2т
JNZ label -- if(A!=0) PC = const16, 3б/2т
RR -- A = A >> 1, w/carry, 1б/1т
RL -- A = A << 1, w/carry, 1б/1т
NOP -- резерв
ADD Rn -- A = A + Rn, n=0..7, 1..2б/1т
SUB Rn -- A = A - Rn, n=0..7, 1..2б/1т
AND Rn -- A = A & Rn, n=0..7, 1..2б/1т
XOR Rn -- A = A ^ Rn, n=0..7, 1..2б/1т
OR Rn -- A = A | Rn, n=0..7, 1..2б/1т
LD Rn -- A = Rn, n=0..7, 1..2б/1т
ST Rn -- Rn = A, n=1..7, 1б/1т
Автор: Serhiy_UA Nov 5 2015, 11:07
ADD Rn -- A = A + Rn, 1..2б/1т
ADC Rn -- A = A + Rn + C, 1..2б/1т
SUB Rn -- A = A - Rn, 1..2б/1т
SBC Rn -- A = A - Rn - C, 1..2б/1т
AND Rn -- A = A & Rn, 1..2б/1т
XOR Rn -- A = A ^ Rn, 1..2б/1т
OR Rn -- A = A | Rn, 1..2б/1т
За один такт эти операции не получается сделать.
Для двухпортового ОЗУ в начале команды считывается два байта с адресами РС и РС+1, где по первому код операции, а по второму может быть константа. Если константа (младшая тетрада кода команды == 0000), то работаем с константой и все делается за один такт. А если там адрес одного из 15-ти РОН, то его еще надо считать из ОЗУ, на что минимум еще такт, если не два.
Автор: Leka Nov 5 2015, 11:37
В 3х-уровневом конвейере получится, тк запись результата идет не в память, а в регистр аккумулятора.
А латентность результата будет 2..3 такта (зависит от того, откуда брать результат - с выхода АЛУ, или с регистра аккумулятора).
В первом такте команды по одному порту считывается один байт новой команды, а по другому порту в это время идет доступ к регистру или константе предыдущей команды.
В следующем такте по другому порту считывается регистр или константа, а по первому - следующая команда.
В третьем такте результат записывается в аккумулятор, и идет чтение операндов следующей команды.
Все сходится, тк запись в память идет отдельной командой, и есть запас в тактах.
Автор: Serhiy_UA Nov 5 2015, 12:38
Это уже несколько иная федерация по вольной борьбе, что-то я уже сомневаюсь в желаемом результате в 200 ЛЕ...
Автор: Leka Nov 5 2015, 13:57
200 ЛЕ - это с запасом. 3х-уровневый конвейер естественным образом получается, без дополнительных элементов.
1 уровень - внутренние регистры одного порта памяти, 2 уровень - внутренние регистры другого порта памяти, 3 уровень - регистр аккумулятора.
Если интересно, и устраивает система команд - могу детально проработать и проверить практически.
Автор: Serhiy_UA Nov 5 2015, 18:11
Система команд, и это чувствуется, продумана и хорошо смотрится для 8-разрядника, везде видно влияние 86-архитектуры, а может, и AVR... Узкое место - это общая память, можно было бы её и разделить на RAM и ROM (что-то из гарвардского стиля) , но тогда не будет возможности модификации программы самой программой, но насколько это необходимо... Еще, память может быть очень большой, и как туда с программами на ассемблере, только на С, но это уже другой уровень усилий по разработке всей системы вместе с программной оболочкой.
С конвейерами программ еще не работал, где можно почитать о правильных методах их построения? Ясно, что конвейер надо приостанавливать на входе когда в нем длинные команды, например STM Ra, а также очищать на условиях... Хотел бы сделать такой процессор сам, потом сравнить, если получится меньше 200ЛЕ, то это будет экстра класс, т.к. мой miniByte-2 занял многовато места, хотя для мелких приложений у него есть и свои преимущества...
Автор: Leka Nov 6 2015, 09:07
Гарвардскую архитектуру придумали для скорости, использование ее для 8-битника - не имеет смысла. Если нужна скорость - лучше сразу отказаться от 8-разрядного АЛУ. Назвали "miniByte" - логично ограничить минимумом число ЛЕ и блоков памяти, и выжать максимум быстродействия при этих условиях. 8-разрядные команды будут выгодно (в идеологическом плане) отличать такой проц от AVR/PicoBlaze/LatticeMico8/etc. А потом сразу перейти на "maxiLong" ...
Автор: Leka Nov 9 2015, 10:04
Советую все-таки делать 16-разрядное АЛУ, пусть и с 8-разрядными командами (ориентир на 200 ЛЕ остается в силе). 8-разрядные АЛУ не дают никаких преимуществ в ЛЕ из-за более сложной схемы адресации.
Автор: Leka Nov 9 2015, 12:04
Кто-нибудь может помочь мне с LCC ?
Попробую разобраться, но это потребует времени... Хотелось бы сначала взглянуть на ассемблерный код, генерируемый LCC для аккумуляторной архитектуры, чтобы понять, стоит ли изучать...
Автор: Genadi Zawidowski Nov 9 2015, 12:19
Так вроде LCC изначально пример кодогенератора для x86 в 32-бит варианте содержал? Это та что надо архитектура?
Автор: Leka Nov 9 2015, 12:56
Нет, х86, это не аккумуляторная архитектура, а регистровая.
Аккумуляторная, когда операции АЛУ меняют только один аккумулятор,
и R1=R1+R2 выльется в: A=R1, A=A+R2, R1=A.
Автор: Serhiy_UA Nov 12 2015, 07:16
Аккумуляторная, когда операции АЛУ меняют только один аккумулятор,
и R1=R1+R2 выльется в: A=R1, A=A+R2, R1=A.
По поводу аккумуляторной архитектуры своих софт процессоров, пока для теоретического обсуждения и без привязки к какому-то процессору.
Предлагаю отказаться от аккумулятора и назначать в РОН-ах текущий аккумулятор. Для этого в PSW (слово состояния программы) иметь поле [] для задания номера текущего аккумулятора, а результат всех аккумуляторных операций направлять в соответствующий РОН по этому номеру. И тогда, например, R1=R1+R2 выльется в: PSW[]=номер R1, A=A+R2.
Автор: Shivers Nov 12 2015, 08:04
Простите что вклиниваюсь, в процессорной архитектуре я чайник. Но можете хотя бы в общих словах сказать, чем плох, к примеру, популярный в прошлом R3000 (архитектура MIPS-1) в качестве софт процессора?
Нам нужен софт процессор в проект, но самодельное мы не можем себе позволить, будем брать что то из классики.
Автор: Timmy Nov 12 2015, 08:25
Нам нужен софт процессор в проект, но самодельное мы не можем себе позволить, будем брать что то из классики.
Плох только тем, что места займёт больше, чем восьмибитный. А так все фирменные софтпроцессоры большой тройки - NIOS2,Microblaze,Mico32 представляют собой испорченный разными способами MIPS.
Автор: Shivers Nov 12 2015, 08:31
Спасибо, понял.
Еще вопрос. Конвейерный R3000 иногда вынужден останавливаться, если текущая команда использует результат предыдущей (еще не записанной в регфайл или память). Есть какие то простенькие, но конвейерные вариации MIPS, где процессор не останавливается?
Автор: Timmy Nov 12 2015, 09:05
Еще вопрос. Конвейерный R3000 иногда вынужден останавливаться, если текущая команда использует результат предыдущей (еще не записанной в регфайл или память). Есть какие то простенькие, но конвейерные вариации MIPS, где процессор не останавливается?
Как можно не останавливаться, если операнд команды ещё не определён? Хотя можно попробовать выполнить следующую команду, но внеочередное исполнение команд - это уже не слишком простенькая вариация. К тому же бесполезная, так как лучше расставлять команды в правильном порядке при компиляции
.
Автор: Leka Nov 12 2015, 09:30
Предлагаю отказаться от аккумулятора и назначать в РОН-ах текущий аккумулятор. Для этого в PSW (слово состояния программы) иметь поле [] для задания номера текущего аккумулятора, а результат всех аккумуляторных операций направлять в соответствующий РОН по этому номеру. И тогда, например, R1=R1+R2 выльется в: PSW[]=номер R1, A=A+R2.
Аккумулятор физически расположен вне РОН, иначе это будет регистровая архитектура. В чисто аккумуляторной архитектуре операции АЛУ меняют только аккумулятор. Те это load-store архитектура по отношению как к памяти, так и к РОН.
Автор: Leka Dec 9 2015, 11:09
1 уровень - внутренние регистры одного порта памяти, 2 уровень - внутренние регистры другого порта памяти, 3 уровень - регистр аккумулятора.
Если интересно, и устраивает система команд - могу детально проработать и проверить практически.
На Марсоходе выложил исходники 16-разрядного аккумуляторного ядра, с 1К регистровым файлом в памяти (фон Неймановская архитектура). 3х-уровневый конвейер, команды регистр-аккумулятор за 1 такт. Чуть больше 200 ЛЕ (но можно ужать, если добавить синтезаторо-зависимые оптимизации, я их убрал). В f.hex.v можно посмотреть ассемблерный код, синтезируемый припомощи LCC, сам ассемблер еще не выкладывал.
Автор: ~Elrond~ Dec 9 2015, 14:26
Leka
Глянул проц, спасибо. Но где же самое интересное? Даже не сам ассемблер как таковой, а в первую очередь адаптация LCC под свой ассемблер?
Автор: Leka Dec 9 2015, 14:45
Позже выложу (подправленный symbolic.c + *.exe), надо рефакторинг сделать. У меня цепочка symbolic ---> asm ---> hex, состоящая из нескольких исполняемых файлов. В LCC я подправил symbolic.c, остальное - оптимизатор-транслятор на Паскале. Паскалевские исходники выкладывать не буду, только если позже перепишу на Си.
Адаптации LCC под ассемблер минимальна, тк используется target=symbolic, это и скармливается ассемблеру.
Автор: Leka Dec 9 2015, 15:46
0.asm - вывод с подправленным symbolic.c, дальше этот файл обрабатывается самопальным ассемблером. У меня модель памяти сильно отличается от общепринятой (из-за 1К регистрового файла), поэтому не стал разбираться/делать свой .md файл.
В symbolic просто закомментировал все ненужное мне, добавил вывод space вместо смещений, и поменял некоторые ключевые слова.
Рефакторинг (и выкладывание .exe) не скоро буду делать.
Автор: Leka Dec 10 2015, 22:07
Кстати, "разгонные" потенциалы смотрел кто для разных ядер?
Чтобы STA мог правильно подсчитать частоты, нужно законстрейнить "ложные" пути, которые не влияют на реальное быстродействие. Это долго и нудно, для хобби проще задрать частоту, и посмотреть...
Для моего m16, например, STA дает ~110МГц на при 1200мВ/0Ц (de0-nano), попробовал 150МГц - работает...
Автор: ~Elrond~ Dec 18 2015, 12:00
Для меня наибольший интерес представляют процессоры, которым на ассемблере можно написать что-то типа
Автор: Leka Feb 19 2016, 15:05
Упрощенный USB-хост для клавиатуры - чтобы беспроводную можно было подключить без софт-процессора с Линуксом (из проводных намного проще взять PS/2). Проект для DE0-nano, ~400 ЛЕ (спасибо разработавшей USB армии даунов). На выходе модуля скан-код последней нажатой клавиши, счетчик нажатий, и карта нажатых Ctrl/Alt/Shift. 0-я версия, комменты в исходниках писать лень, проверил на паре клавиатур - работает.
Автор: Maverick Feb 19 2016, 17:42
С Вашего разрешения добавил ссылку в http://electronix.ru/forum/index.php?s=&showtopic=127898&view=findpost&p=1405743
Автор: bbb Feb 19 2016, 18:33
После того как топикстартер сделает "свои процессоры", я так понимаю, потребуется свои компиляторы и среды разработки написать под них? Или я что-то не понимаю?
Автор: iosifk Feb 19 2016, 19:25
Вообще это не проблема. Для меня достаточно было компилятора ассемблера, который в результате работы вписывал в файл процессора содержимое памяти команд... И заодно я сделал софт-симулятор. "Среда разработки" была мной же написана на Си в ВСВ6. И это все оказалось быстрее отладить, чем автомат на более чем 200 состояний...
Автор: Serhiy_UA Feb 19 2016, 20:18
iosifk,, уточните структуру, систему команд, основные принципы построения, а также итоговые параметры (тактовую частоту и занимаемые ресурсы ПЛИС) для своего софт процессора. И какой получился свой компилятор, т.е. какие он имеет возможности. По софт-симулятору тоже хотелось получить представление...
Если все вместе сложить, то получается достаточно большой объем работы был Вами сделан. Хотелось бы с ней ознакомиться, хотя бы в общих чертах...
Автор: iosifk Feb 19 2016, 20:48
Если все вместе сложить, то получается достаточно большой объем работы был Вами сделан. Хотелось бы с ней ознакомиться, хотя бы в общих чертах...
Дело было такое. Пришел работать на фирму и мне дали сделать проект в ПЛИС. Там должен был быть командо-аппарат, управляющий примерно 50 шт реле, 8-10 ЦАПов и столько же АЦП. Команды принимались по последовательной шине на 300 МГц, а весь проект работал на 50 МГц.
Там на самом деле нужен был DSP процессор, но руководитель проекта сказал, что программисты наверняка что-нибудь пожгут... А схемы он сам может проверить. Беда в том, что алгоритмы выполнения приходящих команд были довольно сложные - уставки, блокировки и пр...
Что я сделал? Я сделал связку из 2-х процессоров. Битовый процессор делал Булеву обработку флагов и входных сигналов и результаты выдавал в память и в порт. Этот битовый порт дела SPI последовательность, далее там сидела микросхема с ОК мощными выходами. И для каждого битового интервала выполнялся расчет для соотв. реле. Т.е на одно реле можно было успеть просчитать до 50 команд. И этого вполне хватало...
Процессор описан в одной из моих статей. У меня на сайте...
А с 17 разрядным процессором битовый общался через память и флаги. Команды -24 бита, шина данных - 17 бит, озу - 16 бит. Потому как 12 битовые данные из АЦП принимались 32 раза и потом усреднялись. Процессор довольно простой: аккумулятор, стек данных и стек возврата, несколько регистров... Команды соответственно подогнаны под задачу. Одной командой данные можно считать из порта в память, в регистр и в порт вывода. И при этом задать wait-state. Всего понадобилось около 1Кслов команд. Т.е. примерно раза в 3-4 меньше, чем у стандартного мк. А вместе с битовым - раз в 10 проще и быстрее...
Про ассемблер тоже писал статью. Но если кому интересно, могу по скайпу показать рабочий стол с запущенной программой...
Ассемблер -это практически визард, т.к. команды не набиваются вручную, а из меню выбирается что и куда делает команда, при этом кодируется машинный код сразу. А потом за дополнительный проход ассемблер только расставляет адреса переходов по меткам...
Да и софт-симулятор тоже дело не хитрое, когда знаешь какая команда в каком окне что должна изменить...
Автор: bbb Feb 19 2016, 22:03
Ну таких как Вы мало. Для большинства даже свою архитектуру процессора разработать и реализовать её на ПЛИС уже страшенный гемор. А если ещё и свой компилятор и свою IDE писать для своего процессора...
ИМХО, эта задача не посильна для одного разработчика.
Он будет решать эту задачу лет 10. Но так полностью "до ума" не доведет.
Автор: Timmy Feb 20 2016, 06:44
Свой компилятор и IDE писать не обязательно, обычно обходятся back-end-ом к GCC, и плагинами к Eclipse, что обеспечивает вполне вменяемый объём работы.
Автор: bbb Feb 20 2016, 15:23
А это, типо просто?
Я, к примеру, даже слов-то таких не знаю.
Русская версия Invision Power Board (http://www.invisionboard.com)
© Invision Power Services (http://www.invisionpower.com)