| |
 Мягкое декодирование кода Голея (24, 12, 8) Мягкое декодирование кода Голея (24, 12, 8), Возможно ли? И какой профит может это дать? |
|
|
|
|
 Sep 5 2018, 09:47 Sep 5 2018, 09:47
|
Профессионал

Группа: Участник
Сообщений: 1 273
Регистрация: 3-03-06
Пользователь №: 14 942

|
Цитата(soldat_shveyk @ Sep 5 2018, 11:57)  И возможно ли в принципе мягкое декодирование для кода Голея? Возможно. Цитата(soldat_shveyk @ Sep 5 2018, 11:57) Что это может дать в конкретных цифрах, будет ли стоить игра свеч? Правильнее будет в матлабе набросать на стандартных функциях скрипт и посчитать выигрыш. Погуглите по словам: extended Golay code soft decoding https://ieeexplore.ieee.org/document/5450028/https://pdfs.semanticscholar.org/a562/14de7...0425fd42d50.pdfи т.п.
|
|
|
|
|
|
|
|
Sep 5 2018, 10:25
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата Правильнее будет в матлабе набросать на стандартных функциях скрипт и посчитать выигрыш. Вот именно это и хотелось бы сделать, чтобы сравнить с тем, что сейчас работает. Но для этого надо написать модель мягкого декодера. Написать не проблема, но алгоритм мне пока что не известен. За ссылки спасибо, попробую скачать. А может существуют хотя бы приблизительные оценки прироста SNR для мягкого декодирования блочного кода? Что-то типа для блочного кода 1/2 длиной 24 бита мягкое декодирование обеспечит выигрыш 2 дБ (ли 3, или 0.2). Было бы интересно.
|
|
|
|
|
|
|
|
Sep 5 2018, 11:25
|
Профессионал
Группа: Участник
Сообщений: 1 050
Регистрация: 4-04-07
Пользователь №: 26 775
|
Для кода Голея (24,12) алгоритм Чейза дает следующие характеристики
Алгоритмы 1 и 2:
Pb Eb/No, dB
1e-3 3,7
1e-4 4,7
1e-5 5,4
Алгоритм 3:
Pb Eb/No, dB
1e-3 4,3
1e-4 5,3
1e-5 6,0
Сравнивайте с вашим жестким декодером
|
|
|
|
|
|
|
|
Sep 5 2018, 12:22
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Спасибо, скачал, изучаю.
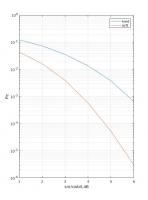
Промоделировал свой декодер в мталабе, получил следующие цифры:
SNR 6 dB, BER = 2.5e-4
SNR 5 dB, BER = 1.7e-3
SNR 4 dB, BER = 1.1e-2
SNR 3 dB, BER = 2.4e-2
SNR 2 dB, BER = 5.7e-2
SNR 1 dB, BER = 1.1e-1
SNR 0 dB, BER = 1.4e-1
По сравнению с этим, алгоритм Чейза 1 и 2 дает неплохой профит. Попробую разобраться с реализацией.
|
|
|
|
|
|
|
|
Sep 5 2018, 12:33
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(soldat_shveyk @ Sep 5 2018, 15:22) По сравнению с этим, алгоритм Чейза 1 и 2 дает неплохой профит. Попробую разобраться с реализацией. Если в вычислительной дури не сильно ограничены, то можно декодер максимального правдоподобия реализовать - потребуется вычисление 4096 сверток длиной 24 и выбор максимума. Писать там мало, а работать будет чуть лучше самого хорошего Чейза.
|
|
|
|
|
|
|
|
Sep 5 2018, 12:44
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата можно декодер максимального правдоподобия реализовать - потребуется вычисление 4096 сверток длиной 24 и выбор максимума У меня QPSK, и один код длиной 24 имеет укладывается 12 символов - комплексных отсчетов. Я попробовал сделать 4096 dot product с выбором максимума на модели в матлабе - получил такой же результат, как и в моем декодере с жестким решением. Это максимальное правдоподобие или нет? Я брал принятые 12 символов QPSK и делал скалярное произведение с каждым из 4096 кодом, который тоже был модулирован QPSK. B процессе умножения выбирал код с максимальным результатом dot.
|
|
|
|
|
|
|
|
Sep 5 2018, 12:55
|
Местный
Группа: Участник
Сообщений: 453
Регистрация: 23-07-08
Пользователь №: 39 163
|
Цитата(soldat_shveyk @ Sep 5 2018, 15:44) У меня QPSK, и один код длиной 24 имеет укладывается 12 символов - комплексных отсчетов.
Я попробовал сделать 4096 dot product с выбором максимума на модели в матлабе - получил такой же результат, как и в моем декодере с жестким решением.
Это максимальное правдоподобие или нет?
Я брал принятые 12 символов QPSK и делал скалярное произведение с каждым из 4096 кодом, который тоже был модулирован QPSK. B процессе умножения выбирал код с максимальным результатом dot. Это максимальное правдоподобие для binary symmetric channel  . А Вам на входе декодера "мягкий" демодулятор нужен, оценивающий LLR принятых бит. Но тут с Чейзом никакой разницы нет. У него на входе тоже мягкие решения должны быть.
|
|
|
|
|
|
|
|
Sep 5 2018, 13:10
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата Вам на входе декодера "мягкий" демодулятор нужен Мягкий демодулятор у меня есть. После установления синхронизации, я получаю по 12 комплексных отсчетов - символов, в которых лежит 24-битный код Голея. Сейчас я каждый символ жестко интерпретирую в два бита [00], [01]... [11] и получаю 24 бита, которые идут на декодер. Чтобы перейти на мягкое решение, я должен каждый комплексный отсчет символа интерпретировать на некое малоразрядное число, и подавать эти числа на алгоритм Чейза? Цитата Это максимальное правдоподобие для binary symmetric channel Понятно. Это только для BPSK будет работать. А как тогда для QPSK реализовать максимальное правдоподобие?
|
|
|
|
|
|
|
|
Sep 5 2018, 13:30
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата Или на мп-декодер. Если я правильно понял, то таким образом можно 12 комплексных отсчетов преобразовать в 24 вещественных для реализации максимального правдоподобия?
|
|
|
|
|
|
|
|
Sep 5 2018, 14:00
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата А можно сразу считать корреляционные метрики для комплексных Да я вроде так и делал. Но получилось так же , как и при жестком демодуляторе. А как правильно считать корреляционную метрику? Например для пакета из четырех бит данных [d0 d1 d2 d3] я получил два комплексных символа (a1+jb1) и (a2+jb2). Что дальше?
|
|
|
|
|
|
|
|
Sep 6 2018, 20:02
|
Знающий
Группа: Участник
Сообщений: 781
Регистрация: 3-08-09
Пользователь №: 51 730
|
Цитата(soldat_shveyk @ Sep 6 2018, 10:26) Хм.. Странно. Я так и делал. При совпадающих пакетах метрика будет равна 12 + j0. При не совпадающих +/-4 +/- j*4, так как кодовое расстояние равно 8.
В процессе вычисления метрик делал выбор максимума. Но на тестах по BER получил результат, аналогичный жесткому декодированию. В чем подвох?
Отдельный расчет корреляционной метрики для комплексных отсчетов при совпадении кодовых слов:
% 24-bit Data Packet
txb = randi([0 1], 1, 24);
% QPSK Modulator
tx_signal = zeros(1, 12);
for k = 1:12
dibit = [txb(2*k - 1) txb(2*k)];
tx_signal(k) = sqrt(2) / 2 * ((dibit(1) * 2 - 1) + 1j * (dibit(2) * 2 - 1));
end
% Rx packet = Tx packet + white noise
rx_signal = awgn(tx_signal, 30, 'measured');
% Calculation of the correlation metric for complex samples
metric = abs(sum(conj(rx_signal) .* tx_signal)) Не знаю. Корреляции, и выбор корреляции с максимальной вещественной частью (не модулем. это важно. Про модуль я машинально написал).
Сообщение отредактировал thermit - Sep 6 2018, 20:03
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Sep 20 2018, 06:30
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата А вы попробуйте сравнить процедуру Чейза и прямой перебор Пробовал, Чейз дает меньший BER. Да и 4096 IF-ов в коде прямого перебора тормозят процесс. Цитата Нет ни всегда. При большом количестве ошибок, евклидово расстояние до правильного слова, может стать большим чем до другого кодового слова. Спасибо.
|
|
|
|
|
|
|
|
Sep 20 2018, 08:43
|
Местный
Группа: Свой
Сообщений: 454
Регистрация: 3-07-07
Из: С-Петербург
Пользователь №: 28 859
|
Цитата Это, разумеется, не верно, т.к. прямой перебор выдает максимально правдоподобную оценку, а Чейз - ее аппроксимацию Я делал не перебор максимального правдоподобия, а перебор 4096 кодов Голея после жесткого решения. Выбирал результат по минимуму sum(bitxor()). На полноценное максимальное правдоподобие ресурсы решили не тратить, да и задержка приличная получается.
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|