| |
 Работе по фронтам не клокового входа Работе по фронтам не клокового входа, чем черевато? |
|
|
|
|
 Jan 2 2014, 18:06 Jan 2 2014, 18:06
|
Гуру

Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454

|
Всем привет! Волею судеб так получилось что spi клок пришелся на не клоковый вход. Чем грозит использование его в конструкциях вида Код always @(posedge clk_pin)
begin
end ?
|
|
|
|
|
|
|
 |
Ответов
(1 - 99)
|
|
Jan 3 2014, 16:02
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 2 2014, 22:06)  Чем грозит использование его в конструкциях вида Геморроем. Хотя, многое зависит от частоты этого клока. Как вариант, можно взять какой-нить имеющийся в наличии клок с частотой в несколько раз больше, ловить им сабжевый клок как обычный сигнал и формировать en для логики обработки данных.
|
|
|
|
|
|
|
|
Jan 3 2014, 20:57
|

Lazy
Группа: Свой
Сообщений: 2 070
Регистрация: 21-06-04
Из: Ukraine
Пользователь №: 76
|
Цитата(Golikov A. @ Jan 2 2014, 21:06) Всем привет! Волею судеб так получилось что spi клок пришелся на не клоковый вход. Чем грозит использование его в конструкциях вида Код always @(posedge clk_pin)
begin
end ? ПМСМ Может не развестись про очень плотном заполнении (теоретически - но маловероятно) Больше рискуете, если CPLD - там ресурсы по интерконнекту ограничены.
--------------------
"Everything should be made as simple as possible, but not simpler." - Albert Einstein
|
|
|
|
|
|
|
|
Jan 3 2014, 23:11
|
Знающий
Группа: Свой
Сообщений: 781
Регистрация: 3-10-04
Из: Санкт-Петербург
Пользователь №: 768
|
Цитата(Golikov A. @ Jan 2 2014, 21:06) Волею судеб так получилось что spi клок пришелся на не клоковый вход. Чем грозит использование его в конструкциях вида Код always @(posedge clk_pin) И почему никто не вспомнил о несинхронных тактовых доменах и метастабильности? o_khavin дал правильный совет: нужно все входные сигналы пропустить через синхронизаторы, чтобы работать в одном тактовом домене. При примерно равных частотах применить другую технику, но домены синхронизировать придется.
|
|
|
|
|
|
|
|
Jan 4 2014, 07:27
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Вот... народ отошел от праздников  то за 3 дня ни одного ответа, то только отвернулся и сразу много... Вся схема естествен работает от нормального клока. имеется 2 SPI которые так завели, потому что человек делавший схему планировал их синхронизовать на основной клок. SPI в максимуме может иметь 50 МГц, а основной клок 100 МГц. И естественно как всегда бывает, стали SPI слейвами. Потому что со стороны проца SPI в слейве в 12 раз медленнее, потому с того конца SPI мастер. SPI слайв на 50 МГц, для основного клока 100 МГц синхронным сделать не реально, на спартане 6 не хватило сил даже на 200 МГц запустить прием - предачу, чтобы ловить фронты. Вот и дальше странности и геморрой. Я реализовал 2 асинхронных SPI которые принимают - передают по своим клокам, а результат уже через флаги синхронизируется с основным клоком. На одном SPI только прием данных На втором SPI прием данных, и в зависимости от принятых передача (прием и передача никогда не идет одновременно) В таком режиме все прекрасно работает, уже месяцы времени наработок, в сообщениях контрольная сумма, ошибок не возникает, все четко. теперь новое устройство и первый SPI решил переписать на прием-передачу, чтобы он одновременно передавал и принимал. И вот тут все сломалось. По какой - то причине то ли передача то ли прием сдвигается на 1 бит, причем в моделсиме все четко, а в железе кирдык. Первый проект разводился в нескольких модификациях и SPI всегда работали без сбоя, а тут на пустом кристалле (пока добавил 4 модуля) ничего не работает... Мне казалось что использовать клоковым сигнал с неклокового входа будет грозить тем что модули на этом сигнале в разных частях кристала будут работать с разными задержками, и потому использовать его для 1 модуля в целом безопасно. Теперь вот думаю, то ли это этот конкретный результат платы мне достался с какой -то проблемой, то ли действительно есть скрытые проблемы...
|
|
|
|
|
|
|
|
Jan 4 2014, 08:35
|
Участник
Группа: Участник
Сообщений: 51
Регистрация: 16-06-09
Пользователь №: 50 327
|
А я поддержу "Dr.Alex" . Действительно SPI слишком медленный протокол.
При использовании постороннего скоростного клока потребуется, как выразился Tiro, "пропустить через синхронизаторы"по сути это просто входные тригеры на сигналах SPI.
Случай для CPLD ещё проще, там даже временных проблем возникнуть не может.
|
|
|
|
|
|
|
|
Jan 4 2014, 09:56
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Дварфик @ Jan 4 2014, 12:35) А я поддержу "Dr.Alex" . Действительно SPI слишком медленный протокол. Какое вообще отношение частота имеет к метастабильности? Цитата(Golikov A. @ Jan 4 2014, 11:27) Теперь вот думаю, то ли это этот конкретный результат платы мне достался с какой -то проблемой, то ли действительно есть скрытые проблемы... Мы тоже подумаем, если Вы таки сообщите, про какой конкретно кристалл идёт речь и на какие конкретно ноги заведён сабжевый клок. Цитата(Golikov A. @ Jan 4 2014, 11:27) Мне казалось что использовать клоковым сигнал с неклокового входа будет грозить тем что модули на этом сигнале в разных частях кристала будут работать с разными задержками, и потому использовать его для 1 модуля в целом безопасно. Обычно рутер вытаскивает клок на глобальное дерево так быстро, как сможет. Проблема в том, что на отрезке от пина до глобального дерева, клок бежит по линиям, для него не предназначенным. В результате его характеристики (длительность фронтов, к примеру) выходят за рамки, для которых считается тайминг. После этого анализ тайминга может стать весьма далёким от действительности.
Сообщение отредактировал o_khavin - Jan 4 2014, 09:52
|
|
|
|
|
|
|
|
Jan 4 2014, 16:46
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Эм... и вот теперь вопрос на миллион  Как забить констраин между сигналом и выходом? Проблема вот в чем по MAIN_CLK и событию DataRedy защелкивается передаваемое значение в регистр DataOut а по SPI_CLK оно выдавливается наружу естественно нет никакой связи между MAIN_CLK и SPI_CLK, я сам слежу за времянкой в этом месте (SPI клоки не появляются пока данные гарантированно не попадут в регистр, там пауза несколько клоков) Теперь, когда я задаю времянку появления данных после фронта клока SPI в эту времянку входит полный путь от данных до выхода на ружу, а мне надо чтобы учитывалось только от DataOut до выхода, от фронта SPI_CLK. То есть как бы не учитывать время сохранения данных в DataOut, можно это как то в констраине описать? Не руками же вычитать время по логам и смотреть получилось или нет?
|
|
|
|
|
|
|
|
Jan 4 2014, 17:41
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 4 2014, 18:57) если написать констраины на сигналы, время выставления данных относительно этого входа, то в случае их выполнения все будет хорошо? То есть разницы не будет между сигналом с клокового и не клового входов?
Правильно ли что сигналы не различимы кроме сложности соблюдения констраинов? Не обязательно. Но есть вероятность. Цитата(Golikov A. @ Jan 4 2014, 20:46) Эм... и вот теперь вопрос на миллион Как забить констраин между сигналом и выходом? Проблема вот в чем по MAIN_CLK и событию DataRedy защелкивается передаваемое значение в регистр DataOut а по SPI_CLK оно выдавливается наружу естественно нет никакой связи между MAIN_CLK и SPI_CLK, я сам слежу за времянкой в этом месте (SPI клоки не появляются пока данные гарантированно не попадут в регистр, там пауза несколько клоков) Теперь, когда я задаю времянку появления данных после фронта клока SPI в эту времянку входит полный путь от данных до выхода на ружу, а мне надо чтобы учитывалось только от DataOut до выхода, от фронта SPI_CLK. То есть как бы не учитывать время сохранения данных в DataOut, можно это как то в констраине описать? Не руками же вычитать время по логам и смотреть получилось или нет? Можно поставить промежуточный регистр на spi-клоке и выдавать данные наружу из него. И времянку от него задать.
|
|
|
|
|
|
|
|
Jan 4 2014, 18:55
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(o_khavin @ Jan 4 2014, 21:41) Не обязательно. Но есть вероятность. и высока ли вероятность? Цитата(o_khavin @ Jan 4 2014, 21:41) Можно поставить промежуточный регистр на spi-клоке и выдавать данные наружу из него. И времянку от него задать. ну собственно так и есть. Есть промежуточный регистр, вопрос как такой констраин пишется? я вообще в них не силен, а в таких специфических и подавно.
|
|
|
|
|
|
|
|
Jan 4 2014, 19:36
|
Местный
Группа: Свой
Сообщений: 462
Регистрация: 20-01-06
Пользователь №: 13 399
|
Цитата(Golikov A. @ Jan 2 2014, 22:06) Волею судеб так получилось что spi клок пришелся на не клоковый вход.
Чем грозит использование его в конструкциях вида Ничем не грозит, поскольку ни в одном более-менее серьезном проекте никто как тактовый сигнал его использовать не будет. Выделяйте фронт (на внутренней более высокой частоте) и используйте его как "строб".
|
|
|
|
|
|
|
|
Jan 4 2014, 20:22
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(Джеймс @ Jan 4 2014, 23:36) Ничем не грозит, поскольку ни в одном более-менее серьезном проекте никто как тактовый сигнал его использовать не будет. Выделяйте фронт (на внутренней более высокой частоте) и используйте его как "строб". Расскажете как выделить 50 МГц клок на 100 МГц тактовой? Боюсь что для этого надо не меньше 200 МГц, а этого мне на 6 спартане добиться не удалось... Мне он нужен как тактовый только для сдвиговых регистров данных и только для этого. Вот какая странность, если задать констраин что SPI клок 100 МГц, все разводиться. А если указать что SPI клок 200 МГц, но данные должны быть готовы не позднее 8 мСек после фронта (за 2 мс до следующего обратного направления). Пишут клок констраин не выдержан, и минимум чего можно добиться это 12 мСек. Блин вот какого? ведь на 100 МГц, сигналы точно готовы до 10 мСек... как договориться? может кто пример правильного констраина написать? сигналы spi_in spi_out spi_clk регистры [8 : 0]spi_data_in_reg [8 : 0]spi_data_out_reg хочу чтобы с spi_in данные попадали в spi_data_in_reg не дольше чем через 5 нСек после восходящего сигнала клока spi_clk а данные из spi_data_out_reg попадали на spi_out не дольше чем через 5 нСек после падающего сигнала клока spi_clk может я чего пишу не верно?
|
|
|
|
|
|
|
|
Jan 4 2014, 21:19
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
тут вам не констрейн писать надо, и междоменный переход. Например, регистр данных, как и счетчик бит, тактируется клоком SPI, по окончании приема от этого же клока устанавливается признак того, что данное принято, и этот признак через пару синхронизаторов уходит в основной домен. как он дошел до основного домена, точнее его изменение с 0 на 1, данные следует защелкнуть в регистр в основном домене, и отправить их дальше куда следует. Возможно, если планируется непрерывный прием, еще нужен теневой регистр в SPI домене, а то и FIFO.
а констрейны - объявить домены асинхронными, и всё. Между ними никаких констрейнов. Констренить только входы данных относительно SPI клока - а это классический SDC-констрейн set_output_delay/set_input_delay
|
|
|
|
|
|
|
|
Jan 4 2014, 21:44
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
вся синхронизация имеется, это понятно и это реализовано... объявить асинхронные домены - это я думаю осилю (хотя если скажете какие буквы жать точно буду рад). теперь нужен последний шаг, объяснить синтезатору за чем важно следить, собственно следить надо вот за чем: по падающему клоку я выставляю данные, а защелкиваются они по восходящему если spi_clk имеет период 20 nSec, то синтезатор считает что данные могут стать валидными как раз за время чуть меньше 20 nSec к след фронту, а мне надо чтобы они стали валидными не позднее 10 nSec (и даже меньше), к след восходящему фронту. если сделать период 10 nSec это получилось автоматически, и все работает и разводиться, но зачем искусственно зажимать клок? Хочу клок с периодом 20 nSec и готовностью данных за 8 nSec я написал так Код NET "mem_spi_clk" TNM_NET = mem_spi_clk;
TIMESPEC TS_mem_spi_clk = PERIOD "mem_spi_clk" 20 ns HIGH 50%;
NET "mem_spi_clk" CLOCK_DEDICATED_ROUTE = FALSE;
OFFSET = IN 8 ns VALID 16 ns BEFORE "mem_spi_clk" RISING;
OFFSET = OUT 8 ns AFTER "mem_spi_clk" FALLING; казалось бы вот оно счастье, а вот фиг, OFFSET = OUT 8 ns AFTER "mem_spi_clk" FALLING; этот констраин не выполняется... хочет чуть ли не 12 nSec при этом схема с TIMESPEC TS_mem_spi_clk = PERIOD "mem_spi_clk" 10 ns HIGH 50%; разводиться, и констраин выполняется, то есть физически можно добиться время установки меньше 10 nSec.... как его уговорить то? Или я чего то не то написал?
|
|
|
|
|
|
|
|
Jan 5 2014, 16:48
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
это был не я у нас разделения труда%).... на этой ноге сидит только 2 сдвиговых регистра SPI приемный и передающий. Причем они полностью изолированны от всего остального по времени, все данные для них могут быть готовы за много клоков до, и считаться через достаточно клоков после. как сделать такое колдунство как локальный клок? Что-то мне кажется эту ногу вообще не надо тащить на буферы, или без этого в плис не бывает? может вообще все проще написать Код always @(spi_clk)
begin
if(spi_clk == 1'b1) //UP
else //down
end или так еще хуже?
|
|
|
|
|
|
|
|
Jan 5 2014, 17:01
|
Знающий
Группа: Свой
Сообщений: 781
Регистрация: 3-10-04
Из: Санкт-Петербург
Пользователь №: 768
|
Цитата(Golikov A. @ Jan 4 2014, 10:27) теперь новое устройство и первый SPI решил переписать на прием-передачу, чтобы он одновременно передавал и принимал. И вот тут все сломалось. По какой - то причине то ли передача то ли прием сдвигается на 1 бит, причем в моделсиме все четко, а в железе кирдык. Первый проект разводился в нескольких модификациях и SPI всегда работали без сбоя, а тут на пустом кристалле (пока добавил 4 модуля) ничего не работает...
Мне казалось что использовать клоковым сигнал с неклокового входа будет грозить тем что модули на этом сигнале в разных частях кристала будут работать с разными задержками, и потому использовать его для 1 модуля в целом безопасно. На самом деле использование не клоковой ножки ничем не грозит, если именно сам автомат SPI разводится нормально. Если он тормозит, то надо на глобальную цепь перекинуть, как уже говорили, через global или bufg. Но вряд ли тормозит именно автомат SPI, это локальная структура и связи короткие. Считаю, что использовать такт SPI безопасно в автомате SPI при одном условии - клок "хороший", без "дребезга". Если нет гарантии - то не годится. Если данные между тактовыми доменами перебрасывать параллельной шиной через регистры, то есть одно условие непропуска данных - данные на передачу должны быть готовы заранее, так, чтобы до прихода первого такта SPI выводимые данные уже были в сдвиговом регистре. А про констрейны - это способ конфигурировать синтезатор и временной анализатор. Скорее даже только второй инструмент. То есть несинхронный дизайн должен анализироваться верно, поэтому констрейны позволяют исключить из анализа пути между несинхронными сигналами. Естественно, цепи междоменной синхронизации должны присутствовать аппаратно.
|
|
|
|
|
|
|
|
Jan 5 2014, 20:43
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 4 2014, 23:22) Расскажете как выделить 50 МГц клок на 100 МГц тактовой? Боюсь что для этого надо не меньше 200 МГц, а этого мне на 6 спартане добиться не удалось... Можно работать по обоим фронтам тактовой 100 МГц. Делал подобное. Наверное получится.
|
|
|
|
|
|
|
|
Jan 6 2014, 09:52
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 5 2014, 20:48) как сделать такое колдунство как локальный клок? Для начала, написать в конце концов PN чипа и номер ноги. Что за привычка долго и мучительно пытаться обсуждать сферического коня?
|
|
|
|
|
|
|
|
Jan 6 2014, 14:17
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 6 2014, 00:21) не получится... Примерно так: Код // сохранённые значения входных сигналов соответствуют следующим моментам тактового сигнала c 100 МГц:
// +---------+ +---------+ +------
// | | | | |
// -----+ +----------+ +------------+
// sck2 sck2n sck1 sck1n sck
// mosi2n mosi1 mosi1n mosi
input c,sck,mosi;
reg sck1n,sck2n,mosi1n,mosi2n,sck1,sck2,mosi1,fr;
reg [7:0] data;
reg [2:0] nbit;
always @(negedge(c))
begin
sck1n <= sck;
sck2n <= sck1n;
mosi1n <= mosi;
mosi2n <= mosi1n;
end
always @(posedge(c))
begin
sck1 <= sck;
sck2 <= sck1;
mosi1 <= mosi;
if (sck1 & (~sck2n))
begin
data <= {data[6:0], mosi1};
fr <= (nbit==7);
nbit <= nbit+1;
end
else if (sck2n & (~sck2))
begin
data <= {data[6:0], mosi2n};
fr <= (nbit==7);
nbit <= nbit+1;
end
if (fr)
begin
fr <= 0;
// байт принят в data
end
end Здесь данные с mosi берутся по переднему фронту sck.
Сообщение отредактировал maksimp - Jan 6 2014, 14:27
|
|
|
|
|
|
|
|
Jan 6 2014, 15:40
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(o_khavin @ Jan 6 2014, 13:52) Для начала, написать в конце концов PN чипа и номер ноги. Что за привычка долго и мучительно пытаться обсуждать сферического коня? я просто пытался абстрактно рассматривать ситуацию, вообще в целом. Меня смущают попытки сразу тянуть сигнал на gbuf и получать огромную задержку на этом пути. Неужели нельзя договориться с синтезатором чтобы он протащил пин на прямую? Но не на уровне раскладки ЛУТов в ручную, а на высоком уровне, чтобы проект мог быть дальше поддержан. Без ассемблера как бы... Но когда такие люди просят данных, не могу не дать чип спартан 6, XC6SLX9-3TQ144I ножки CLK1 - 11 MISO - 12 MOSI - 14 CLK0 - 33 MISO - 34 MOSI - 35 Цитата(maksimp @ Jan 6 2014, 18:17) Примерно так:
Здесь данные с mosi берутся по переднему фронту sck. спасибо за текст и картинки, я понял идею, я пробовал это самым первым когда понял что констрайн не проходит. Я еще попозже повнимательнее посмотрю, может я чего-то упустил, но вроде бы так и делал.
|
|
|
|
|
|
|
|
Jan 6 2014, 17:55
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 5 2014, 21:56) тормозит именно SPI
в частности из готового сдвигового регистра не получается вовремя доставить данные на выход, по падающему фронту регистр сдвигается, а к следующему поднимающемуся данные должны уже стоять, а так не выходит, не хватает 2-3 нСек... Можно сдвигать регистр не по падающему а по поднимающемуся фронту. Приёмник (внешний относительно ПЛИС) берёт данные по поднимающемуся фронту, и сдвигать регистр можно тут же, не ожидая ещё половину такта.
|
|
|
|
|
|
|
|
Jan 6 2014, 18:52
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
данные сдвигаются по падающему фронту,
захват по поднимающемуся.
время между падающим и поднимающимся 10 нСек
время пока клок идет до сдвиг регистра 7-8 нСек,
время пока данные из сдвиг регистра идут на ружу 3-4 нСек
то есть между падающим фронтом и появлением данных проходит 12 нСек вместо 10, это в медленном пути, в быстром проходит 4.
потому перенести выдачу данных на поднимающиеся фронты тоже не вариант, в надежде на задержку.
из реальности уговорить сигнал не идти на глобальный буфер, на что у него уходит 5.9 нСек в медленном пути, а сразу идти на клок элементов, если это вообще возможно. Пока это я еще не реализовывал, и пока не имею 100% информации о возможности
|
|
|
|
|
|
|
|
Jan 6 2014, 18:58
|
Знающий
Группа: Свой
Сообщений: 781
Регистрация: 3-10-04
Из: Санкт-Петербург
Пользователь №: 768
|
Цитата(Golikov A. @ Jan 6 2014, 21:52) данные сдвигаются по падающему фронту,
захват по поднимающемуся.
время между падающим и поднимающимся 10 нСек
время пока клок идет до сдвиг регистра 7-8 нСек,
время пока данные из сдвиг регистра идут на ружу 3-4 нСек
то есть между падающим фронтом и появлением данных проходит 12 нСек вместо 10, это в медленном пути, в быстром проходит 4.
потому перенести выдачу данных на поднимающиеся фронты тоже не вариант, в надежде на задержку.
из реальности уговорить сигнал не идти на глобальный буфер, на что у него уходит 5.9 нСек в медленном пути, а сразу идти на клок элементов, если это вообще возможно. Пока это я еще не реализовывал, и пока не имею 100% информации о возможности Позвольте Вам не поверить. В 6-м Спартанце такие задержки??? Вы как-то не так логику описали. Приводите весь ваш исходник SPI.
|
|
|
|
|
|
|
|
Jan 6 2014, 19:13
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 6 2014, 21:52) то есть между падающим фронтом и появлением данных проходит 12 нСек вместо 10, это в медленном пути, в быстром проходит 4.
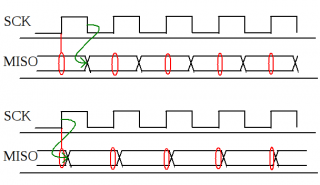
потому перенести выдачу данных на поднимающиеся фронты тоже не вариант, в надежде на задержку. 4 нс это не проблема. Приёмник уже захватил данные по поднимающимуся фронту, держать данные ещё 10 нсек не обязательно. На графиках - верхняя пара - обычныое построение SPI. Красным отмечены моменты захвата данных Нижняя пара - то что предлагается. В любом случае захват будет до изменения данных, даже если там всего 4 нс.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Jan 6 2014, 19:36
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Только надо всегда помнить, что прохождение клока от клоковой ноги до клокового пина регистра обычно дольше, чем прохождение данного от ноги до пина данных регистра, из-за того, что дерево клока большое и толстое, даже локальное/региональное. Но их, обычно, можно выровнять - для этого в ПЛИС обычно предусмотрены линии задержки в пинах данных от входного буфера до регистра в IO буфере. В ПЛИС Lattice - это FIXEDDELAY, и DELAYB элементы - FIXEDDELAY указывается как атрибут синтезатору, а DELAYB ставится как примитив. Таким образом, если первый регистр от сдвигового регистра расположить в IO буфере, и завести данные на него через вот этот хитрый элемент задержки, то он обеспечит нулевой холд, то есть то, что клок дойдет до этого регистра вместе с данными, не позже их. Как мне кажется, это должно решить Вашу проблему на корню, если я ее правильно понял. Это касаемо входного сигнала данных, которые ПЛИС принимает. Но - не забывайте про холд... Сетап может пройти по этому сигналу, а холд оказаться криминальным из-за обгона клока входными данными! Конкретно, с Xilinx, сорри, не знаю, не приходилось с их ПЛИС дело иметь, бог миловал, но аналогичный механизм там есть наверняка - смотрите документацию, связанную с IO буферами и их внутренним устройством. На нижеприведенной картинке эти узлы видно, слева вверху, но это картинка латиса, ищите аналогичные в своей документации.
Что касается задержки clock-to-output для выходного сигнала, который ПЛИС передает, то это, пожалуй, никак не лечится, разве что как-то вручную развести клок к output регистру в IO буфере (и, разумеется, выходной регистр регистра сдвига поместить в IO буфер, а не в LE), если это вообще по архитектуре возможно, пустить клок и в дерево, и еще мимо провести напрямую к нужному регистру - надо внимательно изучить архитектуру, покопать в ручном редакторе разводки кристалла. Еще - а вдруг... например, случайно, SPI клок попал на пин для DDR DQS - тогда этот путь задействовать можно, он вообще дюже быстрый. Ну и вообще, обратить внимание на всякие такие "креативные" решения вопроса. Заранее извиняюсь, если вообще не так понял проблему....
|
|
|
|
|
|
|
|
Jan 6 2014, 20:36
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(Tiro @ Jan 6 2014, 22:58) Позвольте Вам не поверить. В 6-м Спартанце такие задержки??? Вы как-то не так логику описали. Приводите весь ваш исходник SPI. проблемы что клок идет с не клокового входа, о чем собственно вся тема Цитата(SM @ Jan 6 2014, 23:36) Что касается задержки clock-to-output для выходного сигнала, который ПЛИС передает, то это, пожалуй, никак не лечится, разве что как-то вручную развести клок к output регистру в IO буфере (и, разумеется, выходной регистр регистра сдвига поместить в IO буфер, а не в LE)
Заранее извиняюсь, если вообще не так понял проблему.... Все верно в целом, но с приемом в плис проблем нет, констрейны заданы и выполнены с бооольшим запасом. А вот с передачей как раз есть засада и большая, и именно про ручное решение проблемы сейчас и думаю... Цитата(maksimp @ Jan 6 2014, 23:13) 4 нс это не проблема. Приёмник уже захватил данные по поднимающимуся фронту, держать данные ещё 10 нсек не обязательно.
На графиках - верхняя пара - обычныое построение SPI. Красным отмечены моменты захвата данных
Нижняя пара - то что предлагается. В любом случае захват будет до изменения данных, даже если там всего 4 нс. Проблема передачи данных ПЛИСом как слейвом Мастер ставит клок, а на него надо реагировать и выдавать данные... путь сигнала от клока до выхода 12 нСек, вместо 10 нСек потому мастер захватывает черти что. Наверное менять данные по восходящему клоку возможно, поскольку есть дикая задержка от клока до буфера, то напортить данные в момент приема скорее всего не реально, но хорошо бы как то правильно констрейны написать, чтобы все было четко...
|
|
|
|
|
|
|
|
Jan 6 2014, 20:55
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 7 2014, 00:36) Все верно в целом, но с приемом в плис проблем нет, констрейны заданы и выполнены с бооольшим запасом.
А вот с передачей как раз есть засада и большая, и именно про ручное решение проблемы сейчас и думаю... Как вариант, устроить "калибровку" выхода выдавая данные либо по падающему фронту, либо по восходящему в зависимости от конкретного случая. Т.е. пытаться вычитать что-то наружу в одном и другом варианте (дизайн должен иметь возможность переключения без переконфигурирования), проверять на мастере на предмет успешного приёма, и выбирать "хороший" вариант для дальнейшей работы.
|
|
|
|
|
|
|
|
Jan 6 2014, 22:12
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(o_khavin @ Jan 7 2014, 00:55) Как вариант, устроить "калибровку" выхода выдавая данные либо по падающему фронту, либо по восходящему в зависимости от конкретного случая. Т.е. пытаться вычитать что-то наружу в одном и другом варианте (дизайн должен иметь возможность переключения без переконфигурирования), проверять на мастере на предмет успешного приёма, и выбирать "хороший" вариант для дальнейшей работы. Мне кажется потенциально опасное решение. В начале работы на холодном кристале все пойдет по одному пути, потом он прогреется и...? попробовал защелкнуть данные в регистр по падению чип селекта, а потом выдавливать по восходящему фронту получил ошибку Assignment under multiple single edges is not supported for synthesis ту же ошибку я получал пытаясь работать по 2 фронтам клока. к ошибке есть приписка You can change the severity of this error message to warning using switch -change_error_to_warning "HDLCompiler:1128" но хорошо ли это? В целом я знаю что сначала будет фронт одного сигнала, а потом будут фронты другого сигнала, но поможет ли это схеме? И можно ли задать констрейн чтобы данные на выходе менялись не раньше чем заданное число после клока на входе, вроде же можно через VALID да? Если удастся договорится со схемой по этим 2 пунктам, то задача будет в целом решена, данные будут меняться не по падающему клоку, а по восходящему, но с гарантированной паузой. Есть шансы? Ну что-же! успех, наверное можно сказать что наконец то я понял идею maksimp по синхронизации на основной клок, и возможно даже ее реализую, надо еще кое-что проверить. на данный момент реализовал выдачу данных по восходящему фронту, фактически по сигналу защелкивания данных. Очень хочется наложить правильный констрейн на смену данных после фронта, нее раньше чем через заданное время, и что-то я пока не понимаю как. Сделал первые тесты чтения записи, вроде бы все наладилось, в целом оно и понятно если путь данных был примерно 12 нСек, то после поднимающегося фронта данные как раз и выставляются на падающий. А долгая задержка клока сохраняет данные во время защелки, но ВСЕ ТАК хотелось бы подстраховаться констрейном. Кто поможет? Как обозначить чтобы данные менялись не раньше чем через заданное время после фронта?
|
|
|
|
|
|
|
|
Jan 7 2014, 09:22
|
Частый гость
Группа: Участник
Сообщений: 113
Регистрация: 12-03-07
Пользователь №: 26 075
|
Цитата(Golikov A. @ Jan 4 2014, 11:27) По какой - то причине то ли передача то ли прием сдвигается на 1 бит, причем в моделсиме все четко, а в железе кирдык. Может поможет... Помнится у меня была точно такая же проблема. Камень был Spartan-3E, SPI слейв, SCK был заведен на неклоковый вход, данные почемуто сдвигались на 1 бит, в симуляторе было все ОК. Долго мучался с этими констрейнами. Пока не вывалил все сигналы в чипскоп. Оказалось что последовательность сигналов SPI, которые я формировал в симуляторе отличается от последовательности, которые выдает МК. Точнее - их начало, когда CS опускается в ноль. Проблема решилась настройкой SPI на стороне МК (у него было несколько режимов SPI) и подправкой кода ПЛИС. После этого все констрейны удалил, кроме CLOCK_DEDICATED_ROUTE = FALSE; Правда SPI на МК был не очень шустрый - кажется порядка 20 МГц.
|
|
|
|
|
|
|
|
Jan 7 2014, 09:42
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 7 2014, 02:12) Мне кажется потенциально опасное решение. В начале работы на холодном кристале все пойдет по одному пути, потом он прогреется и...? В процессе работы "путь" поменяться не может. Зависимость от температуры есть, но не в весь диапазон. Основной вклад даёт разброс параметров разных чипов. С этим калибровка и борется. Кстати, аналогичный механизм используется в коре Xilinx-а по работе с DDR-памятью - производится калибровка и подстройка задержки DQ относительно DQS.
|
|
|
|
|
|
|
|
Jan 7 2014, 10:08
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(o_khavin @ Jan 7 2014, 13:42) В процессе работы "путь" поменяться не может. Зависимость от температуры есть, но не в весь диапазон. Основной вклад даёт разброс параметров разных чипов. С этим калибровка и борется. Кстати, аналогичный механизм используется в коре Xilinx-а по работе с DDR-памятью - производится калибровка и подстройка задержки DQ относительно DQS. при проверке констраинов 2 пути коротки и длинный коротки с запасом укладывается, длинны не укладывается. НА реальной железке если по 1 слову читать почти всегда все хорошо, если группу слов то временами вылазят ошибки. я трактовал что коротки и длинный путь это как бы граничные условия, реальная работа где-то по середине. Пока хочется избежать калибровки, потому что внутренне мне она кажется страшной%) Цитата(olegras @ Jan 7 2014, 13:22) Может поможет...
Помнится у меня была точно такая же проблема. Камень был Spartan-3E, SPI слейв, SCK был заведен на неклоковый вход, данные почемуто сдвигались на 1 бит, в симуляторе было все ОК. Правда SPI на МК был не очень шустрый - кажется порядка 20 МГц. Спасибо за ответ, на 25 МГц все работает, проблемы на 50 МГц. И их причина обнаружена, данные не успевают выставляться, даже тут уже есть несколько решений проблемы.
|
|
|
|
|
|
|
|
Jan 7 2014, 10:24
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 7 2014, 11:54) а вот что данные могут меняться не РАНЬШЕ чем за указанное время ПОСЛЕ клока, вот такого чего - то нет... или я не правильно трактую мануал? BEFORE на, например, -2 нс (либо на период клока - 2 нс), будет говорить о том, что данные должны удерживаться после фронта, не менее, чем 2нс (hold time), то есть меняться не раньше, чем. Ну, по крайней мере, так должно быть, раз документация говорит, что BEFORE предназначено для анализа HOLD таймингов
|
|
|
|
|
|
|
|
Jan 7 2014, 10:54
|
Частый гость
Группа: Участник
Сообщений: 113
Регистрация: 12-03-07
Пользователь №: 26 075
|
Цитата(Golikov A. @ Jan 7 2014, 13:08) проблемы на 50 МГц. И их причина обнаружена, данные не успевают выставляться ... SPI был настроен в такой режим. Выставление данных - по заднему фронту SCK. CS - на асинхронных ресетах клоковых процессов. Думаю, что и на 50 МГц должно работать.
|
|
|
|
|
|
|
|
Jan 7 2014, 11:14
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 7 2014, 14:49) теперь бы еще узнать как это делается. Я совсем совсем не силен в констрейнах.... А Вы почитайте подробный отчет анализа SETUP-ов и HOLD-ов - там должно быть написано, что он там с чем суммировал в каком анализе, что получилось, и какой запас (или нарушение) - проанализируйте это, и придет ясность, как правильно обконстрейнить. К сожалению, повторю, я с ксилинкс дела не имел, поэтому гарантировано точно не могу подсказать, как правильно описать HOLD (удержание старых данных после клока, не менее, чем на сколько то) - я говорю по аналогии с другими средами разработки. Но "анализ отчета анализатора", подробного отчета, должен по идее все расставить по своим местам. ---------------------- UPD: Хмммм.... Пожалуй, я был неправ... Поверхностное чтение документации на констрейны xilinx показывает, что там нет возможности обконстрейнить HOLD для выходов (для входов однако есть - OFFSET IN ... VALID ....), есть только возможность его узнать, какое оно получилось, анализом минимального времени. И у самого есть вопрос к знатокам хилых - что, внатуре нет? Странно все это...
|
|
|
|
|
|
|
|
Jan 7 2014, 12:02
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
ну задержки есть, то есть хотелось бы чтобы он проанализировал путь, и если он короче чем заданное время воткнул задержку, А если больше не трогал.
Угнетает что на SPI проца нет никакой спецификации. Вот он захватывает данные по восходящему фронту, но нет никаких данных сколько они должны стоять до, и сколько после клока. И если косвенно "сколько до" можно прикинуть, данные должны выставлять по падающему клоку, то сколько они должны удерживаться - не понятно...
Варианты использования такой задержки масса. К примеру задав ее пол периода я могу по восходящему фронту ставить данные не раньше падающего, то есть вообще выполнить требования. А без такой задержки я боюсь иметь теоретическую возможность снять данные до их захвата процом.
Реально это наверное невозможно, так как путь распространения сигнала до регистра и обратно все же не нулевой, и если я вижу фронт, то на проце он был заведомо раньше, но для очистки совести хотелось бы держать это время под контролем.
Вот кстати сейчас думаю воткнуть ДДР на входе и выходе которые есть у спартана 6, это позволит анализировать фронты входящего сигнала с точностью +- 5 нСек, а вот что мне для выхода даст пока не очень понимаю, но чувствуется что тоже что-то даст... почему мне не дают по 2 фронтам блин работать...
|
|
|
|
|
|
|
|
Jan 7 2014, 12:17
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Dr.Alex @ Jan 7 2014, 15:51) А каким образом вообще можно управлять минимальным холдом выхода? Он что, задержки там будет вставлять? Латис, как и альтера, например, после разводки, когда все SETUP-ы утрясли, проводят (опциональный) "Par hold correction" (ниже привожу лог, как они, конкретно латис в данном случае, это делают в одном из проектов). Реально, они удлиняют пути от тех регистров, от которых оказался слишком быстрый путь на выход, либо удлиняя разводку, либо вставляя лишние буфера. Кстати. Точно так же делают и среды разводки заказных ИМС, тот же encounter например, втыкая лишние буфера куда надо, когда запускается коррекция холдов. И вопрос стоял не "зачем", и не "как это внутри делается", а как это описать констрейнами: дано: Спецификация PCI rev 3.0, Table 7-4, Tval, значения min=2нс, max=6нс, CLK=66МГц для латиса:CLOCK_TO_OUT PORT "pci_nTRDY" MAX 6.00 ns MIN 2.00 ns CLKPORT "pci_CLK" ; для альтеры:set_output_delay 9.1515 -clock pci_CLK -max [get_ports pci_nTRDY] set_output_delay -2.00 -clock pci_CLK -min -add_delay [get_ports pci_nTRDY] UPD: для пояснения, 9.1515 это период клока 66 МГц (15.1515) минус те самые 6 нс спецификации PCI/66 кстати. вот заодно и ответ на "зачем" - для PCI например. где 2 нс минимум по спецификации - и у кучи путей, разведенных "кое как", но с соблюдением MAX_DELAY, получается ошибка по MIN_DELAY из-за образовавшихся "коротких и быстрых путей" ! А для XILINX как это написать?CODE
Start NBR section for re-routing
Level 4, iteration 1
0(0.00%) conflict; 0(0.00%) untouched conn; 0 (nbr) score;
Estimated worst slack/total negative slack: 0.886ns/0.000ns; real time: 3 mins 1 secs
Start NBR section for post-routing
End NBR router with 0 unrouted connection
NBR Summary
-----------
Number of unrouted connections : 0 (0.00%)
Number of connections with timing violations : 0 (0.00%)
Estimated worst slack : 0.886ns
Timing score : 0
-----------
Notes: The timing info is calculated for SETUP only and all PAR_ADJs are ignored.
Par hold correction will be run with extra effort.
Hold time optimization iteration 0:
There are 91 hold time violations, the optimization is running ...
End of iteration 0
43027 successful; 0 unrouted; real time: 3 mins 28 secs
Hold time optimization iteration 1:
There are 3 hold time violations, the optimization is running ...
Starting iterative routing.
End of iteration 1
43027 successful; 0 unrouted; real time: 3 mins 36 secs
Hold time optimization iteration 2:
There are 3 hold time violations, the optimization is running ...
End of iteration 2
43027 successful; 0 unrouted; real time: 3 mins 44 secs
Hold time optimization iteration 3:
All hold time violations have been successfully corrected in speed grade M
Total CPU time 4 mins 7 secs
Total REAL time: 4 mins 17 secs
Completely routed.
End of route. 43027 routed (100.00%); 0 unrouted.
Checking DRC ...
No errors found.
Hold time timing score: 0, hold timing errors: 0
Timing score: 0
|
|
|
|
|
|
|
|
Jan 7 2014, 17:28
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 7 2014, 21:23) что то как то муторно написано, не VALID ли мне нужен?
OFFSET = OUT 15 ns VALID 20 ns AFTER "spi_clk" RISING Он самый. Но он по документации есть только у IN, а у OUT - нету. Так что, увы... а перекрыться не может, подразумевается, что задается жесткое окно, где сигнал обязан быть стабилен, от и до. А что до и после, и как они там сдвинутся, никого не волнует уже. То есть констрейн означает, что сигнал должен быть устойчив в течение 20 нс после 15 нс от фронта. Но, повторюсь, согласно документации для OUT нельзя задать VALID, а только AFTER/BEFORE.
|
|
|
|
|
|
|
|
Jan 7 2014, 17:36
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(SM @ Jan 7 2014, 16:17) Латис, как и альтера, например, после разводки, когда все SETUP-ы утрясли, проводят (опциональный) "Par hold correction" (ниже привожу лог, как они, конкретно латис в данном случае, это делают в одном из проектов). Реально, они удлиняют пути от тех регистров, от которых оказался слишком быстрый путь на выход, либо удлиняя разводку, либо вставляя лишние буфера. Кстати. Точно так же делают и среды разводки заказных ИМС, тот же encounter например, втыкая лишние буфера куда надо, когда запускается коррекция холдов. Как минимум для внутренних цепей у Xilinx-а это есть. Если смотреть в лог рутера, то видно что последний stage как раз изничтожает лишние hold-ы, в то время как setup-ы уже нулевые (не выходят за заданные границы). Просто он не имеет отдельного названия - stage N и всё. Так что ищите, надежда есть.
Сообщение отредактировал o_khavin - Jan 7 2014, 17:37
|
|
|
|
|
|
|
|
Jan 7 2014, 19:08
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
вот тут есть непонятность в описании нет валида, но в примерах есть.
и на форуме ксалинкса кто-то его активно использовал. И на констраин при имплиментации никто не ругнулся. И в репорте после синтеза он есть и оценивается. так что может он и есть, но про него никто не знает?... темный лес блин... но такая настройка явно нужна.
ну и реакции на этот констрейн никакой, задавай хоть 100 хоть 0....
в репорте стоит только MAXDELAY, получается что таким образом не получить, только глазами анализировать, минимальный и максимальный пути указаны, можно прикинуть сколько получилось, а поправлять видать только руками...
Думаю загвоздка в том что констрейн - это проверка условий, а не задание. То есть должны быть еще какие - то настройки на выполнение
|
|
|
|
|
|
|
|
Jan 7 2014, 19:14
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 7 2014, 23:08) Думаю загвоздка в том что констрейн - это проверка условий, а не задание. То есть должны быть еще какие - то настройки на выполнение Вообще, констрейны это и проверка, и задание (для timing-driven операций разводки и размещения). Просто, похоже, что документация права - VALID не работает для OUT. А почему его не обругали... Ну банальный глюк софта например. Если бы он работал, то на запредельные значения, как минимум, проверка таймингов бы ругалась отрицательным запасом (slack) по холдам. В таком случае непонятно одно, почему общественность до сих пор бунт не подняла
|
|
|
|
|
|
|
|
Jan 7 2014, 22:37
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(ZASADA @ Jan 8 2014, 01:54) а чего бунтовать? уже 5 страниц темы, а лично мне не понятно,в чем проблема. на запись все работает, значит вполне спокойно на 50 МГц работает неспециализированная нога в качестве входа тактового сигнала. А то, что при чтении на 1 такт все сдвигается и с симулятором не совпадает - так это возможно надо схему чтения менять, а не констрейны. Если что-то не понятно иногда стоит попытаться разобраться... 1. Разница между чтением и записью: При записи входной сигнал защелкивается по входному клоку, эти линии можно друг с другом сровнять по времени и все хорошо. При чтении вам надо выдавать по входному клоку сигналы изнутри схему, и тут уже ничего не попишешь, потому надо извращаться. 1.1. Тут кстати интересный момент я все входные сообщения как более важный обложил контрольными суммами и поскольку они сходились, выходные остались без них. Выходные сообщения не очень важны, и мне показалось что их можно читать по 2 раза, это надежнее контрольной суммы. Так вот это верно для случайных ошибок, а для повторяемой как у меня нет, и ошибки были пропущены. 2. Сдвижка на 1 такт при чтении возникает из-за того что выставленные по падающему клоку данные не успевали вылезти до их защелкивания на ружу. Что порождала 2 вопроса, как с этим бороться и как это детектить. 2.1. Ответом на второй вопрос явилось написание констрейнов, которые и выявили эту проблему, может вам они были очевидны, жаль что вы их не указали пару страниц назад, я бы потратил меньше времени. 2.2. Ответом на первый вопрос явилась схема работы по другому фронту клока, что дает некоторый запас по времени. 3. Двигая время выставления данных на другой фронт, осталось желание сохранить устойчивость схемы, например на тот момент если потом ножки будут в правильно месте. Поэтому захотелось ввести гарантированную задержку на линию выставления данных, чтобы сдвинуть момент появления данных поближе к правильному фронту клока. И вот тут выяснилось что легко констрейнами такое колдунство не сотворить, и как попросить синтезатор задержать сигнал не знаю даже опытные гуру. Ну а дальше появилось мнение что инструмент в целом полезный, а вот где он лежит никто не знает. И если вы уважаемая засада нас научите будет вам почет и уважение! Выводы: 1. На текущий момент схема работает на 50 МГц, чтение - запись (все переведено на восходящий клок), и теперь правильность ее работы также подтверждена констрейнами а не только эксперементами. Жаль не удалось все же минимальную задержку как-то определить, но чтение отчета синтезатора говорит о том что там все хорошо с этим моментом. Придется за ним следить пока что в ручном режиме. 2. Ковыряние, и обсуждение казалось бы уже очевидных вещей, лично мне дало еще несколько решений, интересных с разных точек зрения. Потому я крайне благодарен всем кто активно участвовал в теме и тем кто пробегая мимо кидал реплики. Уверен что все внесли свой вклад и сделали мир лучше. И надеюсь еще кому - то мой опыт будет полезен и интересен. 3. Ну и на последок не стоит сдаваться раньше времени, даже не клоковые ноги можно использовать как клок
|
|
|
|
|
|
|
|
Jan 8 2014, 06:44
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(ZASADA @ Jan 8 2014, 01:54) а чего бунтовать? уже 5 страниц темы, а лично мне не понятно,в чем проблема. на запись все работает, значит вполне спокойно на 50 МГц работает неспециализированная нога в качестве входа тактового сигнала. А то, что при чтении на 1 такт все сдвигается и с симулятором не совпадает - так это возможно надо схему чтения менять, а не констрейны. Да вот пример конкретной проблемы, в рамках другой темы, где требуется точно это же. Читать внимательно надо. Так что много где требуется обконстрейнить hold time, а не только в данном конкретном SPI, а еще например на PCI. Заметьте, не всем, как Вам, надо "в чем проблема, работает", а некоторым, особо въедливым, нужно еще и гарантированное соответствие спецификациям в полном диапазоне температур и питаний, а не только "здесь и сейчас". Для этого придуманы констрейны. И, еще, между прочим, использование входа, не предназначенного для клока, в качестве клока - смягчает в данном случае эту проблему, так как удлиняет путь сигнала, тем самым увеличивая запас по HOLD. А если бы клок был бы на месте - то констрейн на HOLD был бы нужен вдвойне. А "выводы" в корне неверные. Так как нет гарантии, что этот же контроллер заработает и при -20, и при 1.25 вольт вместо 1.2, и при оказавшимся по разбросу технологии особо быстром в районе этих пинов и логики экземпляре ПЛИС. Для чего и существуют констрейны, и их проверка на разных углах температуры, питания и процесса. Пожалуй, создам отдельную тему в нужном разделе - http://electronix.ru/forum/index.php?showtopic=117942 - все таки это общий вопрос, касающийся огромного числа применений ПЛИС вообще, а не конкретного случая SPI.
|
|
|
|
|
|
|
|
Jan 8 2014, 08:14
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(ZASADA @ Jan 8 2014, 12:09) в данном случае проблема была в неверной схемотхнике. Я уже написал выше, что эта "неверная схемотехника" в данном случае только улучшает ситуацию с HOLD, задерживая клок, и увеличивая запас по нему (холду). И как раз по ее причине, возможно, его констрейнить и не обязательно. Но в общем случае, для любого интерфейса, констрейнить надо и сетап, и холд, какая бы схемотехника не была, чтобы быть уверенным, что интерфейс соответствует спецификации.
|
|
|
|
|
|
|
|
Jan 8 2014, 08:30
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(ZASADA @ Jan 8 2014, 12:28) с вашим PCI это никак не связано, две совершенно разные ситуации. Это так кажется, что не связано, если подходить к делу кое-как - "работает, и ладно". А на самом деле связано - для любого интерфейса есть требования по Tsu и Th, в т.ч. и для SPI тоже, и наличие этого требования никак не связано с тем, куда заведен клок. Оно просто есть, и его надо описывать в констрейне. А колдовать уже с правильностью и неправильностью подключений следует по результатам отчета анализатора таймингов, как по запасу по Tsu, так и по запасу по Th. Все остальное, это любительская мышиная возня, а не работа.
|
|
|
|
|
|
|
|
Jan 8 2014, 09:17
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(ZASADA @ Jan 8 2014, 12:28) проблема была не в том, что тактовый сигнал приходил не на специализированную ногу, а в работе по фронту/срезу, что увеличивало эквивалентую частоту работы в 2 раза с 50 до 100 МГц.
с вашим PCI это никак не связано, две совершенно разные ситуации. Приход клока не на клоковую ногу вызывало задержку в проведении клока 8 нСек. Это не давало возможность выставить выходной сигнал по падающему фронту до появления следующего восходящего. Между этими событиями проходит 10 нСек, а сигнал появлялся за 12 нСек. Это привело к сдвигу данных на 1 бит, во время фронта захватывалось прошлое значение бита, а менялось оно после. Более того этот бит был не постоянным, он плавал, иногда бит успевал выставиться иногда нет. Приди нога на клоковую всего этого бы не было. Можно ли в такой ситуации считать что "проблема не в том что сигнал приходит на не специализированную ногу"? Мне кажется нет. А вот для решения данной проблемы потребовались констрейны, которые породили вторую проблему. А именно как сделать холд. Судя по сайту ксалинкса надо использовать IODELAY которые как раз и могут создать правильный холд, но как в точности это делается я пока не знаю.
|
|
|
|
|
|
|
|
Jan 8 2014, 09:28
|
Lazy
Группа: Свой
Сообщений: 2 070
Регистрация: 21-06-04
Из: Ukraine
Пользователь №: 76
|
Цитата(ZASADA @ Jan 8 2014, 11:28) а в работе по фронту/срезу, что увеличивало эквивалентую частоту работы в 2 раза с 50 до 100 МГц. Одно из заблуждений. Сделайте что-то простое... регистр сдвига с логикой между разрядами для обоих случаев - нормальное и "двойное" тактирование (1-разряд - фронт, 2 - срез, 3 - фронт и т.д.) И запустите спидометр и посмотрите на макс. частоту.
--------------------
"Everything should be made as simple as possible, but not simpler." - Albert Einstein
|
|
|
|
|
|
|
|
Jan 8 2014, 09:40
|

Местный
Группа: Свой
Сообщений: 426
Регистрация: 23-02-12
Пользователь №: 70 424
|
Цитата(Golikov A. @ Jan 2 2014, 22:06) Всем привет! Волею судеб так получилось что spi клок пришелся на не клоковый вход. Чем грозит использование его в конструкциях вида Код always @(posedge clk_pin)
begin
end ? Ограничением максимально реализуемой частоты SPI... больше ничем....
|
|
|
|
|
|
|
|
Jan 8 2014, 14:55
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Честно не хрена не знаю про свой процессор В целом угнетает что времянка SPI вообще не указана, написано по падающему данные ставьте, по восходящему защелкивайте. Больше в мануале времянки я не нашел, это LPС1768. Скорее всего он действительно с 0 задержкой, но люблю что-то более надежное чем скорее всего. Слово проблема стоит понимать не в значении затруднение, а в значении задача. Глобально я хотел знать что если вдруг по каким то причинам нужно использовать как клок сигнал с не клокового входа что для этого надо сделать. Почему бытует мнение что этого делать нельзя, что это кончиться геморроем, что так никто не делает (см. первые ответы в теме)? Ответом для себя на данный момент считаю что все можно, никаких ограничений кроме частотных нет, и всего только надо правильно описать констрейны и следить за тем чтобы они сошлись. И последние по поводу ноги и проблемы. Мануал говорит выставляем данные по падающему клоку. Я так сделал и данные не успели к поднимающемуся, проверив время в конкретной ситуации я понял что если ставить данные по другому фронту, то с задержкой данные придут как раз на тот фронт что надо. Это кстати приводит к тому что первый бит должен стоять еще до появления клоков. Потом все мы знаем что в зависимости от разводки, ровно как и от условий эксплуатации время может плавать, так что такой переход не совсем равнозначный и безопасный. Другими словами решением проблемы было усложнение автомата и осознанное нарушение мануала, приводящее к правильному результату. Не думаю что схему можно считать не верной если она выполняет мануал. Так что проблема все же в пине. И SМ прав, я в этой теме пытался уйти от частности, потому и не говорил на какую ногу заведен клок, и сигнал, и какой кристалл. Нет смысла столько сил тратить на конкретную ситуацию, это как бы исследование в целом!
|
|
|
|
|
|
|
|
Jan 8 2014, 15:12
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 8 2014, 18:55) В целом угнетает что времянка SPI вообще не указана, Еще как указана. tSPIDSU SPI data set-up time 0 ns tSPIDH SPI data hold time 2*Tcy(PCLK)-5 ns Так что у Вас как раз то сетап нулевой, с ним можно не париться. А вот HOLD - всем холдам холд. ЗЫ Tspicyc = 79.6 нс, а это 12.563 Мгц. Какие вообще 100 МГц или 50 МГц могут быть? Знаете, до чего разгон доводит? Попробуйте спросить Шумахера :D
|
|
|
|
|
|
|
|
Jan 8 2014, 15:19
|
Местный
Группа: Свой
Сообщений: 462
Регистрация: 20-01-06
Пользователь №: 13 399
|
Цитата(Golikov A. @ Jan 8 2014, 18:55) Честно не хрена не знаю про свой процессор Ну почему же ничего? стр. 62 - 64 стр. 29 Maximum SPI data bit rate of 12.5 Mbit/s (и какие тут 25,50, 100 MHz ??) кстати они не зря упоминают 100MHz системную частоту, поскольку внутренний контроллер _очевидно_ не использует SPI CLK как тактовую частоту, а выделяет фронты И ошибки Ваши в данных в направлении "FPGA" -> "проц" очевидно связаны с тем что вы "загнали" частоту SPI в 2-4 выше раза разрешенной, и контроллер в LPC уже перестает корректно работать
|
|
|
|
|
|
|
|
Jan 8 2014, 17:14
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(ZASADA @ Jan 8 2014, 21:05) не констрейнить надо что ни поподя, а нормальную архитектектуру прорабатывать и реализовывать. Маловато Вы ASIC-ов видимо делали. Одно другому не мешает. Надо делать И то, И это. 100% покрытие констрейнами сигналов с важными времянками также необходимо, как и правильная архитектура. Не надо путать две совершенно разные вещи - выполнение констрейна - это ГАРАНТИЯ работоспособности, гарантия полученная от разработчика архитектуры (будь то ПЛИС, будь то заказная ИМС). И полученная в виде отчета STA без отрицательных слаков. Необконстрейненный путь - отсутствие какой либо гарантии по этому пути - Вы интуитивно думаете, что там все ОК, потому что там "якобы правильная архитектура", а на самом деле, хрен его знает что там, так как не описано ограничение, недра синтезатора/плейсера/роутера - потемки. Архитектура архитектурой, само собой грамотность архитектуры вещь необходимая, но она не отменяет того, что все пути, для которых заданы какие либо временные ограничения, должны быть обконстрейнены по Tsu/Th, повторю, лишь для того, чтобы получить гарантию их выполнения. ДАЖЕ, если архитектурно продумана задержка какими-то синхронными методами, то все равно, стопроцентно, требуются констрейны на такие выходы, просто скорректированные на что-то там, что сделано архитектурно (вдруг синтезатор, руководствуясь чем-то там своим, возьмет, и пустить после всех "архитектур" сигнал по какому-то одному ему известному кривому пути, надо ему запретить это делать, указав жесткие рамки времени). Так что, одно другому не мешает, но констрейны обязательны это надо принять как аксиому для любого входа или выхода, для которого по задаче имеются какие либо временнЫе рамки. Ну да ладно... Собственно истинные причины проблем ТС найдены, а что либо объяснять привыкшим к работе на основе "русского авось" дело неблагодарное.
|
|
|
|
|
|
|
|
Jan 8 2014, 17:34
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Да ваша правда есть данные что радует. Чего то я забыл про даташит.
Но там же
Maximum SSP speed of 50 Mbit/s (master) or 8 Mbit/s (slave)
так что в мастере все ок, никакого переразгона, все в рамках мануала. Именно потому и корячусь в слэйв режиме, как вы сами понимаете в мастер режиме (со стороны ПЛИС, где АРМ слэйв) проблем с SPI клоком не было бы.
Повторю еще раз. Основная проблема в долгом пути клока от ноги до буфера, из за того что не та нога как ввода использована. После написания правильных констрейнов и понимания что они не выполняются по падающему клоку, переноса на поднимающий и выполнения констрейнов там все ЗАРАБОТАЛО!
Неужели похоже что так долго ковырясь в столь "мелком" вопросе я мог не глядя запустить проц в запредельном режиме?
П.С. почитав еще раз я так понял LPC под SPI понимают реализацию от моторолы, а просто данные по клокам они зовут SSP. И вот для него как раз есть только один параметр установка данных до клока, да и тот измерен в SPI режиме... эх... или я опять чего то упустил?
Интересно что и в SPI режиме для входных данных от слэйва указано что данные до падающего фронта могут быть выданы за 0 нСек, и быть валидны после него 2 клока - 5 нСек, то есть на самом деле для клока 50 МГц это значит что они должны до 5 нСек после клока стоять... С этим даташитом стало еще меньше все понятно блин...
|
|
|
|
|
|
|
|
Jan 8 2014, 17:50
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 8 2014, 21:34) Но там же
Maximum SSP speed of 50 Mbit/s (master) or 8 Mbit/s (slave)
так что в мастере все ок, никакого переразгона, все в рамках мануала. Нет, не ОК - нарушаете Tspicyc, который в таблице 18 дан в общей части таймингов SPI, относящейся как к мастеру, так и слейву. Так что, 50 мбит/с в фичах - это, видимо, досадная опечатка вследствие copy/paste какого нибудь. Как и 8 в слейве, кстати. Так что, разрешенный максимум у него 12,563 мбит/с как в мастере, так и в слейве (1/79.6 нс). Цитата(ZASADA @ Jan 8 2014, 21:38) на ASIC такой роскоши нельзя себе позволить. Вот и не надо к этому на FPGA привыкать. Вредно.
|
|
|
|
|
|
|
|
Jan 8 2014, 18:11
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
если читать огромный мануал там все сходиться с даташитом.
в мастере делитель не меньше 2 (причем только четные числа), в слейве не меньше 12. Вот и получается 50 для мастера и 8 для слейва. И это повторяется много где, так что не опечатка.
Просто это не SPI, в котором, кстати и мастер и слэйв режим работают по одной времянке. Это SSP а он как-то скудно описан. Может он для своих%)?
Но по осциллографу все как по картинкам, и на 50 МГц работает четко (в одну сторону гарантированно проверены), контрольные суммы сходятся данные правдоподобны. В обратную похоже тоже. Сейчас гоняю тесты памяти (память с доступом по SPI), похоже тоже все неплохо...
Кстати и делитель и регистр доступа один у входа и выхода, так что передавая на 50 МГц, он и принимает на них же. Запустить на разной скорости не реально. Наиболее вероятно что захват идет четко по фронту с 0 холдом, вот они ни про что и не стали писать. Потому что меня данные по падающему фронту, они будут к поднимающемуся. Ну глупо делать что-то что на 50 МГц работает, а шевелит данными еле еле....
|
|
|
|
|
|
|
|
Jan 8 2014, 19:39
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Цитата(Golikov A. @ Jan 8 2014, 23:25) Если вы вразумительно объясните в чем разница между SSP и SPI буду рад. Я так понял вопрос только названий. Это просто два совершенно разных блока с разной внутренней схемой и функциональностью, разным управлением, и т.д. В одной и той же микросхеме может быть несколько блоков SPI0/1/2 и SSP0/1/2. режим SPI у SSP это всего лишь один из режимов (там еще microwire, и SSI с хитрой фрейм-синхронизацией), а у блока SPI - он единственный. Короче, просто два совершенно разных блока, один из которых (SSP) может тоже, как и SPI, работать в режиме SPI. Но, так как эти блоки совершенно разные, и друг с другом не связанные, времянки у них естественно у каждого свои. Возможно, там и разработчики у SPI и SSP совершенно разные, и каждый, например, пишет как ему нравится. Да сами сравните - главы 17 и 18 мануала http://www.ru.nxp.com/documents/user_manual/UM10360.pdf
|
|
|
|
|
|
|
 |
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|






























 Чиркану письмецо, с меня не убудет, а там поглядим, но думаю глухо будет...
Чиркану письмецо, с меня не убудет, а там поглядим, но думаю глухо будет...