Здравствуйте!
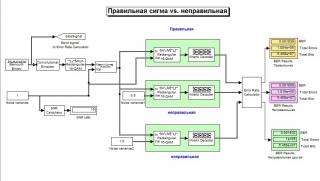
Меня интересует проблема учета уровня шума при мягких демодуляции/декодировании. Прилагаю скриншот с симулинковской моделью, на которой отображены так же результаты моделирования. Можно видеть, что принятие неверной сигмы 1.5 при формировнии решений демодулятора дает лучший результат, чем принятие истинной сигмы 1.0. Результат для меня неожиданный и непонятный. Различе небольшое, но статистически значимое, поскольку выборка большая, и моделирование проводилось неоднократно с разными начальными условиями генератора случайных чисел. Результат один.
Помимо этого видно, что учет разных сигм дает вообще не очень-то различный результат. Я ожидал другого. Можно вообще использовать приближенные LLR вместо точных, где сигма вообще не участвует. Результат опять таки будет мало отличаться. Зачем же тогда вообще нужен учет шума, если толку мало?
Модель изготовлена из матлаб-симулинковского демо "LLR vs. Hard Decision Demodulation". Все параметры модуляции, кодирования и т.д. такие же как в демке. Их можно крутить, но по сути ничего не меняется. Используются неквантованные решения демодулятора.
Расчитываю на помощь экспертов.
Спасибо!

















 Apr 14 2015, 16:02
Apr 14 2015, 16:02