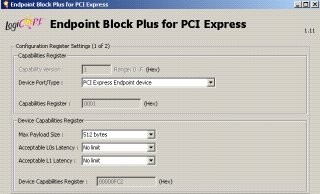
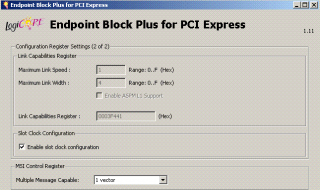
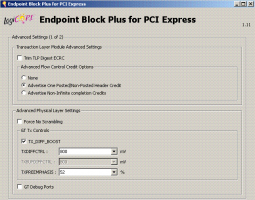
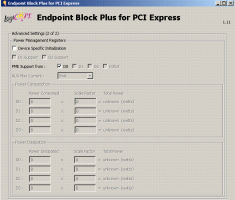
| |
|
  |
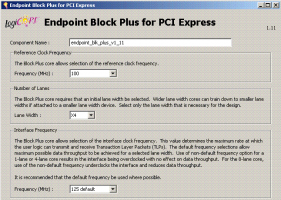
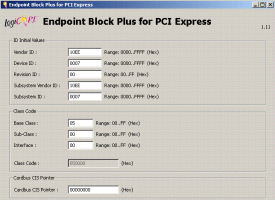
 Ядро PCI Express Block Plus в Virtex 5 Ядро PCI Express Block Plus в Virtex 5 |
|
|
|
|
 Feb 29 2008, 10:18 Feb 29 2008, 10:18
|

Знающий

Группа: Свой
Сообщений: 601
Регистрация: 1-03-05
Из: Spb
Пользователь №: 2 972

|
Цитата(dmitry-tomsk @ Feb 29 2008, 12:34)  Работали с софтовой версией. Интерфейс такой же (local link), но в V-5 не надо следить за буфером принимаемых completion на материнке А интерфейс local link писали с нуля или дополняли интерфейс из example design? + Я Вам отправил личное сообщение
--------------------
Насколько проще была бы жизнь, если бы она была в исходниках
|
|
|
|
|
|
|
|
Feb 29 2008, 10:49
|
Знающий
Группа: Свой
Сообщений: 601
Регистрация: 1-03-05
Из: Spb
Пользователь №: 2 972
|
Цитата(dmitry-tomsk @ Feb 29 2008, 13:37) Искать надо через pci-express block plus. Там на вкладке есть ref design. Если туда пойти, попросит зарегистрироваться, а потом даст ссылку на файлы от nwlogic (ядро платное, но сколько стоит не знаю). Вы сами создавали интерфейс к Local link + User Interface? C вами можно напрямую пообщаться (ICQ,Skype,..)? Разбирался в Example design и заметил, что если они принимают пакет с TD=1, то и выходной пакет они передают тот же самый бит TD (что и в принятом). Но, если в принятом ЕДЗ ECRC можно игнорировать, то в Complition его надо генерить. А в коде TX нет генерации ECRC(TLP digest) - в этом случает TLP будет Malformed ?!
--------------------
Насколько проще была бы жизнь, если бы она была в исходниках
|
|
|
|
|
|
|
|
Feb 29 2008, 11:26
|
Знающий
Группа: Свой
Сообщений: 601
Регистрация: 1-03-05
Из: Spb
Пользователь №: 2 972
|
Цитата(dmitry-tomsk @ Feb 29 2008, 13:59) TLP digest я вообще не использовал (ставил галку trim). В пакете и так есть контрольная сумма, достатчно для большинства приложений. Уточняли?! При этом ядро исправляет этот бит, если он присутсвует в исходящем пакете. К вопросу о качестве екзампл дизайна. Пока мне нужен простейший target с двумя небольшими однонаправленными FIFO. Может у Вас есть что-то, что поможет их связать с ядром от ксайлинкса(через Local Link). Или подскажите подводные камни Local Link интерфейса от Xilinx/ У меня пока единственный вариант доделовать example design под мои задачи. А шишек при первом знакомстве с PCI express от Xilinx на их плате ML555 думаю будет и так не мало... В nwlogic отправил запрос (с их сайта лишь). Посмотрим что пришлют. Хотя на их сайте нет явных упоминаний про интерфейс к ядру от Xilinx (у них оно свое есть). Но для моей текущей задаче их платное ядро будет излишеством  Цитата ICQ не пользую У Вас есть что-то на работе, чтобы можно было пообщаться в реалтайме?
--------------------
Насколько проще была бы жизнь, если бы она была в исходниках
|
|
|
|
|
|
|
|
Feb 29 2008, 11:42
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(NiOS @ Feb 29 2008, 14:26) Уточняли?! При этом ядро исправляет этот бит, если он присутсвует в исходящем пакете. К вопросу о качестве екзампл дизайна. Пока мне нужен простейший target с двумя небольшими однонаправленными FIFO. Может у Вас есть что-то, что поможет их связать с ядром от ксайлинкса(через Local Link). Или подскажите подводные камни Local Link интерфейса от Xilinx/ У меня пока единственный вариант доделовать example design под мои задачи. А шишек при первом знакомстве с PCI express от Xilinx на их плате ML555 думаю будет и так не мало... В nwlogic отправил запрос (с их сайта лишь). Посмотрим что пришлют. Хотя на их сайте нет явных упоминаний про интерфейс к ядру от Xilinx (у них оно свое есть). Но для моей текущей задаче их платное ядро будет излишеством У Вас есть что-то на работе, чтобы можно было пообщаться в реалтайме? Для target всё довольно просто, example design подойдёт. Работает всё нормально (правда медленно, большая задержка в pcie, хотя если увеличить число линий должно быть быстрее). К фифо подключить тоже легко, надо выкинуть ramb и поставить селектор адреса для фифо и регистра флагов.
|
|
|
|
|
|
|
|
Feb 29 2008, 12:24
|
Знающий
Группа: Свой
Сообщений: 601
Регистрация: 1-03-05
Из: Spb
Пользователь №: 2 972
|
Цитата(dmitry-tomsk @ Feb 29 2008, 14:42) Для target всё довольно просто, example design подойдёт. Работает всё нормально (правда медленно, большая задержка в pcie, хотя если увеличить число линий должно быть быстрее). К фифо подключить тоже легко, надо выкинуть ramb и поставить селектор адреса для фифо и регистра флагов. Сколько Mb/s по Вашему можно получить на х8, если оставить из примера обработку по 1 DW payload в обе стороны? Вам удобней здесь общаться или можно также через e-mail? Просто, думаю, всплывут некоторые тонкости ядра от Xilinx. Вдруг Вы их уже проходили.
--------------------
Насколько проще была бы жизнь, если бы она была в исходниках
|
|
|
|
|
|
|
|
Jun 24 2009, 12:55
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Цитата(NiOS @ Feb 29 2008, 15:24) Сколько Mb/s по Вашему можно получить на х8, если оставить из примера обработку по 1 DW payload в обе стороны?
Вам удобней здесь общаться или можно также через e-mail? Просто, думаю, всплывут некоторые тонкости ядра от Xilinx. Вдруг Вы их уже проходили. большой скорости с нагрузкой TLP в 1 DW не добиться нужно переписывать под 1024 DW ... чем сейчас и занимаюсь.... буду рад пообщаться с теми кто занимается данным вопросом
|
|
|
|
|
|
|
|
Jun 25 2009, 08:47
|
Участник
Группа: Свой
Сообщений: 29
Регистрация: 6-09-05
Пользователь №: 8 276
|
Как вы моделировали ядро PCI Express Endpoint Block Plus?
У меня первый же простейший тест типа: записать-прочитать по последовательным
адресам не проходит. Completion пакет чтения на 7-ой итерации почему-то теряется.
Чем он отличается от 6-ти предыдущих ума не приложу.
Кто-нибудь с подобным сталкивался?
|
|
|
|
|
|
|
|
Jun 25 2009, 11:28
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Цитата(Loki5000 @ Jun 25 2009, 12:47) Как вы моделировали ядро PCI Express Endpoint Block Plus?
У меня первый же простейший тест типа: записать-прочитать по последовательным
адресам не проходит. Completion пакет чтения на 7-ой итерации почему-то теряется.
Чем он отличается от 6-ти предыдущих ума не приложу.
Кто-нибудь с подобным сталкивался? если вы выбрали sample_smoke_test0 то в первых 9 транзакциях будет производиться симуляция чтения пространства конфигурации.. затем запись в память с 32 и 64 битной адресацией 1DW. и запрос на чтение с ожиданием соответствующего Completion.
Сообщение отредактировал demon_rt - Jun 25 2009, 12:12
|
|
|
|
|
|
|
|
Jun 26 2009, 10:15
|
Участник
Группа: Свой
Сообщений: 29
Регистрация: 6-09-05
Пользователь №: 8 276
|
Нет, я использую свой тест. Текст теста в аттаче. (user_test0.txt) Результат моделирования тоже. (sim_log.txt) Дошел уже до разбора символов на Link Layer. Пытаюсь понять, пакет завершения не выдается тестируемым Endpoint-ом или drop-ается принимающим его Downstreам_Port-ом? Изменения теста такие как: - обращения по одному и тому же адресу, - чтение без записи - добавление пауз и т.п. ситуацию не меняют. 
|
|
|
|
|
|
|
|
Jun 26 2009, 15:27
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Цитата(Loki5000 @ Jun 26 2009, 14:15) Нет, я использую свой тест. Текст теста в аттаче. (user_test0.txt) Результат моделирования тоже. (sim_log.txt) Дошел уже до разбора символов на Link Layer. Пытаюсь понять, пакет завершения не выдается тестируемым Endpoint-ом или drop-ается принимающим его Downstreам_Port-ом? Изменения теста такие как: - обращения по одному и тому же адресу, - чтение без записи - добавление пауз и т.п. ситуацию не меняют. всавил ваш тест в tests.vhd но ни каких транзакций кроме чтения пространства конфигурации не наблюдал... может вы еще внесли какие то изменения в проект симуляции. потому как стандартные тесты у меня работают нормально.
|
|
|
|
|
|
|
|
Jun 29 2009, 11:14
|
Участник
Группа: Свой
Сообщений: 29
Регистрация: 6-09-05
Пользователь №: 8 276
|
помимо этого, только выбор теста в 'pci_exp_usrapp_tx.vhd' строка 115: test_selector => String'("pio_writeReadBack_test0") заменить соответственно на: test_selector => String'("user_test0") все, больше ничего... 
|
|
|
|
|
|
|
|
Jun 29 2009, 16:11
|
Участник
Группа: Свой
Сообщений: 29
Регистрация: 6-09-05
Пользователь №: 8 276
|
Проблема решилась! Я случайно использовал модель Endpoint Block версии 1.9 совместно с тестовым окружением от версии 1.11 Xilinx Core Generator не смотря на предупреждение о возможной перезаписи сгенерированных ранее файлов создал вдобавок к 'pcie_endpoint_plus.vhd' новый файл 'pcie_endpoint_v1_11.vhd'. А я упустил это из виду. Новая версия отличается несколькими портами. Возможно, это как-то повлияло, или причина кроется где-то в недрах Endpoint Block. Теперь все работает! 
|
|
|
|
|
|
|
|
 Aug 13 2009, 09:42 Aug 13 2009, 09:42
|

Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
Здравствуйте. Чтоб не открывать новую тему решил запостить сдесь (и так уже много чего полезного написано). Вопрос есть один, касательно симуляции. Доработал я pio_tests.v, а в частности pio_writeReadBack_test0. Файлик прицепил  mem64_tb_part.txt
mem64_tb_part.txt ( 7 килобайт )
Кол-во скачиваний: 251В 2-х словах: сделал 2 записи по 10 и 6 dword-ов , и после этого сделал 2 чтения по 12 (с середины записанного региона) и 16 (весь записанный регион) dword-ов. Запись прошла на ура, и 1-е чтение тоже, а вот 2-е загнулось , хотя я в модельсиме видел как моя логика честно отгрузила положенное  . Решил упростить задачу сделал чтение 4 (с середины записанного региона) dword-ов и 16 (весь записанные регион) dword-ов - первое чтение проходит, а на 2-е имеем ту же ситуацию - моя логика честно отгрузила положенное, а dsport загнулся на ожидании данных. Вот и интересует - чем 4 dword-а от 16 отличаются (оба больше 1 конечно; кстати и с 8-ю dword-ами тоже проходит чтение) ? Отчего такая разница ??  И есть есчё интересное поведение trn_tdst_rdy_n - при комбиинации для 2-х заходов чтения 12/16 корка выставляет этот сигнал для 1-го чтения, а для второго не ставит, и что самое интересное первое чтение проходит, а второе нет ? С чего бы это - там же буфер на 2 килобайта, я больше чем 16*2 dword-ов в своих комбинациях не вычитываю  ??
|
|
|
|
|
|
|
|
Aug 14 2009, 04:27
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Kuzmi4 @ Aug 13 2009, 12:42) Здравствуйте. Чтоб не открывать новую тему решил запостить сдесь (и так уже много чего полезного написано). Вопрос есть один, касательно симуляции. Доработал я pio_tests.v, а в частности pio_writeReadBack_test0. Файлик прицепил
mem64_tb_part.txt ( 7 килобайт )
Кол-во скачиваний: 251В 2-х словах: сделал 2 записи по 10 и 6 dword-ов , и после этого сделал 2 чтения по 12 (с середины записанного региона) и 16 (весь записанный регион) dword-ов. Запись прошла на ура, и 1-е чтение тоже, а вот 2-е загнулось , хотя я в модельсиме видел как моя логика честно отгрузила положенное . Решил упростить задачу сделал чтение 4 (с середины записанного региона) dword-ов и 16 (весь записанные регион) dword-ов - первое чтение проходит, а на 2-е имеем ту же ситуацию - моя логика честно отгрузила положенное, а dsport загнулся на ожидании данных. Вот и интересует - чем 4 dword-а от 16 отличаются (оба больше 1 конечно; кстати и с 8-ю dword-ами тоже проходит чтение) ? Отчего такая разница ?? И есть есчё интересное поведение trn_tdst_rdy_n - при комбиинации для 2-х заходов чтения 12/16 корка выставляет этот сигнал для 1-го чтения, а для второго не ставит, и что самое интересное первое чтение проходит, а второе нет ? С чего бы это - там же буфер на 2 килобайта, я больше чем 16*2 dword-ов в своих комбинациях не вычитываю ?? Я не спец по верилогу, но так понимаю Вы читаете и пишете память slave устройства пакетами по несколько DW? А как собираетесь сделать это на плате? В PCIE нет системного ПДП контроллера, надо делать мастер. И вообще, как показывает практика, моделирование PCIE - пустая затея, потом придётся половину контроллера переделывать из-за неверных предположений. Гораздо проще и надёжнее чипскопом на плате смотреть.
|
|
|
|
|
|
|
|
Aug 15 2009, 06:02
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Kuzmi4 @ Aug 14 2009, 19:34) 2 dmitry-tomsk - прочитал.. интересно.. Только не пойму где там написано про то что дял 32-х битных процессоров будем читать/писать по 4 байта , а для 64-х битных по 8 байт? В главе "Transaction Layer Packet Maximum Payload and Maximum Read Request Size" расказывается про 128 байт, и в сносках к ней на асусовскую мать тоже говорится про 128.
Вот разве что удручает так это разбиение пакетов:
То есть на сколько я понял юзеровские пакеты по 4кб ко мне дойдут только в виде 128 байтных реквестов на write (то есть это железяка их сама побъёт без ючастия юзера) а чтение 4kb с моей стороны будет выглядеть как кучка комплетишнов по 128 байт каждый, которые эта же железяка соберёт и отправит юзеру наверх. Ваше user application должна состоят из двух частей - мастера и слэйва. Слэйв принимает memory read/write request длина которых в принципе не может быть больше 1 или 2 DW, так как в процессорах нет команд чтения/записи больше 1 слова из памяти, а системный ДМА контроллер (ISA, EISA) не доступен для PCIE. Мастер может в писать в память хоста пакеты memory write request с MAX_PAYLOAD_SIZE байтами в нагрузку (ограничение со стороны материнок 128 байт, со стороны ядра 512 байт). Мастер может читать из памяти хоста пакеты через memory read request с размером запроса не более MAX_READ_SIZE байт. Хост вправе вернуть не один пакет MAX_READ_SIZE, а несколько, например, 1 и 127 байт, зависит от root complex. Посмотрите ещё xapp1052
|
|
|
|
|
|
|
|
 Aug 18 2009, 07:23 Aug 18 2009, 07:23
|
Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
2 dmitry-tomsk - спасибо за просвещение  В принципе нашёл почти всё прочто вы писали, только не ясно откуда вы взяли что Цитата в процессорах нет команд чтения/записи больше 1 слова из памяти, а системный ДМА контроллер (ISA, EISA) не доступен для PCIE. В том же xapp1052 нашёл такое: Цитата The Power Edge 1900 contains the Intel E5000P chipset with maximum write payloads of 128 bytes and completion payloads of 64 bytes. Это предложение вроде бы как раз указывает на то, что в write request-е для данного чипсета может быть 128 байт а не 4 или 8... Или я что то не так понял ?
|
|
|
|
|
|
|
|
Aug 18 2009, 08:37
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Kuzmi4 @ Aug 18 2009, 11:23) 2 dmitry-tomsk - спасибо за просвещение В принципе нашёл почти всё прочто вы писали, только не ясно откуда вы взяли что В том же xapp1052 нашёл такое: Это предложение вроде бы как раз указывает на то, что в write request-е для данного чипсета может быть 128 байт а не 4 или 8... Или я что то не так понял ? Нашёл я в реководстве по написанию драйверов (драйверы самому приходится писать и это иногда полезно  Вот Ваш мастер как раз и может генерить write request c 128 байтами в нагрузке, read request c 64 байтами. А вот на материнке такого мастера нет.
|
|
|
|
|
|
|
|
Aug 18 2009, 12:30
|
Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
2 dmitry-tomsk - благодарствую. Тут кстати подключил вчера чипскоп - и что меня удивило - непрерывные посылки broadcast from RootComplex vendor defined message - данные каждый раз разные, а ID-шки и адреса одниковые. Что на openSUSE 32бит что на WinXPSP2 32бит... Не подскажете что оси постоянно пытаются в мой дизайн записать? И есчё что интересно - дизайн с xapp1022 - нормально мапился в openSUSE как временный файл (или файл подкачки, не вспомню я счас эти тонкости), и можно было писать читать по 4 байта в реквесте, а мой дизайн мапится - мапится, только read реквестов я не вижу, а с write - только те что broadcast from RootComplex vendor defined message  . Тут вот странно, ведь реквесты заходить должны всегда ?  То есть понятно что свой драйвер будет, этот финт ушами был для проверки что мне заходит с компа, но почему такая существенна разница на такой простой реализации?? И потому тут есть вопрос такой, скорее уточнение, потому как вроде ясно, но хотелось утчонить (из-за вышеупомянутого, что вводит в некоторое недоумение) у работавшего с этим чЮдом - на сколько я понял мне приходят запросы с юзер уровня - и на них я отвечаю, а всякие специфические запросы можно игнорить - в смысле не отвечать на них (в спецификации по крайней мере написано что можно) - то есть не чревато ли это чем то?
|
|
|
|
|
|
|
|
Aug 18 2009, 15:51
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Kuzmi4 @ Aug 18 2009, 16:30) 2 dmitry-tomsk - благодарствую. Тут кстати подключил вчера чипскоп - и что меня удивило - непрерывные посылки broadcast from RootComplex vendor defined message - данные каждый раз разные, а ID-шки и адреса одниковые. Что на openSUSE 32бит что на WinXPSP2 32бит... Не подскажете что оси постоянно пытаются в мой дизайн записать? И есчё что интересно - дизайн с xapp1022 - нормально мапился в openSUSE как временный файл (или файл подкачки, не вспомню я счас эти тонкости), и можно было писать читать по 4 байта в реквесте, а мой дизайн мапится - мапится, только read реквестов я не вижу, а с write - только те что broadcast from RootComplex vendor defined message . Тут вот странно, ведь реквесты заходить должны всегда ? То есть понятно что свой драйвер будет, этот финт ушами был для проверки что мне заходит с компа, но почему такая существенна разница на такой простой реализации?? И потому тут есть вопрос такой, скорее уточнение, потому как вроде ясно, но хотелось утчонить (из-за вышеупомянутого, что вводит в некоторое недоумение) у работавшего с этим чЮдом - на сколько я понял мне приходят запросы с юзер уровня - и на них я отвечаю, а всякие специфические запросы можно игнорить - в смысле не отвечать на них (в спецификации по крайней мере написано что можно) - то есть не чревато ли это чем то? Ну про openSUSE это к специалистам по ней, а про специфичные запросы - на них точно можно не отвечать Насчёт проверки на проектах xapp тоже ничего сказать не могу, когда я делал свой контроллер их ещё не было.
|
|
|
|
|
|
|
|
Sep 5 2009, 06:10
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Цитата(Kuzmi4 @ Sep 4 2009, 13:44) Возникли такие же трудности - времянка вообсче плохая - и как раз ошибок много в этом самом эндпойнте. ИСЕ вообсче отказывается собирать дизайн на этапе мапа - не подскажете как вы выходили из положения ?? При чём на этапе синтеза мин период 5.9 нс , а на этапе мапа - слак у клока в ендпойнте 10 НС(8нс период) !! Да такая же проблема... не могу уложиться в тайменги. Причем на х1 и частоте 65 МГц все работает отлично. при переходе на х4 и частоту 125МГц тайменги укладываются, ядро временно работает (гонит счетчик), но через некоторое время "отваливается" по тому что на такой частоте нужно отслеживать Transaction Receiver Credits Available (как это делать я еще не разобрался). А на х4 и частоте 250МГц начинают появляться тайминг error.
|
|
|
|
|
|
|
|
Sep 6 2009, 06:04
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Transaction Receiver Credits Available это проверка на наличие свободного места в буферах приемника ядра. Является одним из методов борьбы с переполнением в режимах х4 и х8. Смотрите ug167. На счет тайменгов, удалось оптимизировать проект путем замены фи-фо на двухпортовую память и некоторой коррекции кода. Но столкнулся с такой проблемой. В режиме х4 передачи данных на хост (пишу в оперативную память в режиме DMA), Endpoint прогоняет порядка 70Гб со скоростью 800 Мб/с и предача останавливается...
|
|
|
|
|
|
|
|
Sep 8 2009, 18:54
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Цитата(Kuzmi4 @ Sep 8 2009, 11:46) 2 demon_rt - кстати, на счёт остановки - а как это выглядит ? Вы это уже побороли ?? Нет еще не поборол. Обрыв транзакций происходит в различные моменты времени, что не похоже на переполнение буферов. После обрыва в конфигурационном пространстве порта PCI Express на хосте в Secondary Status Register появляется Signaled Target Abort и Fatal Error. Причем линк ап не падает в момент обрыва транзакции, но дальнейшая передача невозможна. Причину возникновения данных ошибок я еще не понял.
|
|
|
|
|
|
|
|
Sep 29 2009, 16:17
|
Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
Здравствуйте. А никто не пробовал работать с 64-битными барами ?  Вопрос собственно почему возник - имеем 64-битный бар, он выбран естественно для того чтобы иметь 64-битный адрес на входе, а не делать всякие ре-органайзеры когда нужно много куда то писать. Смотрим в спецификацию для PCI Express версии 1.1 на страницу 62, видим Figure 2-13: Request Header Format for 64-bit Addressing of Memory , и радуемся. Вот пока требуемый объём был не больше 4 ГБ - мать стартовала, но при адресации к этому 64-битному бару хедер был странный - не по спецификации - Fmt == 01/11 (тут вроде норма) а вот адрес - на 32 бита, а потом сразу данные (это при записи, при чтении - там указание от rrem - что валидные только верхние 32 - как раз где 32-бита адреса).. Захотелось поставить больше 4ГБ - одни матери тупо повисают при старте (c 945/965 чипсет), та что поновей - постоянно перезагружается (мать GA-P55). На последней матери стоит 860 Core i7 с него напрямую выходит PCI-Express на разъём - на него и поцепили нашу ПП с Virtex5, чтоб избавить себя от всяких чипсетов/мостов по пути к процессору. ОС - Linux (Suse 11.1) PCI Express Endpoint корка - 1.11 (ISE 11.2). Это я где то проглядел/недочитал или как это понимать вообсче вот такое поведение ?? И есчё - не подскажете кто пробовал - на виндовсе при запросе памяти меньше 4ГБ - входной хедер соответствует тому, что в спецификации для 64-битной адресации ?
|
|
|
|
|
|
|
|
Nov 19 2009, 16:36
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Kuzmi4 @ Nov 19 2009, 12:45) Обновлю информацию, может кому будет полезно в будущем: 1) при запросе памяти меньше 4ГБ - входной хедер по размеру соответствует 32-х битному(там 32б верхние адреса отпадают, написано в спецификации). 2) Тестирование на запрос памяти > 4ГБ проводилось так же на других десктоповых машинах - всё то же. В конце концов добрался до HP ML370 - на нём не висло и не ресетилось, биос просто забил при конфигурации на эту область и пошёл себе дальше... Вот такая поддержка спецификации в обсчем и целом Вот интересно, а зачем понадобилось делать такой объём памяти в BAR? Это регистровый файл в Вашем устройстве такой большой? Даже для ДМА контроллера пакеты с поддержкой 64 битного адреса нужны ли вообще для ПЛИС? Длина пакета на слово больше, хотя бы теоретически это уменшить пропускную способность. Выделить кусок непрерывной памяти больше нескольких мегабайт под windows уже будет проблемой, а для SGDMA нужен такой огромный объём памяти под дескрипторы, что ПЛИС придётся хранить их во внешней памяти. Для x1 два буфера по 1 МБайт ping-pong давали практически теоретический максимум, не пробовал на x4 или x8, может там и мало будет, но никак не ГБ.
|
|
|
|
|
|
|
|
Dec 3 2009, 12:44
|
Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
И снова здравствуйте. В принципе, думал что знаю PCI Express Block Plus, но тут получилась интересная ситуация. Хотелось бы получить консультацию профи, потому как мне не ясно на данный момент отчего там чЮдеса творятся. Есть 2 прожекта - оба минимальные доработки примера от Xilinx. В первом архиве используется прямая адресация + обращение к барам - изменения по сравнению с примером существенные. Во втором архиве - заменён только контроллер памяти из примера - тестовая прога(всмысле драйвер) пишет всегда 1DW, так что rd/wr_byte_enable не нужны, совсем примтивный арбитраж. Вроде бы на мой взгляд оба проекта практически идентичны, однако при работе с драйвером под SUSE 11.1 в первой реализации по 0x80 адресу в BAR0 появляются нули (они там островками - видна даже периодичность), а вот во второй реализации никаких нулей где бы то ни было в BAR0/1 не наблюдается. На симуляции - оба примера присылают одинаковые данные для адреса 0x80 и выше в BAR0  pcie_ep_original_adopter_arch01.rar
pcie_ep_original_adopter_arch01.rar ( 585.57 килобайт )
Кол-во скачиваний: 178
pcie_ep_original_adopter_arch02.rar ( 582.53 килобайт )
Кол-во скачиваний: 173
|
|
|
|
|
|
|
|
Dec 3 2009, 13:31
|

Частый гость
Группа: Свой
Сообщений: 191
Регистрация: 10-01-05
Из: San Francisco Bay, Silicon Valley
Пользователь №: 1 869
|
Цитата(Kuzmi4 @ Nov 19 2009, 14:45) Обновлю информацию, может кому будет полезно в будущем:
1) при запросе памяти меньше 4ГБ - входной хедер по размеру соответствует 32-х битному(там 32б верхние адреса отпадают, написано в спецификации). Насколько я понял спецификацию, при обращении к любому адресату, находящемуся в младших 4 Гбайт адресного пространства, инициатор обязан всегда использовать 32-битную адресацию, т.е. 3 DW header. Т.е. независимо от того, как на End Point был объявлен BAR0/1 (2 по 32 или 1 по 64 бит), если система посадила End Point в младшие 4 Гбайт, то от PCIe свитча будут всегда приходить запросы, имеющие 3 DW header (32 бит адресация). P.S. Тоже самое относится и к встроенному мастеру на End Point: если адрес получателя "сидит" в младших 4 Гбайт, то инициатор мастера обязан использовать 3 DW header, если выше 4 Гбайт - 4 DW. Оно и понятно примерно, зачем так сделано: откуда мастеру End Point'а знать, как был заявлен другой End Point, к которому ему надо обратиться. А так всё просто - шлём короткий или длинный header и плюём на то, что другому End Point'у хотелось - 32 или 64 бит адресного пространства.
Сообщение отредактировал serebr - Dec 3 2009, 13:38
|
|
|
|
|
|
|
|
Dec 11 2009, 12:48
|
Частый гость
Группа: Свой
Сообщений: 191
Регистрация: 10-01-05
Из: San Francisco Bay, Silicon Valley
Пользователь №: 1 869
|
Цитата(Kuzmi4 @ Dec 11 2009, 18:41) Новости с полей: после того как в отправке Completition Header-е поле Lower Address стал наполнять байтовым адресом вырезанным из получаемого (нижние 2 бита меняю согласно спецификации как и раньше) и изменил процедуру отправки прерывания (стало MSI, как по UG) - всё заработало без сбоев. В обсчем как обычно - нужно внимательно читать ДШ и не пропускать мелочи Поздравляю! Мне всё это ещё предстоит пройти, но своим путём, т.к. делать надо не на Xilinx'е, а на Lattic'e.
|
|
|
|
|
|
|
|
Jan 6 2010, 09:05
|
Гуру
Группа: Свой
Сообщений: 3 304
Регистрация: 13-02-07
Из: 55°55′5″ 37°52′16″
Пользователь №: 25 329
|
И снова здравствуйте Имею неприятную специфику работы этого самого PCI Express Block Plus: Дата-трансферы без прерываний бегают нормально Отсылка прерывания по контрольным точкам (то есть редко) тоже работала нормально с трансферами. А вот если сделать эти дата-трансферы пачками, упорядочить (запись перед трансфером управляющей информации трансфера-запись/чтение,адрес,длинна), прерывания после обработки трансферов(то есть довольно часто) - тогда возникает этот самый неприятный момент - прога на PC виснет. Проверялось как на Р55 платформе так и (да простят меня Одмины ) на ML370. И была замечена интересная специфика - на серверной платформе зависания начинались после гораздо меньшего числа трансферов чем на Р55 (грубо говоря если на Р55 работало полдня без вопросов, то на серверной после ~100-300 трансферов висли) В результате исследования со стороны корки выяснилось что пред-момент зависона выглядит так: получаю трансфер обрабатываю, отсылаю прерывание,получаю подтверждение от корки, что запрос прерывания от меня воспринят и дальше - тишина, входящих запросов от PC нет.. На стороне PC удалось увидеть пару раз (логи ядра в линухе), что виснем как раз на ожидании прерывания... PCIE анализера нет, чтоб посмотреть ушёл ли пакет в мать или нет, но реально видно что корка работает и рапортует в нормальном режиме и это беспокоит. Никто не сталкивался с таким чЮдесным функционированием ?? Как вариант - может я там галочки какие пропустил ? Скриншоты конфигурирования и автомат отсылки прерывания прилагаю (на PC разрешено 1 прерывание, отсылаю 1 прерывание). Потому что нахожусь в каком то тупике - неясно где поломалось...
interrupt_block.v ( 2.98 килобайт )
Кол-во скачиваний: 339
|
|
|
|
|
|
|
|
Jan 11 2010, 11:17
|
Частый гость
Группа: Свой
Сообщений: 191
Регистрация: 10-01-05
Из: San Francisco Bay, Silicon Valley
Пользователь №: 1 869
|
Цитата(jojo @ Jan 11 2010, 17:12) Всё слежу за новостями борьбы с PCI Express, так всё меньше хочется делать свою обёртку.
Вы не пробовали ядро PLDA для Virtex-5? Там и тестбенч есть, и обёртка вокруг ядра Endpoint Block Plus.
Ядро можно получить после короткой переписки по e-mail. Затем уговорить ядро работать стандартным образом. Вот бы уговорить работать ядро PCIe от PLDA для Lattice! Само ядро имеется, а с таблеткой для него - труба.
|
|
|
|
|
|
|
|
Aug 22 2010, 19:15
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
У меня такая проблема: устройство на базе Endpoint Block Plus
v1.9 не на всех PC работает в режиме х8. Перепробовал кучу машин с различными мостами. В некоторых материнках, устройство сразу работает на х8, в других при первом включении на х1, а после перезагрузки(помогает кнопка ресет), переходит на х8, в третьих только на х1, и никакая перезагрузка не помогает, не смотря на то, что на материнке написано х8 и в биосе тоже все нормально. Неужели Endpoint Block Plus такой привередливый к типу чипсетов?????
|
|
|
|
|
|
|
|
Aug 4 2011, 16:57
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(demon_rt @ Aug 22 2010, 23:15) У меня такая проблема: устройство на базе Endpoint Block Plus
v1.9 не на всех PC работает в режиме х8. Перепробовал кучу машин с различными мостами. В некоторых материнках, устройство сразу работает на х8, в других при первом включении на х1, а после перезагрузки(помогает кнопка ресет), переходит на х8, в третьих только на х1, и никакая перезагрузка не помогает, не смотря на то, что на материнке написано х8 и в биосе тоже все нормально. Неужели Endpoint Block Plus такой привередливый к типу чипсетов????? Тема привередливости к чипсетам меня тоже интересует. demon_rt,что Вам удалось за год на эту тему выяснить?
|
|
|
|
|
|
|
|
Aug 8 2011, 10:37
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 4 2011, 19:57) Тема привередливости к чипсетам меня тоже интересует.
demon_rt,что Вам удалось за год на эту тему выяснить? PCI Express платы на основе Xilinx Virtex 5 выпускаем давно. С такими проблемами не сталкивался. Проверьте: 1. Скорость загрузки ПЛИС - нужна параллельная загрузка. 2. Выводы PCI Express подключены через конденсаторы. Проверьте их, может там попались разные конденсаторы.
|
|
|
|
|
|
|
|
Aug 8 2011, 10:49
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 8 2011, 14:37) PCI Express платы на основе Xilinx Virtex 5 выпускаем давно. Какие реальные скорости получаете для передач "Память ПК->Буферная память на PCIe х 1 плате" ( System Memory Read ) в зависимости от чипсета матери?
|
|
|
|
|
|
|
|
Aug 8 2011, 13:13
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 8 2011, 13:49) Какие реальные скорости получаете для передач "Память ПК->Буферная память на PCIe х 1 плате" ( System Memory Read ) в зависимости от чипсета матери? Для реализации x1 у нас используется PEX8311. Насколько я помню, на вывод удалось достичь 150 МБайт/с. Для x8 и чипсет P55 - 1050 МБайт/с. Если найду переходник, то измерю скорость Virtex 5 в режиме x1
|
|
|
|
|
|
|
|
Aug 8 2011, 13:46
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 8 2011, 17:13) Для реализации x1 у нас используется PEX8311. Насколько я помню, на вывод удалось достичь 150 МБайт/с. Этот показатель как-то зависил от матери? Цитата(dsmv @ Aug 8 2011, 17:13) Для x8 и чипсет P55 - 1050 МБайт/с. Если найду переходник, то измерю скорость Virtex 5 в режиме x1 Заранее благодарю.
|
|
|
|
|
|
|
|
Aug 8 2011, 15:58
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 8 2011, 19:42) Вот результаты измерения.
Компьютер - Intel I7 2.8 ГГц, системная плата GIGABYTE GA-P55-UD6
Модуль AMBPEX5 установлен через переходник x1
Вывод данных ( из компьютера в устройство )
1. системная память (непрерывная) 128 МБайт - 201 Мбайт/с
2. пользовательская память (разрывная) 128 Мбайт - 201 Мбайт/с
Модуль AMBPEX1 - используется контроллер PEX8311
Вывод данных ( из компьютера в устройство )
1. системная память (непрерывная) 128 МБайт - 185 Мбайт/с
2. пользовательская память (разрывная) 128 Мбайт - 120 Мбайт/с
Для режима x1 скорости от компьютера практически не зависят. Хотя я это давно не проверял. Огромное Вам спасибо. Скажите, при выводе данных из компьютера в устройство в чём разница между понятиями "системная память (непрерывная)" и "пользовательская память (разрывная)"? И почему на AMBPEX5 через переходник x1 скорости вывода в обоих этих случаях равны, а на PEX8311 сильно отличаются?
|
|
|
|
|
|
|
|
Aug 8 2011, 16:08
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 8 2011, 18:58) Огромное Вам спасибо.
Скажите, при выводе данных из компьютера в устройство в чём разница между понятиями "системная память (непрерывная)" и "пользовательская память (разрывная)"?
И почему на AMBPEX5 через переходник x1 скорости вывода в обоих этих случаях равны, а на PEX8311 сильно отличаются? Системная память выделяется в ядре Windows и является непрерывной по физическим адресам. Пользовательская память выделяется на 3 кольце и является фрагментированной. На физическом уровне состоит из страниц по 4 кбайта. В моём контроллере дескрипторы объедены в блок дескрипторов. Посмотрите мои доклады: http://ds-dev.ru/projects/ds-dma/wiki/%D0%...%86%D0%B8%D0%B8Там же есть исходный код нового контроллера.
|
|
|
|
|
|
|
|
Aug 8 2011, 17:45
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 8 2011, 19:42) Вот результаты измерения. Компьютер - Intel I7 2.8 ГГц, системная плата GIGABYTE GA-P55-UD6 Модуль AMBPEX5 установлен через переходник x1 Вывод данных ( из компьютера в устройство ) 1. системная память (непрерывная) 128 МБайт - 201 Мбайт/с 2. пользовательская память (разрывная) 128 Мбайт - 201 Мбайт/с В моём контроллере дескрипторы объедены в блок дескрипторов. Посмотрите мои доклады: http://ds-dev.ru/projects/ds-dma/wiki/%D0%...%86%D0%B8%D0%B8Там же есть исходный код нового контроллера. А если Ваш код контроллера, который в Virtex 5 давал 201 Мбайт/с разместить в Спартан-6 используя его аппаратное ядро PCIe x 1, то можно ли ожидать получение таких же скоростей 200 Мбайт/с ? Или в Virtex 5 есть нечто, чего нет в Спартан-6 из-за чего такие скорости на Спартане-6 не получить?
|
|
|
|
|
|
|
|
Aug 9 2011, 04:22
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 8 2011, 20:45) А если Ваш код контроллера, который в Virtex 5 давал 201 Мбайт/с разместить в Спартан-6 используя его аппаратное ядро PCIe x 1, то можно ли ожидать получение таких же скоростей 200 Мбайт/с ?
Или в Virtex 5 есть нечто, чего нет в Спартан-6 из-за чего такие скорости на Спартане-6 не получить? Я собираюсь сделать реализацию контрроллера для Virtex 6 и Spartan 6. Но в будущем. Я думаю, что для Spartan 6 скорость 200 Мбайт/с получится. Если хотите, подключайтесь к проекту. Сделаем реализацию для Spartan 6.
|
|
|
|
|
|
|
|
Aug 9 2011, 04:53
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 9 2011, 07:29) dsmv, а пробовали ли Вы Ваше ядро на PCIe GEN2?
Удалось ли получить увеличенные скорости по сравнению с GEN1?
Кстати, есть ли сейчас матери со слотами PCIe x1 GEN2?
Будет ли встроенное Spartan 6 ядро PCIe x1 работать на PCIe x1 GEN2 с увеличенной скоростью? В моём компьютере PCI Express 2.0; Но Virtex 5 (и Spartan6) поддерживают только PCIE v1.1; Так что увеличения скорости при установке в слот PCIE v2.0 нет. Virtex 6 поддерживает PCIE v2.0 и я собираюсь сделать такую реализацию.
|
|
|
|
|
|
|
|
Aug 9 2011, 05:09
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 9 2011, 08:53) В моём компьютере PCI Express 2.0 И даже PCIe x 1 слоты PCI Express 2.0? Если так, то назовите пожалуйста эту мать. Цитата(dsmv @ Aug 9 2011, 08:53) Virtex 6 поддерживает PCIE v2.0 и я собираюсь сделать такую реализацию. Наверное на Artix-7 подешевле будет.
|
|
|
|
|
|
|
|
Aug 9 2011, 06:17
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 9 2011, 08:09) И даже PCIe x 1 слоты PCI Express 2.0? Если так, то назовите пожалуйста эту мать.
Наверное на Artix-7 подешевле будет. Я уже называл: GA-P55-UD6 http://www.gigabyte.ru/products/mb/specs/ga-p55-ud6_10.htmlPCIe x1 - это PCI Express v1.1; Но он расположен крайне неудобно и я его практически не использую. Использую два слота: PCIE_x8_1 - PCI Express v2.0 x8 PCIE_x4_1 - PCI Express v1.1 x4 Для реализации x1 они ведут себя одинаково. Кстати, есть большая разница для реализации PCI Express x4; Модуль AMBPEX8 установленный в PCIE_x8_1 показывает скорость приёма 510 Мбайт/с, а при установке в PCIE_x4_1 - 710 Мбайт/с. А вот для выдачи данных - наоборот, скорость в PCIE_x8_1 больше чем в PCIE_x4_1; ( 560 и 410 Мбайт/с )
|
|
|
|
|
|
|
|
Aug 9 2011, 07:42
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 9 2011, 10:17) Я уже называл: GA-P55-UD6 http://www.gigabyte.ru/products/mb/specs/ga-p55-ud6_10.htmlА вот для выдачи данных - наоборот, скорость в PCIE_x8_1 больше чем в PCIE_x4_1; ( 560 и 410 Мбайт/с ) Не возникают ли провалы в скорости если начинают работать другие устройства, использующие DMA Bus Master, например если выводимые в плату данные будут поступать из гигабитной сети или с HDD? Не пробовали ли чипсет x58, возможно там результаты будут повыше? Как-то расстраивает 410 Мбайт/с на вывод на PCIE_x4_1...
|
|
|
|
|
|
|
|
Aug 9 2011, 09:39
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 9 2011, 10:42) Не возникают ли провалы в скорости если начинают работать другие устройства, использующие DMA Bus Master, например если выводимые в плату данные будут поступать из гигабитной сети или с HDD?
Не пробовали ли чипсет x58, возможно там результаты будут повыше?
Как-то расстраивает 410 Мбайт/с на вывод на PCIE_x4_1... Серьёзных исследований не проводили. На первый взгляд - скорость не падает. Пропускная способность памяти и chipseta на порядок выше, что PCI Express x8. Ну так можно установить в слот x8 и получить 500 Мбайт/с. А если сделать реализацию x8 - то все 1080 Мбайт/с.
|
|
|
|
|
|
|
|
Aug 9 2011, 09:48
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 9 2011, 13:39) Кстати, есть большая разница для реализации PCI Express x4;
А вот для выдачи данных - наоборот, скорость в PCIE_x8_1 больше чем в PCIE_x4_1; ( 560 и 410 Мбайт/с )
Ну так можно установить в слот x8 и получить 500 Мбайт/с. А если сделать реализацию x8 - то все 1080 Мбайт/с. Поясните пожалуйста, правильно ли я Вас понял, что реализация PCI Express x4 (т.е Virtex 5 работающий как бы в режиме PCI Express x4 ) в слоте PCIE_x4_1 на вывод даст скорость 4100 Мбайт/с, а в слоте PCIE_x8_1 на вывод даст скорость 560 Мбайт/с?
|
|
|
|
|
|
|
|
Aug 9 2011, 10:01
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(FLTI @ Aug 9 2011, 12:48) Поясните пожалуйста, правильно ли я Вас понял, что реализация PCI Express x4 (т.е Virtex 5 работающий как бы в режиме PCI Express x4 ) в слоте PCIE_x4_1 на вывод даст скорость 4100 Мбайт/с, а в слоте PCIE_x8_1 на вывод даст скорость 560 Мбайт/с? Нет. Неправильно. Есть модуль AMBPEX8. Там реализован PCI Express x4 на ПЛИС Virtex 4 FX20. В слоте PCIE x4 скорость выдачи около 400 Мбайт/с. В слоте PCIE x8 скорость выдачи 560 Мбайт/с. Я думаю, что реализация на Spartan 6 PCI Express x4 даст похожие цифры.
|
|
|
|
|
|
|
|
Aug 9 2011, 10:49
|
Местный
Группа: Свой
Сообщений: 399
Регистрация: 8-06-05
Пользователь №: 5 832
|
Цитата(dsmv @ Aug 9 2011, 13:39) Серьёзных исследований не проводили. На первый взгляд - скорость не падает. Стоило бы проверить. Где-то на этом форуме видел тему, что кто-то жаловался на падение скорости подобного рода контроллера, как потом выяснилось, из-за большой активности других устройств на PCIe .
|
|
|
|
|
|
|
|
Aug 28 2011, 16:27
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Цитата(dsmv @ Aug 8 2011, 19:42) Модуль AMBPEX5 в режиме x8
Вывод данных ( из компьютера в устройство )
1. системная память (непрерывная) 128 МБайт - 1080 Мбайт/с
2. пользовательская память (разрывная) 128 Мбайт - 1080 Мбайт/с Подскажите пожалуйста в каком режиме осуществляется вывод данных из компьютера в устройство. Я наблюдаю такую картину: В режиме вывода данных из устройства на компьютер все отлично MPS = 128Байт, скорость 1200 Мбайт/с. При записи из компьютера в устройство 128Байт данных, на шине RX PCI Express Block Plus приходят 16 TLP длинной 1DW со сдвигом данных.
|
|
|
|
|
|
|
|
Aug 30 2011, 10:34
|
Местный
Группа: Свой
Сообщений: 451
Регистрация: 6-09-05
Из: Москва
Пользователь №: 8 284
|
Цитата(demon_rt @ Aug 28 2011, 19:27) При записи из компьютера в устройство 128Байт данных, на шине RX PCI Express Block Plus приходят 16 TLP длинной 1DW со сдвигом данных. Это какая-то странная ситуация. Пришлите отправляемый запрос, надо на него посмотреть.
|
|
|
|
|
|
|
|
Oct 27 2011, 18:25
|
Группа: Участник
Сообщений: 13
Регистрация: 20-01-09
Пользователь №: 43 665
|
Такой вопрос, кто нить сталкивался с изохронным режимом (приложение А спецификации) работы PCI Express.
|
|
|
|
|
|
|
|
Dec 15 2011, 11:54
|

Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
Читая форум, прихожу к мысли что с проблемами на этапе установки соединения столкнулся один я.
Есть две платы PCI/104 express. Одна из них как раз с virtex-5 и example design из PCI Express Block Plus корки. Возможности потестить ее с разными хостами нет. PCIe устройство не детектируется, после долгих тыканий набрел на гид по отладке сего ядра на сайте xilinx, благодаря которому смог установить следующую заковырку:
На этапе установке связи хост шлёт плате TS1-пакет с link number, который хочет ей присвоить (точнее начинает слать непрерывно такие пакеты). Через некоторое время плата начинает отсылать такие же пакеты обратно, подтверждая что приняла номер. После этого хост добавляет в отсылаемые пакеты желаемый lane number. И тут (если быть точным за пару пакетов до прихода lane number) плата выставляет флаг rx_elec_idle (насколько я понимаю сообщая о том, что приемная линия перешла в режим простоя) и в наглую не шлет ответный пакет хосту. Через некоторое время процесс инициализации сбрасывается, в сумме он повторяется несколько раз, потом хост естественно оставляет попытки.
Предполагая количество людей, которые уже использовали тот же самый пример и ядро, смутно понимаю что дело не в нем. Грешить на root complex тоже очень не хочется, начальство имеет планы на использование конкретно его в будущих разработках. Буду рад любым подсказкам и наводкам
|
|
|
|
|
|
|
|
Dec 15 2011, 12:59
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Jack_of_Shadows @ Dec 15 2011, 15:54) Читая форум, прихожу к мысли что с проблемами на этапе установки соединения столкнулся один я.
Есть две платы PCI/104 express. Одна из них как раз с virtex-5 и example design из PCI Express Block Plus корки. Возможности потестить ее с разными хостами нет. PCIe устройство не детектируется, после долгих тыканий набрел на гид по отладке сего ядра на сайте xilinx, благодаря которому смог установить следующую заковырку:
На этапе установке связи хост шлёт плате TS1-пакет с link number, который хочет ей присвоить (точнее начинает слать непрерывно такие пакеты). Через некоторое время плата начинает отсылать такие же пакеты обратно, подтверждая что приняла номер. После этого хост добавляет в отсылаемые пакеты желаемый lane number. И тут (если быть точным за пару пакетов до прихода lane number) плата выставляет флаг rx_elec_idle (насколько я понимаю сообщая о том, что приемная линия перешла в режим простоя) и в наглую не шлет ответный пакет хосту. Через некоторое время процесс инициализации сбрасывается, в сумме он повторяется несколько раз, потом хост естественно оставляет попытки.
Предполагая количество людей, которые уже использовали тот же самый пример и ядро, смутно понимаю что дело не в нем. Грешить на root complex тоже очень не хочется, начальство имеет планы на использование конкретно его в будущих разработках. Буду рад любым подсказкам и наводкам А какая плата? Там есть switch? Или конфигурация stack up/down фиксирована? Как сброс сделан? Могу дать свою прошивку и тестовую прогу под windows в обмен на ucf файл. Мы сейчас свою плату PCI104 express делаем, вот не хотелось бы тоже наколоться.
|
|
|
|
|
|
|
|
Dec 16 2011, 07:54
|
Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
Процессорная плата - MSM945 от Digital-Logic (ныне Kontron). Плата с плисом - SMT101 от Sundance (они кстати предоставляют тестовую прошивку под PCIe, но она так же не работает как и пример от корки, что лишний раз намекает что проблемы либо в связи, либо в root complex). (как я заметил вы ищете примеры разводки, но, к несчастью, от Sundance мне удалось получить только схему) Процессорная плата рассчитана только на нахождение на верхушке мезонина, поэтому CPU_DIR фиксированно заведен на единицу. Сброс с разъема PCIe заведен на дополнительную плисину Spartan-3, которая конфигурирует Virtex. Выведя сигналы сброса на светодиоды, я всегда вижу как вначале почему-то мигает trn_reset, затем вместе пару раз trn_reset и sys_reset. Все это в течении пары секунд, пока пытается установиться соединение. От прошивки бы и проги не отказался  Хотя в данный момент они вряд ли помогут с проблемами на нижнем уровне. Кстати, если вы имеете отношение к Томскому "Интенсис" и их SGDMA, то я качал демонстрационную версию модуля, однако у нас плисы разные (у меня XC5VFX30T), и я так и не смог адаптировать ucf под свою плату (сыпались какие-то ошибки с GTP/GTX трансиверами).
|
|
|
|
|
|
|
|
Dec 16 2011, 11:44
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Jack_of_Shadows @ Dec 16 2011, 11:54) Процессорная плата - MSM945 от Digital-Logic (ныне Kontron). Плата с плисом - SMT101 от Sundance (они кстати предоставляют тестовую прошивку под PCIe, но она так же не работает как и пример от корки, что лишний раз намекает что проблемы либо в связи, либо в root complex). (как я заметил вы ищете примеры разводки, но, к несчастью, от Sundance мне удалось получить только схему) Процессорная плата рассчитана только на нахождение на верхушке мезонина, поэтому CPU_DIR фиксированно заведен на единицу. Сброс с разъема PCIe заведен на дополнительную плисину Spartan-3, которая конфигурирует Virtex. Выведя сигналы сброса на светодиоды, я всегда вижу как вначале почему-то мигает trn_reset, затем вместе пару раз trn_reset и sys_reset. Все это в течении пары секунд, пока пытается установиться соединение. От прошивки бы и проги не отказался Хотя в данный момент они вряд ли помогут с проблемами на нижнем уровне. Кстати, если вы имеете отношение к Томскому "Интенсис" и их SGDMA, то я качал демонстрационную версию модуля, однако у нас плисы разные (у меня XC5VFX30T), и я так и не смог адаптировать ucf под свою плату (сыпались какие-то ошибки с GTP/GTX трансиверами). Спасибо! Мне кажется дело со сбросом. На отладочных китах сброс не используется, вместо него кнопка для ручного сброса. Попробуйте его вообще отключить в прошивке. Адаптировать sgdma помогу, самому интересно, шлите ucf файл.
|
|
|
|
|
|
|
|
Dec 16 2011, 12:20
|
Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
собственно вот:
Код ###############################################################################
# Define Device, Package And Speed Grade
###############################################################################
CONFIG PART = xc5vfx30t-ff665-1;
###############################################################################
# User Time Names / User Time Groups / Time Specs
###############################################################################
# CONFIG STEPPING = "ES";
###############################################################################
# User Physical Constraints
###############################################################################
###############################################################################
# Pinout and Related I/O Constraints
###############################################################################
#
# SYS reset (input) signal. The sys_reset_n signal should be
# obtained from the PCI Express interface if possible. For
# slot based form factors, a system reset signal is usually
# present on the connector. For cable based form factors, a
# system reset signal may not be available. In this case, the
# system reset signal must be generated locally by some form of
# supervisory circuit. You may change the IOSTANDARD and LOC
# to suit your requirements and VCCO voltage banking rules.
#
NET "sys_reset_n" LOC = "H9" | IOSTANDARD = LVCMOS33 | PULLUP | NODELAY;
#
# SYS clock 250 MHz (input) signal. The sys_clk_p and sys_clk_n
# signals are the PCI Express reference clock. Virtex-5 GTX
# Transceiver architecture requires the use of a dedicated clock
# resources (FPGA input pins) associated with each GTX Transceiver Tile.
# To use these pins an IBUFDS primitive (refclk_ibuf) is
# instantiated in user's design.
# Please refer to the Virtex-5 GTX Transceiver User Guide
# (UG198) for guidelines regarding clock resource selection.
#
NET "sys_clk_p" LOC = "T4";
NET "sys_clk_n" LOC = "T3";
INST "refclk_ibuf" DIFF_TERM = "TRUE";
#
# Transceiver instance placement. This constraint selects the
# transceivers to be used, which also dictates the pinout for the
# transmit and receive differential pairs. Please refer to the
# Virtex-5 GTX Transceiver User Guide (UG198) for more
# information.
#
# PCIe Lanes 0
INST "ep/pcie_ep0/pcie_blk/SIO/.pcie_gt_wrapper_i/GTD[0].GT_i" LOC = GTX_DUAL_X0Y1;
#
# PCI Express Block placement. This constraint selects the PCI Express
# Block to be used.
#
INST "ep/pcie_ep0/pcie_blk/pcie_ep" LOC = PCIE_X0Y0;
###############################################################################
# Physical Constraints
###############################################################################
#
# BlockRAM placement
#
INST "ep/pcie_ep0/pcie_blk/pcie_mim_wrapper_i/bram_retry/generate_sdp.ram_sdp_inst" LOC = RAMB36_X4Y4;
INST "ep/pcie_ep0/pcie_blk/pcie_mim_wrapper_i/bram_tl_tx/generate_tdp2[1].ram_tdp2_inst" LOC = RAMB36_X4Y3;
INST "ep/pcie_ep0/pcie_blk/pcie_mim_wrapper_i/bram_tl_rx/generate_tdp2[1].ram_tdp2_inst" LOC = RAMB36_X4Y2;
INST "ep/pcie_ep0/pcie_blk/pcie_mim_wrapper_i/bram_tl_tx/generate_tdp2[0].ram_tdp2_inst" LOC = RAMB36_X4Y1;
INST "ep/pcie_ep0/pcie_blk/pcie_mim_wrapper_i/bram_tl_rx/generate_tdp2[0].ram_tdp2_inst" LOC = RAMB36_X4Y0;
###############################################################################
# Timing Constraints
###############################################################################
#
# Ignore timing on asynchronous signals.
#
NET "sys_reset_n" TIG;
#
# Timing requirements and related constraints.
#
NET "sys_clk_c" PERIOD = 10ns;
NET "ep/pcie_ep0/pcie_blk/SIO/.pcie_gt_wrapper_i/gt_refclk_out" TNM_NET = "MGTCLK";
TIMESPEC "TS_MGTCLK" = PERIOD "MGTCLK" 100.00 MHz HIGH 50 %;
# LEDs
NET "led1" LOC = "E10" | IOSTANDARD = LVTTL;
NET "led2" LOC = "F10" | IOSTANDARD = LVTTL;
NET "led3" LOC = "F20" | IOSTANDARD = LVTTL;
NET "led4" LOC = "G21" | IOSTANDARD = LVTTL;
###############################################################################
# End
###############################################################################
Сообщение отредактировал Jack_of_Shadows - Dec 16 2011, 12:24
|
|
|
|
|
|
|
|
Dec 18 2011, 20:22
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(dmitry-tomsk @ Dec 16 2011, 21:47) Как грузится плис - со флэши? В PC104 нет сигнала присутствия в слоте, может загрузка прошивки запаздывает? Странный ucf, в коментариях тактовая 250 МГц, а в таймингах 100 МГц. Прикрепил прошивку для 100 МГц
Прикрепленные файлы
ST101.rar ( 228.11 килобайт )
Кол-во скачиваний: 19
|
|
|
|
|
|
|
|
Dec 19 2011, 08:03
|
Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
ucf сгенерирован core-генератором, в настройках там точно 100 МГц стояло, и на плате точно 100 МГц идет. Сам не понял что у них с комментариями. С вашей прошивкой ничего не изменилось - смотрю pci-устройства через pcitree в win хр. Грузится с флеши, производители платы уверяют что загрузка занимает порядка 70 мс. И на этот случай всегда рекомендуют горячий старт, который тоже не помогает. К тому же я в начале говорил, процесс инициализации начинает идти, проходят успешно стадии detect и polling, а на configuration случается затык, в один прекрасный момент (всегда один и тот же, что значит дело не в случайных помехах) RX линия сбрасывается в режим простоя (или как там правильно перевести IDLE). И кроме того в некоторых местах во время инициализации видно по сигналу rx_status что возникают ошибки 8b/10b decode error - некое нарушение целостности сигнала. Однако опять же они возникают строго в одинаковых местах, что не похоже просто на плохой прием - ведь в других местах я, к примеру, всегда вижу как root complex отправляет link number, а плис через некоторое время отсылает его назад в качестве подтверждения ( вот здесь я приводил осциллограммы проблемного момента, )
|
|
|
|
|
|
|
|
Dec 19 2011, 13:00
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Jack_of_Shadows @ Dec 19 2011, 16:11) Так, сорри, но я ввел вас в заблуждение.
Мне таки позволили расковырять рабочий PC, и я вставил плату с плисом туда (производитель для этого специальную переходную плату дает). Загрузилось сразу же - дефолтная прошивка с установленными в системе драйверами даже объявила о себе в диспетчере устройств, прошивка сгенерированная core generator вроде как тоже (по крайней мере она теперь висит в состоянии L0, как обнаружить ее в системе пока не допер. Все найденные для сканирования pci-шины проги (pcitree, pcidirect) под win7 не запустились).
Получается дело в рут комплексе - MSM945. Но это уже не совсем к этому топику относится Попробуйте bios покопать, power save и прочее. Корегенераторная прошивка ставится как memory controller. Попробуйте мою прошивку, надо только jungo поставить сначала.
|
|
|
|
|
|
|
|
Dec 22 2011, 14:37
|
Местный
Группа: Свой
Сообщений: 301
Регистрация: 18-09-07
Из: Украина
Пользователь №: 30 647
|
[quote name='Jack_of_Shadows' date='Dec 20 2011, 14:20' post='1007945'] Появились еще вопросы к знатокам PCI Express Block Plus: Если я создаю прошивку скажем PCIe x2, однако на плате физически только одна из этих линий соединена с процессором, возможно ли чтобы прошивка с процессором правильно договорились о ширине шины и сами переключились на х1 ? Подсознательно понимаю что такое должно быть возможно, однако на практике работы не вижу. Добрый день. Реально сталкивался с ситуацией, когда устройство на базе PCI Express Block Plus х4 в некоторых материнках в слотах х16 работает как х4, а в некоторых, как х1. Проверить как опознал ХОСТ устройство можно с помощью программки pci32.exe. Архив в прикрепленном файле. Запуск программы из командной строки pci32.exe > pcicfg.txt запишет информацию обо всех найденных pci и pcie устройствах в файл pcicfg.txt. Удачи.
Прикрепленные файлы
pci32.zip ( 266.87 килобайт )
Кол-во скачиваний: 19
|
|
|
|
|
|
|
|
Dec 26 2011, 06:58
|
Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
Andrew Su, спасибо за програмку, но дело у меня в другом. На данном этапе наконец полностью понял суть проблемы: единственный корректный х1 линк от процессора подается на второй порт в одном из сдвоенных трансиверов виртекса. Если я пытаюсь назначить в корке х1 линк на этот порт, ise ругается что это можно делать только на первый из портов трансивера. Вообще единственное что я могу присвоить моему правильному порту, это нечетный номер в соединении (1, 3 и т. д.). Однако как написано в мануале, если я создал в виртексе шину скажем на 4 линии, то он может ее самостоятельно обрубить до х1 только в том случае, если рабочей будет нулевая линия в этой шине (а не просто одна из линий). На форуме xilinx проскакивала информация о том, что в сдвоенных трансиверах можно инвертировать их номера (нулевой станет первым, первый станет нулевым) поменяв их назначение в одном из файлов корки (pcie_gt_wrapper), однако пока не смог понять как. Так получается, что для моих неудачно выбранных покупных плат это единственный вариант заработать - повесить нулевую линию шины pcie на первый трансивер в сдвоенном блоке.
Прошу прощения за сбивчивое объяснение. Как и раньше буду рад подсказкам, хотя проблема и достаточно редкая.
|
|
|
|
|
|
|
|
Dec 26 2011, 13:02
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Jack_of_Shadows @ Dec 26 2011, 10:58) Andrew Su, спасибо за програмку, но дело у меня в другом. На данном этапе наконец полностью понял суть проблемы: единственный корректный х1 линк от процессора подается на второй порт в одном из сдвоенных трансиверов виртекса. Если я пытаюсь назначить в корке х1 линк на этот порт, ise ругается что это можно делать только на первый из портов трансивера. Вообще единственное что я могу присвоить моему правильному порту, это нечетный номер в соединении (1, 3 и т. д.). Однако как написано в мануале, если я создал в виртексе шину скажем на 4 линии, то он может ее самостоятельно обрубить до х1 только в том случае, если рабочей будет нулевая линия в этой шине (а не просто одна из линий). На форуме xilinx проскакивала информация о том, что в сдвоенных трансиверах можно инвертировать их номера (нулевой станет первым, первый станет нулевым) поменяв их назначение в одном из файлов корки (pcie_gt_wrapper), однако пока не смог понять как. Так получается, что для моих неудачно выбранных покупных плат это единственный вариант заработать - повесить нулевую линию шины pcie на первый трансивер в сдвоенном блоке.
Прошу прощения за сбивчивое объяснение. Как и раньше буду рад подсказкам, хотя проблема и достаточно редкая. Странное что-то. Два канала GTP обозначаются одним констрейнтом, а канал выбирается по распиновке клока и данных самим исе. У Вас что ucf был неправильный?
|
|
|
|
|
|
|
|
Dec 26 2011, 14:27
|
Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
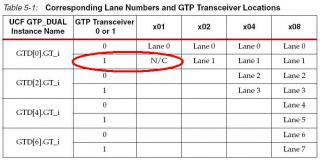
Констрейнт для сдвоенного GTP один и клок на него один. А вот данные строго определены - на нулевой трансивер четные линии шины, на первый нечетные. Вот по этому поводу рисунок из мануала:
Да и как канал может быть выбран по распиновке данных, если данные самим ise разрешается вешать только на нулевые трансиверы (в остальных случаях вылазит ошибка).
Сообщение отредактировал Jack_of_Shadows - Dec 26 2011, 14:29
|
|
|
|
|
|
|
|
Dec 26 2011, 17:37
|
Знающий
Группа: Свой
Сообщений: 672
Регистрация: 18-02-05
Пользователь №: 2 741
|
Цитата(Jack_of_Shadows @ Dec 26 2011, 17:27) Констрейнт для сдвоенного GTP один и клок на него один. А вот данные строго определены - на нулевой трансивер четные линии шины, на первый нечетные. Вот по этому поводу рисунок из мануала:
Да и как канал может быть выбран по распиновке данных, если данные самим ise разрешается вешать только на нулевые трансиверы (в остальных случаях вылазит ошибка). Действительно, странно выбрана распиновка плис. В таблице 5-3 вообще сказано, что для FX30T можно использовать только трансивер X0Y3 для PCIEx1. В Вашем ucf пины указаны только для тактовой, как на схеме подключены пины rx tx пары?
|
|
|
|
|
|
|
|
Dec 27 2011, 07:08
|
Участник
Группа: Участник
Сообщений: 46
Регистрация: 29-10-10
Пользователь №: 60 513
|
По поводу таблицы с поддерживаемыми трансиверами, в пункте перед ней "Relocating the Endpoint Block Plus Core" сказано, что они являются рекомендуемыми ввиду их максимальной близости к физическому блоку PCI Express, переход к другим трансиверам возможен, однако в этом случае xilinx не предоставляет техническую поддержку (в итоге максимальная частота проекта получалась в районе 239 МГц, и он отлично работал при 100 МГц опоры в обычном PC. Предполагаю, что с X0Y3 он бы и на 250 МГц завелся, однако в моей плате этот GTP занят SATA интерфейсом). Вообще на моей плате распиновка такова: Единственная возможная для использования x1 линия: X0Y2, RX - MGTRXP1_112 (M1) & MGTRXN1_112 (L1), TX - MGTTXP1_112 (N2) & MGTTXN1_112 (M2) Возможные тактовые линии: X0Y1, T4 & T3 (идут через драйверную микросхему с PEx16_x8_x4_Clkp/n) X0Y0, AB4 & AB3 (идут напрямую с PEx1_3Clkp/n). Я понимаю что нет ничего хорошего в том, что данные подключены к одному GTP, а клоки к другому, но уж что имею. Линии которые предполагались к использованию как основные, со стороны процессора подключены к шине PEG (PCI Express Graphics, заточена исключительно под работу с видеокартами, не может масштабироваться на меньше чем х16). Пока моя основная идея возможного костыля в такой ситуации это делать шину х4, захватывая оба нужных трансивера, и заставить ее завестись как х1. И здесь пока я упираюсь в ограничения приведенной мною выше таблицы.
|
|
|
|
|
|
|
|
Mar 19 2013, 12:12
|
Участник
Группа: Участник
Сообщений: 40
Регистрация: 8-11-11
Из: Рязань
Пользователь №: 68 183
|
Здравствуйте. Я пытаюсь разобраться с кодом PIO от Xilinx, который присутствует в корке PCIe. В этом примере вся память разбита на области по 2 Кб(всего 4 области). С компа обращаюсь к этой памяти через прогу RW-Everything.
из даташита на эту корку вычитал следующее:
Each space is implemented with a 2 KB memory. If the corresponding BAR is
configured to a wider aperture, accesses beyond the 2 KB limit wrap around and
overlap the 2 KB memory space.
Попробовал записать произвольные значения в память начиная с адреса, содержащегося в BAR. Действительно, как сказано в даташите, значения повторяются каждые 2 Кб. Но не как не пойму каким образом обращаться к остальным областям? В исходниках выбор области осуществляется исходя из значения двухбитового префикса адреса, который поступает в блок PIO_RX_ENGINE по шине AXI. Но как его задавать я так и не понял.
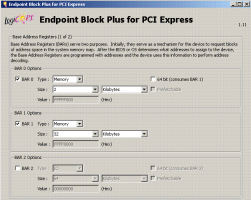
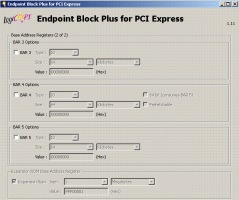
Может каждая область должна привязываться к своему BARу? При конфигурировании корки я активировал только один BAR
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
|