| |
 Эффективный широкий pipelined mux Эффективный широкий pipelined mux, как альтеровский LPM_MUX, но для Xilinx |
|
|
|
|
 Jun 24 2018, 05:57 Jun 24 2018, 05:57
|
Частый гость

Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149

|
Здравствуйте. В процессе миграции проекта с Quartus в Vivado столкнулся с неприятной проблемой. В Quartus проекте используется мегафункция LPM_MUX – т.е. эффективный параметризируемый Mux оптимизированный под конкретное семейство FPGA с возможностью pipelining. Аналогичного IP Core у Xilinx найти не удалось (может я плохо искал?). Изначально в проекте использовал обычный Mux «общего назначения», ключевая часть которого выглядела приблизительно так (модуль целиком в аттаче bus_mux.vhd): Код -- Asynchronous Mux
MUX_P_ASYNC: process(sel, data_in)
variable idx: integer := 0;
begin
idx := conv_integer(sel);
mux_data <= data_in((idx+1)*(BUS_WIDTH)-1 downto idx*(BUS_WIDTH));
end process;] Это простая альтернатива длинным case структурам, которая обычно даёт такой же результат. Однако в данном проекте этот подход был неэффективным, т.к. мультиплексоры должны быть весьма широкие – где-то от 40 до 150 входных шин, каждая шина 32/64 бита. Таких мультиплексоров несколько сотен, и они достаточно тесно «взаимосвязаны». Всё это приводило к высокой насыщенности в кристалле (congested design). В результате в процессе раскладки Routing зачастую или просто загибался, или в результате имел низкую частоту (где-то 50 МГц, тогда как целевая частота в диапазоне 100-200 МГц). Решить проблему помогло добавление pipeline регистров. Т.е. в альтеровской мегафункции LPM_MUX можно просто параметром установить количество ступеней pipeline, и наше одно большое асинхронное дерево MUX разбивается на каскады с промежуточными регистрами между ними. Т.к. аналогичного IP Core для Xilinx найти не удалось, озадачился поиском альтернатив. Нашёл достаточно неплохой xapp522-mux-design-techniques (автор небезызвестный Ken Chapman). Там достаточно хорошо описывается, как наиболее эффективно реализовать мультиплексоры на базе основных «кирпичиков» Configurable Logic Blocks (CLBs) (для Spartan-6 FPGAs, Virtex-6 FPGAs, and 7 series FPGAs). И есть даже примеры исходников ( Reference Design Files). Проблема только в том что: 1) Прилагаемые примеры описывают максимум Mux 16:1 (т.е. 16 входов, один выход). Б ольшие муксы предлагается компоновать из более мелких. 2) Само описание MUX-а низкоуровневое, специфичное для вышеупомянутых семейств, по сути, просто конструктор элементов CLB (дерево из LUT6, MUXF7, MUXF8). На картинке пример реализации 8:1 MUX: 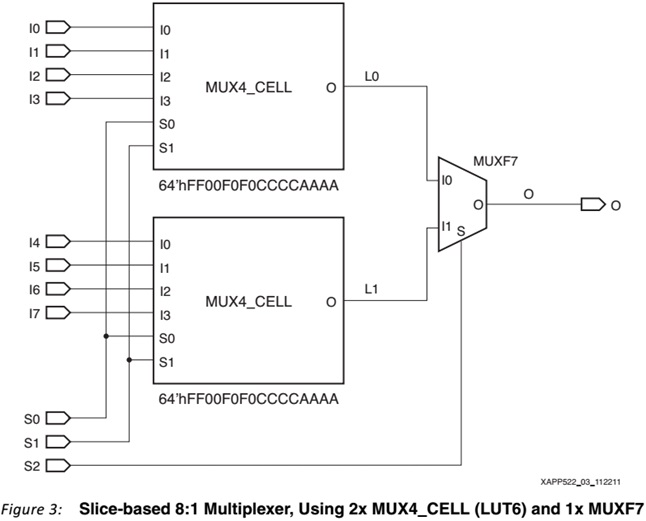 И прилагаемом в xapp-е примерах в коде прямо так и описываются все эти примитивы (особенно вставляют строки инициализации LUT6, т.е. .INIT (64'hFF00F0F0CCCCAAAA) ). Ниже пример кода для 16:1 MUX (standard_mux16.v). CODE ///////////////////////////////////////////////////////////////////////////////////////////
//
// Format of this file.
//
// The module defines the implementation of the logic using Xilinx primitives.
// These ensure predictable synthesis results and maximise the density of the
// implementation. The Unisim Library is used to define Xilinx primitives. It is also
// used during simulation.
// The source can be viewed at %XILINX%\verilog\src\unisims\
//
///////////////////////////////////////////////////////////////////////////////////////////
//
`timescale 1 ps / 1ps
module standard_mux16 (
input [15:0] data_in,
input [3:0] sel,
output data_out);
//
///////////////////////////////////////////////////////////////////////////////////////////
//
// Wires used in standard_mux16
//
///////////////////////////////////////////////////////////////////////////////////////////
//
wire [3:0] data_selection;
wire [1:0] combiner;
//
///////////////////////////////////////////////////////////////////////////////////////////
//
// Start of standard_mux16 circuit description
//
///////////////////////////////////////////////////////////////////////////////////////////
//
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection0_lut(
.I0 (data_in[0]),
.I1 (data_in[1]),
.I2 (data_in[2]),
.I3 (data_in[3]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[0]));
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection1_lut(
.I0 (data_in[4]),
.I1 (data_in[5]),
.I2 (data_in[6]),
.I3 (data_in[7]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[1]));
MUXF7 combiner0_muxf7 (
.I0 (data_selection[0]),
.I1 (data_selection[1]),
.S (sel[2]),
.O (combiner[0])) ;
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection2_lut(
.I0 (data_in[8]),
.I1 (data_in[9]),
.I2 (data_in[10]),
.I3 (data_in[11]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[2]));
LUT6 #(
.INIT (64'hFF00F0F0CCCCAAAA))
selection3_lut(
.I0 (data_in[12]),
.I1 (data_in[13]),
.I2 (data_in[14]),
.I3 (data_in[15]),
.I4 (sel[0]),
.I5 (sel[1]),
.O (data_selection[3]));
MUXF7 combiner1_muxf7 (
.I0 (data_selection[2]),
.I1 (data_selection[3]),
.S (sel[2]),
.O (combiner[1])) ;
MUXF8 combiner_muxf8 (
.I0 (combiner[0]),
.I1 (combiner[1]),
.S (sel[3]),
.O (data_out)) ;
endmodule
///////////////////////////////////////////////////////////////////////////////////////////
//
// END OF FILE standard_mux16.v
//
/////////////////////////////////////////////////////////////////////////////////////////// Понятное дело, что такой код весьма далёк от generic кода общего вида. И чтобы подогнать под большие MUX-ов произвольного размера, да ещё и с добавлением промежуточных pipeline регистров для повышения производительности, нужно приложить определённые усилия. Если идти по такому пути, то написание более универсального MUX-а видится приблизительно так. Для примера возьмём MUX 150:1. Т.к. один CLB реализует максимум 16:1, то разбиваем наши 160 входов на ceil(150/16)=10 групп (9 полных 16:1 мультиплексоров, один неполный 6:1). Они образуют первый каскад, в которую можно «вставлять» промежуточные регистры (используя регистры тех же CLB, что и задействованы в имплементации самих MUX-ов). 10 выходов первого каскада заводим на каскад 2-ого уровня (MUX 10:1), с регистром на выходе если надо. Т.е. вроде можно заморочиться и просто описать этот алгоритм в HDL. Но, честно говоря, я на 100% не уверен, что такой способ наиболее эффективный с точки зрения производительности (может есть и более оптимальные решения). Ну и естественно, в идеале хотелось бы чего-то более простого и универсального. Тем более, что мне нужно это реализовать для двух семейств FPGA (Zynq7000 и UltraScale). А в семействе UltraScale CLB имеют другую архитектуру и могут реализовывать до 32:1 MUX. Опять-таки придётся это отдельным случаем описывать. В идеале хотелось бы иметь некий код общего назначения, понятный без вникания в детали архитектуры конкретного семейства и абстрагированный от CLB. Может можно как-то аттрибутами запихать generic код в примитивы CLB (правда с промежуточными регистрами накладки получаются). Так вот, исходя из всего вышеперечисленного, хотелось бы услышать мнения/критику, как бы наиболее эффективно (с точки зрения производительности) и не сильно проблематично с точки зрения написания кода (а хотелось бы ещё и красиво) реализовать такой конфигурируемый широкий мультиплексор с pipeline регистрами.Может кому уже приходилось сталкиваться с подобным, и можете поделиться набитыми шишками? Или подкинет кто каких полезных ссылок? Буду рад помощи.
|
|
|
|
|
|
|
|
Jun 24 2018, 07:00
|
Гуру
Группа: Модераторы
Сообщений: 4 011
Регистрация: 8-09-05
Из: спб
Пользователь №: 8 369
|
Цитата(Vengin @ Jun 24 2018, 08:57)  т.к. мультиплексоры должны быть весьма широкие – где-то от 40 до 150 входных шин, каждая шина 32/64 бита. Таких мультиплексоров несколько сотен, и они достаточно тесно «взаимосвязаны».
Так вот, исходя из всего вышеперечисленного, хотелось бы услышать мнения/критику, как бы наиболее эффективно (с точки зрения производительности) и не сильно проблематично с точки зрения написания кода (а хотелось бы ещё и красиво) реализовать такой конфигурируемый широкий мультиплексор с pipeline регистрами.Может кому уже приходилось сталкиваться с подобным, и можете поделиться набитыми шишками? Или подкинет кто каких полезных ссылок? Буду рад помощи. Возьмите блоки памяти с разной разрядностью входов и выходов. Вообще, мое мнение такое, что " от 40 до 150 входных шин, каждая шина 32/64 бита" - это плохо проработанный проект. Обработка шинами по 64 бита и много логики вроде бы задумано, чтобы было быстро, но на самом деле это не так. Ну и неудивительно, что частота сползла до 50 Мгц.
--------------------
www.iosifk.narod.ru
|
|
|
|
|
|
|
|
Jun 24 2018, 07:34
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(iosifk @ Jun 24 2018, 10:00) Возьмите блоки памяти с разной разрядностью входов и выходов. В теории это наверное вариант, но на практике скорее всего будут проблемы. Как я уже писал муксов нужно много, и они очень тесно взаимосвязаны. Т.к. блочная память ресурс ограниченнный и с "жёсткой пропиской в кристалле", это будет создавать трудности. Во-первых их скорее всего может тупо не хватить (ибо в проекте блочная память уже используется, хоть и не все 100%). Но большей проблемой может быть их жестко заданная позиция колонками в кристалле. Это скорее всего сильно скажется на раскладке и ухудшит тайминги. Сейчас в проекте все эти муксы образуют "ядро", которое после раскадки почти всегда ложится в центре кристалла. В этом плане блочная память не имеет той же гибкости, что и CLB. P.S.: вроде когда-то давно в одном из xilinx xapp/user guide/white papers встречал описание того, как BRAM использовать как муксы, но сейчас с ходу не нашёл. Может кто подкинет ссылку? Цитата(iosifk @ Jun 24 2018, 10:00) Вообще, мое мнение такое, что " от 40 до 150 входных шин, каждая шина 32/64 бита" - это плохо проработанный проект. Обработка шинами по 64 бита и много логики вроде бы задумано, чтобы было быстро, но на самом деле это не так. Ну и неудивительно, что частота сползла до 50 Мгц. Ну как сказать. Да структура конечно "монструозная", но она вообщем-то вытекает из архитектуры проекта, и является требованием заказчика. Опять таки при изспользовании LPM_MUX в Arria10 удавалось получать до 200 МГц, чего на тот момент было достаточно. Вообще да, думаем о том как оптимизровать именно эту часть, но пока очевидных вещей не то чтобы фонтан.
Сообщение отредактировал Vengin - Jun 24 2018, 07:44
|
|
|
|
|
|
|
|
Jun 24 2018, 07:43
|
Гуру
Группа: Модераторы
Сообщений: 4 011
Регистрация: 8-09-05
Из: спб
Пользователь №: 8 369
|
Цитата(Vengin @ Jun 24 2018, 10:34) В теории это наверное вариант, но на практике скорее всего будут проблемы. Как я уже писал муксов нужно много, и они очень тесно взаимосвязаны. Т.к. блочная память ресурс ограниченнный и с "жёсткой пропиской в кристалле", это будет создавать трудности. Во-первых их скорее всего может тупо не хватить (ибо в проекте блочная память уже используется, хоть и не все 100%). Но большей проблемой может быть их жестко заданная позиция колонками в кристалле. Это скорее всего сильно скажется на раскладке и ухудшит тайминги. Сейчас в проекте все эти муксы образуют "ядро", которое после раскадки почти всегда ложится в центре кристалла. В этом плане блочная память не имеет той же гибкости, что и CLB.
P.S.: вроде когда-то давно в одном из xilinx xapp/user guide/white papers встречал описание того, как BRAM использовать как муксы, но сейчас с ходу не нашёл. Может кто подкинет ссылку? Разве я написал "блочная" память? Кроме блочной, есть еще распределенная. Каждая ячейка может использоваться как распределенная память 16х1 для старых серий или 32х1 для новых...
--------------------
www.iosifk.narod.ru
|
|
|
|
|
|
|
|
Jun 24 2018, 07:47
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(iosifk @ Jun 24 2018, 10:43) Разве я написал "блочная" память? Кроме блочной, есть еще распределенная. Каждая ячейка может использоваться как распределенная память 16х1 для старых серий или 32х1 для новых... Гм, так всё то что описано в первом посте как раз-таки и относится к распределённой памяти (реализуемой на CLB). Я как и писал ищу способы эффективной реализации всего этого дела.
|
|
|
|
|
|
|
|
Jun 24 2018, 08:19
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(iosifk @ Jun 24 2018, 10:00) Возьмите блоки памяти с разной разрядностью входов и выходов.
... Жуть, кошмар и ужас  Блоки памяти для описания широких mux ???. Цитата(Vengin @ Jun 24 2018, 10:47) Гм, так всё то что описано в первом посте как раз-таки и относится к распределённой памяти (реализуемой на CLB). Я как и писал ищу способы эффективной реализации всего этого дела. Все это каскадирование делается обычным for/generate. Описываете "элементраный" блок mux оптимальный для Вашего случая (по скорости или ресурсам) удобно ложащийся на целеву структуру CELL FPGA. А дальше просто комбинируете эти блоки. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 24 2018, 08:31
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(RobFPGA @ Jun 24 2018, 11:19) Все это каскадирование делается обычным for/generate. Оно-то вроде бы и так, но тут тоже нюансы. Если взять за пример вышеупомянутый мукс 150:1, и его нужно разбить не на два, а на три каскада (а может и больше). Как тогда оптимальненее "дробить" каскады? Честно говоря пока не знаю ответ на этот вопрос.
|
|
|
|
|
|
|
|
Jun 24 2018, 09:16
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 24 2018, 11:31) Оно-то вроде бы и так, но тут тоже нюансы. Если взять за пример вышеупомянутый мукс 150:1, и его нужно разбить не на два, а на три каскада (а может и больше). Как тогда оптимальненее "дробить" каскады? Честно говоря пока не знаю ответ на этот вопрос. Это просто - Можно плясать от разных печек - - Если хочется уменьшить latency то зная Вашу целевую частоту и ориентировочно задержку для элементарного блока выбираете сколько каскадов можно втиснуть между pipeline регистрами. Естественно надо учитывать и возможные задержки на роутинг. - Если нужна макс частота - то пихаем регистр в каждый каскад. - Если лень заморачиватся - то добавить на выход обычного mux цепочку регистров с атрибутом syn_pipeline и надеяться что синтезатор поймет Ваш гениальный план и сам впихнет регистры между каскадами. - Если ... Но для такой задачи как Вы описали сделать generic mux непросто - так как при широком дереве такой mux размазывает по кристаллу. Для оптимизации тут надо будет еще заниматься и подбором структуры блоков в каскадах mux, и фиксацией размещения блоков дизайна на кристалле, и добавлением "лишних" pipeline регистров чтобы протянуть нужный вход/выход mux на другую сторону кристалла и.т.д. и.т.п. И все для того что бы выжать последние пять капель MHz целевой частоты.  Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 24 2018, 10:47
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(RobFPGA @ Jun 24 2018, 12:16) Это просто - Можно плясать от разных печек -
- Если хочется уменьшить latency то зная Вашу целевую частоту и ориентировочно задержку для элементарного блока выбираете сколько каскадов можно втиснуть между pipeline регистрами. Естественно надо учитывать и возможные задержки на роутинг.
- Если нужна макс частота - то пихаем регистр в каждый каскад. Так мне вот интересен алгоритм расчёта в общем (да и в частном под контретные архитектуры) случае. Т.е. для случая мукс 150:1 на два касада вроде понятно (при лимите ширины мукса для 1 CLB = максимум 16:1) вышеупомянутая схема: 1) 1-ый каскад: 10 муксов = 9x(16:1 mux) + 1x(6:1 mux) 2) 2-ой каскад 1 мукс = 1x(10:1 mux). По какому алгоритму разбивать 150:1 для 3-ёх каскадов? Некая произвольная сужающаяся древовидная структура, у которой на каждом каскаде количесвто входов меньше предыдущего? Какие вообще оптимальные подходы каскадирования мукса для общего случая: размер мукса N:1 надо разбить на M каскадов? Цитата(RobFPGA @ Jun 24 2018, 12:16) - Если лень заморачиватся - то добавить на выход обычного mux цепочку регистров с атрибутом syn_pipeline и надеяться что синтезатор поймет Ваш гениальный план и сам впихнет регистры между каскадами. Я так понимаю syn_pipeline это атрибут внешнего для xilinx синтезатора Synplify? На данный момент интересует родной синтезатор Vivado. А так бы да, в идеале некий такой атрибут, который бы указал сколько именно каскадов pieline надо - было бы супер.
|
|
|
|
|
|
|
|
Jun 24 2018, 11:02
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(blackfin @ Jun 24 2018, 13:53) (*retiming_backward = 1 *) reg my_reg; Ух-ты, надо поэкспереминтировать. Вроде бегло посмотрел атрибуты синтезатора, но это проглядел. Спасибо за наводку.
|
|
|
|
|
|
|
|
Jun 24 2018, 11:53
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 24 2018, 13:47) Так мне вот интересен алгоритм расчёта в общем (да и в частном под контретные архитектуры) случае. Т.е. для случая мукс 150:1 на два касада вроде понятно (при лимите ширины мукса для 1 CLB = максимум 16:1) вышеупомянутая схема:
1) 1-ый каскад: 10 муксов = 9x(16:1 mux) + 1x(6:1 mux)
2) 2-ой каскад 1 мукс = 1x(10:1 mux).
По какому алгоритму разбивать 150:1 для 3-ёх каскадов? Некая произвольная сужающаяся древовидная структура, у которой на каждом каскаде количесвто входов меньше предыдущего?
Какие вообще оптимальные подходы каскадирования мукса для общего случая: размер мукса N:1 надо разбить на M каскадов? Для Xilinx есть два варианта элементарного блока mux, для 6-ти входовых LUT - обычный бинарный - 4:1 1LUT - 8:1 2 LUT + 1 fmux7 - 16:1 4 LUT + 2 fmux7 + 1fmux8 Или на базе carry OR - 3:1 1LUT - 6:1 2LUT + 2 muxcy - 9:1 3LUT + 3 muxcy - 12:1 4LUT + 4 muxcy - ... Вот из этих вариантов и можно лепить - оптимизируя либо по задержке (слоям логики) либо по структуре. 2 каскада: в первом 10 шт 16:1 -> 1 шт. либо 16:1 либо 12:1. 3 каскада: в первом 20 шт 8:1 -> 2 шт. либо 16:1 либо 12:1 -> ... А может будет выгоднее поставить в первом слое mux на базе carry OR если например у Вас уже есть ohe-hot сигналы для каждой входной шины. При этом не забывайте что надо учитывать и структуру (число слоев логики) сигнала на входах mux. Хорошо когда все входы идут с регистров - но если на входах sel/data mux есть слои логики то в общем случае сказать какая структура будет оптимальнее по задержкам сложно. Цитата(Vengin @ Jun 24 2018, 13:47) Я так понимаю syn_pipeline это атрибут внешнего для xilinx синтезатора Synplify? На данный момент интересует родной синтезатор Vivado. А так бы да, в идеале некий такой атрибут, который бы указал сколько именно каскадов pieline надо - было бы супер. "...так он за меня и есть будет!? Ага! ..." Сколько тактов pipeline это придется все же Вам решать а не синтезатору - а то голодным останетесь. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 24 2018, 13:18
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Цитата(RobFPGA @ Jun 24 2018, 14:53) Для Xilinx есть два варианта элементарного блока mux, для 6-ти входовых LUT - обычный бинарный ...
Вот из этих вариантов и можно лепить - оптимизируя либо по задержке (слоям логики) либо по структуре. Принцип-то понятен. Плохо только, что такие эксперименты занимают достаточно много времени. Цитата(RobFPGA @ Jun 24 2018, 14:53) При этом не забывайте что надо учитывать и структуру (число слоев логики) сигнала на входах mux. Хорошо когда все входы идут с регистров - но если на входах sel/data mux есть слои логики то в общем случае сказать какая структура будет оптимальнее по задержкам сложно. Т.к. эти модули в проекте критичны, то да входы/выходы были полностью посажены на регистры. И при этом т.к. у них ещё и высокий fan-in/out нужно посматривать, насколько хорошо идёт дублирование регистров? и если надо вручную атрибутами добавлять. Цитата(RobFPGA @ Jun 24 2018, 14:53) "...так он за меня и есть будет!? Ага! ..." Сколько тактов pipeline это придется все же Вам решать а не синтезатору - а то голодным останетесь. Имелось в виду, что число каскадов заранее известно (а не синтезатор решает). Т.е. сказать синтезатору, к примеру, нарисуй мне это в 3 каскада. И он уже зная особенности своей архитектуры применит богатый арсенал алгоритмических трюков (а не вручную лепить всю эту логику из низкоуровневых примитивов). И надо сказать пока эксперименты с атрибутом retiming_backward обнадёживают.
|
|
|
|
|
|
|
|
Jun 25 2018, 09:54
|
Профессионал
Группа: Свой
Сообщений: 1 214
Регистрация: 23-12-04
Пользователь №: 1 643
|
Приветствую! Цитата(Vengin @ Jun 24 2018, 16:18) Принцип-то понятен. Плохо только, что такие эксперименты занимают достаточно много времени. Да не так уж и много - теоретически самый быстрый (и самый толстый) вариант это дерево на 4:1 mux c регистром в каждом каскаде. Потом идут варианты (с небольшой разницей) 8:1 и 16:1 опять же с регистрами на выходе. Но это заметно если Вы жестко контролируете роутинг между каскадами. Все остальные варианты будут медленнее. Поэтому самый оптимальный вариант и по скорости и по ресурсам это дерево на 16:1 mux с регистром. Варианты на carry OR надо оценивать на конкретной ширине и в конкретном семействе. В зависимости от ширины они могу быть быстрее чем на OR LUT. Удачи! Rob.
|
|
|
|
|
|
|
|
Jun 25 2018, 13:12
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-02-07
Из: Беларусь, г. Минск
Пользователь №: 25 149
|
Поэкспериментировал немного с атрибутом retiming_backward – в принципе результат положительный. Действительно помогает «задвигать» регистры на промежуточные стадии. Новых (более мелких) каскадов увы не создаёт  Как вариант отделаться малой кровью должно сойти.
Сообщение отредактировал Vengin - Jun 25 2018, 13:13
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|



























