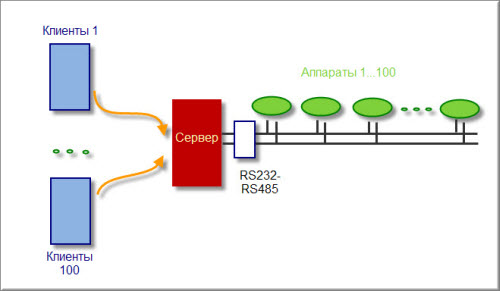
100 устройств. На каждом установлен по одному MEGA16, которые должны при поступлении команды от компьютера сбросить один из 13 пинов устройства на ноль.
Реализовал следующим образом. Компьютерную часть программы писал на Borland Builder C++. На удаленном компьютере нажимается кнопка, соответствующая команда (3 знака - номер устройства + 2 знака - номер пина, например 00101 - 1-е устройство, 1 пин) поступает на сервер. С сервера через СОМ-порт на UART МК.
Для МК писал в CodeVision AVR. При получении сигнала происходит прерывание UART, полученные данные перекодируются из кода ASCII в десятичные и сохраняются. Если номер устройства совпал с реальным номером данной платы (задается положением переключателей на потре B ), то анализируются полученные данные. Соответствующий пин порта А или С сбрасывается на 0, обратно для подтверждения отправляется полученный код, предварительно перекодировав его обратно в код ASCII из десятичных.
МК работает с кварцевой стабилизацией 14400кГц. (Реально стоит 14,31818, другого пока не нашел). Скорость UART 14400кГц.
С одним МК работает. Когда достану преобразователь RS232-RS485 - подключу в линию другие устройства.
Возникает вопрос. Когда будут подключены 100 устройств на 100МК и с Интернета на сервер будут одновременно обращаться десятки команд, будет ли все это работать?
При передаче команды вначале идет старт-бит, данные, стоп-бит. В эту процедуру никто посторонний не влезет. Так для передачи 00101 от 1-го пользователя эта процедура должна произойти 5 раз. А не получится ли так, что после передачи двух младших разрядов сюда вклинется другой пользователь передающий команду, допустим 05603?