| |
|
  |
 Помогите с NIOS+float Помогите с NIOS+float, длительное выполнение инструкций |
|
|
|
|
 Apr 30 2013, 03:22 Apr 30 2013, 03:22
|
Местный

Группа: Свой
Сообщений: 247
Регистрация: 4-10-10
Из: г. Екатеринбург
Пользователь №: 59 925

|
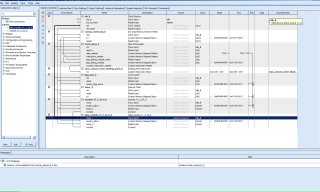
Здравствуйте. Работаю на ките Стратикса4, Квартус11.1. Недавно столкнулся с такой проблемой: 1. создал в квартусе qSys-систему:
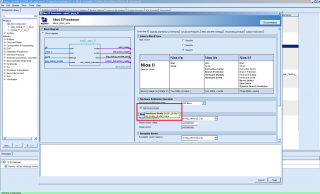
2. в настройках НИОСа выставил галочку "Hardware divide":
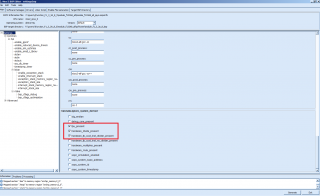
3. в настройках BSP проекта выставил три галочки:
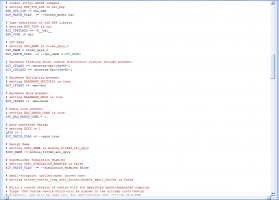
4. флаги в файле public.mk у меня генерятся следующие:
5. в коде обработчика прерывания имеется следующие строки: Код а.) temp_U = IORD(F1_BASE_ADDRESS, F1_ADDR_U);
б.) f1_array_u[f1_index_u] = temp_U;
в.) temp_F = (float)(temp_U) * f1_3_3A_8_calc_coeff_1;
г.) f1_array_u_float[f1_index_u_float] = temp_F;
д.) IOWR(DATA_MODULE_BASE, 3003, 1); 6. по СигналТапку отслеживаю сигналы на шине Авалон. Проблема в следующем: от Авалоновской пересылки в строке а.) до пересылки в строке д.) насчитывается до 300 тактов. НИОС и СигналТап тактируются частотой 50МГц. Пробовал менять флаги вместо 60-1 ставил 60-2 - стало даже хуже  Что не так с моей системой? Или все должно быть так? И можно ли в обработчик прерываний совать плавающую математику? Есть мысль вообще использовать внешний компонент "умножитель", тогда пересылки по Авалону туда/сюда займут тактов 30-40, вычисление на "умножителе" - тактов 5-6, ИТОГО выигрыш в 6-7 раз.
|
|
|
|
|
|
|
|
May 7 2013, 04:10
|
Местный
Группа: Свой
Сообщений: 247
Регистрация: 4-10-10
Из: г. Екатеринбург
Пользователь №: 59 925
|
Цитата(vadimuzzz @ Apr 30 2013, 14:12)  objdump в студию. Извиняюсь за такую длительную паузу. Вот часть из файла .objdump: Код //-------------------------------------------------------------
temp_U = IORD(F1_3_3A_8_BASE_ADDRESS, F1_3_3A_8_ADDRMAP_U_LPF_0);
413ac: 00800234 movhi r2,8
413b0: 10945404 addi r2,r2,20816
413b4: 10800037 ldwio r2,0(r2)
413b8: e0bffd15 stw r2,-12(fp)
f1_3_3A_8_array_u_lp_0[f1_3_3A_8_index_u_lpf] = temp_U;
413bc: d0a6c517 ldw r2,-25836(gp)
413c0: 00c00174 movhi r3,5
413c4: 18df4804 addi r3,r3,32032
413c8: 1085883a add r2,r2,r2
413cc: 1085883a add r2,r2,r2
413d0: 10c7883a add r3,r2,r3
413d4: e0bffd17 ldw r2,-12(fp)
413d8: 18800015 stw r2,0(r3)
temp_F = (float)(temp_U) * f1_3_3A_8_calc_coeff_0;
413dc: e13ffd17 ldw r4,-12(fp)
413e0: 00421540 call 42154 <__floatsisf>
413e4: 1007883a mov r3,r2
413e8: d0a6c717 ldw r2,-25828(gp)
413ec: 1885ff32 custom 252,r2,r3,r2
413f0: e0bffc15 stw r2,-16(fp)
f1_3_3A_8_array_u_lpf_0[f1_3_3A_8_index_u_lpf] = temp_F;
413f4: d0a6c517 ldw r2,-25836(gp)
413f8: 00c00174 movhi r3,5
413fc: 18ddb804 addi r3,r3,30432
41400: 1085883a add r2,r2,r2
41404: 1085883a add r2,r2,r2
41408: 10c7883a add r3,r2,r3
4140c: e0bffc17 ldw r2,-16(fp)
41410: 18800015 stw r2,0(r3)
IOWR(DATA_MODULE_F1_3_3A_8_0_BASE, 3003, 0);
41414: 00800234 movhi r2,8
41418: 108bbb04 addi r2,r2,12012
4141c: 10000035 stwio zero,0(r2)
//------------------------------------------------------------- для кода:
Сообщение отредактировал billidean - May 7 2013, 04:12
|
|
|
|
|
|
|
|
May 8 2013, 09:08
|
Участник
Группа: Участник
Сообщений: 40
Регистрация: 20-05-12
Из: Санкт-Петербург
Пользователь №: 71 932
|
Цитата(billidean @ Apr 30 2013, 07:22) Есть мысль вообще использовать внешний компонент "умножитель", тогда пересылки по Авалону туда/сюда
займут тактов 30-40, вычисление на "умножителе" - тактов 5-6, ИТОГО выигрыш в 6-7 раз. Так и сделал. Только я использую double, там в процессоре еще медленней получается. Данные вывожу не через авалон, а через PIO в свой модуль с системой команд (+,-,/,*,sqrt) который использует alt_fp_*
|
|
|
|
|
|
|
|
May 8 2013, 09:23
|

Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
2 billidean Код 413e0: 00421540 call 42154 <__floatsisf> похоже ваш компилер не вкурсе что проц имеет хардварный FPU Попробуйте вот этот ключ: -mcustom-fmuls Кстати, вот тут смотрели, особенно последний абзац ?
|
|
|
|
|
|
|
|
May 8 2013, 17:38
|
Местный
Группа: Свой
Сообщений: 247
Регистрация: 4-10-10
Из: г. Екатеринбург
Пользователь №: 59 925
|
Цитата(Kuzmi4 @ May 8 2013, 12:23) 2 billidean Код 413e0: 00421540 call 42154 <__floatsisf> похоже ваш компилер не вкурсе что проц имеет хардварный FPU Это мне тоже показалось подозрительным, но у меня не было времени сильно в этом копаться. Спасибо за ссылку, поковыряюсь обязательно. О результатах отпишу.
|
|
|
|
|
|
|
|
May 11 2013, 08:12
|
Местный
Группа: Свой
Сообщений: 247
Регистрация: 4-10-10
Из: г. Екатеринбург
Пользователь №: 59 925
|
Чо-то я задолбался с этими флагами. Всякие разные флаги/галочки ставил, все-равно строка Код call ххх <__floatsisf> присутствует в месте выполнения вычисления. Неужели у вас всех все нормально, т.е. без этой строки??? Если так, то не могли бы вы выслать мне минимальный проект, где все как надо, чтобы я смог проанализировать настройки системы и компиляции. З.Ы.: примерный проектик был бы ваще нормально  Сообщение отредактировал billidean - May 11 2013, 08:13
Сообщение отредактировал billidean - May 11 2013, 08:13
|
|
|
|
|
|
|
|
May 13 2013, 01:06
|

Гуру
Группа: Свой
Сообщений: 2 291
Регистрация: 21-07-05
Пользователь №: 6 988
|
выложил пример проекта для c3-starter. вот кусок objdump: CODE
#include <stdio.h>
int main()
{
20001fc: defff404 addi sp,sp,-48
2000200: dfc00b15 stw ra,44(sp)
2000204: df000a15 stw fp,40(sp)
2000208: dcc00915 stw r19,36(sp)
200020c: dc800815 stw r18,32(sp)
2000210: dc400715 stw r17,28(sp)
2000214: dc000615 stw r16,24(sp)
2000218: df000604 addi fp,sp,24
float a, b, c;
printf("Hello from Nios II from Starter Kit!\n");
200021c: 01008074 movhi r4,513
2000220: 213af004 addi r4,r4,-5184
2000224: 20008240 call 2000824 <puts>
a = 1.6;
2000228: 008ff374 movhi r2,16333
200022c: 10b33344 addi r2,r2,-13107
2000230: e0bfff15 stw r2,-4(fp)
b = 2.5;
2000234: 00900834 movhi r2,16416
2000238: e0bffe15 stw r2,-8(fp)
c = a*b;
200023c: e0ffff17 ldw r3,-4(fp)
2000240: e0bffe17 ldw r2,-8(fp)
2000244: 1885ff32 custom 252,r2,r3,r2
2000248: e0bffd15 stw r2,-12(fp)
printf("%1.3e * %1.3e = %1.3e\n", a, b, c);
custom 252 - это обращение к fpu.
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|