| |
|
  |
 Квартус ограничивает разводку проекта по кристаллу Квартус ограничивает разводку проекта по кристаллу |
|
|
|
|
 Jun 4 2018, 07:33 Jun 4 2018, 07:33
|

Местный

Группа: Свой
Сообщений: 375
Регистрация: 9-10-09
Из: Свердловский регион
Пользователь №: 52 845

|
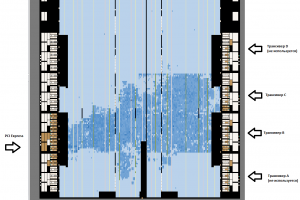
Есть проект под Аррию 10. Данные в плис поступают через два трансивера, задействованы Altera Native Phy ядра. Так же задействовано ip ядро pcie. После компиляции проекта наблюдаю в Chip Planner, что логика в основном сосредоточена в одной области, четко видны границы сверху и снизу. Я так понимаю, что это области "действия" клоков трансиверов. И та логика, что крутится на частотах из трансиверов, размещается квартусом именно в эти области.
Хотелось бы указать квартусу использовать весь кристалл для разводки логики, как это сделать? И еще вопрос, ядро Altera Transceiver Native Phy выдает клок rx_pma_clkout, как то можно узнать, какой это клок - глобальный, региональный...?
|
|
|
|
|
|
|
|
Jun 4 2018, 10:51
|
Местный
Группа: Участник
Сообщений: 221
Регистрация: 6-07-12
Пользователь №: 72 653
|
Цитата(novartis @ Jun 4 2018, 10:48)  Ну вот я хочу добавить еще модулей для работы с данными на этих частотах, квартус туда же все пихает и констрейны перестают выполняться. А если перейти в другой домен через двухклоковое фифо? Частота та же, но домен другой.
|
|
|
|
|
|
|
|
Jun 7 2018, 11:29
|
Местный
Группа: Свой
Сообщений: 375
Регистрация: 9-10-09
Из: Свердловский регион
Пользователь №: 52 845
|
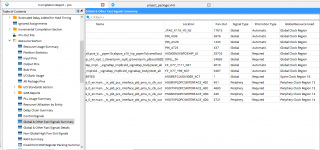
Нагуглил, где можно посмотреть список глобальных, региональных клоков: Fitter > Resource Section > Global & Other fast signals
Получается, что клок из трансивера - периферийный.
|
|
|
|
|
|
|
|
Jun 8 2018, 11:27
|
Местный
Группа: Свой
Сообщений: 375
Регистрация: 9-10-09
Из: Свердловский регион
Пользователь №: 52 845
|
Цитата(bogaev_roman @ Jun 7 2018, 17:22) Для Вас это неожиданностью стало? Посмотрите теперь каким клоком тактируется логика, которая плохо разводится. Если эта тактовая - периферийная, то можно попробовать ее сделать глобальной через assignment editor, но не переусердствуйте - глобальные дорожки ценный ресурс. Лучше добавить одну новую общую частоту, сделать ее глобальной и перетактировать логику (не зная архитектуру проекта сложно что-либо посоветовать точнее, самый главный вопрос - каким образом Вы параллельные данные используете на выходе приемника - на какой частоте). Да не то чтобы неожиданностью, раньше не задумывался над этим, мне было всё равно, как там всё разлеглось, если констрейны выполнились. Логика, которая плохо разводится, тактируется клоками из трансиверов, эти клоки - периферийные. Я пробовал сделать эти клоки глобальными, в итоге разводится равномерно, где то по середине между pcie и трансиверами, но при этом появляются отрицательные слаки в путях параллельных данных от трансиваеров. Сейчас поступил так: разделил проект на две части, одну часть тактирую клоками из трансивера, эти клоки периферийные, здесь происходит первоначальная обработка параллельных данных; другую часть тактирую клоком из pll (глобальный клок), здесь уже следующая стадия обработки параллельных данных. Переход между клоковыми доменами сделал через двухклоковое фифо. Все разводится отлично, констрейны выполнены. Но мне надо избавиться от фифо. По идеи, есть rx_clk0 из трансивера, это периферийный клок. Можно как то создать другой клок gl_clk0 на основе rx_clk0, назначить его глобальным, и сделать переход от клокового домена rx_clk0 в клоковый домен gl_clk0 просто путем задержки на один такт? Код gl_clk0 <= rx_clk0; -- rx_clk0 останется периферийным, gl_clk0 - в sdc файле назначу глобальным
process (rx_clk0)
begin
if (rising_edge(rx_clk0)) then
data <= ....; -- эти данные тактируются rx_clk0
end if;
end process;
process (gl_clk0)
begin
if (rising_edge(gl_clk0)) then
data_new <= data; -- эти данные уже тактируются глобальным клоком gl_clk0
end if;
end process; Вот такой вариант будет корректно работать? Я конечно сам попробую так сделать, но уже завтра только смогу проверить.
|
|
|
|
|
|
|
|
Jun 9 2018, 07:36
|
Профессионал
Группа: Свой
Сообщений: 1 088
Регистрация: 20-10-09
Из: Химки
Пользователь №: 53 082
|
Цитата(novartis @ Jun 8 2018, 14:27) По идеи, есть rx_clk0 из трансивера, это периферийный клок. Можно как то создать другой клок gl_clk0 на основе rx_clk0, назначить его глобальным, и сделать переход от клокового домена rx_clk0 в клоковый домен gl_clk0 просто путем задержки на один такт? С точки зрения архитектуры этот новый клок должен пройти через клокконтрол (или как там его), и задержка у него будет приличная. Возможно придется после этого добавить в ограничениях мультицикл (условно для задержки на один такт сделать анализ по setup=2, а hold=1). Но вот вопрос - если у Вас несколько трансиверов будет, для каждого создавать новый клок? Цитата Вот такой вариант будет корректно работать? Код Я vhdl не знаю, но насколько понимаю, описание некорректно.
gl_clk0 <= rx_clk0; Если это комбинаторика, то квартус по умолчанию новый клок выкинет за ненадобностью и ограничения поставить не получится, потребуется корку ставить (altclkctrl, раньше так называлась, могу ошибаться). Ну и по процессам написал выше - ограничения по умолчанию из-за большой задержки не будут выполняться.
|
|
|
|
|
|
|
|
Jun 9 2018, 11:56
|
Местный
Группа: Свой
Сообщений: 375
Регистрация: 9-10-09
Из: Свердловский регион
Пользователь №: 52 845
|
Цитата Но вот вопрос - если у Вас несколько трансиверов будет, для каждого создавать новый клок? Два трансивера, больше не предвидится. По документации на чип - имеется 32 глобальных линии клока, 16 региональных, 384 Small periphery clock, 24 Large periphery clock (думаю это как раз мои клоки из трансиверов). Так что пару глобальных линий можно и потратить. Цитата gl_clk0 <= rx_clk0; это комбинаторика, это я по быстрому сообщение писал, не подумал, так то конечно квартус выкинет. altclkctrl я ставил, там в настройках ядра указывается для какой цели задается клок - ставил for global cljck. Даже ничего в sdc прописывать не надо. На тот момент я сделал глобальным клок для всей логики, от этого констрейны для параллельных данных от трансиверов перестали выполняться. Сейчас пытаюсь собрать проект, в котором часть логики (предварительная обработка параллельных данных из трансиверов) тактируется клоками из трансиверов (периферийными клоками), а уже дальнейшая логика тактируется клоками из pll, сгенеренными от тех же кварцев, что используются для трансиверов. С переходом через двухклоковое фифо.
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|