| |
|
  |
 Работе по фронтам не клокового входа Работе по фронтам не клокового входа, чем черевато? |
|
|
|
|
 Jan 5 2014, 20:43 Jan 5 2014, 20:43
|
Местный

Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023

|
Цитата(Golikov A. @ Jan 4 2014, 23:22)  Расскажете как выделить 50 МГц клок на 100 МГц тактовой? Боюсь что для этого надо не меньше 200 МГц, а этого мне на 6 спартане добиться не удалось... Можно работать по обоим фронтам тактовой 100 МГц. Делал подобное. Наверное получится.
|
|
|
|
|
|
|
|
Jan 6 2014, 09:52
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 5 2014, 20:48) как сделать такое колдунство как локальный клок? Для начала, написать в конце концов PN чипа и номер ноги. Что за привычка долго и мучительно пытаться обсуждать сферического коня?
|
|
|
|
|
|
|
|
Jan 6 2014, 14:17
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 6 2014, 00:21) не получится... Примерно так: Код // сохранённые значения входных сигналов соответствуют следующим моментам тактового сигнала c 100 МГц:
// +---------+ +---------+ +------
// | | | | |
// -----+ +----------+ +------------+
// sck2 sck2n sck1 sck1n sck
// mosi2n mosi1 mosi1n mosi
input c,sck,mosi;
reg sck1n,sck2n,mosi1n,mosi2n,sck1,sck2,mosi1,fr;
reg [7:0] data;
reg [2:0] nbit;
always @(negedge(c))
begin
sck1n <= sck;
sck2n <= sck1n;
mosi1n <= mosi;
mosi2n <= mosi1n;
end
always @(posedge(c))
begin
sck1 <= sck;
sck2 <= sck1;
mosi1 <= mosi;
if (sck1 & (~sck2n))
begin
data <= {data[6:0], mosi1};
fr <= (nbit==7);
nbit <= nbit+1;
end
else if (sck2n & (~sck2))
begin
data <= {data[6:0], mosi2n};
fr <= (nbit==7);
nbit <= nbit+1;
end
if (fr)
begin
fr <= 0;
// байт принят в data
end
end Здесь данные с mosi берутся по переднему фронту sck.
Сообщение отредактировал maksimp - Jan 6 2014, 14:27
|
|
|
|
|
|
|
|
Jan 6 2014, 15:40
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(o_khavin @ Jan 6 2014, 13:52) Для начала, написать в конце концов PN чипа и номер ноги. Что за привычка долго и мучительно пытаться обсуждать сферического коня? я просто пытался абстрактно рассматривать ситуацию, вообще в целом. Меня смущают попытки сразу тянуть сигнал на gbuf и получать огромную задержку на этом пути. Неужели нельзя договориться с синтезатором чтобы он протащил пин на прямую? Но не на уровне раскладки ЛУТов в ручную, а на высоком уровне, чтобы проект мог быть дальше поддержан. Без ассемблера как бы... Но когда такие люди просят данных, не могу не дать  чип спартан 6, XC6SLX9-3TQ144I ножки CLK1 - 11 MISO - 12 MOSI - 14 CLK0 - 33 MISO - 34 MOSI - 35 Цитата(maksimp @ Jan 6 2014, 18:17) Примерно так:
Здесь данные с mosi берутся по переднему фронту sck. спасибо за текст и картинки, я понял идею, я пробовал это самым первым когда понял что констрайн не проходит. Я еще попозже повнимательнее посмотрю, может я чего-то упустил, но вроде бы так и делал.
|
|
|
|
|
|
|
|
Jan 6 2014, 17:55
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 5 2014, 21:56) тормозит именно SPI
в частности из готового сдвигового регистра не получается вовремя доставить данные на выход, по падающему фронту регистр сдвигается, а к следующему поднимающемуся данные должны уже стоять, а так не выходит, не хватает 2-3 нСек... Можно сдвигать регистр не по падающему а по поднимающемуся фронту. Приёмник (внешний относительно ПЛИС) берёт данные по поднимающемуся фронту, и сдвигать регистр можно тут же, не ожидая ещё половину такта.
|
|
|
|
|
|
|
|
Jan 6 2014, 18:52
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
данные сдвигаются по падающему фронту,
захват по поднимающемуся.
время между падающим и поднимающимся 10 нСек
время пока клок идет до сдвиг регистра 7-8 нСек,
время пока данные из сдвиг регистра идут на ружу 3-4 нСек
то есть между падающим фронтом и появлением данных проходит 12 нСек вместо 10, это в медленном пути, в быстром проходит 4.
потому перенести выдачу данных на поднимающиеся фронты тоже не вариант, в надежде на задержку.
из реальности уговорить сигнал не идти на глобальный буфер, на что у него уходит 5.9 нСек в медленном пути, а сразу идти на клок элементов, если это вообще возможно. Пока это я еще не реализовывал, и пока не имею 100% информации о возможности
|
|
|
|
|
|
|
|
Jan 6 2014, 18:58
|
Знающий
Группа: Свой
Сообщений: 781
Регистрация: 3-10-04
Из: Санкт-Петербург
Пользователь №: 768
|
Цитата(Golikov A. @ Jan 6 2014, 21:52) данные сдвигаются по падающему фронту,
захват по поднимающемуся.
время между падающим и поднимающимся 10 нСек
время пока клок идет до сдвиг регистра 7-8 нСек,
время пока данные из сдвиг регистра идут на ружу 3-4 нСек
то есть между падающим фронтом и появлением данных проходит 12 нСек вместо 10, это в медленном пути, в быстром проходит 4.
потому перенести выдачу данных на поднимающиеся фронты тоже не вариант, в надежде на задержку.
из реальности уговорить сигнал не идти на глобальный буфер, на что у него уходит 5.9 нСек в медленном пути, а сразу идти на клок элементов, если это вообще возможно. Пока это я еще не реализовывал, и пока не имею 100% информации о возможности Позвольте Вам не поверить. В 6-м Спартанце такие задержки??? Вы как-то не так логику описали. Приводите весь ваш исходник SPI.
|
|
|
|
|
|
|
|
Jan 6 2014, 19:13
|
Местный
Группа: Участник
Сообщений: 313
Регистрация: 2-07-11
Пользователь №: 66 023
|
Цитата(Golikov A. @ Jan 6 2014, 21:52) то есть между падающим фронтом и появлением данных проходит 12 нСек вместо 10, это в медленном пути, в быстром проходит 4.
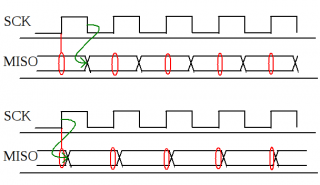
потому перенести выдачу данных на поднимающиеся фронты тоже не вариант, в надежде на задержку. 4 нс это не проблема. Приёмник уже захватил данные по поднимающимуся фронту, держать данные ещё 10 нсек не обязательно. На графиках - верхняя пара - обычныое построение SPI. Красным отмечены моменты захвата данных Нижняя пара - то что предлагается. В любом случае захват будет до изменения данных, даже если там всего 4 нс.
Эскизы прикрепленных изображений
|
|
|
|
|
|
|
|
Jan 6 2014, 19:36
|
Гуру
Группа: Свой
Сообщений: 7 946
Регистрация: 25-02-05
Из: Moscow, Russia
Пользователь №: 2 881
|
Только надо всегда помнить, что прохождение клока от клоковой ноги до клокового пина регистра обычно дольше, чем прохождение данного от ноги до пина данных регистра, из-за того, что дерево клока большое и толстое, даже локальное/региональное. Но их, обычно, можно выровнять - для этого в ПЛИС обычно предусмотрены линии задержки в пинах данных от входного буфера до регистра в IO буфере. В ПЛИС Lattice - это FIXEDDELAY, и DELAYB элементы - FIXEDDELAY указывается как атрибут синтезатору, а DELAYB ставится как примитив. Таким образом, если первый регистр от сдвигового регистра расположить в IO буфере, и завести данные на него через вот этот хитрый элемент задержки, то он обеспечит нулевой холд, то есть то, что клок дойдет до этого регистра вместе с данными, не позже их. Как мне кажется, это должно решить Вашу проблему на корню, если я ее правильно понял. Это касаемо входного сигнала данных, которые ПЛИС принимает. Но - не забывайте про холд... Сетап может пройти по этому сигналу, а холд оказаться криминальным из-за обгона клока входными данными! Конкретно, с Xilinx, сорри, не знаю, не приходилось с их ПЛИС дело иметь, бог миловал, но аналогичный механизм там есть наверняка - смотрите документацию, связанную с IO буферами и их внутренним устройством. На нижеприведенной картинке эти узлы видно, слева вверху, но это картинка латиса, ищите аналогичные в своей документации.
Что касается задержки clock-to-output для выходного сигнала, который ПЛИС передает, то это, пожалуй, никак не лечится, разве что как-то вручную развести клок к output регистру в IO буфере (и, разумеется, выходной регистр регистра сдвига поместить в IO буфер, а не в LE), если это вообще по архитектуре возможно, пустить клок и в дерево, и еще мимо провести напрямую к нужному регистру - надо внимательно изучить архитектуру, покопать в ручном редакторе разводки кристалла. Еще - а вдруг... например, случайно, SPI клок попал на пин для DDR DQS - тогда этот путь задействовать можно, он вообще дюже быстрый. Ну и вообще, обратить внимание на всякие такие "креативные" решения вопроса. Заранее извиняюсь, если вообще не так понял проблему....
|
|
|
|
|
|
|
|
Jan 6 2014, 20:36
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(Tiro @ Jan 6 2014, 22:58) Позвольте Вам не поверить. В 6-м Спартанце такие задержки??? Вы как-то не так логику описали. Приводите весь ваш исходник SPI. проблемы что клок идет с не клокового входа, о чем собственно вся тема Цитата(SM @ Jan 6 2014, 23:36) Что касается задержки clock-to-output для выходного сигнала, который ПЛИС передает, то это, пожалуй, никак не лечится, разве что как-то вручную развести клок к output регистру в IO буфере (и, разумеется, выходной регистр регистра сдвига поместить в IO буфер, а не в LE)
Заранее извиняюсь, если вообще не так понял проблему.... Все верно в целом, но с приемом в плис проблем нет, констрейны заданы и выполнены с бооольшим запасом. А вот с передачей как раз есть засада и большая, и именно про ручное решение проблемы сейчас и думаю... Цитата(maksimp @ Jan 6 2014, 23:13) 4 нс это не проблема. Приёмник уже захватил данные по поднимающимуся фронту, держать данные ещё 10 нсек не обязательно.
На графиках - верхняя пара - обычныое построение SPI. Красным отмечены моменты захвата данных
Нижняя пара - то что предлагается. В любом случае захват будет до изменения данных, даже если там всего 4 нс. Проблема передачи данных ПЛИСом как слейвом Мастер ставит клок, а на него надо реагировать и выдавать данные... путь сигнала от клока до выхода 12 нСек, вместо 10 нСек потому мастер захватывает черти что. Наверное менять данные по восходящему клоку возможно, поскольку есть дикая задержка от клока до буфера, то напортить данные в момент приема скорее всего не реально, но хорошо бы как то правильно констрейны написать, чтобы все было четко...
|
|
|
|
|
|
|
|
Jan 6 2014, 20:55
|
Местный
Группа: Участник
Сообщений: 230
Регистрация: 29-08-09
Пользователь №: 52 094
|
Цитата(Golikov A. @ Jan 7 2014, 00:36) Все верно в целом, но с приемом в плис проблем нет, констрейны заданы и выполнены с бооольшим запасом.
А вот с передачей как раз есть засада и большая, и именно про ручное решение проблемы сейчас и думаю... Как вариант, устроить "калибровку" выхода выдавая данные либо по падающему фронту, либо по восходящему в зависимости от конкретного случая. Т.е. пытаться вычитать что-то наружу в одном и другом варианте (дизайн должен иметь возможность переключения без переконфигурирования), проверять на мастере на предмет успешного приёма, и выбирать "хороший" вариант для дальнейшей работы.
|
|
|
|
|
|
|
|
Jan 6 2014, 22:12
|
Гуру
Группа: Свой
Сообщений: 4 256
Регистрация: 17-02-06
Пользователь №: 14 454
|
Цитата(o_khavin @ Jan 7 2014, 00:55) Как вариант, устроить "калибровку" выхода выдавая данные либо по падающему фронту, либо по восходящему в зависимости от конкретного случая. Т.е. пытаться вычитать что-то наружу в одном и другом варианте (дизайн должен иметь возможность переключения без переконфигурирования), проверять на мастере на предмет успешного приёма, и выбирать "хороший" вариант для дальнейшей работы. Мне кажется потенциально опасное решение. В начале работы на холодном кристале все пойдет по одному пути, потом он прогреется и...? попробовал защелкнуть данные в регистр по падению чип селекта, а потом выдавливать по восходящему фронту получил ошибку Assignment under multiple single edges is not supported for synthesis ту же ошибку я получал пытаясь работать по 2 фронтам клока. к ошибке есть приписка You can change the severity of this error message to warning using switch -change_error_to_warning "HDLCompiler:1128" но хорошо ли это? В целом я знаю что сначала будет фронт одного сигнала, а потом будут фронты другого сигнала, но поможет ли это схеме? И можно ли задать констрейн чтобы данные на выходе менялись не раньше чем заданное число после клока на входе, вроде же можно через VALID да? Если удастся договорится со схемой по этим 2 пунктам, то задача будет в целом решена, данные будут меняться не по падающему клоку, а по восходящему, но с гарантированной паузой. Есть шансы? Ну что-же! успех, наверное можно сказать что наконец то я понял идею maksimp по синхронизации на основной клок, и возможно даже ее реализую, надо еще кое-что проверить. на данный момент реализовал выдачу данных по восходящему фронту, фактически по сигналу защелкивания данных. Очень хочется наложить правильный констрейн на смену данных после фронта, нее раньше чем через заданное время, и что-то я пока не понимаю как. Сделал первые тесты чтения записи, вроде бы все наладилось, в целом оно и понятно если путь данных был примерно 12 нСек, то после поднимающегося фронта данные как раз и выставляются на падающий. А долгая задержка клока сохраняет данные во время защелки, но ВСЕ ТАК хотелось бы подстраховаться констрейном. Кто поможет? Как обозначить чтобы данные менялись не раньше чем через заданное время после фронта?
|
|
|
|
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
|
|
|