Всем привет!
Случилось так, что пришлось познакомиться с KiCad поближе. До этого был длительный опыт использования разных пакетов (начиная с ДОСовых OrCAD и Tango PCB, виндовый OrCAD, Protel'ы разных вариантов и заканчивая Altium'ом). Первое знакомство с KiCad'ом повергло в ступор. Собственно, посмотреть в его сторону сподвигло желание иметь нативный пакет электронной САПР в среде Linux, соответствующий духу последнего. Но столкнувшись с бедностью и даже, не побоюсь этого слова, убогостью функциональных возможностей, сильно засомневался. Изрядным плюсом было то, что пакет реально шустрый - быстро грузится, не тормозит в работе. Дальнейшее знакомство показало, что есть ещё один просто мегаплюс - текстовые документированные (хотя и не в полной мере) форматы файлов.
Забегая вперёд, хочется сказать, что этот пост (и тема) не о том, каков путь очередного осваивающего пакет пользователя, а о том, как довести (или хотя бы приблизить) пакет до более-менее юзабельного состояния (потому что то, что, как говорится, "из коробки", почти не пригодно для эффективной работы, моё мнение). Примеры из личного опыта тут только для полноты контекста, чтобы было понятнее. Ну, и возможно кому-то из начинающих осваивать KiCad пригодится аналогичный опыт.
Первое, с чем пришлось столкнуться - перенос библиотек и проектов. Сразу скажу, что тут получилась полная неудача. Делалось по маршруту Altium->PCAD->KiCad. Уж не знаю, то ли Altium горбато экспортирует, то ли плагин pcad2kicad работает не вполне корректно, но ничего путного не вышло. Помучавшись некоторое время, решил плюнуть на имеющееся проекты - пусть живут под виртуалкой в старом альтиуме. А вот c библиотеками уже так не сделать.
БиблиотекиПотыкавшись немного в редакторе библиотек компонентов электрических схем, понял, что эта штука для людей с крепкими нервами и железной волей, т.е. не для меня.

И была предпринята попытка решить вопрос иным способом - с помощью генераторов. Подход не нов (на просторах Сети их есть) - ведь убожество встроенного редактора и документированные простые текстовые форматы файлов просто-таки подталкивают на этот путь.
Стало очевидным следующее: собственно все символы компонентов можно поделить на две группы:
* символы, которые сложно (или бессмысленно) описать алгоритмически, а проще нарисовать;
* символы, которые легко описать алгоритмически.
К первой группе относятся почти все дискретные компоненты. Например, резистор или конденсатор несложно описать в виде алгоритма, который нарисует требуемое изображение, но делать это бессмысленно, т.к. такой элемент нужен один. А какой-нибудь относительно непростой по виду элемент - гетерогенный вроде реле проще всё-таки один раз нарисовать. К счастью, таких элементов совсем немного, поэтому создание такой библиотеки не занимает много времени, тем более, что часть их можно либо позаимствовать целиком, либо взять за основу.
Вторая группа - микросхемы и разъёмы. И вот тут начинают рулить генераторы. С разъёмами всё совсем просто: мы используем УГО разъёмов преимущественно в виде таблицы со столбцами "Цепь", "Конт". Создавать и хранить отдельную библиотеку для этого оказалось избыточным - куда проще сгенерировать компоненты разъёмов (какие нужны) прямо "по месту" в проекте и сунуть их в библиотеку проекта. Всё, что для этого нужно - это указать количество выводов разъёма и опционально задать его ширину (см. ниже). Т.е. и описания-то символа никакого не требуется.
С микросхемами посложнее - всё-таки тут есть некое разнообразие. При изучении вопроса обратил внимание на
этот пост, по ссылке из которого описывается искомый подход. Даже пытались это дело использовать, но кое-что не устроило, а подправить под свои хотелки оказалось для нас сложным, т.к. нет знакомства с платформой, которая там использовалась (Node.js). Да и формат описания показался несколько сложным. Но сама идея классная. В итоге был написан собственный генератор на языке Python, который из текстового описания на YAML генерирует схемные символы.
Собственно, саму
библиотеку и формат описания можно посмотреть тут. Ограничения генератора УГО микросхем:
* позволят создавать УГО только ГОСТовского вида - расположение выводов только по бокам;
* тип выводов - passive (не придумалось веских оснований делать иначе).
Там же по ссылке ниже есть пара примеров описания и результат работы генератора.
Описываемый подход позволяет помимо собственно генерации компонентов автоматизировать создание библиотек. По факту всё получилось как при сборке программы: YAML-описания - это исходные файлы, *.cmp файлы - это что-то вроде объектных файлов (продуктов компилятора), которые потом "линкуются" в главную цель - библиотеку. В приведённой библиотеке представлена структура файлов и каталогов, а также сборочный скрипт на основе утилиты
scons. Чтобы внести изменения в библиотеки, достаточно отредактировать YAML-описание компонента и запустить
scons - при этом будут сгенерированы только компоненты, описание которых изменилось, и пересобрана соответствующая библиотека.
Оказалось, что пользоваться настолько просто и легко, что такая структура библиотеки у нас живёт в каждом проекте. Т.е. есть общая для всех проектов библиотека (пути к ней прописаны в свойствах проекта по умолчанию), а есть локальная в каждом проекте - в ней "живут" разъёмы, используемые в проекте, и специфичные для проекта компоненты или версии компонентов. На версиях компонентов хочется остановиться подробнее. В процессе изучения попался
пост от уважаемого
IgorKossak:
QUOTE (IgorKossak @ Jun 2 2013, 18:42)

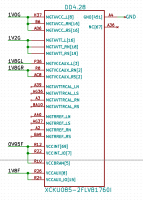
PS. Недавно озаботился новым проектом на STM32F407Z. Сделал как обычно УГО со всеми функциями для выводов и сгруппировал по портам ввода\вывода. Положил этот УГО на схему и ужаснулся тому, что он занял половину площади листа. Пришлось переделать УГО под данный конкретный проект, в котором сгруппировал выводы пофункционально (Ethernet, USB, UART, ...) и указал только нужные функции (и номера портов). Жить стало значительно легче, площадь УГО уменьшилась втрое, читабельность увеличилась. Но пострадала переносимость. Для другого проекта придётся другой УГО делать. Ну и как бы мне помогла общественная библиотека?
Цитированный текст зацепил прямо за живое - сам неоднократно сталкивался с подобным. Но перерисовывать компоненты под проект обычно было "в лом" - куча движений мышью, требующих определённой точности т.д.. А подход, основанный на текстовых описаниях компонентов и сборке библиотек, прямо-таки отлично ложится на реализацию идеи. Суть: в основной библиотеке хранятся полные версии компонентов, а в проекте, если тот или иной компонент изрядно избыточен (или даже просто "конфигурация" его внешнего вида не очень красиво выглядит на схеме), то файл с описанием этого компонента копируются в локальную библиотеку проекта, там это описание быстро правится в текстовом редакторе (лучше в "программерском") методом удаления лишнего текста и/или переноса текстовых кусков в нужные места - в общем, работа как при редактировании исходных текстов программ, потом запускается сборка, несколько секунд и получается библиотека с кастомизированным компонентом для проекта.
Проверено на практике - очень просто и удобно. Вспоминаю возню с библиотеками в пакетах, с которыми работал прежде.., не, не надо, генераторы и сборка рулят.
ИнструментарийУтилиты для реализации вышеописанного, можно взять тут. По использованию тут писать особо нечего, по ссылке приведено достаточно информации. Единственное, что хочется ещё раз отметить: опыт использования показал, что генератор компонентов-микросхем удобнее запускать не отдельно, а в составе сборки библиотеки (см. выше), т.к. при отдельном запуске придётся ещё потом руками библиотеку создавать. Хотя для разовых действий нормально.
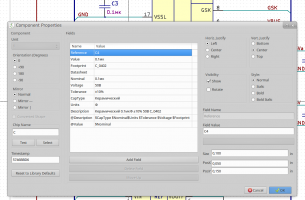
Менеджер компонентов редактора схемНу, и наконец ещё один инструмент. При начале работы в схемном редакторе был неприятно удивлён абсолютным отсутствием средств для группового редактирования. После работы в том же Altium'е это было ощущение полной беспомощности. Основное, чего не хватало - это возможности быстро и эффективно работать со свойствами компонентов. Например, задать посадочные (да, там есть специальная программа для этого - CvPcb, но это очень на любителя и кроме того это не решает проблемы в целом. За годы работы в электронных САПР выработался подход, при котором у каждого компонента создаётся определённый набор свойств, причём, свойства не валятся в кучу, а каждое задаётся отдельно. Например, резисторов и конденсаторов есть свойства, обозначающие номинал и допуск (отклонение от номинала), у конденсаторов - тип диэлектрика, и т.д. Записывать всё это одним свойством очень негибко и неудобно.
Намного удобнее задавать все параметры компонента отдельными свойствами и иметь возможность создавать композитные свойства - состоящие из значений других свойств компонента по заданному [простому] формату. Это позволяет легко и эффективно управлять и внешним видом схемы, и содержимым, передаваемым в редактор печатных плат (сформировав значение встроенного свойства Value), и подготовкой данных для генерации перечня элементов.
В общем, в результате было написано приложение для управления свойствами компонентов. Это GUI приложение, написанное с использованием фреймворка PyQt5, работает оно с файлами eeschema. Не скрою, большое влияние при разработке приложения оказал изрядный опыт работы в Altium Designer и хотя развитие этой САПР идёт "не туда" (моё мнение, но достаточно посмотреть на эволюцию этой программы за последние несколько лет, т.ч. расстаюсь без особого сожаления), некоторые инструменты и подходы там реализованы очень эффективно - имеются в виду способы выделения объектов через Find Similar Objects и Inspector. Поэтому тот, кто имел опыт работы с AD, без труда заметит общие черты.
Собственно сама программа находится в том же репозитории (запускаемый файл - scmgr.py), что и остальные инструменты, русскоязычное описание доступно на
wiki странице проекта.
Напоследок хочется отметить ещё одно классное следствие используемого в KiCad'е подхода - текстовых форматов файлов, а именно - возможность эффективно использовать системы управления версиями (мы используем git) для хранения проектов и библиотек. Помимо компактных комитов существует нативная возможность легко найти некоторые отличия между версиями. Конечно, графические изменения тут так просто будет не оследить, но редактирование компонентов сразу видно в diff'ах (хоть текстовых, хоть в двухпанельных). Для того, чтобы не испортить картину, менеджер компонентов работает с файлами *.sch "аккуратно" - не меняет их структуру. Т.е. все изменения сразу видны diff'ом.
P.S. Все инструменты достаточно "молодые", вполне могут быть "детские болезни". Поэтому в случае использования проверяйте результат. Приложение менеджера компонентов бекапит исходный файл, но всё равно лучше покамест делать резервные копии перед использованием.
«Отыщи всему начало, и ты многое поймёшь» К. Прутков



















 Nov 22 2016, 11:13
Nov 22 2016, 11:13







 А пакет-то с 1992 года начался и до сих пор функциональность на уровне paint. Я вот не догоняю, неужели самим авторам удобно так работать? Или они свойствами совсем не пользуется?..
А пакет-то с 1992 года начался и до сих пор функциональность на уровне paint. Я вот не догоняю, неужели самим авторам удобно так работать? Или они свойствами совсем не пользуется?..