| |
 Коды БЧХ Коды БЧХ, Вопросы по алгоритмам декодирования |
|
|
|
|
 Sep 22 2010, 05:44 Sep 22 2010, 05:44
|
Вечный ламер

Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453

|
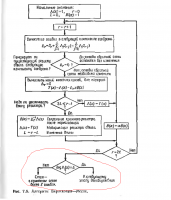
Гуру кодирования, просвятите по теме Потребовалось мне для проекта сделать БЧХ декодер работающий в поле GF(2), реализовал его по алгоритму Берлекэмпа-Месси приведенному на рисунке. Мне интересно, чем определяется необходимость последней проверки алгоритма перед процедурой Ченя(на рисунке выделено)? Ведь для бинарных БЧХ кодов четные невязки всегда будут равны нулю, а на нечетных проходах, по блок-схеме алгоритма, мы всегда попадаем на изменение длинны и степени полинома локатора ошибок. Т.е. эта проверка ничего не определяет. Тогда зачем она нужна? Или такая ситуация возможна только для не бинарных кодов? И вопрос по алгоритму Евклида. Во всех книгах написано что он лучше подходит для аппаратной реализации, чем алгоритм Берлекэмпа-Месси, из-за своей регулярной структуры. Но один из шагов алгоритма деление полинома на полином. В железе же это делается с помощью регистров с линейными обратными связями, что приводит к многотактному делению и появлению лишних задержек, что ИМХО не айс. Так в чем же его преимущество перед алгоритмом Берлекэмпа-Месси ? Спасибо.
Эскизы прикрепленных изображений
--------------------
|
|
|
|
|
|
11 страниц  1 2 3 > »
1 2 3 > »
|
 |
Ответов
(1 - 99)
|
|
Sep 22 2010, 06:22
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(vadimuzzz @ Sep 22 2010, 00:13)  1. да, для двоичных кодов БЧХ процедура проще, четные итерации можно пропустить. если эта картинка из Блейхута, то в главе 7.6 есть подробности. т.е. для двоичных кодов последнюю проверку (if deg(Lambda) == L) можно отбросить? Цитата 2. в той же книге про алгоритм Евклида говорится: "считается, что он менее эффективен в практическом использовании"  а вот Сарагоса с Кларком говорят что наоборот, для железа Евклид самое то. Вот мне и интересно почему %)
--------------------
|
|
|
|
|
|
|
|
Sep 22 2010, 10:44
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Sep 22 2010, 10:44) 1. неисправимую ошибку можно детектировать в процедуре ченя, когда количество найденных корней не совпадет с порядком локатора ошибок. Только для укороченных кодов. В остальных случаях Чень перебирает все элементы поля и среди них обязательно найдутся все корни полинома. Цитата 2. написал на сях алгоритм (на основе сорцов из сети), при количестве ошибок больше чем можно исправить дает выполнение этого равенства. Поэтому меня и заинтересовал этот момент. Чую что здесь что то не то (хотя может быть я просто в алгоритме ошибся %)).
UPD. Вот я ламер, неисправимая ошибка и количество неисправимых ошибок это же разные вещи %) Если я сделал правильные умозаключения, то для двоичных кодов эта проверка не нужна, т.к. для этих кодов ветка 2L > r-1 никогда не выполняется. Поэтому степень полинома локаторов изменяется одновременно с L. Эта проверка редко, но срабатывает. Степень не всегда меняется одновременно с L. Помоделируйте декодер и поймаете такую ситуацию.
|
|
|
|
|
|
|
|
Sep 22 2010, 16:03
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(SKov @ Sep 22 2010, 04:44) Только для укороченных кодов. В остальных случаях Чень перебирает все элементы поля и среди них обязательно найдутся все корни полинома. Вот что странно, я использовал в качестве базы пример Код * Title: Encoder/decoder for binary BCH codes in C (Version 3.1)
* Author: Robert Morelos-Zaragoza там используется следующий алгоритм ченя Код // put elp into index form
for (i = 0; i <= L; i++)
elp[i] = index_of[elp[i]];
printf("sigma(x) = ");
for (i = 0; i <= L; i++)
printf("%3d ", elp[i]);
printf("\n");
printf("Roots: ");
// Chien search: find roots of the error location polynomial
for (i = 1; i <= L; i++)
reg[i] = elp[i]; // промежуточная переменная, локаторы в индексной форме
count = 0; // считаем реальное количество корней
for (i = 1; i <= n; i++) { // осуществляем полный перебор по всем словам для поиска корней локатора ошибок
q = 1; // индексы корней уравнения локаторов ошибок определяют местоположения ошибок
for (j = 1; j <= L; j++)
if (reg[j] != -1) { // перемножение
reg[j] = (reg[j] + j) % n; // умножение на alpha^(-i*k)
q ^= alpha_to[reg[j]]; // делаем сложение в полиномиальной форме
}
if (!q) { // получили 0, значит искомое число есть корень уравнения
// store root and error location number indices
root[count] = i; // сохраняем индекс корня
loc[count] = n - i; // вписываем местоположение конретной ошибки (она обратная индексу корня)
count++;
printf("%3d ", n - i);
}
}
printf("\n");
if (count == L) // если счетчик корней равен степени полинома локаторов ошибок
// no. roots = degree of elp hence <= t errors
for (i = 0; i < L; i++)
recd[loc[i]] ^= 1;
else // elp has degree > t hence cannot solve
printf("Incomplete decoding: errors detected\n"); В атаче сишный файл реализации (15,5,7) двоичного кодера. Если я правильно понял теорию это код максимальной длинны. В примере задаются 4 битовые ошибки, которые кодер не может исправить. В этом случае deg(Lambda) == 3, L == 3. Алгоритм Берлекэмпа-Месси не находит предпосылок к невозможности декодирования. Выясняется это только в процедуре Ченя, когда сравнивается количество найденых корней (count == 0) со степенью полинома локатора ошибок == длине LFSR регистра. При этом не находится ни одного корня, тогда как по вашим словам корни быть обязаны  В атаче модифицированный файл, оригинальный файл был взят здесь Цитата Эта проверка редко, но срабатывает. Степень не всегда меняется одновременно с L.
Помоделируйте декодер и поймаете такую ситуацию. спасибо, соберу рандомно/переборный тест и проверю.
Прикрепленные файлы
 bch.zip
bch.zip ( 7.17 килобайт )
Кол-во скачиваний: 138
--------------------
|
|
|
|
|
|
|
|
Sep 22 2010, 17:58
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Sep 22 2010, 20:03) При этом не находится ни одного корня, тогда как по вашим словам корни быть обязаны Да, похоже, что Акела промахнулся. Я, кажется, погорячился. Полином локаторов, в случае превышения максимального числа ошибок, совсем не обязан иметь ВСЕ корни в этом поле. Звиняюсь.
|
|
|
|
|
|
|
|
Sep 28 2010, 07:26
|

Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(des00 @ Sep 27 2010, 17:21) Есть такой вопрос по реализации декодера для ПЛИС. Для декодирования нужно определить 2t синдромов, если считать синдромы классически(через таблицы), получается сильно жирно по ресурсу памяти. По любому должен существовать способ расчета синдромов с помощью сдвиговых регистров с обратными связями. Подскажите плиз где можно про это прочитать? В основных книгах информации об этом я не нашел.
Спасибо. Недавно сам занимался аппаратной реализацией такого декодера - вообщемто всё удачно получилось. Вот что я тогда нашёл по этой тематике: 1 - софтверная реализация и алгоритмы кодирования/декодирования 2 - аппаратная реализация декодера 3 - оптимизированный алгоритм Чейня 4 - реализация умножителей в поле Галуа (очень полезно) 5 - реализация декодера Рида-Соломона (очень похожа по струкруре блоков на БЧХ) 6 - ещё одна реализация декодера, но алгоритм SiBM тут с ошибкой (я делал RiBM) 7 - мегакнига по реализации кодов коррекции ошибок применительно к флэшкам 8 - готовая прожка кодирования/декодирования от микрона (по ней я отлаживался) h__p://depositfiles.com/files/zmz0ppjzi
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Sep 28 2010, 11:11
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(vadimuzzz @ Sep 27 2010, 09:31) поделить на aplha^i, i=1..2t спасибо всё красиво получилось, вычисление синдрома 3 строчки (ну и + строк 40 для функций). Хочу что бы все функции декодера считались на SV, потом может быть выложу в тему про батл AHDL vs SV %) Цитата(Mikhalych @ Sep 28 2010, 02:26) Вот что я тогда нашёл по этой тематике:
h__p://depositfiles.com/files/zmz0ppjzi спасибо за литературу %)
--------------------
|
|
|
|
|
|
|
|
Sep 28 2010, 11:57
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(x736C @ Sep 28 2010, 06:43) Сколько «жрет» ресурсов ваша реализация? как доделаю тогда будет ясно, т.к. я в этом деле ламер всё двигается медленно %) Цитата AHDL сравнивать с SV, мне кажется, неуместно. Языки разного поколения. AHDL разве объектно-ориентированный? да есть такая тема на форуме, если интересно в личку, не надо тут офтопить %)
--------------------
|
|
|
|
|
|
|
|
Sep 28 2010, 11:58
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(Mikhalych @ Sep 28 2010, 11:26) Недавно сам занимался аппаратной реализацией такого декодера - вообщемто всё удачно получилось.
....
6 - ещё одна реализация декодера, но алгоритм SiBM тут с ошибкой (я делал RiBM) Без обратного элемента - это хорошо, но не всегда подходит. Часто заказчик требует особо быстрого декодирования 1-2 ошибок, а там без обратного элемента не получается.
|
|
|
|
|
|
|
|
Sep 28 2010, 12:54
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(SKov @ Sep 28 2010, 15:58) Без обратного элемента - это хорошо, но не всегда подходит. Часто заказчик требует
особо быстрого декодирования 1-2 ошибок, а там без обратного элемента не получается. Я делал на 12 ошибок - алгоритм БМ без обратного элелемнта в GF(2^13) алгоритм RiBM вычислял коэф. за 24 такта, SiBM вычислил бы за 12 тактов, но чёто у меня не получилось его реализовать Для 1-2 ошибок Хемминг лучше
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Sep 28 2010, 13:02
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(x736C @ Sep 28 2010, 16:59) Вопрос ко всем. А вы память используете? нет - всё на логике и сдвиговых регистрах
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Sep 28 2010, 14:08
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(des00 @ Sep 28 2010, 17:53) ... использовали умножители в GF за такт? Да - за один такт. Сделаны на логике - для некоторых видов порождающих полиномов есть очень простое решение (статейку на эту тему я приводил) Цитата(des00 @ Sep 28 2010, 17:53) ЗЫ. Классический алгоритм БМ, приведенный у блейхута это RiBM или SiBM? У него iBM вроде =) Если сравнивать аппаратные затраты и скорость вычислений для этих 3х алгоритмов - то тут данные такие: t - исправляющая способность кода; GFA - сумматор в GF; GFM - умножитель в GF; MUX - мультиплексор; REG - регистр; Cycle - число тактов для вычисления коэф-тов iBM -> GFA: 2t+1 GFM: 3+3 REG: 4t+4 MUX: t+1 Cycle: 3t RiBM -> GFA: 3t+1 GFM: 6t+2 REG: 6t+2 MUX: 3t+1 Cycle: 2t SiBM -> GFA: 2t GFM: 4t REG: 2t+1 MUX: 2t Cycle: t
Сообщение отредактировал Mikhalych - Sep 28 2010, 15:24
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Oct 1 2010, 07:40
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Mikhalych @ Sep 28 2010, 07:54) алгоритм RiBM вычислял коэф. за 24 такта, SiBM вычислил бы за 12 тактов, но чёто у меня не получилось его реализовать либо я тупой, либо одно из двух  в статьях выложенных выше приведены 4 варианта алгоритма SiBM. Но все они разные. В целях пристрелки реализовал один в один 3 штуки ни один не работает(причем в одном алгоритме была ошибка). Детальное исполнение алгоритма на бумажке показывает что косяков в реализации нет, но алгоритм не работает %) Может быть у кого нить есть статья с описанием SiBM который приведен без ошибок? Спасибо.
--------------------
|
|
|
|
|
|
|
|
Oct 4 2010, 13:04
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(petrov @ Oct 4 2010, 06:10) ИМХО это нормальная ситуация, графики BER для кодированной и не кодированной модуляции пересекаются в области высокой вероятности ошибки, и не кодированная передача становится лучше, а в кодированной происходит размножение ошибок, шум превышает расстояние евклида или хемминга до границы принятия решения и декодер начинает принимать за истинные другие кодовые слова. то что ситуация обычная это понятно, но ведь должен же существовать какой то способ, для определения того, что ошибок больше чем корректирующая способность(t)? На степень полинома локаторов надежды нет, т.к. он, алгоритмически ограничен t, поиск корней полинома тоже может дать сбой (как в этом примере). Вот мне и интересно, как определить что ошибок больше чем нужно и выдать сигнал decfailed, вместо мусора %) По идее можно бы воспользоваться свойством вырождения матрицы синдромов, но считать детерминант на лету, не есть гуд. Еще нашел в блейхуте что можно вычислить спектр кода, но вот пока еще неясно как и даст ли это результат.
--------------------
|
|
|
|
|
|
|
|
Oct 4 2010, 13:10
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(des00 @ Oct 4 2010, 17:04) Вот мне и интересно, как определить что ошибок больше чем нужно и выдать сигнал decfailed, вместо мусора %) может CRC считать?
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Oct 4 2010, 13:17
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Mikhalych @ Oct 4 2010, 07:10) может CRC считать? это для протокола более высокого уровня, мне нужно другое %) Цитата(des00 @ Oct 4 2010, 07:04) По идее можно бы воспользоваться свойством вырождения матрицы синдромов, но считать детерминант на лету, не есть гуд. да и не получится так, потому что синдром по определению определен на множестве элементов alpha^1 ...alpha^2t.
--------------------
|
|
|
|
|
|
|
|
Oct 4 2010, 13:19
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(des00 @ Oct 4 2010, 17:11) это для протокола более высокого уровня, мне нужно другое %) а если сделать декодер на t+1 ошибку... и если ошибок t и меньше - то всё хорошо, а если t+1 - то недоверяем и говорим decfailed?
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Oct 4 2010, 13:30
|
Гуру
Группа: Свой
Сообщений: 2 220
Регистрация: 21-10-04
Из: Balakhna
Пользователь №: 937
|
Цитата(des00 @ Oct 4 2010, 17:04) то что ситуация обычная это понятно, но ведь должен же существовать какой то способ, для определения того, что ошибок больше чем корректирующая способность(t)? На степень полинома локаторов надежды нет, т.к. он, алгоритмически ограничен t, поиск корней полинома тоже может дать сбой (как в этом примере). Вот мне и интересно, как определить что ошибок больше чем нужно и выдать сигнал decfailed, вместо мусора %) ИМХО не должен, если только дополнительную избыточность на это тратить.
|
|
|
|
|
|
|
|
Oct 4 2010, 13:34
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Mikhalych @ Oct 4 2010, 07:19) а если сделать декодер на t+1 ошибку... и если ошибок t и меньше - то всё хорошо, а если t+1 - то недоверяем и говорим decfailed? тогда есть опасность не влезть в требуемую полосу пропускания и что делать если ошибок будет ну например t+5 ? Цитата(petrov @ Oct 4 2010, 07:30) ИМХО не должен, если только дополнительную избыточность на это тратить. хмм, неужели в и RS кодерах всё так же плохо. И даже проверка нулей спектра кода не поможет? ЗЫ. Мне сильно желательно диагностика такой ситуации для канала без явной синхронизации. Чтобы лучше работала система синхронизации. Подобное я делал на корке RS, но никогда не задумывался, до сего момента, что decfailed корки мне врал %(
--------------------
|
|
|
|
|
|
|
|
Oct 4 2010, 14:38
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(vadimuzzz @ Oct 4 2010, 09:22) как бы RS - это подмножество BCH да, но там недвочиные символы, если верить Блейхуту, то можно проверить все ли корректирующие символы из нужного алфавита. Цитата он не врал, ЕМНИП у этого сигнала вполне конкретный смысл, он показывает неисправимые ошибки, но не все. под врал я понимал то, что когда он не показывал decfail нельзя было однозначно сказать были ошибки или нет %) Подводя итог, как я понял бороть сей эффект бесполезно. Ну разве что расширить код добавив символ четности. Немного поможет %)
--------------------
|
|
|
|
|
|
|
|
Oct 4 2010, 15:46
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(GetSmart @ Oct 4 2010, 09:26) Разве этого недостаточно? Если вы про расширение кода, то еще не знаю. надо рыть литературу. Правда, из-за выбранной сетки частот, мне нужны фреймы 2**m-1. Если про тот код что есть, буду смотреть. Может быть устроит то что получилось. ЗЫ. Последний вопрос про бинарные БЧХ, неподскажите есть где нибудь внятное алгоритмическое описание получения генераторного полинома. Понятно что это НОК от примитивных полиномов членов поля, но как определяются эти примитивные полиномы? Разбирался с кодом с http://the-art-of-ecc.com/, даже портировал его в SV, но так до конца и не понял всех тонкостей алгоритма.
--------------------
|
|
|
|
|
|
|
|
Oct 4 2010, 16:54
|
Гуру
Группа: Свой
Сообщений: 2 220
Регистрация: 21-10-04
Из: Balakhna
Пользователь №: 937
|
Цитата(des00 @ Oct 4 2010, 20:32) А что еще дешево (с точки зрения ресурса) и качественно используется для малых размеров блока? (меньше 255 бит) Купить усилитель на 3 дБ мощнее %) Не знаю на счёт дёшево, но турбокоды явно больше дадут. Возможно TCM можно приспособить для коротких блоков, в гигабитном езернете что-то такое используется. Хотя бы мягкое декодирование БЧХ по алгоритму Чейза используйте. Цитата(Serg76 @ Oct 4 2010, 20:39) мало того, некоторые коды БЧХ используются в качестве компонентных при построении блоковых турбокодов Это да TPC мощные коды.
|
|
|
|
|
|
|
|
Oct 4 2010, 18:59
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Oct 4 2010, 20:32) странно, в блейхуте, сарагосе и т.д. написано что для малых размеров блока БЧХ коды близки к оптимальным %) Да и в стандарте dvbs от них не отказываются %)
А что еще дешево (с точки зрения ресурса) и качественно используется для малых размеров блока? (меньше 255 бит) БЧХ коды нормально работают, если от них не требовать больше, чем они могут дать. Если вы квантуете канал с АБГШ, то на БЧХ кодах вполне реально получить 3..5 дБ ЭВК даже при декодировании только двичных ошибок в дискретном канале. Вообще, если есть ДСК, то БЧХ близки к лучшим кодам. Известно, что примитивные БЧХ, исправляющие 2 ошибки, квазисовершенны. Для длин больше 1000 вообще трудно что-то приличнее придумать для ДСК. Но это все в дискретном канале. А вот если у вас есть непрерывный выход, то ситуация кардинально меняется. Конечно, и в этом случае можно использовать декодер БЧХ для ДСК, применяя алгоритмы Чейза или декодирование по МОР (Форни.) Но много там не получишь (обычно в пределах 1.5...2 дБ дополнительного выигрыша к ЭВК дискретного канала). Но для длин <100 это все равно надо делать и это будет хорошо. А вот если длина хотя бы несколько сотен (а лучше - тысяч), то ситуация совсем другая. Тут уже начинают блистать LDPC коды. Турбо-коды были модны лет 10 назад, но в последнее время их пододвинули LDPС. Тот же стандарт DVB -хх использует именно LDPC с дурацкой примочкой из внешнего БЧХ-кода. Так что определитесь, какие у вас ограничения на канал и сложность декодера, и выбирайте лучший вариант из большого многообразия конструкций кодов и декодеров.
|
|
|
|
|
|
|
|
Oct 5 2010, 02:39
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(petrov @ Oct 4 2010, 10:54) Купить усилитель на 3 дБ мощнее %) Это точно не пойдет Цитата Не знаю на счёт дёшево, но турбокоды явно больше дадут. Возможно TCM можно приспособить для коротких блоков, в гигабитном езернете что-то такое используется. я сильно ограничен по ресурсам, у меня на кодер/декодер есть около 1000 плиток(чем меньше, тем лучше). Мне нужно два декодера {255,233,4} на 200Мб/с и {127, 64, 10} на 2Мб/с. ИМХО на таких длинах TCM/LDPC и т.д. это как из пушки по воробьям. Цитата(SKov @ Oct 4 2010, 12:59) Конечно, и в этом случае можно использовать декодер БЧХ для ДСК, применяя алгоритмы Чейза или декодирование по МОР (Форни.) Цитата Хотя бы мягкое декодирование БЧХ по алгоритму Чейза используйте. Доделаю жесткое, комитнусь и порою книги на эту тему %) Цитата Так что определитесь, какие у вас ограничения на канал и сложность декодера, и выбирайте лучший вариант из большого многообразия конструкций кодов и декодеров. вроде как выбрал, надеюсь не прогадал %) ЗЫ. А по определению примитивных полиномов можете что нить подсказать? Спасибо %)
--------------------
|
|
|
|
|
|
|
|
Oct 5 2010, 07:29
|
Гуру
Группа: Свой
Сообщений: 2 220
Регистрация: 21-10-04
Из: Balakhna
Пользователь №: 937
|
Цитата(des00 @ Oct 5 2010, 06:39) я сильно ограничен по ресурсам, у меня на кодер/декодер есть около 1000 плиток(чем меньше, тем лучше). Мне нужно два декодера {255,233,4} на 200Мб/с и {127, 64, 10} на 2Мб/с. ИМХО на таких длинах TCM/LDPC и т.д. это как из пушки по воробьям. В эзернете ограниченный бюджет задержки и там используется специальный TCM код с маленькой задержкой декодирования. Можно использовать TPC на основе расширенного БЧХ(16,11,4), длина блока 256, скорость 11^2/16^2, выигрыш около 5 дБ, ещё лучше на основе БЧХ(32,26,4), выигрыш около 6.5 дБ. По ресурсам не влезет конечно, но получить приличный выигрыш на относительно коротких блоках можно.
|
|
|
|
|
|
|
|
Oct 5 2010, 08:25
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(petrov @ Oct 5 2010, 02:29) В эзернете ограниченный бюджет задержки и там используется специальный TCM код с маленькой задержкой декодирования. Можно использовать TPC на основе расширенного БЧХ(16,11,4), длина блока 256, скорость 11^2/16^2, выигрыш около 5 дБ, ещё лучше на основе БЧХ(32,26,4), выигрыш около 6.5 дБ. По ресурсам не влезет конечно, но получить приличный выигрыш на относительно коротких блоках можно. Ничего себе я ошибался  , а ссылками/названиями/литературой по этим кодерам не поделитесь? Спасибо.
--------------------
|
|
|
|
|
|
|
|
Oct 5 2010, 09:18
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(petrov @ Oct 5 2010, 12:41) Книгу Channel_Coding_in_Communication_Networks_-_ Glavieux.pdf выкладывал уже, есть у вас? Я почему-то не видел этот документ. Вас не затруднит его куда-нибудь выложить? На Рапидшаре он уже "протух". Цитата Там сам изобретатель TPC Pyndiah главу по ним написал Изобретатель? 
|
|
|
|
|
|
|
|
Oct 5 2010, 09:38
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Oct 5 2010, 13:30) тут Спасибо. Извините, забыл про ваш вопрос. Интересующие Вас минимальные многочлены можно взять из таблицы в конце книжки Питерсона и Уэлдона. Она есть в и-нете.
|
|
|
|
|
|
|
|
Oct 5 2010, 10:20
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(petrov @ Oct 5 2010, 13:34) Изобретатель изобретатель Он сам себя таковым не считает. Посмотрите введение к его главе. Он там справедливо упоминает и Хагенауэра и "многих других исследователей". Very quickly many researchers, such as Hagenauer,
Benedetto, Divsalar [HAG 96, BEN 96, DIV 95, ROB 94, WIB 95] and a number of
others confirmed the results of Berrou and within a few years the turbocode became
essential in the field of the error corrector coding as the 21st century solution.Это правильно. Другое дело, что эти западники никогда (почти) не упоминают наши отечественные исследования в этой области. Как-будто это не в нашей стране была одна из лучших школ теории информации и кодирования. Это касается и блоковых турбокодов на основе расширенных кодов Хемминга. Вот здесь, например, есть по крайней мере две статьи с описанием кодирования - декодирования и результатов моделирования таких турбокодов (это 1995год). Правда, у этого Pyndiah-а есть ссылка на тезисы конференции 1994 года. Ну, значит он был первый  Тогда интернет был в зачаточном состоянии, ездили на конференции мало, и информация распространялась медленно. Как пишут в таких случаях "результаты были получены независимо и почти одновременно". Просто за державу обидно
|
|
|
|
|
|
|
|
Oct 5 2010, 12:22
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(des00 @ Oct 5 2010, 00:15) UPD. Конечно можно сгенерить всё в матлабе и копипастом перенести в код. Но интересно написать функции генерации кода БЧХ на SV, которые будут определять всю структуру (все функции кроме генерации генераторного полинома на SV есть и работают, ква таки сила), чтобы не зависеть ни от каких генераторов. сорцы выложены тут автоматическое определение генераторного полинома еще не допилил %) Цитата(SKov @ Oct 5 2010, 04:38) Спасибо.
Извините, забыл про ваш вопрос. Интересующие Вас минимальные многочлены можно
взять из таблицы в конце книжки Питерсона и Уэлдона. Она есть в и-нете. вот что странно, в Си коде, который я приводил функция генерации генераторного полинома CODE
void gen_poly()
/*
* Compute the generator polynomial of a binary BCH code. Fist generate the
* cycle sets modulo 2**m - 1, cycle[][] = (i, 2*i, 4*i, ..., 2^l*i). Then
* determine those cycle sets that contain integers in the set of (d-1)
* consecutive integers {1..(d-1)}. The generator polynomial is calculated
* as the product of linear factors of the form (x+alpha^i), for every i in
* the above cycle sets.
*/
{
register int i, ii, jj, ll, kaux;
register int test, aux, nocycles, root, noterms, rdncy;
int cycle[1024][21], size[1024], min[1024], zeros[1024];
/* Generate cycle sets modulo n, n = 2**m - 1 */
cycle[0][0] = 0;
size[0] = 1;
cycle[1][0] = 1;
size[1] = 1;
jj = 1; /* cycle set index */
if (m > 9) {
printf("Computing cycle sets modulo %d\n", n);
printf("(This may take some time)...\n");
}
do {
/* Generate the jj-th cycle set */
ii = 0;
do {
ii++;
cycle[jj][ii] = (cycle[jj][ii - 1] * 2) % n;
size[jj]++;
aux = (cycle[jj][ii] * 2) % n;
} while (aux != cycle[jj][0]);
/* Next cycle set representative */
ll = 0;
do {
ll++;
test = 0;
for (ii = 1; ((ii <= jj) && (!test)); ii++)
/* Examine previous cycle sets */
for (kaux = 0; ((kaux < size[ii]) && (!test)); kaux++)
if (ll == cycle[ii][kaux])
test = 1;
} while ((test) && (ll < (n - 1)));
if (!(test)) {
jj++; /* next cycle set index */
cycle[jj][0] = ll;
size[jj] = 1;
}
} while (ll < (n - 1));
nocycles = jj; /* number of cycle sets modulo n */
/*
printf("Enter the error correcting capability, t: ");
scanf("%d", &t);
*/
t = 3;
d = 2 * t + 1;
/* Search for roots 1, 2, ..., d-1 in cycle sets */
kaux = 0;
rdncy = 0;
for (ii = 1; ii <= nocycles; ii++) {
min[kaux] = 0;
test = 0;
for (jj = 0; ((jj < size[ii]) && (!test)); jj++)
for (root = 1; ((root < d) && (!test)); root++)
if (root == cycle[ii][jj]) {
test = 1;
min[kaux] = ii;
}
if (min[kaux]) {
rdncy += size[min[kaux]];
kaux++;
}
}
noterms = kaux;
kaux = 1;
for (ii = 0; ii < noterms; ii++)
for (jj = 0; jj < size[min[ii]]; jj++) {
zeros[kaux] = cycle[min[ii]][jj];
kaux++;
}
k = length - rdncy;
if (k<0)
{
printf("Parameters invalid!\n");
// exit(0);
return ;
}
printf("This is a (%d, %d, %d) binary BCH code\n", length, k, d);
/* Compute the generator polynomial */
g[0] = alpha_to[zeros[1]];
g[1] = 1; /* g(x) = (X + zeros[1]) initially */
for (ii = 2; ii <= rdncy; ii++) {
g[ii] = 1;
for (jj = ii - 1; jj > 0; jj--)
if (g[jj] != 0)
g[jj] = g[jj - 1] ^ alpha_to[(index_of[g[jj]] + zeros[ii]) % n];
else
g[jj] = g[jj - 1];
g[0] = alpha_to[(index_of[g[0]] + zeros[ii]) % n];
/*
printf("Generator polynomial:\ng(x) = ");
for (i = 0; i <= 31; i++) {
printf("%d", g[i]);
}
printf("\n");
*/
}
printf("Generator polynomial:\ng(x) = ");
for (ii = 0; ii <= rdncy; ii++) {
printf("%d", g[ii]);
if (ii && ((ii % 50) == 0))
printf("\n");
}
printf("\n");
}
явно показывает что никакие таблицы не используются. Все вычисления производятся на лету. Надо будет еще раз к ней подойти до полной ясности %)
--------------------
|
|
|
|
|
|
|
|
Oct 5 2010, 12:27
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(vadimuzzz @ Oct 5 2010, 15:51) в нашей стране проще ознакомиться с трудами IEEE, чем увидеть журналы типа того, что вы указали В 95-м году это было не так. Надо было одинаково идти в крупную библиотеку какого-нибудь крупного города. Это не журнал, это тезисы докладов научной конференции. Сейчас их не стоит и смотреть, поскольку прошло 15 лет, там все устарело. Это интересно разве что с точки зрения истории и приоритетов.
|
|
|
|
|
|
|
|
Nov 2 2010, 11:23
|
Группа: Новичок
Сообщений: 4
Регистрация: 28-01-10
Пользователь №: 55 123
|
А кто-нибудь сталкивался с алгоритмом на основе матрицы Вандермормонда? Мне он показался более практичным чем Форни для малых значений ошибок, но разобраться с ним у Сарагосы у меня не получилось.
|
|
|
|
|
|
|
|
Jan 19 2011, 09:57
|
Профессионал
Группа: Участник
Сообщений: 1 273
Регистрация: 3-03-06
Пользователь №: 14 942
|
Цитата(des00 @ Oct 4 2010, 16:34) ЗЫ. Мне сильно желательно диагностика такой ситуации для канала без явной синхронизации. Чтобы лучше работала система синхронизации. Подобное я делал на корке RS, но никогда не задумывался, до сего момента, что decfailed корки мне врал %( Ув. des00, Вы обеспечиваете синхронизацию декодера по доминирующим нулевым синдромам? Или я не в ту степь?! Цитата(Mikhalych @ Sep 28 2010, 16:02) нет - всё на логике и сдвиговых регистрах Буфер принятого слова для ожидания декодирования тоже на регистрах или в нем нет необходимости?
|
|
|
|
|
|
|
|
Jan 21 2011, 13:19
|
Профессионал
Группа: Участник
Сообщений: 1 273
Регистрация: 3-03-06
Пользователь №: 14 942
|
Цитата(des00 @ Jan 21 2011, 11:43) да именно так, но такое хорошо работает только на декодерах с большой исправляющей способностью (1/2, 3/4, 5/6, 7/8, 9/10) и большим размером блока. Для сабжевого конкретного случая я перешел на синхронизацию по шапочке. Спасибо. Знакомы ли Вы с многочисленными статьями а-ля «blind frame synch. of BCH»? В большинстве статей для синхронизации предлагается parity check matrix. Пытаюсь разобраться в особенностях популярных алгоритмов  Цитата(Mikhalych @ Sep 28 2010, 10:26) Недавно сам занимался аппаратной реализацией такого декодера...
...
8 - готовая прожка кодирования/декодирования от микрона (по ней я отлаживался) Правильно ли я понимаю, что программа использует исключительно укороченные коды? (”Number of data bits to be encoded. Must divide 4.“) Что кажется логичным, т.к. программа реализует защиту флеш-памяти.
|
|
|
|
|
|
|
|
Jan 22 2011, 21:12
|
Профессионал
Группа: Участник
Сообщений: 1 273
Регистрация: 3-03-06
Пользователь №: 14 942
|
Хорошо. Итак. Архив содержит следующие документы: Blind Frame Synchronization For Block Code.pdf
Blind Frame Synchronization And Phase Offset Estimation For Coded Systems.pdf
Blind Frame Synchronization For Error Correcting Codes Having a Sparse Parity Check Matrix.pdf
Blind frame synchronization of product codes based on the adaptation of the parity check matrix.pdf
Blind Frame Synchronization of Reed-Solomon Codes.pdf
Blind Frame Synchronization on Gaussian Channel.pdf
Blind_Frame_Synchronization.rar ( 1.37 мегабайт )
Кол-во скачиваний: 161Кое-что вынес за скобки. В принципе всё есть в инете. Из того, что очень интересно, но найти не удалось. http://elibrary.ru/item.asp?id=11532386Приведен пример реализации кодовой цикловой синхронизации для каскадного кода БЧХ(31,16) -
- Рида-Соломона(32,16), обеспечивающего надежную синхронизацию в канале связи с вероятностью
ошибки до 10^-1.http://elibrary.ru/item.asp?id=11520710Методы кодовой цикловой синхронизации и их применение для передачи сообщений в каналах связи
с вероятностью ошибки до 10^-1
|
|
|
|
|
|
|
|
Jan 12 2012, 06:46
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(petrov @ Oct 4 2010, 10:54) Хотя бы мягкое декодирование БЧХ по алгоритму Чейза используйте. Цитата(SKov @ Oct 4 2010, 12:59) Конечно, и в этом случае можно использовать декодер БЧХ для ДСК, применяя алгоритмы Чейза или декодирование по МОР (Форни.)
Но много там не получишь (обычно в пределах 1.5...2 дБ дополнительного выигрыша к ЭВК дискретного канала).
Но для длин <100 это все равно надо делать и это будет хорошо. Нашел время вернуться к БЧХ кодам и алгоритму Чейза. Есть несколько вопросов : 1. в книге Кларка, при описании алгоритма Чейза он пишет : Цитата Метод 2: взять в качестве векторов 1 множество из 2^d/2 векторов, имеющих всевозможные символы на d/2 наименее достоверных позициях и нулевые символы на остальных. Но нигде в книге нет ни слова, как определить какие символы наименее достоверные. Неужели предполагается выделять достоверность символов с помощью сравнения их квантованных амплитуд, считая что чем больше амплитуда (например для BPSK) тем символ достовернее ? 2. В разделе "8.1.3. Системы, использующие код Рида—Соломона и короткий блоковый код". Неужели такие системы использовались/используются? Всегда считал что наиболее подходящими для каскада являются блоковый и сверточные коды. 3. Прочитал у него же про многопороговое декодирование блоковых кодов. Правильно ли я понял, что при использовании того же БЧХ (15,5,7) и многопорогового декодера с мягким решением, выигрыш от кодирования будет больше чем при использовании арифметического БЧХ с Чейзом ? Спасибо.
--------------------
|
|
|
|
|
|
|
|
Jan 12 2012, 14:39
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Oct 1 2010, 10:40) либо я тупой, либо одно из двух в статьях выложенных выше приведены 4 варианта алгоритма SiBM. Но все они разные. В целях пристрелки реализовал один в один 3 штуки ни один не работает(причем в одном алгоритме была ошибка). Детальное исполнение алгоритма на бумажке показывает что косяков в реализации нет, но алгоритм не работает %) Может быть у кого нить есть статья с описанием SiBM который приведен без ошибок? Спасибо. Возникла та же проблема. Реализовал SiBM, вношу одну ошибку в КС. А декодер показывает что их две (вычисления приводят к полиному локаторов 2-й степени, Ченя соответственно решает и находит 2 корня). Считаю на бумаге все получается. Может где в алгоритме ошибка?
|
|
|
|
|
|
|
|
Jan 13 2012, 05:57
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(petrov @ Jan 12 2012, 03:28) Да. нда, все оригинальное просто Цитата(Gold777 @ Jan 12 2012, 09:39) Возникла та же проблема. Реализовал SiBM, вношу одну ошибку в КС. А декодер показывает что их две (вычисления приводят к полиному локаторов 2-й степени, Ченя соответственно решает и находит 2 корня). Считаю на бумаге все получается. Может где в алгоритме ошибка?
все алгоритмы в статьях рабочие, отличия только в деталях/индексах и т.д. реализации для плис всех этих алгоритмов для БЧХ/РС кодов я выкладывал в этой теме.
--------------------
|
|
|
|
|
|
|
|
Jan 13 2012, 09:45
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Jan 13 2012, 08:57) нда, все оригинальное просто все алгоритмы в статьях рабочие, отличия только в деталях/индексах и т.д. реализации для плис всех этих алгоритмов для БЧХ/РС кодов я выкладывал в этой теме. Если я работаю с записанным сигналом, прогоняю его через Моделсим алгоритм работает правильно. Если в реальном времени, вношу к примеру одну ошибку в чистый сигнал находится внесенная ошибка правильно, но помимо нее декодер находит определенную постоянную вторую ошибку на месте на котором ее быть не должно в каждом кодовом слове (соответственно полином локаторов имеет в данном случае вторую степень). Вот собственно такую ситуацию я наблюдаю в SignalTab. Такая же ситуация наблюдается при увеличении числа ошибок. Вот не пойму где ошибка то у меня?
Сообщение отредактировал Gold777 - Jan 13 2012, 09:47
|
|
|
|
|
|
|
|
Jan 16 2012, 09:24
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(des00 @ Jan 13 2012, 17:15) ошибка описания, синтезируемая модель и поведенческая ведут себя по-разному. Спасибо за помощь. Разобрался. Старую таблицу памяти подцепил, в которой ошибка была.
|
|
|
|
|
|
|
|
Mar 6 2012, 05:50
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Mar 6 2012, 08:16) Из обсуждения выше я понял, что достоверно невозможно определить количество ошибок, если ошибок слишком много. Но меня интересует случай, когда ошибок меньше граници детектирования. Можно ли в этом случае определить возможность исправления ошибок до поиска ченя? Если количество ошибок превышает исправляющую способность кода , то нет смысла определять сколько было ошибок. Если как Вы говорите ошибок точно меньше исправляющей способности, то вы с высокой степенью вероятности можете предположить, что возможность исправления есть. А вот местоположения этих ошибок Вы сможете определить только после процедуры Ченя. Хотя мне непонятно зачем Вам определять возможность исправления.
|
|
|
|
|
|
|
|
Mar 6 2012, 05:58
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(Denisnovel @ Mar 6 2012, 09:54) Может я не правильно выразился. Можно ли вычислить сигнал "decoding failure" до поиска Ченя? нельзя
|
|
|
|
|
|
|
|
Mar 6 2012, 06:08
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
Цитата(Gold777 @ Mar 6 2012, 00:58) нельзя Цитата(Denisnovel @ Mar 6 2012, 01:04) Ясно. Спасибо. можно, но не в реализации алгоритма берлекампа с фиксированным количеством шагов. В частности, если мне не изменяет память, в книге "Кодирование с исправлением ошибок в системах связи" есть классическая реализация алгоритма берлекампа с делением, там есть анализ степени полинома, которая получилась. ну и еще, если степень полинома локаторов меньше t, то гарантировано все будет ок.это не к месту %)
--------------------
|
|
|
|
|
|
|
|
Mar 7 2012, 13:21
|
Знающий
Группа: Свой
Сообщений: 812
Регистрация: 22-01-05
Из: SPb
Пользователь №: 2 119
|
Цитата(des00 @ Mar 7 2012, 16:27) а вот и тот алгоритм и статья . Кстати есть такая занятная вещь как "декодирование за границей БЧХ" никто не сталкивался ? Обычно рассматривается случай одной-двух дополнительных ошибок, не больше. Есть куча работ.
|
|
|
|
|
|
|
|
Mar 14 2012, 07:32
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
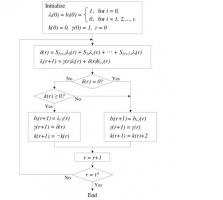
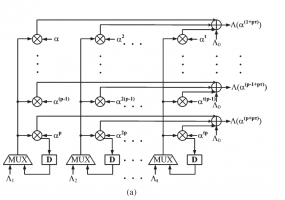
Делаю паралельную реализация поиска Ченя согласно прикрепленному файлу. Считает правильно, но результат сдвунут на 1. Т.е. 0 появляется раньше на одну позицию. При начале поиска происходит инициализация. Если написать "start_root_index(i)-1" то с одной ошибкой работает, с двумя не работает совсем. Код loc_mult_par[i] <= gf_mult_a_by_b_const(iloc_poly[i], ALPHA_TO[start_root_index(i)-1]); Что это может быть?
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Mar 14 2012, 08:27
|
Частый гость
Группа: Свой
Сообщений: 82
Регистрация: 7-12-05
Из: 77
Пользователь №: 11 952
|
Цитата(Denisnovel @ Mar 14 2012, 11:32) Делаю паралельную реализация поиска Ченя согласно прикрепленному файлу. Считает правильно, но результат сдвунут на 1.
Что это может быть? Код неукороченный случаем?
--------------------
Не, ну наболело, капитан - он выступает как директор пляжа, посол! (с) Ширли-Мырли
|
|
|
|
|
|
|
|
Mar 14 2012, 09:33
|
Частый гость
Группа: Свой
Сообщений: 108
Регистрация: 31-12-07
Из: Фрязино М.О.
Пользователь №: 33 753
|
Сейчас сделал так. Вроде работает. Буду тестировать. Код function automatic data_t start_root_index(input int step);
start_root_index = (step*(gf_n_max - n /*+ 1*/)) % gf_n_max;
endfunction
|
|
|
|
|
|
|
|
Mar 26 2012, 05:14
|
Группа: Новичок
Сообщений: 6
Регистрация: 26-03-12
Пользователь №: 71 000
|
Господа, просвятите начинающего!
Задача стоит реализовать на языке MATLAB алгоритм Берлекемпа-Месси в декодере БЧХ. Алгоритм предусматривает использование компонент (элементов) синдрома, которые определяются как значения принятого слова (полинома) в нулях кода (в корнях порождающего многочлена). Мне непонятно, в какой форме должны находиться и использоваться в этой ситуации корни порождающего многочлена. Буду особенно благодарен за комментарии с примерами.
|
|
|
|
|
|
|
|
Mar 28 2012, 01:38
|
Группа: Новичок
Сообщений: 6
Регистрация: 26-03-12
Пользователь №: 71 000
|
Цитата(des00 @ Mar 27 2012, 12:16) что мешает найти в матлабе файлик rsdec.m или bchdec.m и посмотреть ? отсутствие уверенности в том, что там именно нужный мне алгоритм
|
|
|
|
|
|
|
|
Mar 28 2012, 11:15
|
Частый гость
Группа: Участник
Сообщений: 118
Регистрация: 28-10-11
Из: Москва
Пользователь №: 68 022
|
Цитата(mad_physicist @ Mar 26 2012, 09:14) Господа, просвятите начинающего!
Задача стоит реализовать на языке MATLAB алгоритм Берлекемпа-Месси в декодере БЧХ. Алгоритм предусматривает использование компонент (элементов) синдрома, которые определяются как значения принятого слова (полинома) в нулях кода (в корнях порождающего многочлена). Мне непонятно, в какой форме должны находиться и использоваться в этой ситуации корни порождающего многочлена. Буду особенно благодарен за комментарии с примерами. Если хотите разобраться в алгоритме БМ, почитайте Морелос-Сарагоса - Искусство помехоустойчивого кодирования. Для алгоритма БМ нужны только компоненты синдромов. Компоненты синдромов рассчитываются с помощью элементов поля Галуа. О чем вы спрашиваете мне не очень понятно ( Что значит в какой форме должны находиться и использоваться в этой ситуации корни порождающего многочлена?).
Сообщение отредактировал Gold777 - Mar 28 2012, 11:26
|
|
|
|
|
|
|
|
Mar 29 2012, 01:23
|
Группа: Новичок
Сообщений: 6
Регистрация: 26-03-12
Пользователь №: 71 000
|
Цитата(Gold777 @ Mar 28 2012, 18:15) Если хотите разобраться в алгоритме БМ, почитайте Морелос-Сарагоса - Искусство помехоустойчивого кодирования. Для алгоритма БМ нужны только компоненты синдромов. Компоненты синдромов рассчитываются с помощью элементов поля Галуа.
О чем вы спрашиваете мне не очень понятно ( Что значит в какой форме должны находиться и использоваться в этой ситуации корни порождающего многочлена?). То, что я написал, основано именно на книге Морелоса-Сарагосы и статье С.В. Фёдорова о реализации БМ-алгоритма для РС-кодов на ПЛИС. Компоненты синдромов вычисляются путём подстановки корней порождающего полинома в полином принятого сообщения. Я пока не понимаю, как именно это должно происходить. То есть у меня имеется порождающий полином 14-й степени, нахождение его корней "в лоб", обычной арифметикой, даёт мне 14 комплексных корней. Я подозреваю, что такое решение не есть правильное, и необходимо использовать полиноминальную арифметику. Но каким образом это сделать я пока не знаю. Попутно задам ещё один вопрос: подскажите, как связаны между собой компоненты синдрома, о которых говорилось выше, и синдромный полином?
|
|
|
|
|
|
|
|
Mar 29 2012, 15:13
|
Вечный ламер
Группа: Модераторы
Сообщений: 7 248
Регистрация: 18-03-05
Из: Томск
Пользователь №: 3 453
|
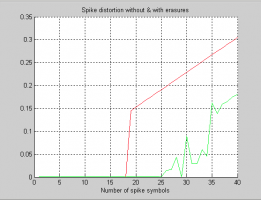
Уважаемые гуру, подскажите что не так делаю. Решил проверить работу декодера БЧХ со стираниям. Взял алгоритм из Скляра : 1. заместить стирания нулями 2. заместить стирания единицам 3. декодировать оба и выбрать то слово, которое соответствует наименьшему числу ошибок, исправленных вне позиций стирания. Кол-во исправляемых стираний определяется по формуле p <= d-1. Набросал в матлабе простой пример. взял код {255, 131, 18}, с dmin = 37. Но не вижу исправления 36 стираний %( Единственная разница алгоритма в Скляре и в примере в том, что в примере добавляются только стирания, по идее кол-во ошибок вне позиций стирания в обоих случаях должно быть одинаковым. Или я слишком упрощаю и в этом и есть моя ошибка ? Спасибо.
Эскизы прикрепленных изображений
--------------------
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|